多模态模型架构:三大演进线路与对比总结
1 引言
多模态模型架构的核心目标,是解决文本、图像、音频等异质模态的交互与对齐问题。目前主流的多模态架构演进形成了三大核心线路:融合-编码架构、双塔架构与统一Transformer架构。本文将详细解析这三条演进线路的核心思想、代表模型、优劣势及适用场景,为多模态技术选型提供清晰参考。
2 基础:Embedding与Transformer
多模态架构的底层依赖两大核心技术:Embedding表征与Transformer编码,二者共同支撑了异质模态的数值化与交互建模。
2.1 Embedding:模态的统一数值化表达
定义:Embedding是将复杂的非结构化信息(如图像、文本、语音)转换为低维稠密向量的过程,用一串数字来表示其语义特征。
- 1. 机器无法直接理解图像、文字等原始信息,Embedding将其转换为可计算的“数字语言”;
- 2. 在统一的Embedding空间中,可通过相似度(如余弦相似度)衡量不同模态的语义关联,例如“cat”的文本向量与猫的图像向量会更接近,而与“car”的文本向量更远。

2.2 Transformer:多模态交互的核心骨架
2017年,Google Brain在论文《Attention is All You Need》中提出Transformer架构,彻底改变了序列建模的范式,也成为多模态模型的核心骨架。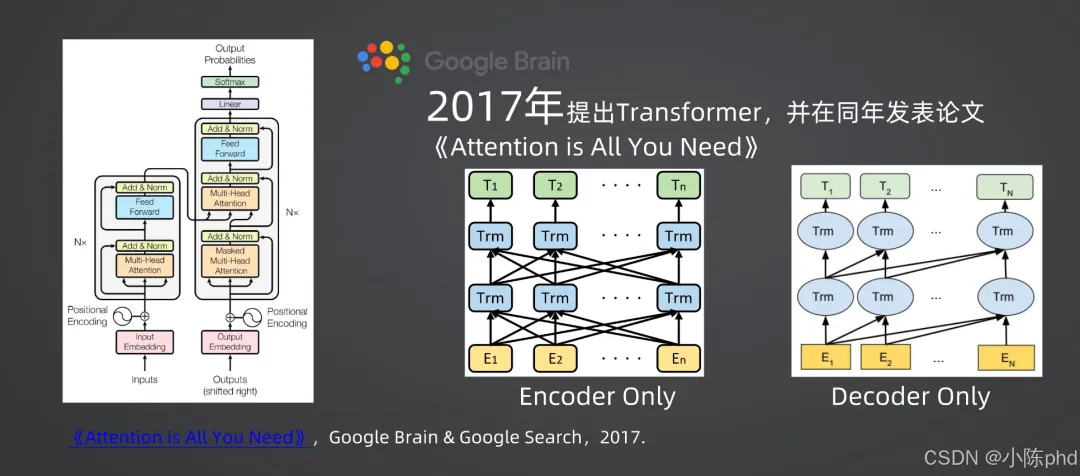
- • Encoder Only:仅包含编码器,擅长从输入中提取特征(如BERT、ViT);
- • Decoder Only:仅包含解码器,擅长生成式任务(如GPT);
- • Encoder-Decoder:同时包含编码器和解码器,适用于序列到序列任务(如机器翻译)。
- • 关键能力:通过自注意力机制(Self-Attention)捕捉序列中的全局依赖,为多模态的细粒度交互提供了可能。
2.3 ViT:图像模态的Transformer适配
为了将Transformer应用于图像领域,Google于2020年提出ViT(Vision Transformer),核心思路是将图像转换为序列,适配Transformer的输入格式:
- 1. Patch切分:将图像切分为固定大小的像素块(Patch),每个Patch大小为P×P,再将每个Patch展平为一维向量,通过线性映射到d维空间(如ViT Base的d=768,对应16×16×3的RGB Patch);

- 2. 位置编码:Transformer本身不理解序列顺序,因此ViT引入可学习的位置向量(Learnable Position Embedding),添加到每个Patch Embedding中,保留图像的空间位置信息;

- 3. Transformer编码:将Patch Embedding序列送入标准Transformer,通过自注意力机制让不同Patch之间建立关联(如“眼睛”和“耳朵”的Patch会形成强关联),相比CNN仅关注局部特征,Transformer可捕捉全局语义;

- 4. 全局特征提取:在输入序列前加入一个特殊的分类标记
[CLS],训练完成后,该标记的输出即可作为整张图像的全局特征,用于后续任务。
3 演进线路一:融合-编码架构(Fusion-encoder)
融合-编码架构是多模态交互的早期主流思路,核心是让不同模态在模型内部深度交互,实现细粒度的语义对齐。
3.1 核心思想
模态输入在Transformer内部通过交叉注意力(Cross-Attention)深度交互:
- 1. 图像和文本先通过各自的编码器(如ViT、BERT)进行编码,得到独立的Embedding表示;
- 2. 在Transformer的多层结构中,两种模态的Embedding保持独立的数据流(Stream),仅在特定层通过Cross-Attention等机制进行交互,让文本词关注图像区域,或图像区域关注文本片段。
3.2 代表模型
- • 2019年:LXMERT(UNC)、ViLBERT(Georgia Tech & Facebook AI Research)作为融合-编码架构的开端,首次将Cross-Attention引入多模态建模;
- • 近年:Qwen2.5 VL、InternVL 3、Step 3等模型进一步优化了融合-编码架构,提升了跨模态推理能力。
3.3 特点与适用场景
- • 优势:能捕捉图像区域与文本词语之间的一一对应关系,注意力权重可直观显示“模型在看哪里”,适合需要深度理解模态关联的复杂任务;
- • 局限:计算成本高,无法离线预计算Embedding,难以支撑大规模检索等高效场景;
- • 典型场景:视觉问答(VQA)、跨模态推理等需要深度模态交互的任务。
4 演进线路二:双塔架构(Dual-encoder)
双塔架构是工业界更青睐的多模态范式,核心是“先独立编码,后空间对齐”,在效率与效果之间取得了平衡。
4.1 核心思想
不同模态各自编码,再在共享语义空间里对齐:
- 1. 每个模态(如文本、图像)使用独立的编码器(如文本用BERT/GPT,图像用ViT/ResNet)提取专属Embedding;
- 2. 将两种模态的Embedding投影到同一个语义空间,通过相似度(如余弦相似度)度量它们的语义关系,让相同语义的跨模态样本在空间中更接近。
4.2 代表模型与技术细节
4.2.1 CLIP:双塔架构的里程碑
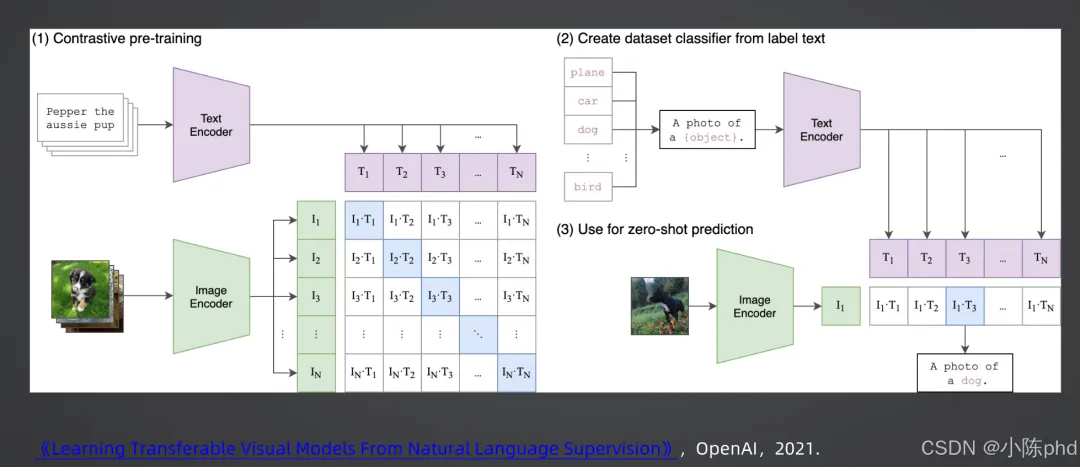
2021年,OpenAI提出CLIP(Contrastive Language-Image Pre-training),彻底推动了双塔架构的大规模应用,核心流程分为三步:
- • 文本编码器(Transformer)和图像编码器(ViT/ResNet)分别对文本和图像进行编码,得到文本特征 和图像特征 ;
- • 构造批次内的图文对,通过对比损失函数优化:最大化匹配图文对的相似度,最小化不匹配图文对,的相似度,让图文在语义空间中对齐;
- 2. 零样本分类:用标签文本(如“A photo of a dog”)构建分类器,通过文本编码器得到文本特征,再与图像特征计算相似度,实现无需额外训练的跨模态分类;
- 3. 检索应用:离线预计算所有图像的Embedding,当用户输入文本查询时,仅需计算文本Embedding与图像Embedding的余弦相似度,即可快速返回匹配结果。
4.2.2 其他代表模型
- • 2021年:ALIGN(Google)与CLIP同期提出,同样采用双塔对比学习范式;
- • 国内模型:CN-CLIP、Wukong-CLIP、Taiyi-CLIP等,针对中文场景优化了双塔架构性能。
4.3 特点与适用场景
- 1. 效率高:可离线预计算模态Embedding,检索时仅需相似度计算,支撑百万级候选的快速筛选;
- 2. 泛化性强:训练完成后可实现零样本(Zero-shot)跨模态检索与分类,无需针对特定任务微调;
- • 局限:缺少细粒度模态交互,生成能力弱,难以支撑复杂的跨模态生成任务;
- • 典型场景:跨模态检索(以文搜图、以图搜文)、推荐系统、零样本分类等需要高效语义匹配的场景。
5 演进线路三:统一Transformer架构(Unified Transformer)
统一Transformer架构是多模态模型的最新演进方向,核心是打破模态边界,用单一Transformer架构处理所有模态,实现“一统多模态”的目标。
5.1 核心思想
所有模态统一token化→单一Transformer:
- 1. 将文本、图像、音频、视频等所有模态数据统一转换为token序列(如图像切分为Patch token,音频切分为帧token,文本保持为word token);
- 2. 用一个共享的Transformer架构处理所有模态的token,不再区分模态专用编码器,让模型在统一的token空间中学习跨模态语义关联。
5.2 代表模型
- • Chameleon:Meta提出的统一多模态模型,支持文本、图像、音频、视频等多模态输入输出;
- • Sora (OpenAI):文本生成视频的里程碑模型,将视频帧统一为token,通过Transformer实现高质量视频生成;
- • Veo 3 (Google):DeepMind的文本生成视频模型,同样采用统一token化思路;
- • 国内模型:CogVLM2、Yi-VL、InternLM-XComposer2.5等,支持图文对话、文生图/视频等多模态任务。
5.3 特点与适用场景
- 1. 架构简洁:无需维护多个模态专用编码器,单一Transformer即可处理所有模态;
- 2. 天然支持生成:统一token化让跨模态生成(如文生图、文生视频)更自然,无需额外的模态转换模块;
- 3. 泛化性强:在统一token空间中,模型能学习到更通用的跨模态语义表示,适配更多任务。
- 1. 对算力和数据依赖极高:需要大规模多模态数据和超强算力支撑训练,训练成本高昂;
- 2. 训练难度大:不同模态的token分布差异大,统一训练容易出现模态偏好,难以平衡各模态的表现。
- • 典型场景:多模态对话(如图文聊天、音视频交互)、跨模态生成(文本生成图像/视频、图像生成视频)等需要统一处理多模态输入输出的场景。
6 三大多模态架构对比总结

多模态架构的演进,本质是在“交互深度”“计算效率”“生成能力”三者之间的权衡与突破:
- 1. 融合-编码架构:优先保证模态交互深度,适合需要深度理解的任务,但牺牲了效率;
- 2. 双塔架构:优先保证计算效率,适合大规模检索场景,但牺牲了细粒度交互;
- 3. 统一Transformer架构:追求架构统一与生成能力,是未来多模态大模型的核心方向,但需要解决算力与数据依赖的问题。

