【笔记】强化学习实践
- 2026-05-24 01:21:36
参考代码库:https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Third-Edition
What Is Reinforcement Learning?
强化学习处于监督学习和无监督学习之间,没有明确的数据标签,但是有 reward 来指导学习,同时也使用监督学习的方法来进行目标函数估计。
强化学习的复杂性在于:
non-IID data,数据不是独立同分布的 exploration/exploitation dilemma,利用已有的知识还是更多地探索环境 delay reward
强化学习的组件:包括 Agent,环境,行为,奖励,和观测。
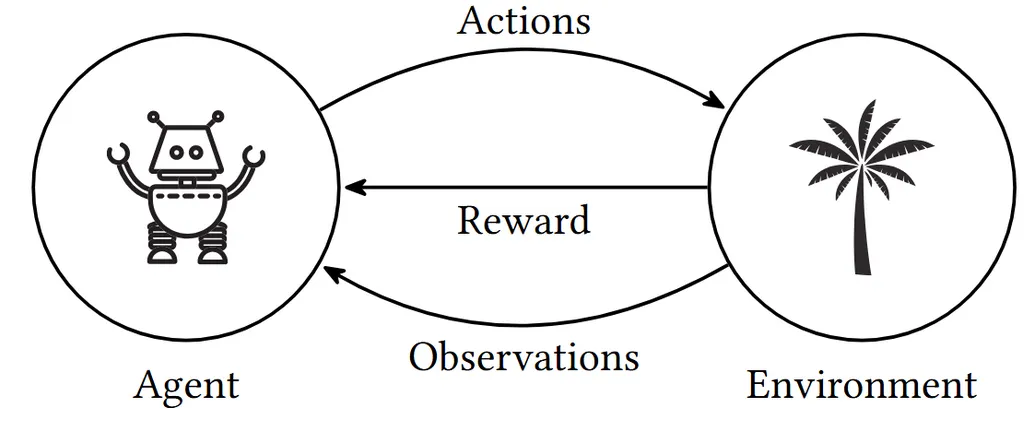
Reward:数值,表示 Agent 行为的好坏(feedback),强化学习的含义就是依据 reward 来正向或者负向强化行为。Agent 的目的就是在一连串的行为中实现最大的累积 reward(largest accumulated reward)。
Agent:可以和环境互作的实体,可以采取行动,进行观测,获得奖励。
Environment:除了 agent 以外的 everything。
Actions:agent 可以在环境中进行的事件。可以是离散的(比如下棋),也可以是连续的(比如自动驾驶中的方向盘角度)。
Observations:agent 从环境中获取的休息,和 state 区分,state 是环境内部的,一般无法直接获取。Agent 通过 Observation 获取环境信息,并根据这些信息做出决策(Action),从而影响环境的状态(State)。
RL 的理论基础和术语:
马尔可夫决策过程(Markov decision processes,MDPs)
马尔可夫过程 Markov process,可以观测到不同的状态(state),状态之间可以转变,所有的状态构成状态空间(state space)。一定时间内观测到的状态序列构成 history,Markov property 指的是未来状态仅依赖于当前状态。不同状态之间的转移概率可以用转移矩阵来表示(transition matrix)
Markov reward processes,在 MP 上加上另一个 reward 矩阵。Return (G)表示未来的 reward 的和,一般要加上 discount factor,return 的变化会很大,因此在应用中通常计算期望,叫做 value of the state (V),即对特定的状态 s,value of s 表示 follow Markov reward process 所得到的平均 return。
Markov decision processes,在 MRP 上加上 action,将转移矩阵变成三维的,加上 action 概率
Policy:定义 agent 行为的一系列规则,即输入是观测,输出是不同行为的概率。
OpenAI Gym API and Gymnasium
RL 的关键组分就是 agent 和 environment,在每一步,agent 会从环境中得到观测,进行计算,选择合适的 action,然后得到 reward 和新的观测。现在实现一个最简单的 RL 模型,首先有一个环境,能够和 agent 进行有限步的互作并给 agent 随机的 reward:
classEnvironment:def__init__(self): self.steps_left = 10defget_observation(self) -> List[float]:return [0.0, 0.0, 0.0]defget_actions(self) -> List[int]:return [0, 1]defis_done(self) -> bool:return self.steps_left == 0defaction(self, action: int) -> float:if self.is_done():raise Exception("Game is over") self.steps_left -= 1return random.random()Agent 部分包含一个构造器和在环境中进行一步操作的函数:
classAgent:def__init__(self): self.total_reward = 0.0defstep(self, env: Environment): current_obs = env.get_observation() ##观测 actions = env.get_actions() ##行动 reward = env.action(random.choice(actions)) ##获取 reward self.total_reward += reward安装依赖环境:
conda create -n rl python=3.11##requirements.txt#gymnasium[atari]==0.29.1#gymnasium[classic-control]==0.29.1#gymnasium[accept-rom-license]==0.29.1#moviepy==1.0.3#numpy<2#opencv-python==4.10.0.84#torch==2.5.0#torchvision==0.20.0#pytorch-ignite==0.5.1#tensorboard==2.18.0#mypy==1.8.0#ptan==0.8.1#stable-baselines3==2.3.2#torchrl==0.6.0#ray[tune]==2.37.0#pytestpip install -r requirements.txtThe OpenAI Gym API and Gymnasium
Gym 是 openAI 开发的强化学习算法以及环境 API 的 python 库,后面停止维护了,Gymnasium 是 Gym 的一个分支,提供持续的维护开发。
Gym 的主要目的是通过统一的接口为 RL 实验提供多种多样的环境,因此其主要的类是环境,Env,包含:
action_space,Space类,环境支持执行的 actions,可以是离散的,也可以是连续的,可以是多个 action 的组合observation_space,Space类, 环境可以给 agent 提供的观测step方法,在环境中执行 action(参数是action),返回是包含五个元素的 Python tuple,有下一个观测,reward,指示 episode 是否完成的 flag,是否为截断 episode 的 flag(是否达到时间步长限制等),以及来自环境的其他信息组成的字典。reset方法,返回初始状态的环境,获取第一个观测,以及来自环境的其他信息组成的字典。一般创建环境后需要调用。
一般流程为:创建环境(make(name) 函数),在一个循环中,调用 step() 方法并执行一个操作,直到 done 或 truncated 标志变为 True,然后可以调用 reset() 重新开始。
行为空间和观测空间都是 Space 类,其主要包含一个属性(property)和三个方法:
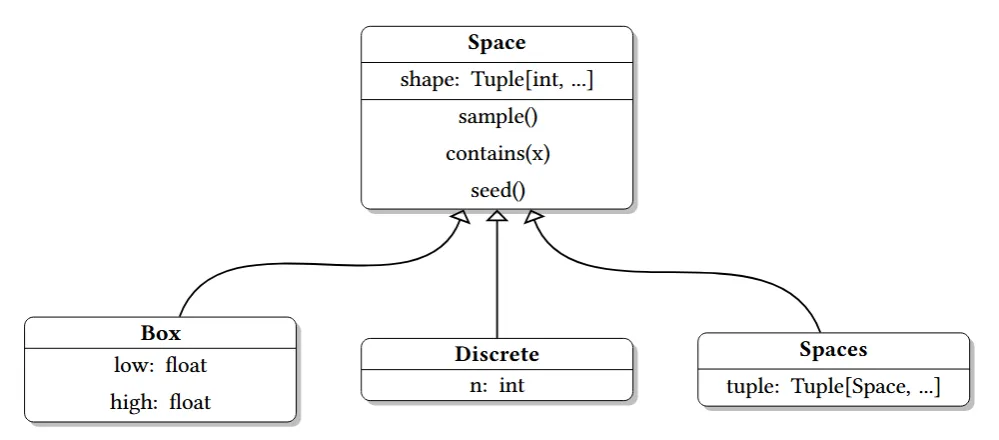
shape属性,space 的形状,为一个 NumPy arraysample方法,从 space 中返回一个随机样本contains(x)方法,判断 x 是否在 space 中seed方法,随机数生成器,用于在多次 run 中可以得到可复现的行为
常用的 Space 亚类包括三个(上图下面的三个):
Discrete类,从 0 到 n-1 的一个列表,也可以用start自定义开始 index。比如Discrete(n=4)可以用来表示四个方向的动作空间:[left, right, up, or down]Box类,有着上下界的 n 维 tensor,比如Box(low=0.0, high=1.0, shape=(1,), dtype=np.float32)可以用来表示 0-1 之间的一个数值(油门踏板的轻重);Box(low=0, high=255, shape=(210, 160, 3), dtype=np.uint8)可以表示 RGB 图片,值从 0-255,三维的 tensor 分别表示图像的长宽和 RGB 通道Spaces类,用 Tuple 来组合多个 Space,比如多个动作空间的组合:Tuple(spaces=(Box(low=-1.0, high=1.0, shape=(3,), dtype=np.float32), Discrete(n=3), Discrete(n=2)) )
也有其他的 Space 亚类,比如 Sequence 表示可变长度的序列,Text 表示字符串,Graph 表示网络图结构。
下面是 CartPole 的例子,在这个例子中 agent 需要控制一个小车(cart)来保持一个竖直的杆(pole)不倒:
这个环境的观测包括四个浮点值:
cart 质心的 X 轴坐标 cart 移动的速度 棍子和 cart 形成的角度 棍子的角速度
环境的奖励是 1,每个时间步都有一个奖励,直到棍子倒了为一个 episode。
import gymnasium as gyme = gym.make("CartPole-v1") ##创建环境obs, info = e.reset() ##初始化环境,得到第一个观测>>> obsarray([ 0.04317661, 0.03905296, -0.03008377, 0.0104478 ], dtype=float32)查看动作空间和观测空间:
>>> e.action_spaceDiscrete(2)>>> e.observation_spaceBox([-4.8000002e+00-3.4028235e+38-4.1887903e-01-3.4028235e+38], [4.8000002e+003.4028235e+384.1887903e-013.4028235e+38], (4,), float32)可以看到动作空间是两个离散的值,0 和 1,0 表示向左移动,1 表示向右移动。观测空间中前两个列表表示下限和上限,比如 cart 的移动范围在 -4.8 到 4.8 之间,第三个表示维度(4 个值),第四个是类型。
执行动作:
>>> e.step(0)(array([ 0.04395767, -0.15562493, -0.02987481, 0.2934892 ], dtype=float32), 1.0, False, False, {})向左移动一步,得到 5 个元素的 tuple,表示新的观测,奖励,是否结束,是否截断,其他信息。
也可以对动作空间和观测空间进行抽样:
>>> e.action_space.sample()1>>> e.action_space.sample()0>>> e.observation_space.sample()array([ 3.5342343e+00, -1.1708327e+38, 2.8985918e-01, 4.8329556e+36], dtype=float32)>>> e.observation_space.sample()array([ 2.1052108e+00, -6.3045888e+37, 2.9477644e-01, -9.7010877e+37], dtype=float32)下面是一个随机 agent 的例子:
import gymnasium as gymif __name__ == "__main__": env = gym.make("CartPole-v1") total_reward = 0.0 total_steps = 0 obs, _ = env.reset()whileTrue: action = env.action_space.sample() obs, reward, is_done, is_trunc, _ = env.step(action) total_reward += reward total_steps += 1if is_done:break print("Episode done in %d steps, total reward %.2f" % (total_steps, total_reward))$ python ch2_02_cartpole_random.py Episode donein 18 steps, total reward 18.00Extra Gym API functionality
为了给已有的环境增加更多的功能,比如对观测进行进一步处理,对奖励进行标准化等,Gym 提供了 Wrapper 类。Wrapper 类继承 Env 类,通过重写父类的方法增加功能,唯一的参数就是实例化的 Env 类。具有两个属性:env wrapped 后的环境或者另一个 wrapper,unwrapped 为原始的环境。为了更方便使用,还提供了多个子类:
ObservationWrapper,重定义observation(obs),输入原环境的观测,输出处理后的观测RewardWrapper,重定义reward(rew)ActionWrapper,重定义action(a)
下面是将上面的随机 agent 加上 ActionWrapper 的例子,重写了 action 方法,小于某个概率时采用随机的 action ,而不是原来的 action:
import gymnasium as gymimport randomclassRandomActionWrapper(gym.ActionWrapper):def__init__(self, env: gym.Env, epsilon: float = 0.1): super(RandomActionWrapper, self).__init__(env) self.epsilon = epsilondefaction(self, action: gym.core.WrapperActType) -> gym.core.WrapperActType:if random.random() < self.epsilon: action = self.env.action_space.sample() print(f"Random action {action}")return actionreturn actionif __name__ == "__main__": env = RandomActionWrapper(gym.make("CartPole-v1")) obs = env.reset() total_reward = 0.0whileTrue: obs, reward, done, _, _ = env.step(0) total_reward += rewardif done:break print(f"Reward got: {total_reward:.2f}")上面的例子都是在命令行上运行的,缺乏可视化的展示,HumanRendering 和 RecordVideo 做的就是进行可视化,前者打开一个 GUI,后者生成视频文件(mp4),需要在最后加上 env.close()。
import gymnasium as gymif __name__ == "__main__": env = gym.make("CartPole-v1", render_mode="rgb_array")#env = gym.wrappers.HumanRendering(env) env = gym.wrappers.RecordVideo(env, video_folder="video") total_reward = 0.0 total_steps = 0 obs = env.reset()whileTrue: action = env.action_space.sample() obs, reward, done, _, _ = env.step(action) total_reward += reward total_steps += 1if done:break print(f"Episode done in {total_steps} steps, total reward {total_reward:.2f}") env.close()交叉熵方法
RL 方法按照不同的角度可以进行分类:
模型无关/基于模型
模型无关(model-free):无需构建环境或者奖励的模型,agent 接受当前的观测,进行计算,得出应该采取的行为 基于模型(model-based):建模预测下一个观测或奖励是什么,基于该预测选择最佳的行为,适用于有着严格规则限制的环境,比如下棋 基于策略/基于值
基于策略(policy-based):直接去估计 agent policy 的参数(),即 action 的概率分布,采取概率最大的 action 基于值(value-based):估计值函数(value function)的参数,采取的 action 为使得值最大的 action On-policy / off-policy
On-policy:收集一次数据(互动一个 episode),训练/更新参数一次,也就是利用需要更新参数的 policy 收集数据 off-policy:基于历史数据(用另一个 policy 收集数据),可以训练/更新参数多次
交叉熵方法是最简单的 RL 方法,通过交叉熵 loss 优化 agent policy 的参数,使得输出的行为概率分布向着更高 reward 的行为逼近,也就是一个分类问题:
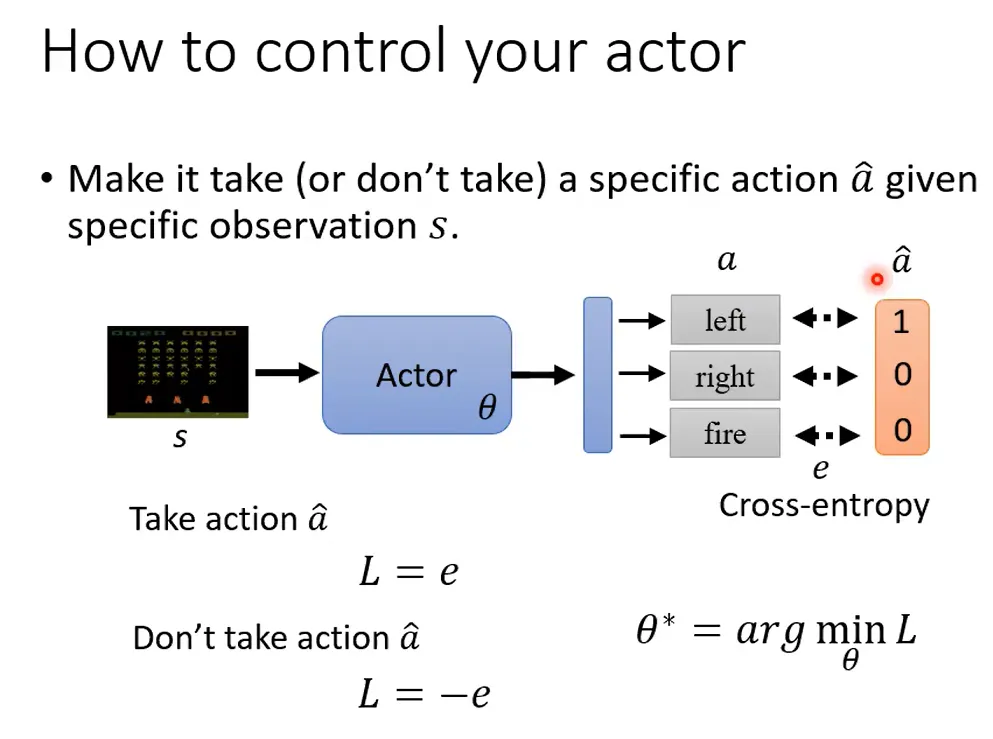
如何得到更高 reward 的行为——每次采样的时候,保留较高 reward 的 episode(这里设置的是 reward 在 Top 70%),用这些 episodes 来训练模型,从而逐步提高。因此交叉熵方法是 model-free, policy-based, on-policy。
在 CartPole 问题中应用交叉熵方法
载入需要的包,设置超参数,batch size:
import numpy as npimport gymnasium as gymfrom dataclasses import dataclassimport typing as ttfrom torch.utils.tensorboard.writer import SummaryWriterimport torchimport torch.nn as nnimport torch.optim as optimHIDDEN_SIZE = 128BATCH_SIZE = 16PERCENTILE = 70Policy Network,很简单,一层的 MLP:
classNet(nn.Module):def__init__(self, obs_size: int, hidden_size: int, n_actions: int): super(Net, self).__init__() self.net = nn.Sequential( nn.Linear(obs_size, hidden_size), nn.ReLU(), nn.Linear(hidden_size, n_actions) )defforward(self, x: torch.Tensor):return self.net(x)定义两个 dataclass,EpisodeStep 用来存放每步的观测和行为,Episode 用来存放一整个 episode 的奖励以及 episode 中每步的信息(为 EpisodeStep 构成的列表):
@dataclassclassEpisodeStep: observation: np.ndarray action: int@dataclassclassEpisode: reward: float steps: tt.List[EpisodeStep]接着定义生成 episodes 的方法,每个 batch 内部多个 episodes,即 episodes 为我们训练的样本,batch_size 为需要的 episodes 数量。
defiterate_batches(env: gym.Env, net: Net, batch_size: int) -> tt.Generator[tt.List[Episode], None, None]: batch = [] episode_reward = 0.0 episode_steps = [] obs, _ = env.reset() sm = nn.Softmax(dim=1)whileTrue: obs_v = torch.tensor(obs, dtype=torch.float32) act_probs_v = sm(net(obs_v.unsqueeze(0))) act_probs = act_probs_v.data.numpy()[0] action = np.random.choice(len(act_probs), p=act_probs) ##依据概率分布进行抽样 next_obs, reward, is_done, is_trunc, _ = env.step(action) episode_reward += float(reward) step = EpisodeStep(observation=obs, action=action) episode_steps.append(step)if is_done or is_trunc: e = Episode(reward=episode_reward, steps=episode_steps) batch.append(e) episode_reward = 0.0 episode_steps = [] next_obs, _ = env.reset()if len(batch) == batch_size:yield batch batch = [] obs = next_obs前面讲过,obs 为四个数值,因此使用 unsqueeze 增加一个 batch 维度,输入 net:
>>> obs_v.shapetorch.Size([4])np.random.choice 利用网络输出的 action 概率分布进行抽样,使得 agent 能够更好的探索环境。当 is_done 或者 is_trunc 是 True 的时候结束该 episode,将总的 reward 以及每步的观测和行为(存在 EpisodeStep 中)存在 Episode 里面,并加入到 batch 列表。当 episode 数量(batch size)达到要求就生成并返回 batch 列表。
env = gym.make("CartPole-v1")n_actions = int(env.action_space.n)obs_size = env.observation_space.shape[0]net = Net(obs_size, HIDDEN_SIZE, n_actions)batch = next(iterate_batches(env, net, BATCH_SIZE))len(batch)##16batch[0].reward##15.0len(batch[0].steps),len(batch[1].steps)##(15, 22)batch[0].steps[0]##EpisodeStep(observation=array([0.02282685, 0.01514341, 0.03914361, 0.00883957], dtype=float32), action=1)接下来定义 filter_batch 对生成的 episodes 进行筛选,选择总 reward 排在前 70% 的 episodes,返回四个值,观测,观测对应的行为,reward 阈值,平均 reward:
deffilter_batch(batch: tt.List[Episode], percentile: float) -> \ tt.Tuple[torch.FloatTensor, torch.LongTensor, float, float]: rewards = list(map(lambda s: s.reward, batch))##展开 rewards reward_bound = float(np.percentile(rewards, percentile)) reward_mean = float(np.mean(rewards)) train_obs: tt.List[np.ndarray] = [] train_act: tt.List[int] = []for episode in batch:if episode.reward < reward_bound:continue train_obs.extend(map(lambda step: step.observation, episode.steps)) train_act.extend(map(lambda step: step.action, episode.steps)) train_obs_v = torch.FloatTensor(np.vstack(train_obs)) train_act_v = torch.LongTensor(train_act)return train_obs_v, train_act_v, reward_bound, reward_meanmap 和 lambda经常一起使用,用于对可迭代对象中的每个元素应用某个函数
用法:map(lambda 参数: 表达式, 可迭代对象)
# 对每个数平方nums = [1, 2, 3, 4, 5]squares = list(map(lambda x: x**2, nums))# 结果: [1, 4, 9, 16, 25]
接下来就可以进行训练,取一个 batch 的数据(小于等于 16 个 episodes)然后更新参数:
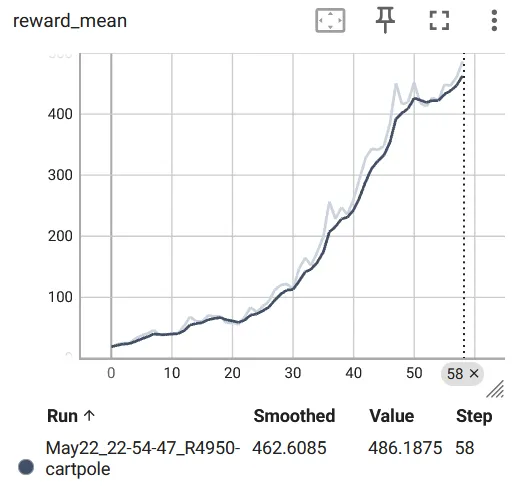
if __name__ == "__main__": env = gym.make("CartPole-v1", render_mode="rgb_array") env = gym.wrappers.RecordVideo(env, video_folder="CartPole-v1_video")assert env.observation_space.shape isnotNone obs_size = env.observation_space.shape[0]assert isinstance(env.action_space, gym.spaces.Discrete) n_actions = int(env.action_space.n) net = Net(obs_size, HIDDEN_SIZE, n_actions) print(net) objective = nn.CrossEntropyLoss() optimizer = optim.Adam(params=net.parameters(), lr=0.01) writer = SummaryWriter(comment="-cartpole")for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)): obs_v, acts_v, reward_b, reward_m = filter_batch(batch, PERCENTILE) optimizer.zero_grad() action_scores_v = net(obs_v) loss_v = objective(action_scores_v, acts_v) loss_v.backward() optimizer.step() print("%d: loss=%.3f, reward_mean=%.1f, rw_bound=%.1f" % ( iter_no, loss_v.item(), reward_m, reward_b)) writer.add_scalar("loss", loss_v.item(), iter_no) writer.add_scalar("reward_bound", reward_b, iter_no) writer.add_scalar("reward_mean", reward_m, iter_no) env.close()if reward_m > 475: print("Solved!")break writer.close()这个训练循环会一直进行,直到某个 batch 的平均 reward 大于 475。
需要更新下 moviepy,不然会报错 TypeError: must be real number, not NoneType
pip install --upgrade moviepy
可以使用 tensorboard 查看训练过程:
tensorboard --logdir=./runs --port=6006可能会出现 ModuleNotFoundError: No module named 'pkg_resources' 报错,需要降级 setuptools:
pip install "setuptools<82"
如果是从本地连接服务器,需要在 SSH 连接的时候进行端口映射:
ssh -L 本地端口:127.0.0.1:TensorBoard端口 用户名@服务器的IP地址 -p 服务器登录端口可以看到 Loss 在持续下降,平均 reward 以及阈值都在持续上升:
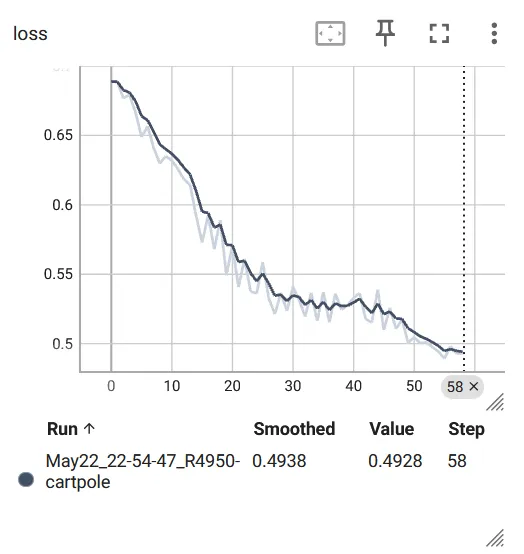
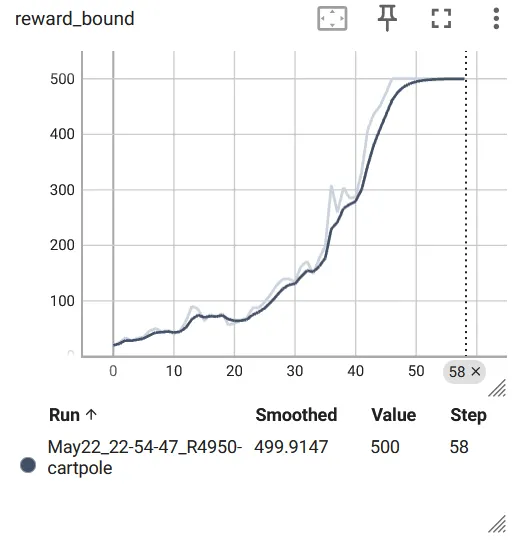
最后一个 episode(729 个)的视频(降低了帧率):
在 FrozenLake 中应用交叉熵方法
FrozenLake (冰湖):agent 从左上角开始,经过 4×4 的网格,到达右下角为成功,获得奖励 1,episode 结束,否则没有奖励。动作空间为 up, down, left, right。网格中也有洞,掉到洞里 episode 也会结束。还有一个打滑的设定,每次 agent 行动时都有 33% 的概率会被旋转 90 度的动作替代,比如预期进行向上的动作时,33% 的可能是向上,33% 可能是向左,33% 的可能是向右。

>>> e = gym.make("FrozenLake-v1", render_mode="ansi") >>> e.observation_space Discrete(16) >>> e.action_space Discrete(4) >>> e.reset() (0, {’prob’: 1}) 为了和之前的 CartPole 的网络输入相匹配,将单个数值的观测转化为 16 维的 one-hot 向量,使用之前讲到的 ObservationWrapper:
classDiscreteOneHotWrapper(gym.ObservationWrapper):def__init__(self, env: gym.Env): super(DiscreteOneHotWrapper, self).__init__(env)assert isinstance(env.observation_space, gym.spaces.Discrete) shape = (env.observation_space.n, ) self.observation_space = gym.spaces.Box(0.0, 1.0, shape, dtype=np.float32)defobservation(self, observation): res = np.copy(self.observation_space.low) res[observation] = 1.0return res测试一下:
env = gym.make("FrozenLake-v1")env1 = DiscreteOneHotWrapper(gym.make("FrozenLake-v1"))env.observation_space, env1.observation_space##(Discrete(16), Box(0.0, 1.0, (16,), float32))env.reset(),env1.reset()#((0, {'prob': 1}),#(array([1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],# dtype=float32), {'prob': 1}))相较于之前的 CartPole,冰湖问题的关键难点在于:CartPole 每一步都有奖励,而 FrozenLake 只会在结束的时候有奖励(sparse),并且最终得到的奖励只会有 0,1 两个值。如果还使用之前的 percentage 选择,会导致开始训练的时大部分都是失败的 episodes。需要对之前的策略进行改进:
更大的 batch size,获取更多成功的 episodes 在 reward 前加上小于 1 的系数 ,增加多样性,系数和 episode 的长度相关,越长 reward 越低() 对好的 episode 保留更长时间 降低学习率 增加训练时间
先改一下 filter_batch:
deffilter_batch(batch: tt.List[Episode], percentile: float) -> \ tt.Tuple[tt.List[Episode], tt.List[np.ndarray], tt.List[int], float]: reward_fun = lambda s: s.reward * (GAMMA ** len(s.steps)) disc_rewards = list(map(reward_fun, batch)) reward_bound = np.percentile(disc_rewards, percentile) train_obs: tt.List[np.ndarray] = [] train_act: tt.List[int] = [] elite_batch: tt.List[Episode] = []for example, discounted_reward in zip(batch, disc_rewards):if discounted_reward > reward_bound: train_obs.extend(map(lambda step: step.observation, example.steps)) train_act.extend(map(lambda step: step.action, example.steps)) elite_batch.append(example) ###保留比较好的 episodereturn elite_batch, train_obs, train_act, reward_bound在训练的时候,将之前步骤中的比较好的 episode 也加入训练(full_batch + batch),随着 batch 的累积,取最新的 500 个比较好的 episodes 进行训练,batch_size 设置成 100,其他的和 CartPole 一样:
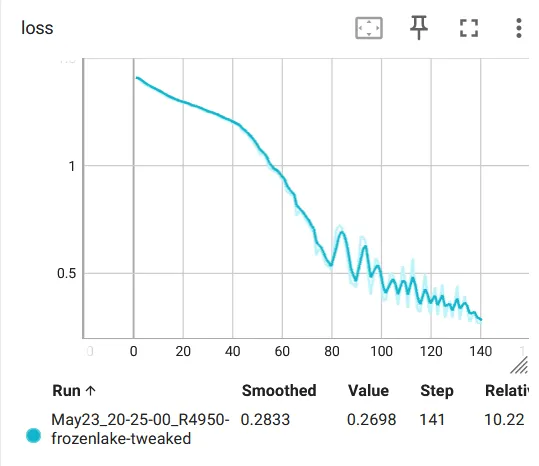
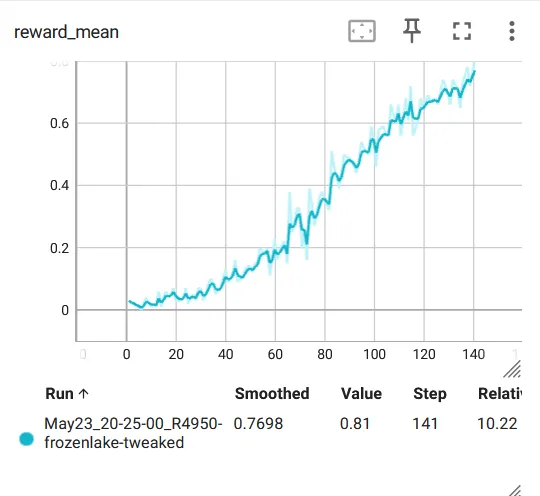
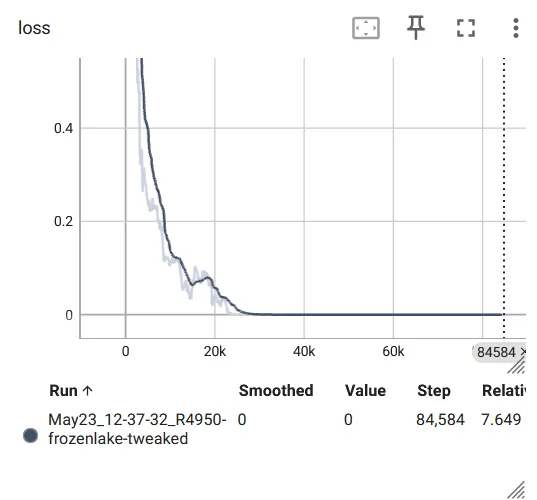
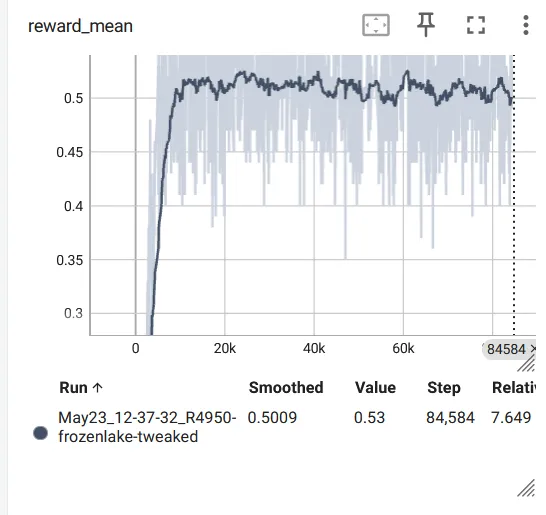
if __name__ == "__main__": random.seed(12345) env = DiscreteOneHotWrapper(gym.make("FrozenLake-v1", render_mode="rgb_array")) env = gym.wrappers.RecordVideo(env, video_folder="FrozenLake_video") obs_size = env.observation_space.shape[0] n_actions = env.action_space.n net = Net(obs_size, HIDDEN_SIZE, n_actions) objective = nn.CrossEntropyLoss() optimizer = optim.Adam(params=net.parameters(), lr=0.001) writer = SummaryWriter(comment="-frozenlake-tweaked") full_batch = []for iter_no, batch in enumerate(iterate_batches(env, net, BATCH_SIZE)): reward_mean = float(np.mean(list(map(lambda s: s.reward, batch)))) full_batch, obs, acts, reward_bound = filter_batch(full_batch + batch, PERCENTILE)ifnot full_batch: ##如果没有比较好的 episode,跳过continue obs_v = torch.FloatTensor(np.vstack(obs)) acts_v = torch.LongTensor(acts) full_batch = full_batch[-500:] optimizer.zero_grad() action_scores_v = net(obs_v) loss_v = objective(action_scores_v, acts_v) loss_v.backward() optimizer.step() print("%d: loss=%.3f, rw_mean=%.3f, ""rw_bound=%.3f, batch=%d" % ( iter_no, loss_v.item(), reward_mean, reward_bound, len(full_batch))) writer.add_scalar("loss", loss_v.item(), iter_no) writer.add_scalar("reward_mean", reward_mean, iter_no) writer.add_scalar("reward_bound", reward_bound, iter_no) env.close()if reward_mean > 0.8: print("Solved!")break writer.close()可以看到在大约 10000 步之后 reward 就停在 0.5 左右,不再上升了,效果不是很好:
如果将打滑的设定去掉,学习的速度就显著加快(只需要 100 个 batch 左右),并且效果也好很多:
env = DiscreteOneHotWrapper(gym.make("FrozenLake-v1", is_slippery=False))