摘要:前文拆解了TaskGroup和ParkingLot。本文转向TaskControl——bthread的全局协调器,管理所有TaskGroup和worker pthread。tag分组实现调度隔离,工作窃取通过质数偏移均匀分布,动态伸缩按需创建worker,延迟删除避免与steal_task竞态。
在前面的文章中,我们自底向上拆解了 bthread 调度系统的关键组件:ParkingLot(第十四篇)提供 worker 的挂起/唤醒原语,TaskGroup(第十三篇)是单个 worker 的调度引擎,TaskMeta(第十二篇)是每个 bthread 的核心数据结构。
现在我们来到这些组件的顶层协调者——TaskControl。
TaskControl 是 bthread 调度系统的全局单例,管理所有 TaskGroup 和 worker pthread。它负责创建和销毁 worker、协调工作窃取、分发唤醒信号、动态伸缩线程池,以及通过 bvar 暴露监控指标。如果把 TaskGroup 比作引擎,ParkingLot 比作齿轮,那 TaskControl 就是整台机器的控制系统——它决定启动多少引擎、如何分配任务、何时加减马力。
一、TaskControl 概览
TaskControl (全局单例) ┌────────────────────────────────────────────────────────────────────┐ │ │ │ tag 0 tag 1 │ │ ┌─────────────────────┐ ┌─────────────────────┐ │ │ │ TaskGroup[0] │ │ TaskGroup[N] │ │ │ │ TaskGroup[1] │ │ TaskGroup[N+1] │ │ │ │ ... │ │ ... │ │ │ │ ParkingLot[0..M] │ │ ParkingLot[0..M] │ │ │ │ PriorityQ[0] │ │ PriorityQ[1] │ │ │ └─────────────────────┘ └─────────────────────┘ │ │ │ │ _concurrency = 所有 worker 总数 │ │ _workers[] = 所有 pthread_t │ │ _cpus[] = CPU 亲和性配置 │ │ _nbthreads = 存活 bthread 总数 │ └────────────────────────────────────────────────────────────────────┘
TaskControl 的核心职责:
- worker 生命周期管理:创建、绑定 CPU、启动、停止、join worker pthread
- TaskGroup 注册与管理:将 TaskGroup 按 tag 分组存储,支持动态添加和移除
- 工作窃取协调:
steal_task 从其他 TaskGroup 的队列中窃取任务 - 信号唤醒:
signal_task 通过 ParkingLot 唤醒空闲 worker - 动态伸缩:
add_workers 按需添加 worker,_destroy_group 安全移除 - tag 调度隔离:不同 tag 的 TaskGroup 分组管理,互不干扰
- bvar 监控:CPU 利用率、上下文切换次数、信号次数、队列状态等
二、数据结构
2.1 核心成员字段
class TaskControl { // === tag 分组管理 === std::vector<butil::atomic<size_t>> _tagged_ngroup; // 每个 tag 的 TaskGroup 数量 std::vector<TaggedGroups> _tagged_groups; // 每个 tag 的 TaskGroup 数组 butil::Mutex _modify_group_mutex; // 保护分组修改 // === 全局状态 === butil::atomic<bool> _init; // 是否已完成初始化 bool _stop; // 是否正在停止 butil::atomic<int> _concurrency; // worker pthread 总数 std::vector<pthread_t> _workers; // 所有 worker 线程 ID std::vector<unsigned> _cpus; // CPU 亲和性核心列表 butil::atomic<int> _next_worker_id; // 递增的 worker ID // === 全局 bvar 监控 === bvar::Adder<int64_t> _nworkers; // 活跃 worker 总数 bvar::Adder<int64_t> _nbthreads; // 存活 bthread 总数 // ... 更多 bvar 指标 // === 按 tag 的 bvar 监控 === std::vector<bvar::Adder<int64_t>*> _tagged_nworkers; std::vector<bvar::Adder<int64_t>*> _tagged_nbthreads; // ... // === 优先级队列 === bool _enable_priority_queue; std::vector<WorkStealingQueue<bthread_t>> _priority_queues; // === ParkingLot === size_t _pl_num_of_each_tag; std::vector<TaggedParkingLot> _tagged_pl;};
字段按功能分为六组。_tagged_ngroup 和 _tagged_groups 实现 tag 分组——每个 tag 维护自己的 TaskGroup 数组和计数器。_modify_group_mutex 保护这两个字段的并发修改。
2.2 TaggedGroups 类型
typedef std::array<TaskGroup*, BTHREAD_MAX_CONCURRENCY> TaggedGroups;// BTHREAD_MAX_CONCURRENCY = 1024
每个 tag 有一组 ParkingLot。多个 TaskGroup 可以共享同一个 ParkingLot(通过 _pl_num_of_each_tag 控制)。ParkingLot 的数量通常少于 TaskGroup 的数量,减少 futex 管理开销。
三、初始化
intTaskControl::init(int concurrency){ if (_concurrency != 0) return -1; // 已初始化 if (concurrency <= 0) return -1; // 参数非法 _concurrency = concurrency; // 1. 解析 CPU 亲和性配置 if (!FLAGS_cpu_set.empty()) { parse_cpuset(FLAGS_cpu_set, _cpus); } // 2. 初始化 tag 分组、bvar、优先级队列 for (int i = 0; i < FLAGS_task_group_ntags; ++i) { _tagged_ngroup[i].store(0); // 初始化 bvar、优先级队列... } // 3. 确保全局 TimerThread 已启动 get_or_create_global_timer_thread(); // 4. 创建 worker pthread(round-robin 分配 tag) _workers.resize(_concurrency); for (int i = 0; i < _concurrency; ++i) { auto arg = new WorkerThreadArgs(this, i % FLAGS_task_group_ntags); pthread_create(&_workers[i], NULL, worker_thread, arg); } // 5. 等待所有 tag 都有至少一个 TaskGroup for (int i = 0; i < FLAGS_task_group_ntags;) { if (_tagged_ngroup[i].load() == 0) { usleep(100); continue; } ++i; } _init.store(true); return 0;}
初始化流程分为五步:
步骤 1:解析 CPU 亲和性。--cpu_set 配置(如 "0-3,5,7")指定 worker 可以绑定的 CPU 核心。
步骤 2:按 tag 初始化。FLAGS_task_group_ntags 控制分组数量。每个 tag 有独立的 TaskGroup 数组、bvar 指标和优先级队列。
步骤 3:启动 TimerThread。 bthread_usleep 和 butex 超时依赖全局定时器线程(第十篇)。
步骤 4:创建 worker。 tag 通过 i % ntags 轮询分配——worker 0 分配 tag 0,worker 1 分配 tag 1,依此类推。每个 worker 在 worker_thread 中创建自己的 TaskGroup。
步骤 5:等待就绪。 确保所有 tag 至少有一个 TaskGroup 注册,这样 choose_one_group() 不会返回 NULL。这是一个同步点——init() 在所有 worker 启动后才返回。
四、worker_thread:worker 入口函数
void* TaskControl::worker_thread(void* arg){ run_worker_startfn(); // 用户启动回调 auto dummy = static_cast<WorkerThreadArgs*>(arg); auto c = dummy->c; auto tag = dummy->tag; delete dummy; // 参数使用后立即释放 run_tagged_worker_startfn(tag); // 带 tag 的启动回调 // 创建 TaskGroup(1:1 绑定) TaskGroup* g = c->create_group(tag); g->_tid = pthread_self(); // 分配 worker ID,绑定 CPU,设置线程名 int worker_id = c->_next_worker_id.fetch_add(1); if (!c->_cpus.empty()) { bind_thread_to_cpu(pthread_self(), c->_cpus[worker_id % c->_cpus.size()]); } if (FLAGS_task_group_set_worker_name) { // 线程名如 "brpc_wkr:0-1"(tag-worker_id) } tls_task_group = g; // 设置线程局部指针 c->_nworkers << 1; // 全局计数 +1 c->tag_nworkers(g->tag()) << 1; // tag 计数 +1 g->run_main_task(); // 进入主调度循环(阻塞) // 退出清理 tls_task_group = NULL; g->destroy_self(); c->_nworkers << -1; c->tag_nworkers(g->tag()) << -1; return NULL;}
pthread_create │ ▼ worker_thread() │ create_group(tag) → new TaskGroup → init → _add_group │ bind CPU / set name │ run_main_task() ← 阻塞在这里,调度 bthread │ destroy_self() ← worker 停止后清理 │ ▼ pthread_join
每个 worker 与一个 TaskGroup 一一绑定。create_group 创建 TaskGroup 并注册到 TaskControl 的 tag 分组中。run_main_task() 是调度主循环(第十三篇),worker 在这里不断等待任务、切换执行,直到被停止。
CPU 绑定使用 worker_id % _cpus.size() 取模——worker 数量可能超过 CPU 核心数,取模确保均匀分布。
五、TaskGroup 的注册与移除
5.1 create_group + _add_group
TaskGroup* TaskControl::create_group(bthread_tag_t tag) { TaskGroup* g = new TaskGroup(this); g->init(FLAGS_task_group_runqueue_capacity); // 初始化队列(容量 4096) _add_group(g, tag); return g;}
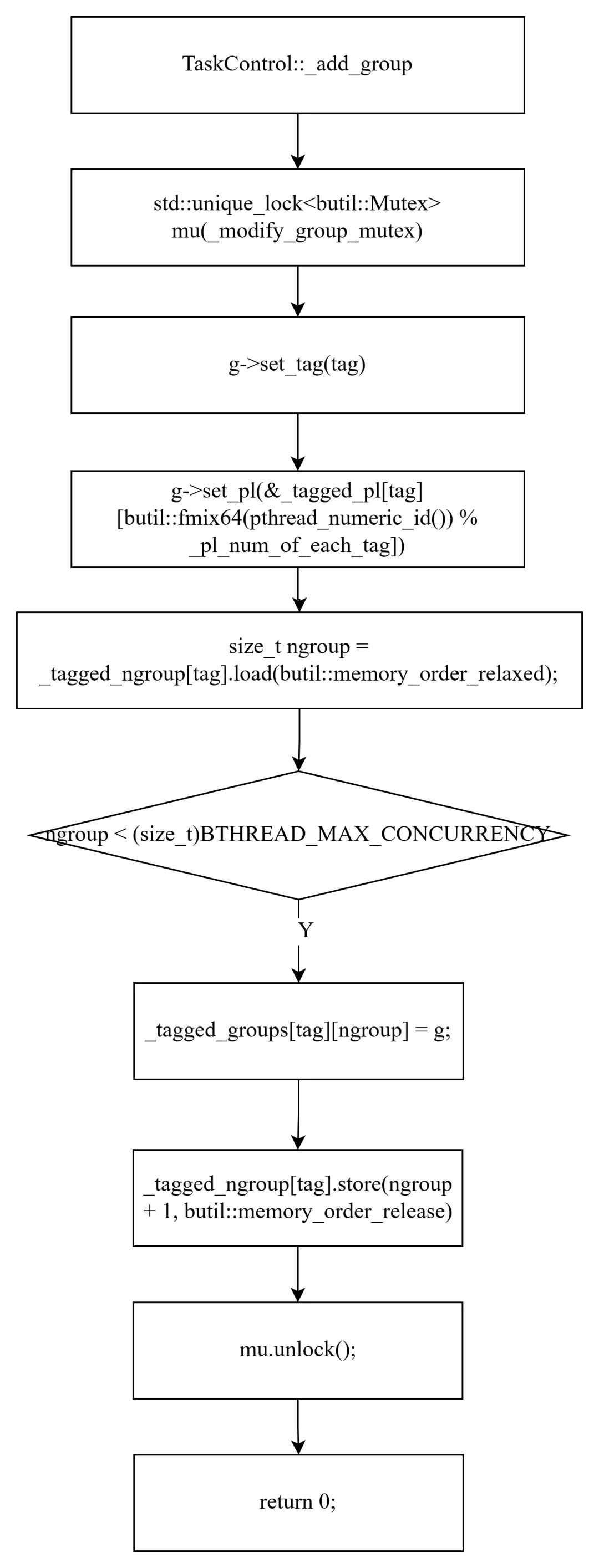
int TaskControl::_add_group(TaskGroup* g, bthread_tag_t tag) { std::unique_lock<butil::Mutex> mu(_modify_group_mutex); if (_stop) return -1; g->set_tag(tag); // 基于 pthread ID 哈希选择 ParkingLot g->set_pl(&_tagged_pl[tag][fmix64(pthread_numeric_id()) % _pl_num_of_each_tag]); size_t ngroup = _tagged_ngroup[tag].load(); if (ngroup < BTHREAD_MAX_CONCURRENCY) { _tagged_groups[tag][ngroup] = g; // 先写数组 _tagged_ngroup[tag].store(ngroup + 1, memory_order_release); // 再更新计数 } return 0;}
注册流程的关键设计:
1. ParkingLot 分配。 通过 fmix64(pthread_numeric_id()) % _pl_num_of_each_tag 选择 ParkingLot。多个 TaskGroup 可能共享同一个 ParkingLot,但通过哈希尽量分散。
2. 先写数组,再更新计数。 这保证了 steal_task 遍历时的安全性——如果 steal_task 看到最新的 ngroup,对应的 groups[i] 已经设置好了。memory_order_release 确保 groups 的写入在 ngroup 更新之前对其他线程可见。
3. 互斥锁保护。_modify_group_mutex 保证 _add_group 和 _destroy_group 互斥执行。但 steal_task 不加锁——通过原子操作和写入顺序来保证无锁读取的安全性。
5.2 _destroy_group:延迟删除
int TaskControl::_destroy_group(TaskGroup* g) { bool erased = false; { BAIDU_SCOPED_LOCK(_modify_group_mutex); auto tag = g->tag(); auto& groups = tag_group(tag); size_t ngroup = tag_ngroup(tag).load(); for (size_t i = 0; i < ngroup; ++i) { if (groups[i] == g) { // 将末尾元素交换到被移除位置 groups[i] = groups[ngroup - 1]; tag_ngroup(tag).store(ngroup - 1, memory_order_release); erased = true; break; } } } // 延迟删除:通过 TimerThread 在 1 秒后执行 delete if (erased) { get_global_timer_thread()->schedule( delete_task_group, g, microseconds_from_now(FLAGS_task_group_delete_delay * 1000000L)); } return 0;}
_destroy_group 有两个精巧的设计:
1. 末尾交换法 O(1) 移除。 将数组末尾的 TaskGroup 移到被移除位置,然后递减 ngroup。这保证了 steal_task 的安全性:
- 如果
steal_task 看到最新的 ngroup(已递减),不会访问被移除的位置 - 如果
steal_task 看到旧的 ngroup,末尾元素已经被交换到前面,不会遗漏
2. 延迟删除。 不立即 delete TaskGroup,而是通过 TimerThread 延迟 1 秒(FLAGS_task_group_delete_delay)执行。因为 steal_task 不加锁,可能还在访问被移除的 TaskGroup,延迟删除确保所有并发的 steal_task 都已完成。
六、steal_task:工作窃取
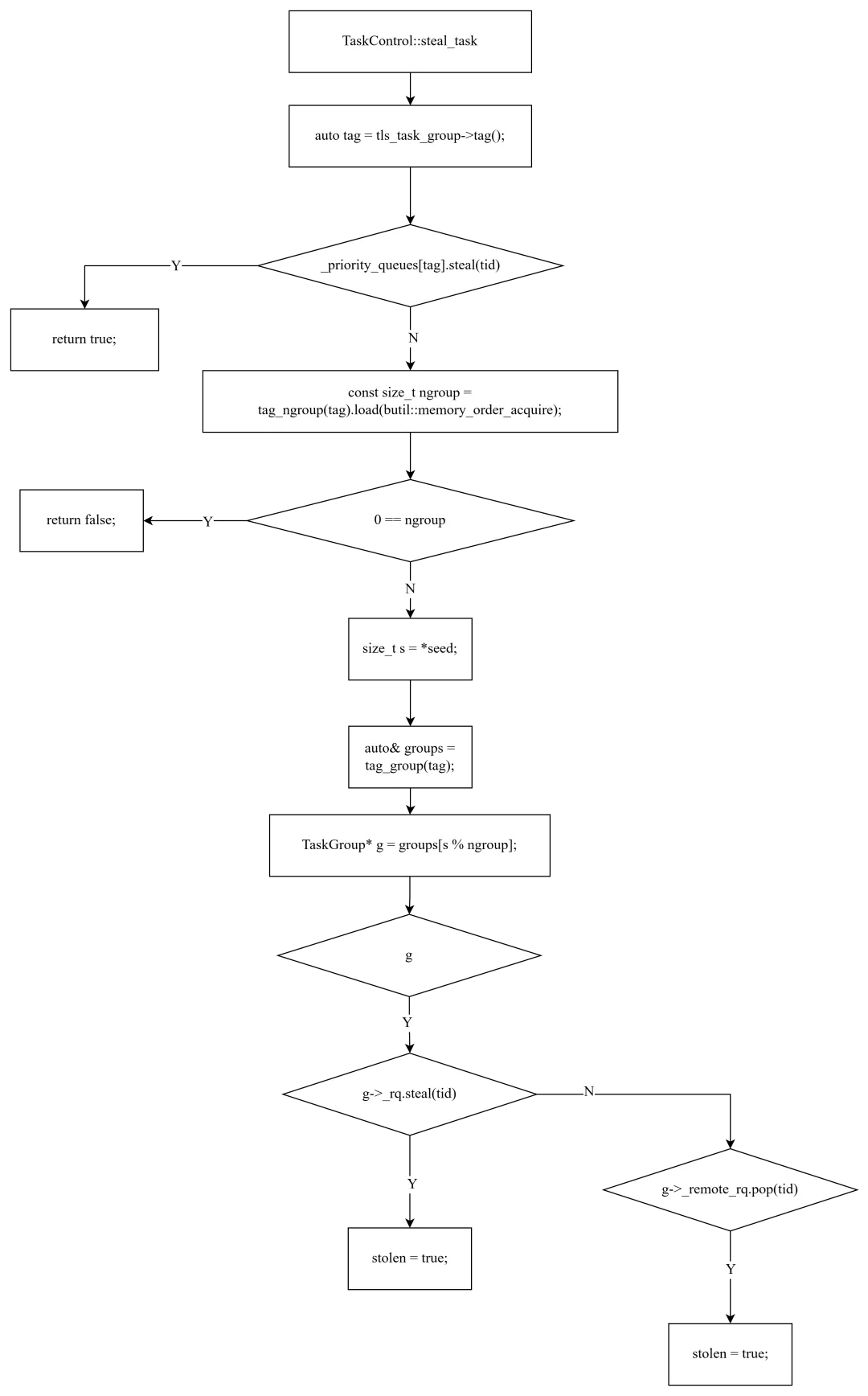
boolTaskControl::steal_task(bthread_t* tid, size_t* seed, size_t offset){ auto tag = tls_task_group->tag(); // 1. 优先从全局优先级队列窃取 if (_priority_queues[tag].steal(tid)) { return true; } // 2. 遍历同 tag 的其他 TaskGroup const size_t ngroup = tag_ngroup(tag).load(memory_order_acquire); if (0 == ngroup) return false; bool stolen = false; size_t s = *seed; auto& groups = tag_group(tag); for (size_t i = 0; i < ngroup; ++i, s += offset) { TaskGroup* g = groups[s % ngroup]; if (g) { if (g->_rq.steal(tid)) { // 无锁本地队列 stolen = true; break; } if (g->_remote_rq.pop(tid)) { // 有锁远程队列 stolen = true; break; } } } *seed = s; return stolen;}
窃取策略分三层:
第一层:全局优先级队列。 每个 tag 有一个 WorkStealingQueue 作为优先级队列。高优先级 bthread 被放入这个队列,窃取时优先从这里获取。WorkStealingQueue 的 push 从尾部插入,steal 从头部窃取——这确保了高优先级任务先被窃取。
第二层:本地无锁队列(_rq)。 使用 steal 操作从目标 TaskGroup 的 WorkStealingQueue 头部窃取。这是最高效的窃取方式,不需要锁。
第三层:远程有锁队列(_remote_rq)。 如果 _rq 窃取失败,再尝试从 _remote_rq 弹出任务。远程队列有锁保护,是备选方案。
质数偏移遍历
for (size_t i = 0; i < ngroup; ++i, s += offset) { TaskGroup* g = groups[s % ngroup];
offset 是一个质数,s 从随机种子开始每次加 offset。质数步长的特性:当 offset 与 ngroup 互质时,s % ngroup 会均匀覆盖所有位置。这避免了多个 worker 从同一个位置开始窃取,减少竞争热点。
窃取范围限制在同 tag 的 TaskGroup 内——这是 tag 隔离的体现。不同 tag 的任务互不窃取,确保调度隔离。
七、signal_task:唤醒空闲 worker
voidTaskControl::signal_task(int num_task, bthread_tag_t tag){ if (num_task <= 0) return; if (num_task > 2) num_task = 2; // 限制最大唤醒数 // 轮询 ParkingLot,逐一唤醒 auto& pl = tag_pl(tag); size_t start_index = fmix64(pthread_numeric_id()) % _pl_num_of_each_tag; for (size_t i = 0; i < _pl_num_of_each_tag && num_task > 0; ++i) { num_task -= pl[start_index].signal(1); if (++start_index >= _pl_num_of_each_tag) start_index = 0; } // 仍有未唤醒任务 → 动态添加 worker if (num_task > 0 && FLAGS_bthread_min_concurrency > 0 && _concurrency.load() < FLAGS_bthread_concurrency) { BAIDU_SCOPED_LOCK(g_task_control_mutex); if (_concurrency.load() < FLAGS_bthread_concurrency) { add_workers(1, tag); } }}
信号唤醒的三层策略:
1. 限制最大唤醒数。num_task 上限为 2。这是性能与调度及时性的平衡——过度唤醒会导致 worker 醒来后发现没有任务,白白浪费 CPU。
2. 轮询 ParkingLot。 从随机位置开始,遍历该 tag 下的所有 ParkingLot,每个调用 signal(1) 唤醒一个 worker。遍历到所有需求满足或 ParkingLot 用尽为止。
3. 动态添加 worker。 如果所有 ParkingLot 都没有等待者(worker 全部繁忙),且当前并发数未达上限,则动态创建一个新的 worker。这是一种自适应策略——在负载高峰时自动增加处理能力。
为什么使用全局互斥锁 g_task_control_mutex?add_workers 会修改 _workers 向量,需要与其他可能的并发操作互斥。double-check(先检查再加锁再检查)减少锁竞争。
八、add_workers:动态伸缩
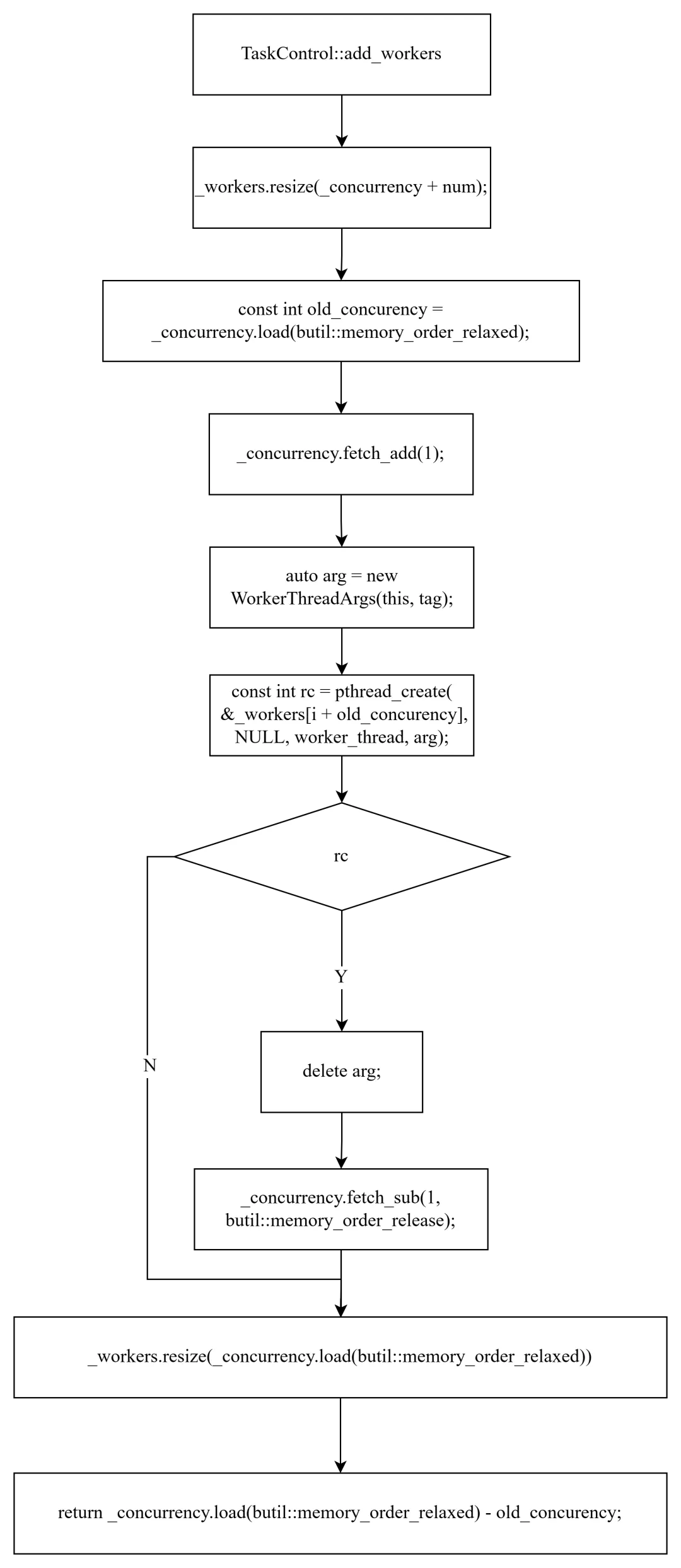
intTaskControl::add_workers(int num, bthread_tag_t tag){ _workers.resize(_concurrency + num); // 扩容 const int old_concurrency = _concurrency.load(); for (int i = 0; i < num; ++i) { _concurrency.fetch_add(1); // 先递增(worker 启动后可能立即检查) auto arg = new WorkerThreadArgs(this, tag); if (pthread_create(&_workers[i + old_concurrency], NULL, worker_thread, arg)) { delete arg; _concurrency.fetch_sub(1); // 创建失败,回退 break; } } _workers.resize(_concurrency.load()); // 调整为实际大小 return _concurrency.load() - old_concurrency;}
动态伸缩的关键设计:
1. 先递增并发数。_concurrency 在 pthread_create 之前递增。因为 worker 启动后可能立即检查并发数(例如 _control->concurrency()),提前递增确保新 worker 看到正确的值。
2. 失败回退。pthread_create 可能失败(系统资源不足),此时递减 _concurrency 并跳出循环。
3. 返回实际添加数。 由于创建可能部分失败,返回值可能小于请求的 num。调用者(signal_task)需要据此判断是否需要重试。
九、choose_one_group:选择 TaskGroup
TaskGroup* TaskControl::choose_one_group(bthread_tag_t tag){ auto& groups = tag_group(tag); const auto ngroup = tag_ngroup(tag).load(memory_order_acquire); if (ngroup != 0) { return groups[fast_rand_less_than(ngroup)]; // 均匀随机 } CHECK(false) << "Impossible: ngroup is 0"; return NULL;}
choose_one_group 用于任务分发——当一个非 worker 线程(或 bthread)需要将新任务提交到某个 TaskGroup 时,通过随机选择实现负载均衡。init() 保证所有 tag 至少有一个 TaskGroup,因此 ngroup 不为 0。
使用 fast_rand_less_than 而非 rand()——前者基于 xorshift,速度更快且不需要锁。
十、stop_and_join:优雅停止
voidTaskControl::stop_and_join(){ // 1. 停止 epoll 线程 stop_and_join_epoll_threads(); // 2. 设置 _stop 标志,ngroup 归零 { BAIDU_SCOPED_LOCK(_modify_group_mutex); _stop = true; std::for_each(_tagged_ngroup.begin(), _tagged_ngroup.end(), [](atomic<size_t>& idx) { idx.store(0, memory_order_relaxed); }); } // 3. 停止所有 ParkingLot for (int i = 0; i < FLAGS_task_group_ntags; ++i) { for (auto& pl : _tagged_pl[i]) { pl.stop(); // 设置 stop 标志 + futex_wake } } // 4. 中断所有 worker 的阻塞系统调用 for (auto worker : _workers) { interrupt_pthread(worker); // pthread_kill 发送信号 } // 5. 等待所有 worker 退出 for (auto worker : _workers) { pthread_join(worker, NULL); }}
停止流程分五步,每步都有明确的目的:
步骤 1:先停 epoll。 worker 可能阻塞在 epoll_wait 上,这不受 ParkingLot 的 futex 控制。必须先关闭 epoll fd,让 epoll_wait 返回错误。
步骤 2:设置标志 + 归零 ngroup。_stop = true 阻止新的 _add_group。ngroup 归零阻止新的 steal_task——看到 ngroup == 0 的 worker 会认为没有可窃取的任务。
步骤 3:停止 ParkingLot。 调用每个 ParkingLot 的 stop()(第十四篇),设置 stop 标志并唤醒所有等待的 worker。被唤醒的 worker 在 wait_task 中检测到 stopped() 返回 true,退出主循环。
步骤 4:中断阻塞。interrupt_pthread 发送信号中断可能阻塞在系统调用(如 usleep)上的 worker。
步骤 5:join。 等待所有 worker 线程退出,确保资源释放。
十一、tag 分组与调度隔离
tag 是 TaskControl 中重要的调度隔离机制:
tag 0 (默认): tag 1 (自定义): TaskGroup[0] ← worker 0 TaskGroup[4] ← worker 4 TaskGroup[1] ← worker 1 TaskGroup[5] ← worker 5 TaskGroup[2] ← worker 2 TaskGroup[3] ← worker 3 窃取范围: tag 0 内部 窃取范围: tag 1 内部 ParkingLot: tag 0 独有 ParkingLot: tag 1 独有 优先级队列: tag 0 独有 优先级队列: tag 1 独有
tag 的作用:
1. 调度隔离。steal_task 只在同 tag 的 TaskGroup 之间窃取。不同 tag 的任务不会互相干扰——一个 tag 的任务激增不会影响另一个 tag 的调度延迟。
2. 独立监控。 每个 tag 有独立的 bvar 指标(worker 数量、bthread 数量、CPU 利用率),便于按业务分组监控。
3. 独立资源。 每个 tag 有自己的 ParkingLot 数组和优先级队列,避免跨 tag 的锁竞争。
4. round-robin 分配。init() 中 worker 的 tag 通过 i % ntags 轮询分配,确保 tag 之间的 worker 数量均匀。
十二、bvar 监控体系
TaskControl 通过 bvar 暴露丰富的监控指标:
| | |
|---|
bthread_worker_count | | |
bthread_count | | |
bthread_worker_usage | | |
bthread_switch_second | | |
bthread_signal_second | | |
bthread_creation | | |
bthread_group_status | | |
按 tag 的指标通过后缀区分(如 bthread_worker_count_0、bthread_worker_count_1)。
for_each_task_group 模板函数是监控的基础设施——它遍历所有 tag 下的所有 TaskGroup,对每个执行回调。在 init() 完成前直接返回,避免 bvar 在初始化阶段触发问题。
十三、总结
TaskControl 的设计可以归纳为一句话:全局单例协调器,按 tag 分组管理 TaskGroup,通过工作窃取实现负载均衡,动态伸缩适应负载变化,延迟删除保证无锁窃取的安全性。
六个关键设计:
1. tag 分组隔离。 所有 TaskGroup 按 tag 分组存储,窃取、唤醒、监控都在 tag 内部完成。round-robin 分配 worker 到 tag,确保负载均匀。
2. 无锁窃取 + 加锁修改。steal_task 不加锁,通过原子操作读取 ngroup 和 groups 数组。_add_group 和 _destroy_group 加锁修改。先写数组再更新计数的顺序保证窃取安全。
3. 末尾交换 O(1) 移除 + 延迟删除。_destroy_group 将末尾元素交换到被移除位置,O(1) 完成。通过 TimerThread 延迟 1 秒删除,确保并发的 steal_task 已经完成。
4. 质数偏移窃取。steal_task 使用质数步长遍历 TaskGroup 数组,确保均匀分布。多个 worker 不会集中窃取同一个 TaskGroup。
5. 三层唤醒策略。signal_task 先轮询 ParkingLot 唤醒空闲 worker,唤醒数上限为 2。如果全部繁忙且并发数未达上限,动态添加新 worker。
6. 优雅停止五步流程。 停 epoll → 设置标志 + 归零 ngroup → 停 ParkingLot → 中断阻塞 → join。每步处理不同类型的阻塞,确保所有 worker 都能及时退出。
本文基于 Apache brpc 源码(src/bthread/task_control.h、src/bthread/task_control.cpp)撰写。