Unidbg学习笔记(十八):从模拟调用到算法还原
- 2026-04-29 10:01:17
大多数人用 Unidbg 停在“能调出结果”这一步。但 Unidbg 的终极价值不是“替你调 SO 函数”,而是“帮你理解 SO 函数在做什么”。这一篇讲怎么把 Unidbg 从“RPC 替代品”升级为“白盒分析工作台”,最终不再依赖原始 SO.
上一篇把你留在了哪里
到这里,你已经有了完整的工具箱:模拟调用、Trace、Console Debugger、Hook 框架。每一个工具都解决一个具体问题。
但真正的高手,不是“工具最多的那个”,而是能把多个工具组合起来解决一个大问题的那个。这一篇就讲一个大问题 —— 如何用 Unidbg 把一个加密 SO 从“会调用”提升到“能重写”。
这是逆向工程的最高境界:脱离 SO 依赖。为什么重要?
性能:用 Go / Rust / C 直接实现或调用本地密码库(OpenSSL、BoringSSL),比走 Unidbg 快一个数量级以上;纯 Python 实现不一定比 Unidbg 快(Unicorn 有 JIT),但只要调用 PyCryptodome / cryptography 这类原生库就能反超 部署:不再需要携带 SO 和模拟器,一个 pure 程序就能跑 迭代:SO 升级时,你只需要分析 diff 部分,而不是重跑整个模拟 尊严:逆向的终极目标不是“让它跑起来”,而是“我真正理解了它”
会用的三个层次
从黑盒调用到白盒还原的三个层次
在进入方法论之前,先澄清一个认知 —— 你对一个 SO 函数的“会用”,其实有三个层次:
层次 1:黑盒调用
你知道函数的签名(入参、出参),能把数据塞进去拿出结果。内部发生了什么,一概不知。
DvmClass clazz = vm.resolveClass("com/x/sign");byte[] result = (byte[]) clazz .callStaticJniMethodObject(emulator, "doSign([B)[B", input) .getValue();能做到这一步 = Unidbg 入门。这是大部分人停留的地方。
问题:你变成了 SO 的搬运工。SO 下次版本更新,你还得重来;SO 对环境检测越来越严,你不知道该补哪里;没有 SO 的纯 Python 环境里你完全无能为力。
层次 2:灰盒理解
你知道函数大致在做什么:“噢,它用了 AES, CBC 模式,密钥是从某处来的,IV 是常量,Padding 是 PKCS7”。但具体到每一轮的变化、密钥扩展的细节,你说不清楚。
能做到这一步 = 可以做部分优化。比如用 Python 的 PyCryptodome 做大部分加密,只在涉及密钥派生的那一步用 Unidbg.
层次 3:白盒还原
你完全用自己的代码重写整个算法,不再依赖 SO。你的 Python 代码和 SO 的输出比特级一致。
能做到这一步 = 你理解了这段代码。而这正是 Unidbg 真正要帮你达到的终点。
从层次 1 到层次 3, Unidbg 是唯一好用的桥梁 —— 因为它既能调用,又能 Trace,又能 Hook,又能做参照基准。没有哪个真机工具能同时做到这四件事。
还原算法的五步工作流
算法还原五步工作流
这是我分析一个加密 SO 函数的标准流程。它不是“按步骤执行就能搞定”,而是五个螺旋推进的阶段——加上一个"开门第一步",我习惯叫它 Step 0。
步骤 0:先看输出长度做个先验猜测
在打开 IDA、跑 Trace 之前,只看一眼输入输出的字节数就能把候选算法范围砍掉 80%。这一步不需要任何工具,纯靠经验:
0x04 头) | ||
输入也要看。如果业务函数声称"对任意长度字符串签名"输出却是固定 32 字节,那肯定是 hash 类(普通对称加密输出长度跟输入相关);如果输出是 256 / 384 / 512 字节这种"非 2 的幂的整字节倍数"且字节分布看起来均匀随机(没有规律、没有 ASCII、没有重复段),几乎可以锁死 RSA(长度等于公钥位数 / 8,即 2048 / 3072 / 4096)。
这一步用一句话画到笔记本上:
"长度先验:输入变长 + 输出 32 字节 = SHA-256 嫌疑;输入变长 + 输出 128/256 字节 = RSA 嫌疑;输入定长 + 输出同长 = 对称分组算法。"
带着这个先验进入 Step 1,你的 Trace、搜常量、Hook 全都会更有针对性。
步骤 1: Trace 记录完整指令流
第一件事不是看 IDA,而是 Trace 一次:
emulator.traceCode(module.base, module.base + module.size);// 执行一次目标函数byte[] result = invokeSignFunction(input);这会产出一个几十 MB 的 trace.log,里面有从进入函数到返回的每一条指令。这个文件是你接下来的主要工作对象。
为什么先 Trace? 因为它不会漏 —— IDA 可能因为间接跳转、动态加载漏掉某些路径,Trace 不会。你得到的是“这次运行真实走过的路”。
步骤 2:在 Trace 里搜算法常量
这一步是整个流程里最容易出惊喜的一步。绝大多数标准算法都有唯一的常量签名:
0x637c777b / 0x7c77_7bf2 | grep 637c777b trace.log | |
0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476 | grep 67452301 trace.log | |
0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476, 0xc3d2e1f0 | grep c3d2e1f0 trace.log | |
0x6a09e667, 0xbb67ae85, ... | grep 6a09e667 trace.log | |
0x77073096, 0xee0e612c, ... | grep 77073096 trace.log | |
ABCDEFG... | grep "414243444546" trace.log | |
命中即确认。你在 trace 里看到 0x637c777b 这个魔数,几乎可以 100% 断定“这里是 AES”。
但光看字面“搜常量”还不够,得理解为什么标准算法的常量极难被混淆。这些常量不是随便挑的,它们是算法设计者为了让线性分析/差分分析失效而从数学空间里挑出来的——AES 的 S-Box 是 GF(2⁸) 上的有限域求逆再做仿射变换的结果,SHA-256 的 8 个 IV 是前 8 个素数平方根的小数部分取前 32 位,MD5 的 4 个 IV 是自然数 0123456789abcdef 的小端重排。一旦这些常量被改动,任何一个比特的偏移都会完全摧毁算法的安全性(因为混淆扩散性质是靠常量的代数结构保证的),所以即便是魔改版,设计者也通常只敢“换一整套”而不是“改几个比特”,因此标准常量几乎都会原样出现在二进制里。
我们把“常量”分成两类来理解混淆的可能性:
A-Za-z0-9+/ | 自定义 alphabet 很常见 |
没命中也不代表不是标准算法,可能的原因按常见度从高到低是:
常量被拆成字节逐个加载——ARM64 常见的是 movz x0, #0x777b+movk x0, #0x637c, lsl #16(低 16 位先用 movz 装载,高 16 位再用 movk 覆盖),最终x0 = 0x637c777b。直接搜637c777b就搜不到,但搜#0x777b/#0x637c的指令序列还在。应对办法是同时搜小端字节和搜 movz/movk 立即数模式,两条路一起走。常量在 .rodata里,被ldr x0, [pc, #offset]间接加载——这时 Trace 只记录ldr指令和x0的最终值,看不到数据读取路径。应对办法是**用指令 Trace 的寄存器列,直接搜寄存器值出现过0x637c777b**,而不是搜指令文本。算法被魔改过,常量本身被换——比如自定义 S-Box。这时靠搜常量就抓不到了,只能走下一步的 Hook+对比。 编译器做了常量折叠——比如 0x637c777b ^ 0xdeadbeef被预先算成0xbd21c994,二进制里只看到后一个数。这种情况在重度优化的闭源 SO 里偶尔出现,很难光靠搜常量破解,只能借助下一步的动态 Hook 兜底。
实际操作时,我的习惯是写一个小脚本批量搜一遍所有已知算法的指纹常量,一次扫完再看命中了什么,比一个个 grep 快得多:
FINGERPRINTS = {"AES S-Box": ["637c777b", "7c777bf2"],"AES Inv S-Box": ["52096ad5"],"SHA-256 IV": ["6a09e667", "bb67ae85"],"MD5 IV": ["67452301", "efcdab89"],"ChaCha20 const": ["65787061", "6e642033"],"HMAC ipad": ["36363636"],"HMAC opad": ["5c5c5c5c"],}with open("trace.log") as f: text = f.read()for algo, patterns in FINGERPRINTS.items():for p in patterns:if p in text or p.upper() in text: print(f"HIT: {algo} via {p}")一次运行,90% 的标准算法就自己跳出来了。剩下的 10% 才需要去走下一步的 Hook。
对那 10% 还有一招——搜中间值反推:别只搜算法常量,搜你已经知道的某个具体值反向追踪。业务函数的输出、Frida 抓到的中间状态、SO 写到内存的任意 4 字节,都可以当锚点反搜 trace。比如你从输出里拿到某 4 字节是 CB 48 E5 43,当作 little-endian uint32 = 0x43e548cb,trace 里 grep 命中:
0x40013f5c: "eor r1, r2, r1" r2=0x7a56221e r1=0x39b36ad5 => r1=0x43e548cb接着 grep 0x7a56221e 和 0x39b36ad5 看它们怎么算出来的,一路反追到源头。这条路在魔改算法上特别有效——魔改能换常量、换不掉数学(同样输入永远算出同样输出),所以你手上拿到的输出本身就是天然的"探针"。
步骤 3:在关键地址 Hook, dump 中间数据
Trace 告诉你“代码走到了哪里”,但看不到“每一步的数据长什么样”。这就是 Hook 的用武之地。
但在写 Hook 之前,先解决一个更棘手的问题:关键地址到底怎么找?一个加密函数可能有几千条指令,你不可能每条都挂钩子。真正高效的“找关键地址”的方法论,从易到难有三条:
已知常量锚定法:在步骤 2 里搜常量命中后,直接在 IDA 里跳到那个地址,往上追几行看数据是从哪里读的、往下追几行看结果写到哪里——“读输入的地方”和“写输出的地方”往往就是你要的 Hook 点。比如搜到
0x637c777b在.rodata:0x4000,IDA 的交叉引用列表会告诉你哪几条ldr指令用了它,这些ldr的前后就是 AES 轮函数入口。IDA 循环结构识别法:一个加密算法的主干必然是循环——AES 是 10/12/14 轮,SHA-256 是 64 轮,MD5 是 64 步。在 IDA 的 Graph 视图里,带回边的块就是循环,循环体的起始地址就是“每轮循环的入口”,循环体的末尾就是“每轮循环的出口”。把 Hook 挂在循环出口,你就能 dump 到每一轮后的中间状态。识别循环最快的办法是看 IDA Graph 右侧缩略图,回边会画成明显的向上箭头。
Trace 二分法:前两条失效时(比如混淆样本把循环展开了),就用 Trace 二分。做法是:找一条明显的“输入到输出”的数据流,Trace 记录
x0(输入指针)和返回值,然后二分这段 Trace——在中间位置设一个 Hook,看寄存器里有没有“半成品”(已经变形的输入)。如果有,说明加密在前半段发生;如果没有,说明在后半段。递归往下切,3-4 次就能缩到一个几百指令的范围。
找到关键地址后,Hook 的写法就简单了。同一个函数通常会挂三种类型的 Hook:入口 Hook 看输入、循环出口 Hook 看每轮状态、返回 Hook 看输出。下面是一个完整的模板:
// Hook 1: 函数入口, 看输入长什么样hookZz.wrap(module.base + 0x1A00, new WrapCallback<HookZzArm64RegisterContext>() {@OverridepublicvoidpreCall(Emulator<?> emulator, HookZzArm64RegisterContext ctx, HookEntryInfo info){long inputAddr = ctx.getXLong(0);int inputLen = (int) ctx.getXLong(1);byte[] data = emulator.getBackend().mem_read(inputAddr, inputLen); System.out.println("[entry] input = " + Hex.encodeHexString(data)); }});// Hook 2: 循环出口, 看每轮循环后的中间状态(假设 x19 是 state 指针)hookZz.wrap(module.base + 0x1B40, new WrapCallback<HookZzArm64RegisterContext>() {privateint round = 0;@OverridepublicvoidpostCall(Emulator<?> emulator, HookZzArm64RegisterContext ctx, HookEntryInfo info){long bufAddr = ctx.getXLong(19);byte[] data = emulator.getBackend().mem_read(bufAddr, 16); System.out.println("[round " + (round++) + "] state = " + Hex.encodeHexString(data)); }});// Hook 3: 函数返回, 看最终输出hookZz.wrap(module.base + 0x1D80, new WrapCallback<HookZzArm64RegisterContext>() {@OverridepublicvoidpostCall(Emulator<?> emulator, HookZzArm64RegisterContext ctx, HookEntryInfo info){long outputAddr = ctx.getXLong(2); // 假设 x2 是输出指针byte[] data = emulator.getBackend().mem_read(outputAddr, 32); System.out.println("[exit] output = " + Hex.encodeHexString(data)); }});跑一次,你就得到了“输入 → 每轮状态 → 输出”的完整数据流。现在对比标准 AES 每轮的状态:
如果每一轮都完全一样 → 标准 AES,差别只在密钥,密钥就藏在 key schedule 里,挂个 key 相关的 Hook 就能 dump 出来。 如果前几字节一样,后面有偏差 → 魔改了 MixColumns 或 ShiftRows 的某一步,需要逐字节比对找出差异发生在哪个操作。 如果第一轮就完全不一样 → 可能是 S-Box 被换了,或者 AddRoundKey 用了异或以外的操作,需要回到 IDA 看指令本身。 如果前几轮对上,第 5 轮开始全错 → 典型的“轮数改变了”或“第 n 轮后插入了额外操作”,这是最常见的魔改手法之一。
步骤 4:对比标准实现,找出魔改部分
这一步是真正的算法分析,也是最考验耐心的一步。
假设你怀疑是魔改 AES。做法:
用一个标准 AES 实现 (Python PyCryptodome),给定相同的输入和密钥,记录它每一轮的中间状态 用 Unidbg + Hook 记录 SO 每一轮的中间状态 两组数据并排对比:
Round 1: std: 6363c6f8 6363c6f8 6363c6f8 6363c6f8 SO: 6363c6f8 6363c6f8 6363c6f8 6363c6f8 # 完全相同Round 2: std: 6a6dcbf6 6b6bcafa ... SO: 4a2d8b56 3b3b8aff ... # 开始偏离偏离的那一轮就是魔改发生的地方。然后你回到 IDA 看那一轮的代码,看看改了什么:
S-Box 变了? (对比 rodata 里的 256 字节) MixColumns 矩阵变了? (看常量) 轮密钥扩展变了? (看 key schedule 的代码) 顺序颠倒了? (SubBytes 和 ShiftRows 换了位置?)
重要:魔改通常只是“一两处小改动”,极少是“完全重写”。因为写一个全新的密码算法又安全又高效,普通开发者做不到。他们的魔改通常是改 S-Box 或改常量或打乱顺序,这些改动都是可识别的。
步骤 5:用高级语言重写,Unidbg 作为基准
现在你理解了算法,用 Python 把它重写一遍:
defcustom_aes_encrypt(data, key):# 用魔改后的 S-Box sbox = bytes.fromhex("63 7c 77 7b f2 ... 你 dump 出来的 S-Box ...")# 用魔改后的 MixColumns 矩阵 matrix = [...]# 完整实现 AES 的 10 轮 ...return ciphertextUnidbg 作为基准:
for i in range(100): test_input = random_bytes(16) expected = call_unidbg(test_input) actual = custom_aes_encrypt(test_input, KEY)assert expected == actual, f"diff at {i}"跑 100 次都一致 → 你的重写是对的。出一次不一致 → 回到步骤 4, 继续 diff.
为什么一定要和 Unidbg 对照,不和真机对照? 因为 Unidbg 是确定性的 —— 同样的输入永远产出同样的输出。真机上有线程、时间、内存扰动,结果不稳定,没法做严格对比。
一个省工作量的原则:还原前先扫一眼"算法复用"
做完一个签名的还原后别急着开下一个——先扫其他签名是否调用了同一个核心函数,可能省掉 50% 的重复工作。
反检测 SDK 暴露 N 个签名接口,背后往往只有 1-2 个核心算法。最典型的是抖音的"六神"接口(X-Argus / X-Gorgon / X-Helios / X-Khronos / X-Ladon / X-Medusa),看起来是 6 个独立签名,但实际上 X-Helios 和 X-Ladon **共用同一个核心函数 sub_4865C**——只是输入参数和后处理不同。还原 1 个 = 解决 2 个。
识别复用的最快方式:在 Trace 里看每个签名最终落到哪个 sub_xxxx。两个签名都跑到同一个 sub_xxxx,还原一次就够了。这条思路在面对"接口多但实际算法少"的反检测 SDK 时事半功倍——先识别复用,再决定还原顺序。
真正的难点:密钥追溯的 5 种姿势
到这里如果你以为"算法还原 = 把加密过程重写一遍"就完事了,那是因为还没踩过真正的坑。真实加密 SO 里 90% 的难度不在加密本身,而在密钥从哪里来。同样是 AES-128-CBC,密钥是硬编码的、还是每次设备唯一的、还是和服务器协商出来的,重写难度差一个量级。
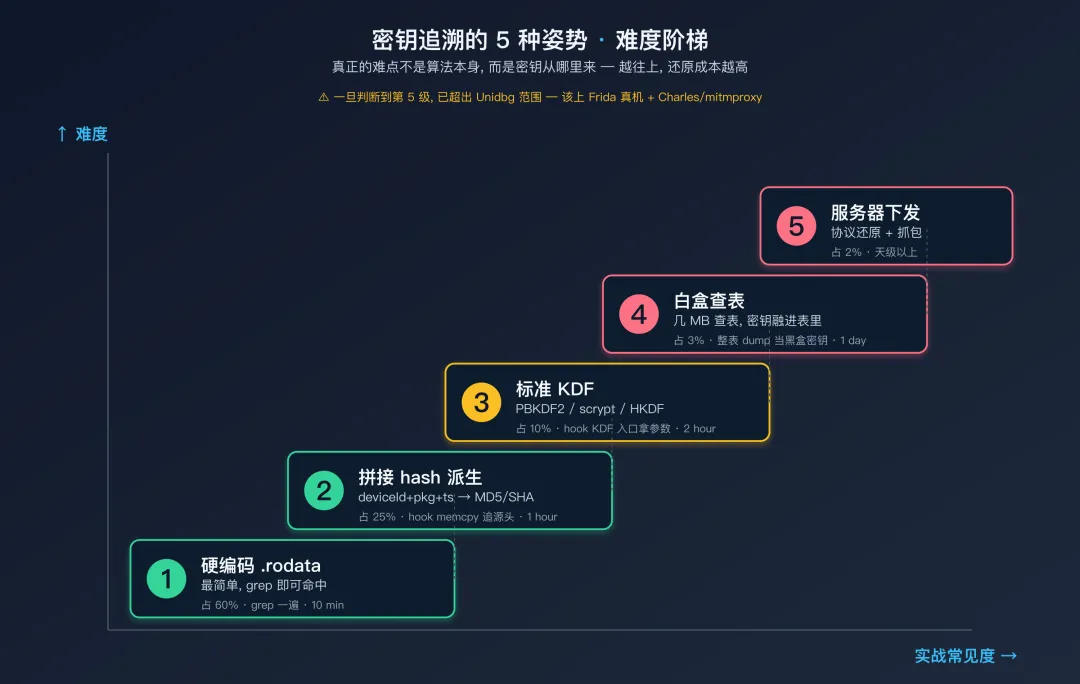
我把追过的密钥来源分成 5 类,从易到难:
姿势 1:硬编码在 .rodata
最简单的情形。密钥就是一段 16 / 32 字节的常量,编译进 SO。识别办法:
在 Hook 里把"刚加载完密钥还没开始扩展"那一刻的内存 dump 下来(通常在 AES key_schedule入口前)拿这串字节去 .rodata里 grep——命中了就是硬编码没命中,但你 dump 到的那串字节看起来很"工整"(全 ASCII / 全可打印 / 有规律),那也基本是硬编码
重写:直接把字节抄到你的 Python 代码里。
姿势 2:拼接 + hash 派生
很常见的反爬套路:把 deviceId + packageName + timestamp + 一串 salt 拼起来 MD5/SHA-256 一次,取前 16 字节做 AES key。
识别办法不在算法本身,在算法之前——往上追"key 这个指针的内容是从哪里写进来的"。具体做法是 Hook 算法入口拿到 key 指针,**再 Hook memcpy / strcpy / memmove**,过滤目标地址等于 key 指针的调用。这样你能抓到"这串 16 字节是谁写进去的",再往源头追一步通常就能看到 hash 的 finalize。
重写:在 Python 里把拼接顺序、salt、hash 算法复现一遍。最容易翻车的点是字符串顺序和编码——deviceId+pkg 还是 pkg+deviceId、UTF-8 还是 UTF-16-LE,差一个就全错。一定要拿至少 5 组真实输入对,每组都对上才算还原。
姿势 3:PBKDF2 / scrypt / HKDF 派生
更"专业"的 SO 会用标准 KDF。识别特征:
PBKDF2:内部循环上千次 HMAC(迭代次数常见 1000 / 10000 / 100000) scrypt:吃大块内存,能看到一片连续的 1MB+ 缓冲区被反复读写 HKDF:两段 HMAC(extract + expand),expand 阶段会循环输出多个 block
重写:这一类 KDF 都有标准库(hashlib.pbkdf2_hmac / cryptography.hazmat.primitives.kdf.hkdf),关键是把迭代次数、salt、info、output length 这 4 个参数抠出来。Hook 抓 KDF 函数入口的寄存器+栈就能拿到。
姿势 4:白盒密码学(密钥融进查表)
最棘手的一类。开源项目 Chow / WBAES 是典型,商用样本常见于支付、版权类 SO。特征:
.rodata里有几 MB 大小的查表(不是 256 字节的 S-Box,而是几百 KB 到几 MB)整个加密过程几乎全是 "查表 + 异或",看不到独立存在的"密钥"指针 同样的 SO 在不同设备上不会重新派生,但每个 SO 版本的查表是唯一的——因为密钥已经"烧"进表里了
重写策略:白盒还原是另一个大话题。在 Unidbg 的工作流里,可行的是把整套查表 dump 出来当成黑盒密钥——你不试图理解"原始密钥是什么",而是把"查表 + 计算流程"整体当成你的密钥。Python 实现把查表加载进来,按 SO 的查表顺序复现一遍。优点是能脱离 SO,缺点是你的 Python 代码也得带上几 MB 的查表。这通常是工程层面"够用"的解,真正学术意义上的还原(恢复原始 AES 密钥)需要专门的白盒攻击技术(BGE / 切片攻击),不在本篇范围。
姿势 5:JNI 回 Java 层 / 服务器下发
有时候你 Hook 算法入口拿到 key,往上追,发现 key 是 JNI CallStaticByteArrayMethod 从 Java 层返回的;再上一步可能还在 Kotlin 里调了一次 RSA 解密本地存储的 ciphertext;再上一步那个 ciphertext 是服务器下发的。
这时候"算法还原"已经变质成"协议还原"——你需要还原的不是加密算法,而是整条密钥下发链路。Unidbg 这一层的工作做完后,下一步该上 Charles / mitmproxy 抓服务器响应,或者直接 hook Java 层的 CallStaticObjectMethod(JNI 没有 CallStaticByteArrayMethod 这种细分 API,数组类型统一走 Object 系列,返回的 jobject 再 cast 成 jbyteArray 用 GetByteArrayElements 解开)看返回值。
实操优先级:先在 Unidbg 里把"native 接收到的 key 字节"打印出来,先确认这个 key 是否每次启动都一样。每次都一样 = 设备维度固定(追姿势 2 即可);每次启动变 = 协议维度动态(要走真机+抓包)。这一刀切下去能省好几天。
常见加密算法的指纹速查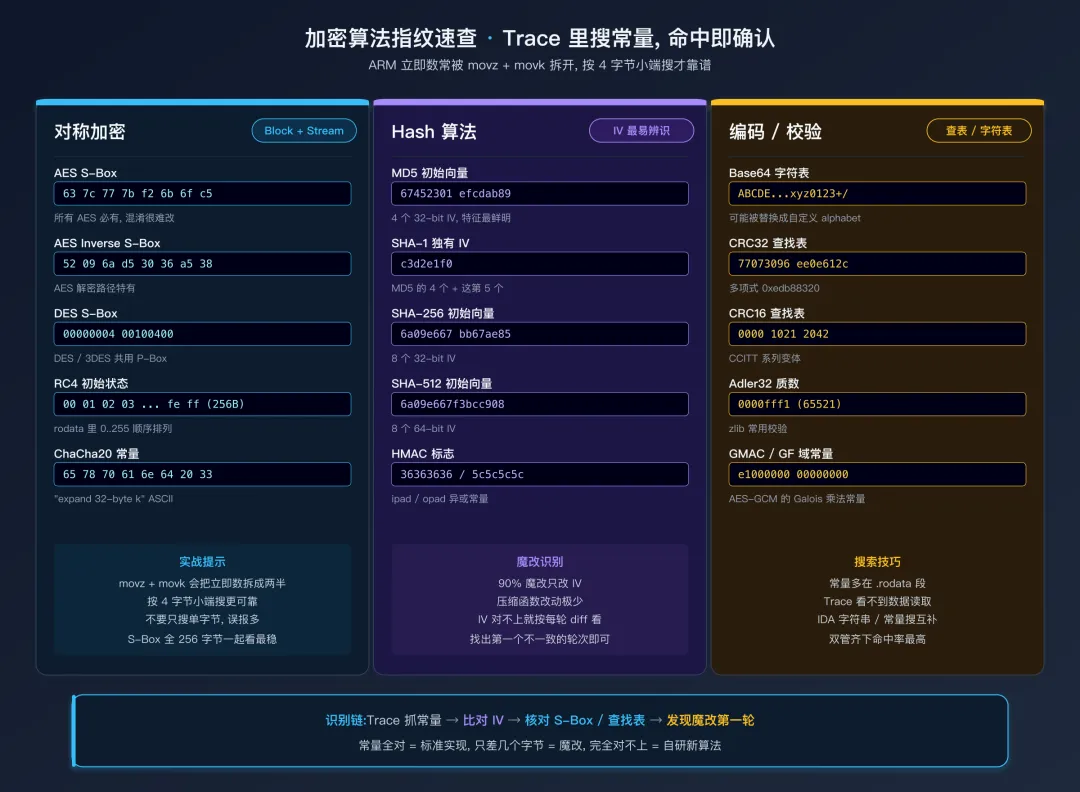
常见加密算法的 ARM 指令特征
下面这张表是我在分析过的样本里积累的“常量速查”,贴在你的分析手册里可以省很多时间:
对称加密
637c777b | ||
52096ad5 | ||
0001020304... | ||
65787061 6e642033 322d6279 7465206b |
Hash 算法
67452301 efcdab89 98badcfe 10325476 | ||
c3d2e1f0 | ||
6a09e667 bb67ae85 3c6ef372 a54ff53a ... | ||
6a09e667f3bcc908 ... |
编码/校验
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ | ||
77073096 ee0e612c 990951ba ... | 0xedb88320 的查找表 |
HMAC/MAC
36363636 和 5c5c5c5c | ||
0xe100000000000000 |
小技巧:不要只搜第一个字节。把常量拆成 4 字节的 little-endian,搜后面的字节更保险——因为 ARM 的立即数加载常常把高低位分开。
字节序陷阱:为什么你搜不到
有一种最典型的“我明明搜了但没命中”的情形,根源不在样本被混淆了,而在字节序。比如你在代码里看到 state[0] = 0x6a09e667,兴冲冲去 Trace 里 grep 6a09e667——什么都没有。换个顺序 grep 67e6096a——全命中。

原因是 ARM 是小端(little-endian)架构,0x6a09e667 这个 32-bit 整数写到内存里的字节序列是 67 e6 09 6a,而 Trace 里的寄存器内容又不一定是小端,取决于 Trace 工具怎么打印——Unidbg 的指令 Trace 默认把寄存器按逻辑值打印(大端显示),但 Hook 里你用 mem_read 读出来的就是原始字节(小端)。
这会带来两种截然不同的搜法:
搜寄存器值(指令 Trace): grep "6a09e667"# 正常的 big-endian 展示搜内存内容(Hook dump): grep "67e6096a"# 小端存储的字节流更致命的是 ARM64 的 movz + movk 拆分加载:一个 32-bit 立即数 0x6a09e667 在指令流里会变成两条指令——
movz x0, #0xe667movk x0, #0x6a09, lsl #16这时候你搜 6a09e667、搜 67e6096a、搜 e667 单独都能命中,但只有同时搜 #0xe667 和 #0x6a09,并且两条指令在 1-2 行内相邻才能准确判断“这就是 SHA-256 的 IV 加载”。
遇到这类情况,我习惯在脚本里把每个常量都派生出 4 种变形一起搜:正写、反转字节、高低 16 位、高低 16 位反转。过滤噪音要靠肉眼,但至少不会因为字节序错过真命中。
一个真实案例:RSA 的发现路径
常量识别法有一个典型的反例——RSA。它没有标志性的 32-bit 魔数,不能靠搜常量抓到。我分析过一个酷狗的 libj.so,业务函数 encrypt(str) 跑下来输出 128 字节固定长度密文,既不是 AES(长度不等于明文)也不是 SHA(长度不等于 32/64)。第一反应是“可能是 RSA / DH / ECC”,但 Trace 里搜 AES/SHA/MD5 常量都没命中,这符合 RSA 的特征:它的核心是大数模幂运算,常量是运行时计算出来的模数和指数,不会以魔数形式出现在代码里。
识别 RSA 的打开方式是抓 OpenSSL 的底层原语。任何用 OpenSSL 实现的 RSA,最终都会走到 BN_mod_exp_mont(蒙哥马利模幂);任何用 mbedtls 的都会走到 mbedtls_mpi_exp_mod。这些函数名是开源库的导出符号,即便 SO 被 strip,内部调用链也会泄漏,只要 Trace 里出现 BN_ 开头的符号调用,几乎可以 100% 确认是 OpenSSL 的大数运算。
具体做法是两层 Hook:外层挂在业务的加密入口,看明文和密文;内层挂在 BN_mod_exp_mont,看参数 (result, base, exponent, modulus)——这四个参数就把 RSA 彻底摊开了,base 是 PKCS#1 padding 后的明文,exponent 是公钥指数(通常 65537),modulus 是公钥 N。抓到这三个值,你就可以在 Python 里用 pow(base, e, n) 完全复现加密,不再需要 SO。
下面是这个案例的完整代码(出自 KuGouChangChang.java:111-174):
// 外层: 业务的 RSA 加密入口// 通常是 SO 里自定义的封装函数, 调用 RSA_public_encrypt 之类publicvoidhookSubRSAEncrypt(){ IHookZz hookZz = HookZz.getInstance(emulator); hookZz.wrap(module.base + 0x2195b3, new WrapCallback<HookZzArm32RegisterContext>() {@OverridepublicvoidpreCall(Emulator<?> emulator, HookZzArm32RegisterContext ctx, HookEntryInfo info){// r1 = 明文指针, r2 = 输出缓冲指针 Pointer plaintext = ctx.getPointerArg(1); Inspector.inspect(plaintext.getByteArray(0, 0x150), "RSA 明文"); Pointer outBuf = ctx.getPointerArg(2); ctx.push(outBuf); // 留到 postCall 看密文 }@OverridepublicvoidpostCall(Emulator<?> emulator, HookZzArm32RegisterContext ctx, HookEntryInfo info){ Pointer output = ctx.pop(); Inspector.inspect(output.getByteArray(0, 0x150), "RSA 密文"); } });}// 内层: OpenSSL 的大数模幂运算 BN_mod_exp_mont// 函数签名: int BN_mod_exp_mont(BIGNUM *r, const BIGNUM *a, const BIGNUM *p,// const BIGNUM *m, BN_CTX *ctx, BN_MONT_CTX *m_ctx);// ARM32 调用约定: r0=r, r1=a (base), r2=p (exponent), r3=m (modulus), 后续在栈上publicvoidhookSubBN_mod_exp_mont(){ IHookZz hookZz = HookZz.getInstance(emulator); hookZz.wrap(module.base + 0x1e48d5, new WrapCallback<HookZzArm32RegisterContext>() {@OverridepublicvoidpreCall(Emulator<?> emulator, HookZzArm32RegisterContext ctx, HookEntryInfo info){// r1/r2/r3 都是 BIGNUM 结构体的指针 (struct bignum_st)// OpenSSL 的 bn.h 里, BIGNUM 第一个字段就是 BN_ULONG *d (数值字节数组)// struct bignum_st { BN_ULONG *d; int top; int dmax; int neg; int flags; };// 所以 getPointer(0) 等价于读 BIGNUM->d, 拿到真实数值 Pointer arg2 = ctx.getPointerArg(1); Pointer base_data = arg2.getPointer(0); // = BIGNUM->d Inspector.inspect(base_data.getByteArray(0, 0x150), "RSA base (PKCS#1 后的明文)"); Pointer arg3 = ctx.getPointerArg(2); Pointer exp_data = arg3.getPointer(0); Inspector.inspect(exp_data.getByteArray(0, 0x150), "RSA exponent (通常 0x010001 = 65537)"); Pointer arg4 = ctx.getPointerArg(3); Pointer mod_data = arg4.getPointer(0); Inspector.inspect(mod_data.getByteArray(0, 0x200), "RSA modulus (公钥 N, 256 字节 = 2048 位)"); } });}跑一次目标加密函数,控制台会同时打出业务层的明文/密文(外层 Hook)和底层的 RSA 三参数(内层 Hook)。三个值抓到之后,Python 端就是一行:
ciphertext_int = pow(base_int, exponent_int, modulus_int)几个工程细节:
BIGNUM 第一个字段是 d 指针:OpenSSL 的 struct bignum_st内存布局里第一个字段就是BN_ULONG *d(指向数值字节数组),所以arg.getPointer(0)从结构体偏移 0 处读出来的就是 d。Hook 里漏了这一步直接读arg.getByteArray(0, n),dump 出来的全是{d_ptr, top, dmax, neg, flags}这堆结构体头部,根本不是数值。**指数大概率是 01 00 01(65537)**:RSA 标准公钥指数。如果你 dump 出来不是这个,要么是私钥操作(不太可能在客户端发生),要么是非标准 RSA。模数长度对应位数:256 字节 = 2048 位 RSA,128 字节 = 1024 位。这个长度先验在第十八章 Step 0 已经讲过——遇到 128/256/512 字节固定输出且字节看起来均匀分布就该往 RSA 上想。 +1是 Thumb 模式标志:ARM32 SO 大量用 Thumb 指令,函数地址低位需要 +1。ARM64 没有这个问题。抓 BN_mod_exp_mont比抓RSA_public_encrypt更稳:后者只在用 OpenSSL 标准 API 调用时出现,前者无论上层包装怎么变,只要底层走的是 OpenSSL 大数运算就一定经过它——这是 OpenSSL RSA 实现里所有路径的"必经关口"。
判据:业务函数输出 128/256/512 字节固定长度密文 + Trace 里搜 AES/SHA 常量都没命中 → 几乎可以锁死是 RSA。这时候直接挂
BN_mod_exp_mont(OpenSSL)或mbedtls_mpi_exp_mod(mbedtls)—— 这两个符号是开源大数库的"必经关口",即便 SO strip 过、内部调用链没暴露符号,被它们调用的层级仍然会留下符号 import。
Unidbg 作为“算法验证器”
Unidbg 除了是分析工具,还是一个活的测试基准。这是它最被低估的价值。三种常用的验证方式:
方式 1:还原一步,验证一步
你不要等到整个算法还原完才跑验证。每还原一小块,立刻和 Unidbg 对比。
比如你在实现 MD5:
defmd5_step_1_pad(data):# 第 1 步: padding ...# 马上 Hook Unidbg 的 padding 函数, dump 它的 padding 结果# 对比两边的 padding 是否一致问题越早发现越好修。最怕的情况是等你写了 200 行 Python,对不上,你根本不知道错哪里。
方式 2:分段验证
一个算法通常由几个阶段组成:输入预处理 → 密钥派生 → 主加密 → 输出后处理。每个阶段都是一个“验证节点”。
用 Unidbg 在每个节点上设 Hook, dump 该阶段的输入和输出。用你的 Python 实现逐段替换,每次只替换一个阶段,看最终结果是否一致。
第 1 次: Python padding + SO 其他 → 对上第 2 次: Python padding + Python KDF + SO 加密 + SO 后处理 → 对上第 3 次: 都用 Python → 对上, 完成!这种“增量替换”的节奏,比“一把梭哈”稳得多。
方式 3:固定随机项后再验证
如果目标函数内部有随机源(rand() / gettimeofday() / /dev/urandom),同样的输入每次会得到不同的输出。这时验证就做不了。
解决办法:先把随机项固定住。第十三篇讲过具体方法 —— 重写 SyscallHandler、Hook rand()、提供确定性的 /dev/urandom。固定之后,Unidbg 变成确定性系统,可以做严格对比。
这里有个常见误区:有人把“固定随机”理解成“让 Unidbg 和真机一样”。错! 目标是让 Unidbg 本身的输出可重现,不是和真机一样。你只需要在 Python 复现里用相同的固定值,对比就成立。
Unidbg 的能力边界
通篇讲了 Unidbg 多有用,但作为收官章,必须诚实地说一句:Unidbg 不是万能的。下面 4 类样本是它会卡的地方,碰到这些情况你得换工具或换思路:
边界 1:依赖硬件密钥的算法(TEE / SE / Keystore)
Android 的 AndroidKeyStore 把私钥放在 TEE(可信执行环境)里,应用层只能拿到一个不透明的 handle,真正的加密在 TEE 内部完成。Unidbg 模拟的是用户态的 ARM CPU 和 bionic libc,根本接触不到 TEE。这类样本在 Unidbg 里要么直接报错(找不到 keymaster 的 binder 接口),要么需要你整段 stub 掉——但 stub 之后你模拟出来的就不是真的算法了,没意义。
怎么办:要么换成真机 frida 直接 hook 业务函数返回值(不深入 native),要么寻找软实现 fallback 路径(部分 SDK 在 TEE 不可用时会走纯软件 RSA)。
边界 2:未补全的 syscall
Unidbg 内置的 SyscallHandler 只覆盖了常用 syscall。一旦样本调了冷门接口(bpf、perf_event_open、io_uring、新版本的 prctl 子命令),你会看到一句报错然后 emulator 直接挂掉。理论上你可以自己继承 UnixSyscallHandler 把它补上,但工作量不小,而且有些 syscall 的语义在用户态根本没法模拟(比如 bpf 装载到内核里的字节码)。
判断阈值:如果一个样本要补的 syscall 超过 5 个,先怀疑是不是走错路了——可能这段代码就是反检测分支,不是核心算法。
边界 3:anti-emulator 检测
Unidbg 自己有指纹。检测方法包括:
读 /proc/self/maps看有没有unidbg字样的路径或异常的内存段布局检查 bionic关键导出符号的地址特征(Unidbg 的 libc 是自己实现的,地址分布和真机不同)读系统属性 ro.product.cpu.abi/ro.build.fingerprint/ro.hardware,看是否是真机型号检查模拟器特征文件 /dev/qemu_pipe、/dev/socket/qemud、/system/lib/libc_malloc_debug_qemu.so是否存在跑时间敏感的代码看 CPU 周期数(Unicorn 通常比真 ARM 慢一个数量级以上,具体倍数取决于 Backend 与指令热度——Unicorn 老版本 50× 起跳,Unicorn2 / Dynarmic 在热路径上可压到 5-15×,但仍肉眼可见) 检查 /system/lib64下的关键 SO 是否真实存在
样本一旦发现自己跑在 Unidbg 里,可能直接走"假算法路径"——返回看起来对但其实是错的结果,让你"觉得"还原成了。这一类是最可怕的,因为不会报错,只会让你浪费几天。
怎么办:把第十三篇讲的环境构造做扎实(/proc/self/maps 伪造、/system/build.prop 仿真、JNI 反射注册),并且关键算法一定要在真机上对一组数据验证一次——只要真机和 Unidbg 输出一致,就说明检测点没生效。
边界 4:重度 OLLVM / VMProtect 混淆
控制流平坦化让你的 Trace 充满 dispatcher 的状态机切换噪音——一个 200 条指令的算法 Trace 出来变成 5000 条指令,95% 是 cmp + br 的状态机分发。这时候 Step 1 的 Trace 工作量爆炸,Step 2 搜常量没问题,但 Step 3 想找"循环出口"基本没戏(循环已经被展开成状态机了)。
字符串/常量加密:.rodata 里看到的不是真常量,是密文,运行时一段解密代码把它变成真常量再用。Step 2 搜不到常量。
VM 化保护(VMProtect、自定义 VM):原来的 ARM 指令被替换成 VM 字节码,每条业务"指令"其实是几十条 VM dispatcher 指令。Trace 几乎完全失去意义。
怎么办:
OLLVM 平坦化:先去平坦化( unflattener、IDA 插件 D-810),把 CFG 还原成正常形态再 Trace字符串解密:写脚本自动化跑解密例程并 patch 回 SO,得到一份"明文版"再分析 VM 化保护:要么手动逆 VM dispatch 表(大工程),要么放弃白盒还原走灰盒——只 hook VM 解释器入口,把 VM 字节码当作密钥的一部分整体打包
心态准备:碰到这三类的任何一种,你的工作量是 10 倍起跳。如果业务没那么重要,有时候直接用 Unidbg 当 RPC 反而是更经济的选择。承认这一点不丢人。
一个对照表:什么时候用 Unidbg、什么时候不用
一句话总结:Unidbg 适合"算法本身"的还原;不适合"算法之外的环境"的还原。能分清这条边界,你就不会在错的方向上耗时间。
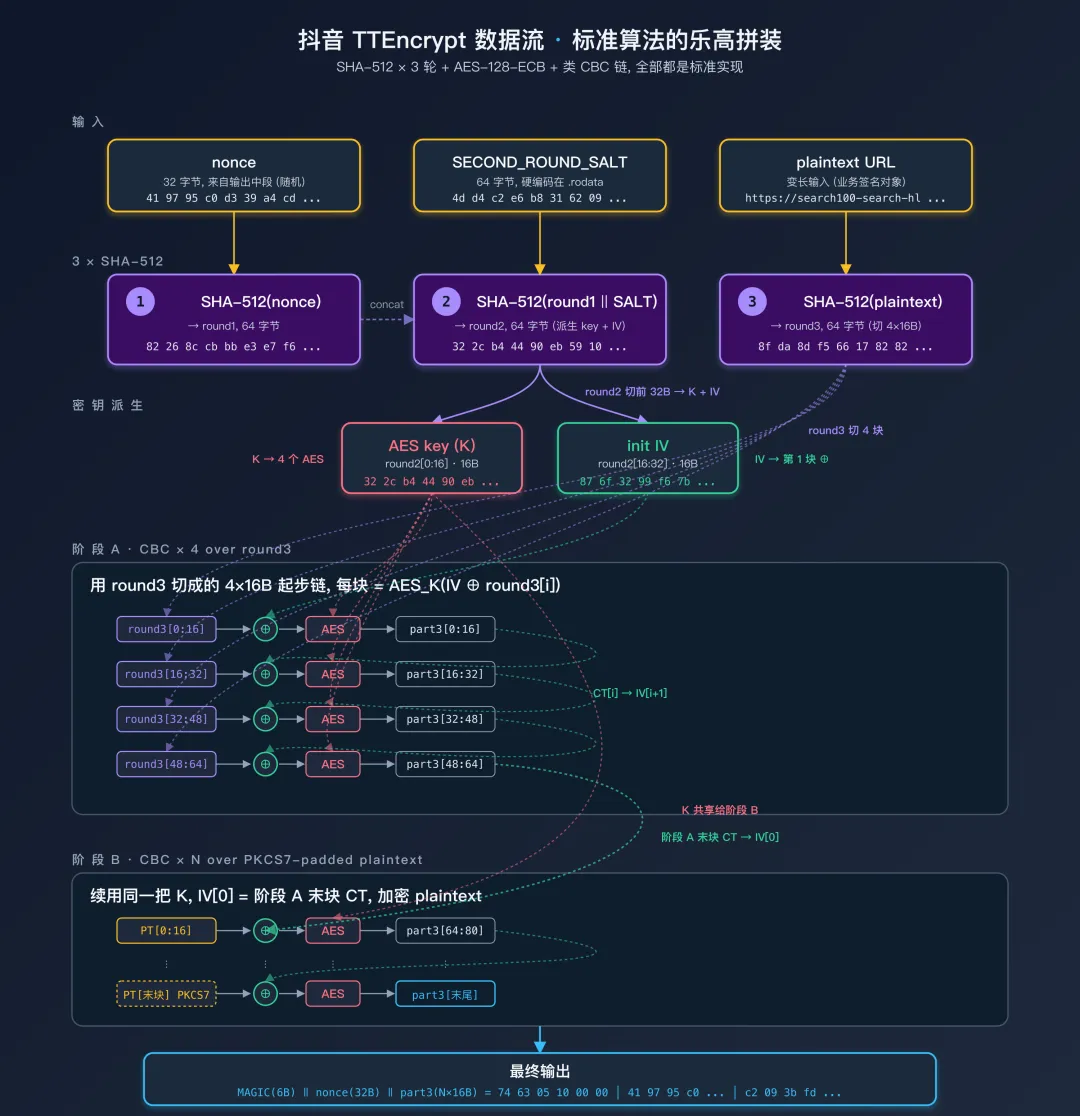
一个真实的案例:抖音 TTEncrypt
把这一篇的五步工作流全部串起来,看一个本系列项目里实际跑过的样本——抖音的 libEncryptor.so 中的 TTEncrypt 算法(对应代码见 unidbg-chqi/.../AwemeTTEncrypt.java,逆向记录见 readme/抖音TTencrypt加密算法破解.md)。
背景
输入是一条 URL,输出是一段变长字节流。最初拿到样本时只知道两件事:
入口符号: Java_..._ttEncrypt(String)—— Java 层的 native 方法IDA 里能看到 libEncryptor.so加载后跑了一长串BL调用,但符号几乎全 strip,看不出在调什么
按五步工作流走一遍。
Step 0:长度先验
跑一次拿到一组真实输入输出。输入是 800+ 字节的完整 URL,输出 832 字节。把输出拆开看:
前 6 字节: 74 63 05 10 00 00 ← 像是 magic + 版本号中 32 字节: 41 97 95 c0 d3 39 a4 cd ... ← 字节分布看着均匀, 像随机 nonce后 N×16 字节: c2 09 3b fd 32 2a 57 77 ... ← 长度恰好是 16 的整数倍光看这个结构就能下两个判断:
后段是 16 字节对齐的分组密文——长度规律强烈指向 AES(而且 ECB / CBC / CTR 哪种都有 16 字节分组),不是 SHA、不是 RSA。 中间 32 字节大概率是某个 hash 的输入或输出,因为它的长度等于 SHA-256 输出 / SHA-512 截断 / 两轮 SHA-1 拼接……几个常见数。
带着这两个先验进 Step 1。
Step 1:Trace 全局录制
PrintStream traceStream = new PrintStream(new FileOutputStream("trace_1.txt"), true);emulator.traceCode(module.base, module.base + module.size).setRedirect(traceStream);跑一次 ttEncrypt(url),trace 出来 60 多 MB。光看是看不完的,进入 Step 2。
Step 2:搜算法常量
按"指纹速查表"逐个 grep(注意 ARM 是小端,常量要双向搜):
637c777b | ||
6a09e667f3bcc908 | 08c9bcf3 67e6096a) | |
6a09e667 | ||
bb67ae85 | 未命中 | |
bb67ae8584caa73b | ||
67452301efcdab89 同时 | 未命中 |
证据指向:标准 AES + 标准 SHA-512,没有 SHA-256、没有 MD5、没有 RSA。6a09e667 单独命中不能区分 SHA-256 和 SHA-512(这是**两个算法共享的 IV[0]**,第三章长度先验和指纹速查表都漏过这条),但 bb67ae8584caa73b(64-bit IV[1])是 SHA-512 独有的,命中即定性。
到这一步,没有任何"魔改 / 自定义 IV"的迹象——所有命中的都是标准常量原样出现。剩下要搞清楚的就是"标准 AES 和标准 SHA-512 是怎么拼起来的"。
Step 3:在关键地址挂 Hook
借助 IDA 反向跟着常量命中的位置追到几个候选函数入口,挂 4 个 HookZz:
// 注意: 32 位 SO, 函数地址要 +1 表示 Thumb 模式publicvoidhookSub3BB8(){ // ttEncrypt 主入口 hookZz.wrap(module.base + 0x3BB8, /* 略, 完整代码见 AwemeTTEncrypt.java */);}publicvoidhookSub3640(){ // AES 单块加密 hookZz.wrap(module.base + 0x3640 + 1, /* ... */);}publicvoidhookSub8BAC(){ // SHA-512 hookZz.wrap(module.base + 0x8BAC + 1, /* ... */);}publicvoidhookSub8214(){ // 字节级 XOR 链 hookZz.wrap(module.base + 0x8214 + 1, /* ... */);}四个 hook 配合 Inspector.inspect 把每次调用的输入输出 dump 出来。一次 ttEncrypt 跑下来日志大致是这样(用真实样本数据):
[SHA512-1] in: 41 97 95 c0 d3 39 a4 cd ed 6b 33 4a 6e 83 85 65 ... (32 字节, 即输出中段那 32 字节)[SHA512-1] out: 82 26 8c cb bb e3 e7 f6 ab 72 15 91 ff a0 65 88 ... (64 字节)[SHA512-2] in: 82 26 8c cb ... 4d d4 c2 e6 b8 31 62 09 0e 52 b3 c7 ... (64+64 字节: round1 + 64 字节常量)[SHA512-2] out: 32 2c b4 44 90 eb 59 10 0c 61 40 4a bd 32 38 be ... (64 字节) 《─── AES key (前 16) ───》 《─── XOR mask (16-32) ───》[SHA512-3] in: https://search100-search-hl.amemv.com/... (URL 明文)[SHA512-3] out: 8f da 8d f5 66 17 82 82 12 e0 7d 12 12 25 ea f9 ... (64 字节, 切成 4 个 16 字节)[XOR-1] r3=0x87 ip=0x8f => r3=0x08[XOR-1] r3=0x6f ip=0xda => r3=0xb5 ... ← SHA512-2 的 16~31 字节 XOR SHA512-3 的 0~15 字节[AES-1] key: 32 2c b4 44 90 eb 59 10 0c 61 40 4a bd 32 38 be[AES-1] in: 08 b5 bf 6c 90 6c 02 e4 8f d5 e8 bc f3 45 15 01 ← 上一步 XOR 结果[AES-1] out: c2 09 3b fd 32 2a 57 77 06 a3 cb 09 2d 1c 27 ba ← 正好是输出后段的前 16 字节!到这里整个数据流已经清晰:每个原子操作都是标准算法,差别只在拼接。
Step 4:对比标准实现
挑 SHA-512 的第一轮验证一下(最容易做 sanity check):
import hashlibnonce = bytes.fromhex("419795c0d339a4cded6b334a6e838565161813041""5c0245c2df405a38610e6dd")h1 = hashlib.sha512(nonce).digest()assert h1[:16] == bytes.fromhex("82268ccbbbe3e7f6ab721591ffa06588")# ✓ 完全一致AES 也同样验证:
from Crypto.Cipher import AESkey = bytes.fromhex("322cb44490eb59100c61404abd3238be")pt = bytes.fromhex("08b5bf6c906c02e48fd5e8bcf3451501")ct = AES.new(key, AES.MODE_ECB).encrypt(pt)assert ct == bytes.fromhex("c2093bfd322a5777 06a3cb09 2d1c27ba")# ✓ 完全一致两个原语都是 100% 标准实现。所有"魔改感"全部来自拼接顺序,不在算法内部。
Step 5:Python 重写整套流程
把 6 步逻辑串起来,全部用标准库。SECOND_ROUND_SALT 是从 SHA512-2 的输入里减去 round1 拿到的 64 字节常量(硬编码在 SO 的 .rodata 里,每次跑都一样,从 hook dump 直接抄):
import hashlibfrom Crypto.Cipher import AESfrom Crypto.Util.Padding import padSECOND_ROUND_SALT = bytes.fromhex("4dd4c2e6b83162090e52b3c7a6733ba41cb2462b829ab58a""196b39db5717752 4f49baf7f08e8d68d26a72e37c1a95a2f""1f05a51892aef2949732b62a38aadd58")MAGIC = bytes.fromhex("746305100000") # 6 字节固定 headerdeftt_encrypt(plaintext: bytes, nonce: bytes) -> bytes:# Step 1: SHA-512(nonce) r1 = hashlib.sha512(nonce).digest()# Step 2: SHA-512(r1 || SALT) → AES key + XOR mask r2 = hashlib.sha512(r1 + SECOND_ROUND_SALT).digest() aes_key = r2[:16] xor_mask = r2[16:32]# Step 3: SHA-512(plaintext) → 4 个 16 字节 r3 = hashlib.sha512(plaintext).digest() cipher = AES.new(aes_key, AES.MODE_ECB)# Step 4-5: 用 r3 的 4 个 16 字节做"准 CBC" — 第一块 IV 是 xor_mask, 后面用上一块密文 out = bytearray() iv = xor_maskfor i in range(0, 64, 16): block = bytes(a ^ b for a, b in zip(iv, r3[i:i+16])) ct = cipher.encrypt(block) out.extend(ct) iv = ct# Step 6: 同样的 CBC 链路加密整个 plaintext (PKCS7 padding) padded = pad(plaintext, 16)for i in range(0, len(padded), 16): block = bytes(a ^ b for a, b in zip(iv, padded[i:i+16])) ct = cipher.encrypt(block) out.extend(ct) iv = ctreturn MAGIC + nonce + bytes(out)# 用 Unidbg 抓到的同一组 nonce + URL 做基准对比nonce = bytes.fromhex("419795c0d339a4cded6b334a6e838565""161813041 5c0245c2df405a38610e6dd")url = b"https://search100-search-hl.amemv.com/aweme/v1/search/item/?_rticket=..."expected = call_unidbg(url, nonce) # Unidbg 跑一次拿基准assert tt_encrypt(url, nonce) == expected# ✓ 字节级一致, 还原成功代码量从 SO 里几千条 ARM 指令 → 约 30 行 Python(不算 SALT 常量)。**SECOND_ROUND_SALT 是这个 SO 的核心秘密**——它本质是开发者藏在 .rodata 里的"伪密钥",没有 Unidbg + Hook dump 一眼是看不出来的;而拼装顺序(SHA-512 三连 + XOR + AES-ECB 链)只要 dump 数据流就能猜出来。
这个案例的启发
复杂签名 ≠ 复杂算法,而是标准算法的乐高拼装。TTEncrypt 在签名圈里以"难"出名,但拆开后每一个原子操作都是 hashlib / PyCryptodome 一行调用。让它显得"复杂"的是拼接顺序 + 一段藏在 .rodata里的硬编码 SALT。Step 0 长度先验决定后面四步走多快。先看输入输出长度那一眼省了我半天试错——如果上来就把整个 ARM 反汇编当作"自定义 SBox"去逆,这个样本怎么也得多花两天。 常量搜索时小心 IV[0] 的歧义。 6a09e667既是 SHA-256 也是 SHA-512 的 IV[0],单独命中不能定性;要么搜 IV[1](bb67ae8532-bit /bb67ae8584caa73b64-bit),要么看输出长度(32 vs 64)。这条经验本系列前面"指纹速查表"没写清楚,本案例补上。真正难破的不是算法,是密钥来源。这个 SO 的 SALT 是硬编码(密钥追溯姿势 1,最简单),所以两小时能搞定;如果 SALT 是从服务器下发的(姿势 5),还原成本至少翻 5 倍——具体见前面"密钥追溯的 5 种姿势"那一节。 Hook dump 比静态分析高效一个量级。整套流程 IDA 静态啃可能要一天,Unidbg + 4 个 wrap hook + Inspector 两小时拿到所有数据流。这就是 Unidbg "白盒分析工作台" 的真正价值。
常见误区与陷阱
误区 1:一上来就看 IDA F5
很多人的习惯是 Ghidra / IDA 一打开,先看 F5 伪代码。这是错的。
正确顺序:先 Trace 一次,再看 IDA。 Trace 告诉你“这次运行到底走了哪些代码”,IDA 可能因为间接跳转或优化漏掉一些路径。看 Trace 知道范围,再回 IDA 看细节,效率高 3 倍。
误区 2:试图还原所有分支
SO 里常有很多“防御性分支” —— 检查参数、处理错误、防呆。你不需要把这些都还原。只还原主路径 —— 就是 Trace 里实际走过的路径。其他分支在你的 Python 实现里直接抛异常或留 TODO 就行。
误区 3:重写的 Python 跑起来很慢
Python 跑 AES 一轮比 ARM 慢 100 倍很正常 —— 但这是因为你用 Python 纯实现,应该调用 PyCryptodome 等库,然后只在“和标准不同的那部分”写 Python。比如魔改 S-Box → 用 AES.new(mode=ECB) + 自己预处理一下 state 就行。
误区 4:没做基准验证就开始用
“写完代码,跑了一个 case 对上了,发布”。这是灾难的开始。你应该用至少 100 个随机输入和 Unidbg 对比,全对上才能认为还原成功。因为有些 bug 只在特定输入下暴露(比如某个字节为 0 时的边界)。
误区 5:混淆了“看懂”和“还原”
有些人分析完觉得“我懂了,这就是 SHA-256”,然后就直接上 hashlib.sha256。不对。哪怕看起来像 SHA-256, 也必须做基准验证,因为任何一个小魔改都会导致结果完全不同。
一句话:不经过 Unidbg 基准验证的还原,都是半成品。
总结
一句总结:把 Unidbg 当成一台“无尘车间里的示波器” —— 你往里塞信号,它给你完全确定性的波形。有了这个基准,你才能放心地把 SO 扔掉,用自己的代码替代它。这就是 Unidbg 最高级的用法。

