这是这个系列的最后一篇。写到这里,我希望你不仅“会用 Unidbg”,而是真正理解 Unidbg 在整个逆向工程版图里的位置 —— 它的边界在哪里,它什么时候不该用,替代品是什么,这个领域未来会往哪走。一个工具的最高理解,是知道它什么时候不该用。
上一篇把你留在了哪里
第十九篇我们把 Unidbg 推到了“生产服务”的极限。写到那里,你可能会觉得 “Unidbg 真是个万能瑞士军刀”。但任何工具都有它的边界,任何技术都不会永远统治它的领域。
写这一系列文章的时候,我反复问自己一个问题:如果三年后 Unidbg 不再被维护,我们该怎么办? 这不是杞人忧天 —— 开源项目的生命周期常常比我们想象的短。一个负责任的工程师,不应该把所有筹码押在一个工具上。
这篇文章的目的,就是帮你建立一个多工具的逆向工具世界观。当 Unidbg 不行时,你知道下一步往哪走。
Unidbg 目前的边界Unidbg 的四个结构性边界
把 Unidbg 当万能工具的人,通常是因为没遇到过它的边界。一旦遇到,你才知道它解决不了某些问题。下面是几个真实的边界:
边界 1:只能处理单 SO 的视野
Unidbg 模拟的是一个 ELF 模块的执行。它不模拟整个 Android 进程的全部 SO 协作。这意味着:
- 一个 SO 调用另一个 SO 的函数,Unidbg 也能模拟(只要你把那个 SO 也加载进去)
- 但两个 SO 通过某个全局状态、共享内存、binder 互动时,Unidbg 就抓瞎了
- 一个 SO 通过 dlopen 动态加载另一个 SO,然后两者之间相互回调,Unidbg 可以做但很麻烦
真实场景:一个风控 SDK 的初始化函数会通过 binder 和系统服务通信,要求拿到当前的 SIM 卡序列号。Unidbg 没有 binder 通路,这一步过不去。你可以伪造结果,但伪造不对就被检测。
边界 2: Java 生态限制了嵌入性
Unidbg 是 Java 编写的。这有它的好处(JVM 跨平台,部署简单),但也有显著的副作用:不能作为 IDA / Ghidra 插件,大部分逆向工程师的主战场是 IDA,Unidbg 永远是个外挂,不能在 F5 视图里直接“Run this function in Unidbg”;不能作为 Python 库,如果你已经有一个 Python 的分析框架(Capstone + r2pipe + ...),你没法把 Unidbg 当成一个 import 进来用;JVM 启动慢,哪怕你只想跑一次,JVM 都要 1-2 秒的启动时间,对于“快速验证”场景不友好。
这听起来像是一个工程选择问题,但其实它背后反映的是整个逆向工具链的生态割裂。不妨做个思想实验:假如 Unidbg 当年是用 C/C++ 或 Rust 写的,整个生态会是什么样?
# 幻想版: Unidbg 是 C 库 + Python 绑定import unidbgemu = unidbg.AndroidEmulator(arch="arm64")emu.load_library("libsample.so")emu.attach_debugger(entry_point=0x1A34)# 在 IDA 里选中一段代码, 右键 "Run in Unidbg"# 弹出 dialog 让你设入参, 执行, 把寄存器结果写回 IDA 的注释
这段代码如果能跑,整个逆向工作流会被彻底改写——你不再需要在 IntelliJ 里写 Java,再切回 IDA 看结果,再回来改 Java,再运行……而是能在 IDA 里一气呵成。
但现实是 Unidbg 用 Java 写,为了调用它你要开 Gradle 项目、导入 jar、写 main 方法、编译运行。这套流程天然抵制“快速实验”——一个想法从“我猜这个函数是 AES”到“跑出验证数据”要 10-30 分钟,而用 Python 工具链的人只需要 30 秒。Qiling 之所以在学术圈和研究圈更流行,核心就是它选对了生态。
JNI 绑定也是生态站队的副产品。想从 Python 调 Unidbg,你要么写一个 JNI wrapper(开发量大),要么走 HTTP 服务(unidbg-boot-server 模式,有 RPC 开销),要么干脆放弃 Python 改用 Java——每一条路都有磨损。这不是 Unidbg 作者的错,是 JVM 和 Python/C 生态之间天然存在的“玻璃墙”。
这是个生态站队的问题。逆向工程的主流生态是 Python + C,Unidbg 选择了 Java,注定是个“跨生态的访客”。选择 Java 的理由不是没有——JVM 的跨平台、Android 原生的 Dalvik 兼容、Kotlin 的可读性——但代价是永远无法真正“融入”逆向工具链,只能被隔着一堵墙调用。
边界 3:社区活跃度的现实
Unidbg 的核心 commit 高度依赖少数几个维护者。看 GitHub 的 commit 历史,你会发现:
- 大功能更新(比如 Backend 切换、AbstractJni 改进)集中在 2019-2022 年
- 2023 年之后 commit 频率明显放缓,但 PR 仍在持续合并(JNI gap 修复、内存保护、依赖更新等到 2024 年依然有动作)
- 大量 issue 长期未回复或长期挂着,作者更倾向于把精力放在合并 PR 上
这不是说 Unidbg 已死,而是它进入了偏维护的阶段 —— 修 bug 多于加新功能。如果 Android/JNI 出现新的特性(比如新版 ART 的 Hidden API 改动),Unidbg 跟进的速度会越来越慢。
作为使用者你应该有意识:不要假设你提的 issue 一定会被修,不要假设新版 Android 一定能用。学会自己 patch Unidbg 源码,是高级用户的必备能力。
边界 4: iOS 支持的"工程量"和"开箱兼容性"不对等
虽然 Unidbg 名字里带 "uni"(取自底层 Unicorn 引擎)和 "dbg"(debugger),但它在 iOS 这一侧的实际可用性比 Android 弱了不止一档——这里要说清楚一个反直觉的事实。
光从代码量看,unidbg-ios/src 里有 287 个 java 文件(dyld / MachO / Obj-C runtime / Codesign 都有专门实现),对比 unidbg-android/src 只有 231 个。从仓库维护者投入的工程量看,iOS 部分并不少。但社区使用反馈一致是:
- 主流 iOS 加密 SDK 的开箱兼容性远低于 Android——Android 那边一个新样本通常半天到一天能补通,iOS 那边经常卡在 Obj-C runtime 的某个细节上反复几天
- iOS 测试样本和案例补遗几乎没有——前面 19 篇里所有案例样本(Aweme / Music163 / WeRead / KuGou 等)都是 Android,iOS 没有同等量级的实战教程沉淀
- 越狱机 + Frida 的工作流成熟度更高——iOS 圈的主流逆向流程本来就更依赖真机,社区习惯不一样
所以这不是"Unidbg 的 iOS 实现简陋",而是"Unidbg 在 iOS 上没有形成像 Android 那样的样本兼容生态"。这是工具维护、社区习惯、防御技术差异三方共同作用的结果。
结论:如果你的目标是 iOS,先问"是否有人用 Unidbg 跑通过我这个样本",没有就直接 Frida + 越狱机更稳。Unidbg 的 iOS 路径目前更适合"已经有 Unidbg Android 经验、愿意自己补环境踩坑"的进阶玩家。
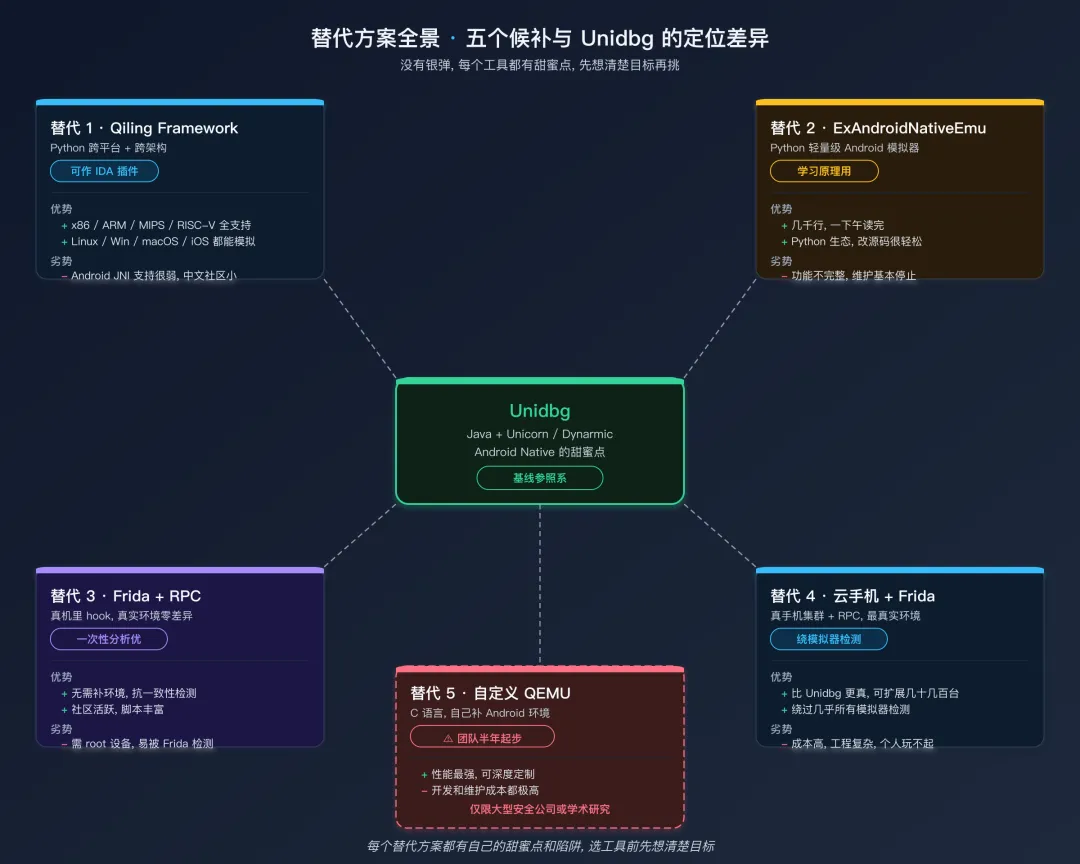
替代方案全景替代方案全景:五大工具的定位
知道了边界,接下来看候补名单。下面是 5 个主流替代品,各有适用场景:
替代 1: Qiling Framework
语言:Python主页:https://qiling.io核心特性:跨平台、跨架构的二进制模拟框架,支持 Linux / Windows / macOS / iOS / DOS / UEFI
优势:
- Python 原生,可以作为库被任意 Python 项目 import
- 可作为 IDA 插件,把 IDA 选中的代码段直接送进 Qiling 模拟执行
- 跨架构,x86/ARM/MIPS/RISC-V 都支持
- 跨平台 OS,不只 Android Linux,还能模拟 Windows PE 二进制等
劣势:
- Android JNI 工程化弱于 Unidbg。Qiling 的
qiling.os.android 模块也实现了 JNIEnv/JavaVM、RegisterNatives、JNI_OnLoad 这些基础设施,但和 Unidbg 内置的 AbstractJni 体系比,覆盖度和样本兼容性都明显低一档,复杂样本要自己补的 hook 会多很多。
适用场景:
不适用场景:纯 Android JNI 调用,Unidbg 体验明显更好。
替代 2: ExAndroidNativeEmu
语言:Python主页:https://github.com/AeonLucid/AndroidNativeEmu (原版) + 多个 fork核心特性:用 Unicorn 实现的轻量级 Android Native 模拟器
优势:
- 极轻量。整个项目几千行 Python,可以一个下午读完源码
- 易扩展。想加个 syscall,想改个 hook,直接改源码
- 同样是 Python 生态,可以和分析脚本无缝集成
劣势:
- 功能不如 Unidbg 完善。AbstractJni、文件系统、Backend 切换、Trace 工具都比 Unidbg 弱很多
- 样本兼容性差。大部分复杂样本要么跑不起来,要么需要大量手动补环境
- 主仓库已基本停滞(maiyao1988 fork 自 2023 年底再无更新),但社区里还有几个 fork(如 CKCat、CherishLee 等)在 2025 年初仍有维护,要用得选活跃度高的
适用场景:
不适用场景:任何对功能完整性有要求的项目。
替代 3: Frida + RPC
语言:JavaScript / Python (注入到目标进程的脚本)主页:https://frida.re核心特性:动态插桩工具,在真实进程中 hook 任意函数
优势:
- 真实环境。不需要补任何 Android 环境,因为本来就在真机上跑
劣势:
- 依赖真机/模拟器。你必须有 root 设备或者越狱手机
- 易被检测。Frida 注入痕迹明显,大部分商业 SDK 都有 Frida 检测
- 批量调用受限。一台手机一次只能跑一个进程,几千 QPS 需要多设备 + 调度
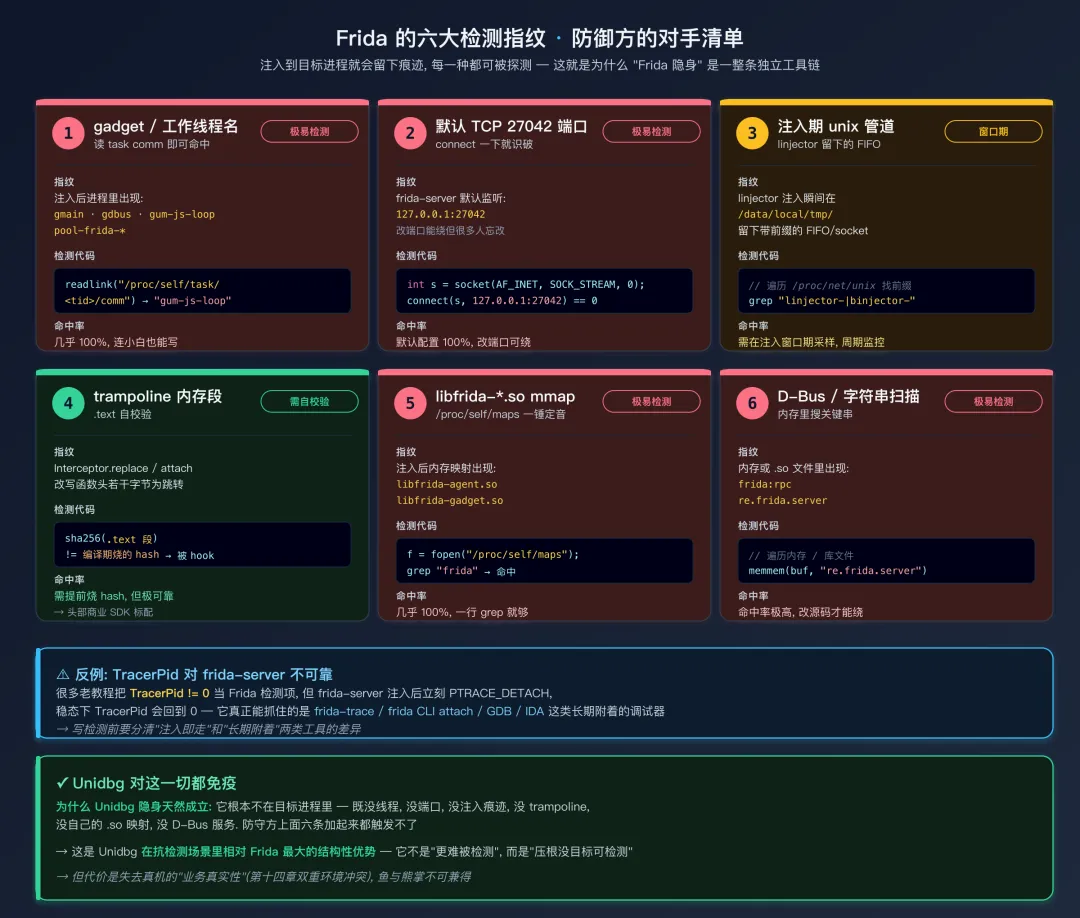
“易被检测”这一点值得展开,因为它是 Frida 在对抗场景里真正的软肋。Frida 注入到目标进程后会留下多种指纹,每一种都可能被检测:
- gadget / 工作线程名:注入后进程里会出现
gmain、gdbus、gum-js-loop、pool-frida-* 等线程,直接读 /proc/self/task/<tid>/comm 即可命中。 - 默认 TCP 端口 27042:frida-server 默认监听
127.0.0.1:27042,App 自己 connect() 一下就能探测到本机有没有 frida-server 在跑。 - 注入期的 unix 管道:linjector 在注入瞬间会在
/data/local/tmp/ 下创建带 linjector- / binjector- 前缀的 FIFO/socket,遍历 /proc/net/unix 能在注入窗口期捕捉到。 - trampoline 内存段:
Interceptor.replace 会在目标函数头部直接写跳转指令;Interceptor.attach 走的是 PTrampoline + relocation,但被 hook 函数前若干字节同样会被改写。防守方 checksum 自己的 .text 段就能检测到这种改动。 libfrida-agent.so / libfrida-gadget.so 的 mmap 痕迹:遍历 /proc/self/maps,看到名字含 frida 的 mapping 几乎可以一锤定音。- 特定字符串搜索:在内存或者库文件里搜
frida:rpc、re.frida.server(D-Bus 服务名)这类字符串,命中率极高。
需要单独说一下 TracerPid:很多老教程会把它当成 Frida 检测项,但实际上 frida-server 只在注入瞬间用 ptrace 写入 agent,完成后立刻 PTRACE_DETACH,稳态下 TracerPid 会回到 0,所以它对 frida-server 注入并不可靠;它真正能可靠抓住的是 frida-trace、frida CLI attach、GDB/IDA 这类长期附着的调试器。
Frida 六大检测指纹一览回到上面六个签名:前两条是 Frida 特有的指纹,后面几条是通用的"被 hook 过的进程"指纹。只要防守方写一段代码连续检查这些,Frida 的隐蔽性就崩了——这就是为什么"Frida 隐身"是一个独立的工具链(hluda / strongR-frida / patchless-hook 等等),并且升级频率要跟着样本走。Unidbg 没有这个问题,因为它根本不在目标进程里,无迹可寻。
适用场景:
不适用场景:
替代 4:云手机 + Frida
语言:-核心特性:用云端真实手机 + Frida 提供 RPC 服务
优势:
- 完全真实环境。比 Unidbg 更真,因为是真手机
劣势:
- 成本高。一台云手机几百到几千一月,几十台就是真金白银
- 管理复杂。设备掉线、ROM 升级、Frida 检测对抗、IP 池管理,全是工程问题
- 依然怕 Frida 检测。真机也能被 Frida 检测到
适用场景:
不适用场景:个人研究者(成本承担不起)、低价值场景。
替代 5:自定义 QEMU
语言:C核心特性:基于 QEMU 用户态模拟,自己补 Android 环境
优势:
- 最完整的模拟。理论上可以模拟整个 Android Runtime
- 性能最好。QEMU 有 TCG/JIT,单纯的指令模拟比 Unidbg 快
劣势:
- 开发成本极高。要补 Android 环境,要补 ART,要补 JNI,要补 binder..。这是一个团队半年以上的项目
适用场景:大型安全公司的研究团队。绝不适合个人/小团队。
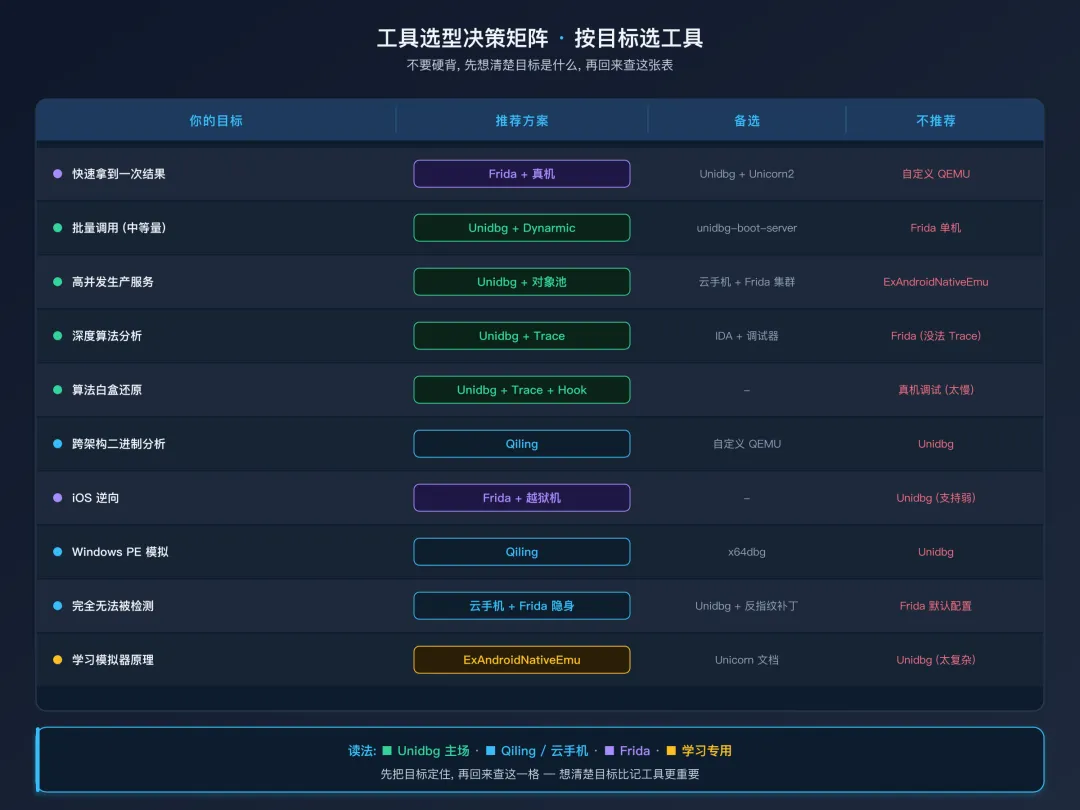
工具选型决策矩阵工具选型决策矩阵
把上面的替代方案和 Unidbg 整理成一张决策矩阵,按“目标”选工具:
| | | |
|---|
| 快速拿到一次结果 | | | |
| 批量调用 (中等量) | | | |
| 高并发生产服务 | | | |
| 深度算法分析 | Unidbg + Unicorn2 + Trace | | |
| 算法白盒还原 | | | |
| 跨架构二进制分析 | | | |
| iOS 逆向 | | | |
| Windows PE 模拟 | | | |
| 完全无法被检测 | | | |
| 学习模拟器原理 | | | |
怎么用这张表:不要硬背。记住一个原则 —— 先想清楚自己的目标是什么,然后从这张表里查。想清楚目标比记工具更重要。
经验法则
- Unidbg 的甜蜜点:Android Native + 算法分析 + 中等并发。这是它最强的领域,几乎没有替代品。
- Frida 的甜蜜点:真机临时分析 + 一次性结果 + 抗检测。它的真实环境优势 Unidbg 永远比不过。
- Qiling 的甜蜜点:不是 Android 的二进制 + Python 集成。在 Android 这一块它打不过 Unidbg.
- 云手机的甜蜜点:高价值业务 + 已有基础设施。个人或小团队成本不划算,但不等于做不到 —— 单台云手机一两百块的方案也存在,做 demo / 小规模试水仍然可行,只是别预期能持续撑高并发
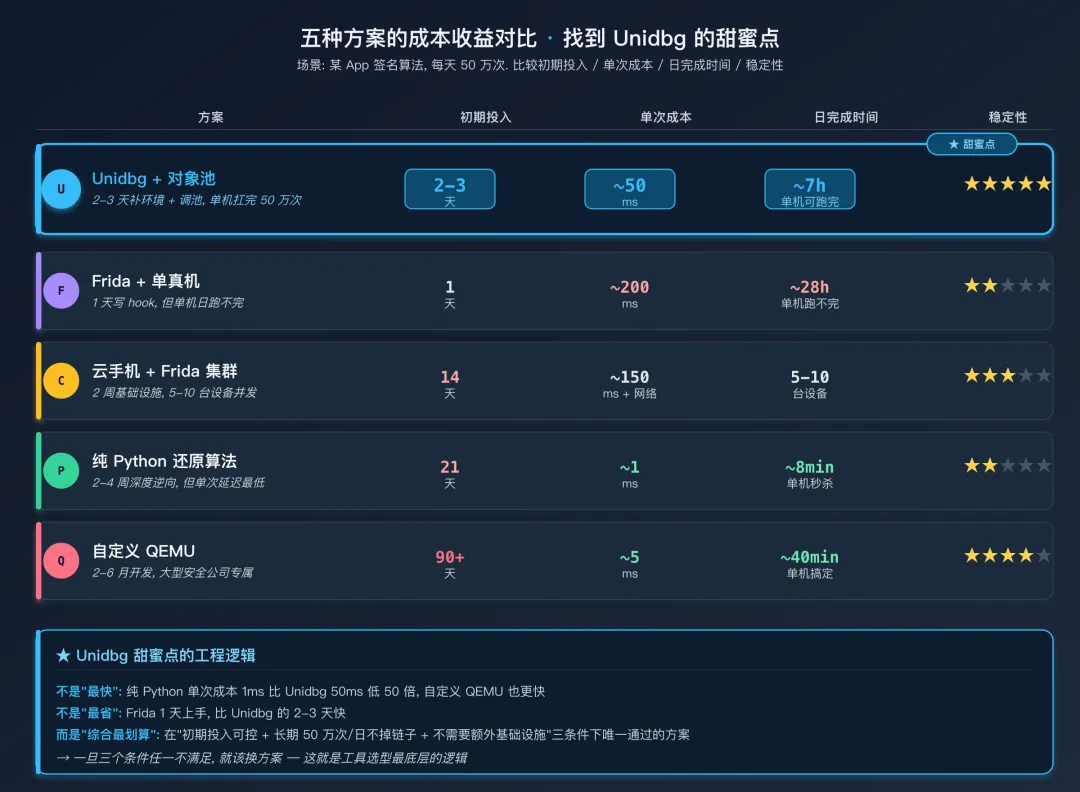
Unidbg 甜蜜点的成本收益分析
为什么说 Unidbg 在 "Android Native + 算法分析 + 中等并发" 这三个条件同时满足时几乎无可替代?做个成本收益账就明白了。以一个典型场景—— "某 App 的签名算法,每天需要算 50 万次" ——为例(下表里的耗时是数量级估计,实际值会随算法复杂度有 2-5 倍偏差,重点看相对差距):
五种方案的成本收益对比可以看到,纯 Python 还原算法的“每次调用成本”最低,但前期投入最高;自定义 QEMU 技术上最快,但半年起步的开发投入对绝大多数团队都不划算。Unidbg 在“2-3 天能跑通 + 50 万次日可扛”之间找到了甜蜜点——初期投入可控,长期运行成本合理,不需要额外基础设施,不怕真机掉线。
反过来,三个条件任何一个不满足,Unidbg 的优势都会打折:
- 不是 Android Native(比如 Windows EXE、iOS IPA)→ Unidbg 的 Android 特性用不上,还不如 Qiling。
- 不是算法分析(比如做 UI 自动化、埋点验证)→ Unidbg 没有 UI 和事件,必须真机。
- 不是中等并发(每天 10 次或每天 1 亿次)→ 前者用 Frida 更快,后者得上算法还原。
这就是工具选型最底层的逻辑:甜蜜点不是“这个工具最强”,而是“没有别的工具能在同等代价下做到这件事”。
趋势展望:这个领域往哪走
最后这一段更像是未来的预测。不一定准,但值得思考:
趋势 1:大模型辅助逆向分析
LLM 在 2023-2024 年开始进入逆向圈。现在的能力:
- 看伪代码猜功能:给 IDA F5 的输出,让 LLM 猜“这个函数在做什么”。准确率 60-80%,能省你很多眼力
- 识别算法:给一段汇编,让 LLM 判断“这是 AES 还是 SHA”。已经有专门的分类模型
- 生成 hook 代码:给一个目标函数描述,让 LLM 生成 Frida hook 脚本。已经够用
未来 1-2 年很可能出现的:
- “会用 Unidbg 的 AI” —— 你描述目标,AI 自动生成 Unidbg 调用代码 + 补环境
- 自动算法还原 —— 给一个 SO + 一些样本输入输出,AI 直接产出 Python 实现
- 自动反检测 —— AI 看 SO 的反检测代码,自动生成绕过补丁
如果这些工具成熟,手工写 Unidbg 代码的需求会大幅减少。但理解原理的需求只增不减 —— 因为你得审 AI 生成的代码对不对。
趋势 2: Rust / Go 生态的模拟器新项目
现在已经有几个用 Rust 写的轻量级 ARM 模拟器:
- unicorn-rs - Unicorn 的 Rust 绑定
- 几个不开源的内部项目(不便点名),用 Rust 重写整个 Android 模拟器栈
这些项目的优势:
- 性能更好:Rust 没有 GC,没有 JVM 启动开销
- 内存安全:Rust 的内存模型更安全,减少很多 native 层的 bug
未来可能出现一个“用 Rust 重写的 Unidbg”,兼具 Unidbg 的功能完整性和 Qiling 的嵌入性。这是个值得关注的方向。
不过要意识到这条路的工程量:Unidbg 背后十年沉淀的 AbstractJni / IOResolver / 系统调用表不是能在一两年里重新攒起来的——Rust 重写的版本要做到同等兼容度,至少需要一个全职小团队干 2-3 年。所以短期内更可能发生的,不是"某个开源新项目把 Unidbg 彻底替掉",而是"某个内部项目在特定场景下做得比 Unidbg 好,然后这些经验反哺给 Unidbg 或被零星开源"。个人工程师要跟上这个趋势,建议每半年扫一次 GitHub trending 和安全大会的议题,看看有没有冒头的新项目——别等某天发现圈子都在用新东西自己还停留在 Java 栈上。
趋势 3:硬件虚拟化加速
QEMU 的 TCG 模拟比 KVM 慢一个数量级,因为 KVM 直接用硬件虚拟化。但 KVM 要求宿主机和被模拟代码是同一架构。
未来:在 ARM 服务器上用 KVM 模拟 ARM Android,性能极高。这是阿里、腾讯这些大厂的云手机底层在做的事情。
对开源工具的影响:等 ARM 服务器普及,也许会出现“基于 KVM 的开源 Android 模拟器”,速度比 Unidbg 快 10-100 倍。
但这条路有个天然的门槛:KVM 加速要求宿主机必须是 ARM,而绝大多数研究者/小团队手里用的仍然是 x86 开发机。这意味着"KVM 加速的开源模拟器"在未来很长一段时间里都会是云厂商的内部工具,而不是个人桌面能跑的东西。对个人和小团队的启示是:不要押注"下一代免费模拟器"会让所有工作提速 100 倍,这个红利多半先落到有云服务器资源的大厂。反过来,Unidbg 这种"随便一台 Mac 就能跑"的工具,长期仍然是个人研究者的主力——它不是最快的,但是最普惠的。
趋势 4: SO 保护技术的演进
防守方也没闲着。 2024-2025 年开始出现的新技术:
- VMP(Virtual Machine Protection):把 SO 中的关键函数编译成自定义虚拟机字节码,模拟器看到的不是 ARM 指令,而是无法直接理解的 VM 指令
- 白盒密码学:把密钥嵌入到代码本身,没有“密钥”这个独立的对象,模拟器找不到
- 基于 TEE 的密钥保护:关键计算放在 TEE 内,App 进程只能“调用”,看不到内部
- Anti-Unicorn 的精细化:比第十五篇讲的还细的检测,比如观察 mmap 顺序、TLS/线程结构布局这些 Unicorn 默认不还原的"环境特征"
对应的攻击者反应:
- VMP → 需要研究 VM 的指令集,比直接逆向 ARM 难十倍
- 白盒密码学 → 需要专门的攻击工具(differential fault analysis 等)
- TEE → 几乎无解,只能 hook 调用接口看输入输出
- 反检测精细化 → Unidbg 需要不断 patch 自己,像猫鼠游戏
这个攻防游戏会持续,谁也不会完全胜利。Unidbg 的下一站,大概率是和这些新保护技术斗智斗勇。
值得多说一句 VMP,因为它是目前对 Unidbg 最致命的技术。传统的 ARM 指令执行路径是 .text 里的一条条指令被 CPU 执行,Trace 能完整记录,Hook 能精确介入——这是 Unidbg 赖以生存的前提。VMP 把这个前提彻底颠覆:样本里不再有“正常的 ARM 代码”,而是一段 handler dispatch 的“解释器循环”,循环每次读取一个自定义字节码,查表决定干什么,然后跳到下一个 handler。站在 Unicorn 角度看,执行流永远在解释器内部打转,你 Trace 到的全是 ldr/cmp/b.eq 这样的机械操作,根本看不到业务逻辑。
破 VMP 的正确姿势已经完全不同了:要先通过 handler 行为反推字节码的语义表(这一步需要大量的动态观察 + 符号执行),然后写一个“反解释器”把字节码翻译回等价的 ARM 或伪代码,最后再对翻译后的产物做正常的算法分析。这一整个流程里,Unidbg 能帮的只有“跑解释器、dump 中间 state”,它无法替你完成语义还原——那是逆向工程师的活。所以遇到 VMP 样本时,Unidbg 仍然有用,但用法完全变了:不再是“白盒分析工具”,而是“高速日志收集器”。
另一个值得关注的是TEE 化的签名流程。越来越多的金融类、支付类 App 开始把关键的加密密钥放在 TrustZone 里,App 进程只能通过 ioctl 发起调用,看到的永远是“加密后的密文”。这种架构对 Unidbg 直接是降维打击——你能跑所有的 App 侧代码,却永远拿不到密钥。应对办法只剩下“把 TEE 调用接口的输入输出对一次,做成黑盒映射”,这已经不是传统意义上的“逆向”,而是“做一个 MITM 代理”。好消息是 TEE 开发成本极高,目前只有少数头部 App 用;坏消息是一旦用了,Unidbg 基本就没戏了,必须配合真机甚至硬件攻击手段。
这些新保护技术的共同特点是:它们不阻止你分析,它们改变“分析”这个动作本身的意义。Unidbg 这一代工具适配的是“代码 = 指令流”的世界观,当代码变成“字节码 + 解释器”或“远程 TEE 调用”时,工具必须跟着进化——否则就从“万能工具”退化成“部分可用的工具”。
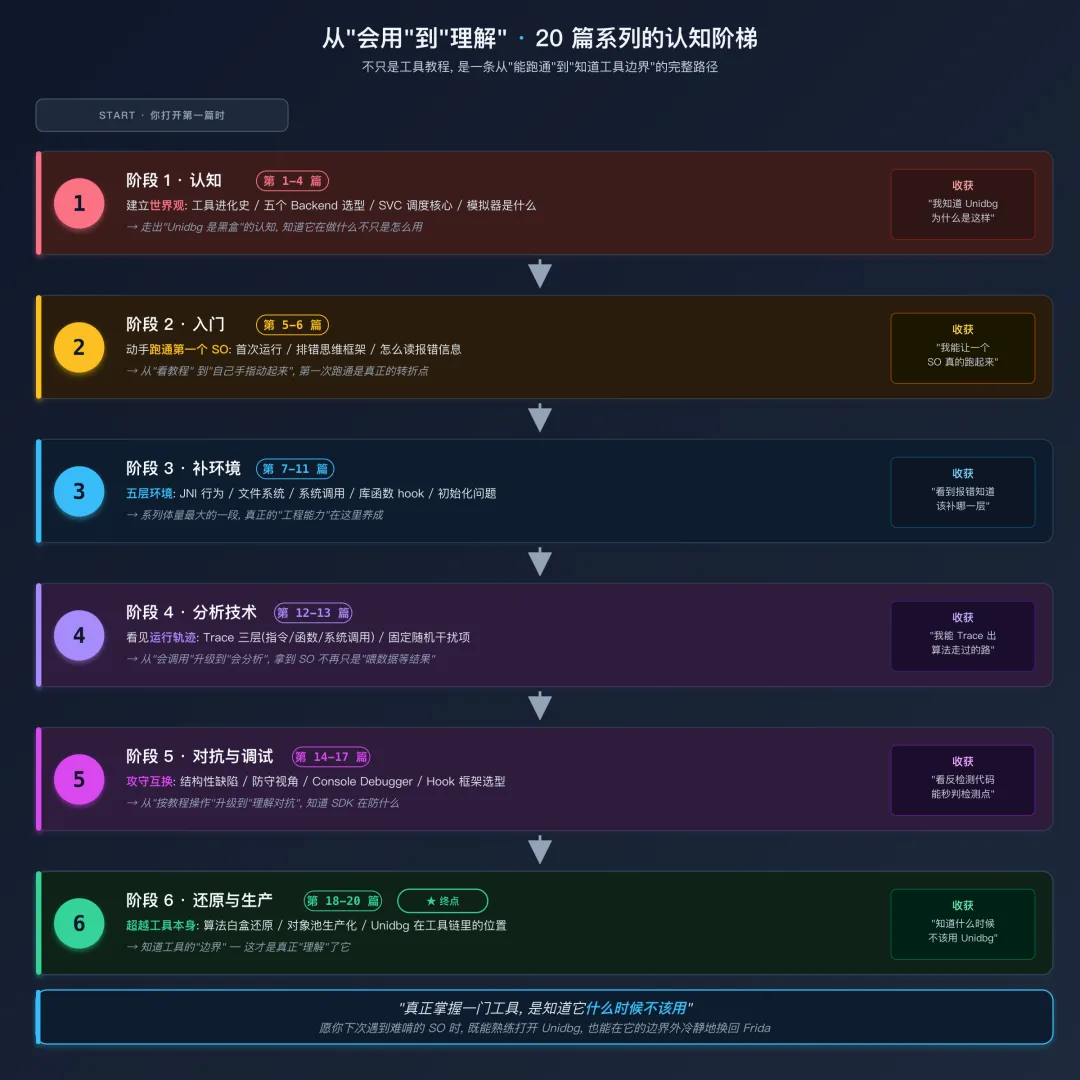
这个系列教会了你什么
写到这里,这个 20 篇的系列就结束了。回头看,我们走过了这样一条路:
20 篇系列的认知阶梯 | | |
|---|
| 认知 | | 工具进化史、世界观、五个 Backend、SVC 调度核心 |
| 入门 | | |
| 补环境 | | JNI 层、文件系统层、系统调用层、库函数层、初始化问题 |
| 分析技术 | | |
| 对抗与调试 | | 结构性缺陷、对抗视角、Console Debugger、Hook 选型 |
| 还原与生产 | | |
走完这条路,你应该能回答这些问题:
- 遇到一个 SO,你知道用 Unidbg 还是 Frida
- 遇到一个报错,你知道是 JNI 没补、syscall 没补还是 Backend 问题
- 遇到一个加密算法,你知道用 Trace 找常量、Hook dump 中间数据、对比标准实现
- 遇到一个性能要求,你知道切 Backend、池化实例、监控 RSS
- 遇到一个新场景,你知道 Unidbg 的边界在哪,什么时候该换工具
这就是从“会用 Unidbg”到“理解 Unidbg”的全部。工具会过时,但理解模拟器的思维方式不会。
“真正掌握一门工具,是知道它什么时候不该用。” 愿你下一次遇到难啃的 SO 时,既能熟练打开 Unidbg,也能在它的边界外冷静地换回 Frida.
系列附录:推荐资源
官方文档与代码
- Unidbg GitHub: https://github.com/zhkl0228/unidbg
- Unidbg 单元测试:看
unidbg-android/src/test 目录,很多示例 - Backend 实现:
Unicorn2Factory / DynarmicFactory 源码
替代工具
- Qiling Framework: https://qiling.io
- ExAndroidNativeEmu:多个 GitHub fork,选活跃度最高的
学习社区
- Reverse Engineering Stack Exchange (英文综合逆向)
- pwn.college / 0x00sec (英文 CTF + 安全社区)
进阶阅读
- "Android Hacker's Handbook" (官方介绍 Android 内部)
- "Practical Reverse Engineering" (汇编 + 调试)
- ARM Architecture Reference Manual (ARM 指令集)
最后的最后:不要迷信工具,不要崇拜框架。工具和框架都会过时,但对底层原理的理解不会。如果这个系列只能让你记住一句话,我希望那句话是:多问“为什么这么做”,少问“怎么做”。当你能回答前者,后者自然就会了。