Hook 是 Unidbg 里最容易过度设计的一环。拿到框架表看一眼,你会本能地选最强大的那个 —— 但结果常常是“一个锤子敲碎了整个桌子”。这一篇把 Unidbg 内置的六种 Hook 框架拆开,讲清楚哪种场景用哪种,以及不该用哪种。
上一篇把你留在了哪里
第十六篇我们讲了 Console Debugger,这是一把手术刀 —— 精确,但只能在你亲自操刀时生效。断点回调算是半自动化,但仍然是“点对点”的。
但有些场景,手术刀不够用:
- 想拦截
getrusage 这类 libc 函数 —— 调用点分散在 SO 里十几处,你没法一个一个下断点。 - 想把
malloc 换成自己的实现 —— 你需要的是“替换”,不是“观察”。 - 想让
free(ptr) 变成空操作 —— 断点改 PC 能做到,但每次都手动太累。
这时候需要的是Hook 框架 —— 一次注册,全局生效,代码简洁。
Unidbg 内置了不止一个 Hook 框架,而是六个。它们不是并列关系,而是从高到低五个不同的抽象层次。用错层次,代码会翻倍;用对层次,一行就搞定。
Hook 的本质
在讨论框架之前,先澄清一个概念:Hook 的本质就是“在函数调用前后插入自己的代码,而不修改原始二进制”。
实现 Hook 有三种底层技术:
| | |
|---|
| GOT/PLT Hook | | |
| Inline Hook | | |
| Engine-level Hook | | |
三种 Hook 底层技术对比不归在这三类里的两个特殊 Hook:SystemPropertyHook 用的是 HookListener 链(在 dlsym 解析符号时把目标函数重定向到 SVC handler,比 PLT 更早一层);FunctionCallListener 是 Debugger 内部基于 BL/BLR 指令钩子实现的——两者都属于"unidbg 内部 instrumentation",不是真机上能复现的传统 hook 技术。后面框架介绍里会单独讲清楚。
在真机上做 Hook,你得先考虑 SELinux 权限、cache 刷新、线程安全、同一函数不能被多个 Hook 重复注册..。一堆工程问题。
在 Unidbg 里,这些问题全部消失。因为 Unidbg 就是执行引擎本身 —— 它随时知道每条指令在哪里执行、每个函数在哪里被调用。Hook 只是“在合适的时机通知你一声”,没有 cache 一致性问题,没有权限问题,没有竞争问题。
这就是为什么 Unidbg 里可以同时内置六种不同层级的 Hook 框架,各司其职。
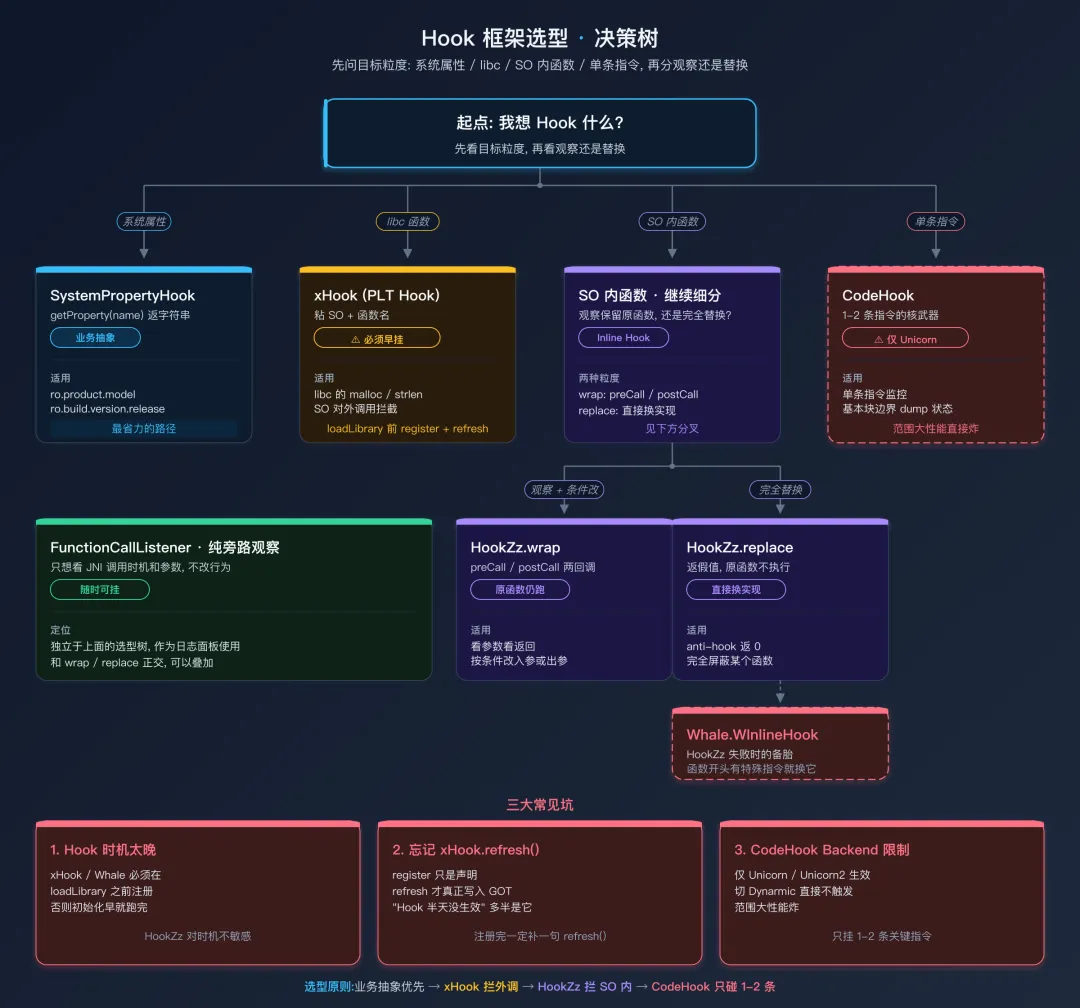
六种 Hook 框架的抽象层次
从高到低:
六种 Hook 框架的抽象层次记住这个层次感比记命令重要:
- 越往下,命令式 越强,灵活性越大,但代码量和出错概率也变大
选型的金科玉律:从上往下选,找到能完成任务的最高层级。不要直接上 CodeHook,也不要一上来就写 Inline Hook.
框架 1: FunctionCallListener - 只观察,不改变
定位:监控 JNI 函数被调用的时机和参数。
适用场景:"我只想知道这个 SO 里谁调用了 CallObjectMethodV,调用的是 Java 的哪个方法,传了什么参数"。纯观察,不打算改。
vm.setJni(new AbstractJni() {// AbstractJni 的重写中...});// FunctionCallListener 不在 Emulator / SyscallHandler 上, 而在 Debugger 上// 拿 Debugger 的姿势是 emulator.attach()Debugger debugger = emulator.attach();// 两种范围:// - traceFunctionCall(listener) 全局, 所有 module 的 BL 都拦// - traceFunctionCall(module, listener) 限定在指定 module 范围内debugger.traceFunctionCall(new FunctionCallListener() {@OverridepublicvoidonCall(Emulator<?> emulator, long callerAddress, long functionAddress){ System.out.println("call from " + Long.toHexString(callerAddress) + " -> " + Long.toHexString(functionAddress)); }@OverridepublicvoidpostCall(Emulator<?> emulator, long callerAddress, long functionAddress, Number[] args){// 可以在返回后看 x0 / args[0] }});
注意:FunctionCallListener 是个“傍观者”,你不能修改任何行为。适合做日志面板,不适合做拦截器。
框架 2: SystemPropertyHook - 专治系统属性
定位:专门拦截 __system_property_get / __system_property_find。这是 Android 里最常见的“设备指纹”来源之一。
适用场景:SO 里有这样的代码:
char buf[PROP_VALUE_MAX];__system_property_get("ro.build.fingerprint", buf);// 然后拿 buf 去对比黑名单
你想让 SO 认为自己在 "Pixel 5 / Android 13" 上。Unidbg 把这件事拆成了 SystemPropertyHook(注册成 HookListener 拦 __system_property_get / __system_property_find) + SystemPropertyProvider(你来决定每个 key 返回什么)两步:
SystemPropertyHook hook = new SystemPropertyHook(emulator);hook.setPropertyProvider(new SystemPropertyProvider() {@Overridepublic String getProperty(String key){switch (key) {case"ro.build.fingerprint":return"google/redfin/redfin:13/TQ3A.230705.001/...";case"ro.build.version.release":return"13";default:returnnull; // 未命中的返回 null, 让 Unidbg 走默认逻辑 } }});emulator.getMemory().addHookListener(hook);
构造器里强制传 Emulator 是因为 SystemPropertyHook 内部要拿 SvcMemory 注册 SVC 跳板;getProperty 是 SystemPropertyProvider 接口的方法,不是 SystemPropertyHook 自己的——这两个细节如果搞反了,IDE 直接报错。
相比用 xHook 或 HookZz 去 Hook __system_property_get 的好处:你不用自己解析 name、写结果、处理 buffer 长度。Unidbg 已经帮你做完了。
这是“业务粒度 Hook”的典型 —— 它抽象了属性读取这一个具体业务,让你只关心“返回什么值”。
框架 3: xHook (PLT Hook) - 拦截库函数调用
定位:拦截“某个 SO 调用 libc/其他 SO 的函数”。工作在 GOT/PLT 表这一层。
适用场景:SO 代码里调用了 getrusage、ioctl、gettimeofday 这类 libc 函数,你想把它们的返回值改掉。
IxHook xHook = XHookImpl.getInstance(emulator);xHook.register("libtarget.so", "getrusage",new ReplaceCallback() {@Overridepublic HookStatus onCall(Emulator<?> emulator, HookContext context, long originFunction){ RegisterContext ctx = emulator.getContext();int who = (int) ctx.getLongArg(0); Pointer rusage = ctx.getPointerArg(1);// 构造假的 rusage 数据 rusage.setLong(0, 100); // ru_utime.tv_secreturn HookStatus.LR(emulator, 0); // 直接返回 0, 不调用原始函数 } }, true);xHook.refresh(); // 必须调用, 才能真正生效
xHook 的三个关键点
粒度是“SO + 函数名”:你是在拦截“libtarget.so 调用 getrusage”,而不是全局拦截 getrusage。其他 SO 调用 getrusage 不受影响。这正是 PLT Hook 的本质。
第一参数是正则不是精确字符串:源码 IxHook.java:13 上明确叫 pathname_regex_str。"libtarget.so" 因为是合法 regex 子串所以能精确匹配,但你也可以用 "lib.*\\.so" 一次拦多个 SO 的同一个函数,或者用 ".*" 做全局拦截。这是隐藏能力点,多数人不知道。
xHook.refresh() 不能忘:xHook 的注册是批量应用的,必须调 refresh() 才会真正写入 GOT 表。我见过不止一个人 Hook 半天没生效,原因就是忘了 refresh.
忘记 refresh 的失败现场长什么样
这个坑我亲眼见过无数次,几乎每个刚上手的同事都会踩一遍,所以值得把“忘了 refresh” 的症状完整记录下来,下次你遇到就能秒识别。
假设你写了这样一段“看起来完全正确”的代码,想 hook getrusage:
IxHook xHook = XHookImpl.getInstance(emulator);xHook.register("libtarget.so", "getrusage", new ReplaceCallback() {@Overridepublic HookStatus onCall(Emulator<?> emulator, HookContext ctx, long originFunction){ System.out.println("[hook] getrusage called!");return HookStatus.LR(emulator, 0); }}, true);// 忘了调 xHook.refresh()DalvikModule dm = vm.loadLibrary(new File("libtarget.so"), true);dm.callJNI_OnLoad(emulator);
跑起来你会看到:
I/Hooks - Register getrusage success for libtarget.so[程序正常输出...](整个运行完都不会出现 "[hook] getrusage called!")
关键症状是“注册时 success,但回调从不触发”。日志里 Register xxx success 只说明 xHook 把你的回调登记到了内部表里,真正的 GOT 改写要等 refresh() 被调用时才发生。一旦你漏了这一步,SO 加载时走的是未经修改的 GOT,调用自然还是原始的 getrusage。
补一行就好:
xHook.register("libtarget.so", "getrusage", callback, true);xHook.refresh(); // 这一行!DalvikModule dm = vm.loadLibrary(...);
这个设计其实有它的道理——refresh 是一个昂贵的操作(要遍历 PLT/GOT 改写),如果每次 register 都自动 refresh,注册 10 个 hook 就要 refresh 10 次。把它做成显式调用,让用户一次性注册完再 refresh,性能好得多。但代价就是新手会漏。
社区的惯例是写一个 helper 函数把 register + refresh 封装起来,避免忘记:
publicstaticvoidregisterAndApply(IxHook xHook, String soName, String fn, ReplaceCallback cb){ xHook.register(soName, fn, cb, true); xHook.refresh();}
看着冗余,但至少再也不会忘。
适用场景:所有对 libc / 其他第三方 SO 的函数拦截。几乎不适用于 SO 内部自己的函数。
框架 4: HookZz (Inline Hook) - 函数入口拦截
定位:在任意函数的入口处插入回调。既可以“观察参数”,也可以“替换整个函数”。
适用场景:你想 Hook SO 内部一个函数(比如 sub_1A34),在它被调用时看参数,根据参数决定“让它正常执行”还是“直接返回假值”。
IHookZz hookZz = HookZz.getInstance(emulator);hookZz.wrap(module.base + 0x1A34, new WrapCallback<HookZzArm64RegisterContext>() {@OverridepublicvoidpreCall(Emulator<?> emulator, HookZzArm64RegisterContext ctx, HookEntryInfo info){long arg0 = ctx.getXLong(0); System.out.println("preCall x0 = " + arg0);// 可选: 在这里修改寄存器// ctx.setXLong(0, newValue); }@OverridepublicvoidpostCall(Emulator<?> emulator, HookZzArm64RegisterContext ctx, HookEntryInfo info){long retVal = ctx.getXLong(0); System.out.println("postCall ret = " + retVal);// 可选: 在这里修改返回值// ctx.setXLong(0, 0); }});
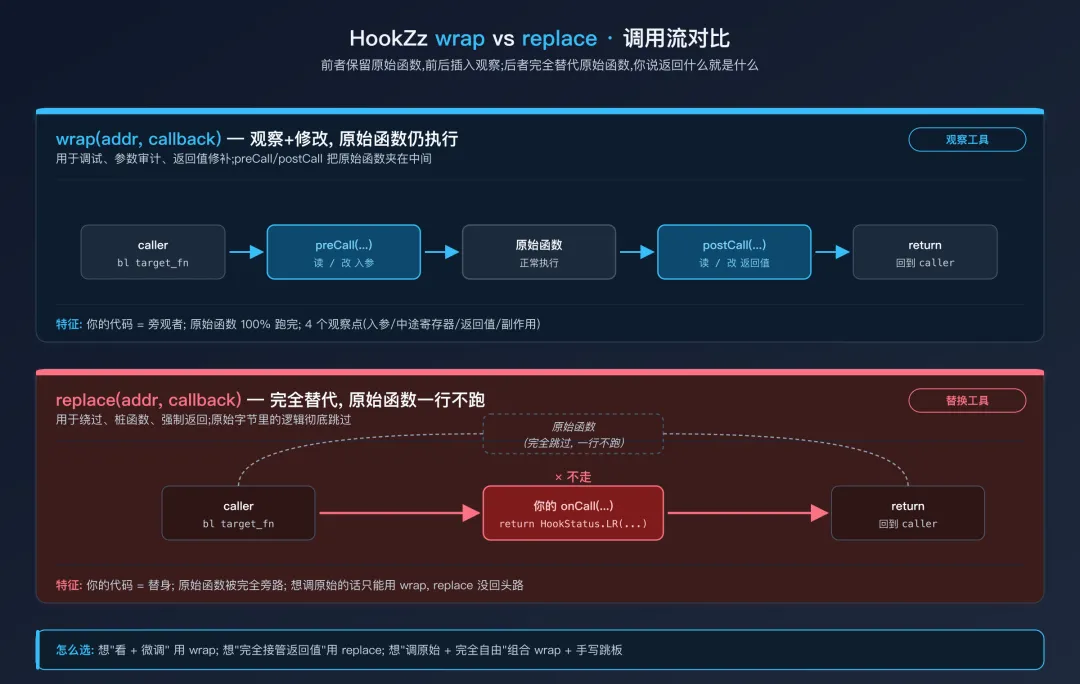
wrap vs replace 的区别
HookZz 提供两种模式:
wrap(addr, callback):在函数前后都插入回调,原始函数仍然执行。你可以观察 + 修改参数/返回值。replace(addr, callback):你的回调完全替代原始函数。返回什么,函数就返回什么。原始代码一行都不执行。
用 wrap 调试和观察,用 replace 做替换。
HookZz wrap vs replace 调用流对比hookZz.replace(module.base + 0x1A34, new ReplaceCallback() {@Overridepublic HookStatus onCall(Emulator<?> emulator, HookContext context, long originFunction){// 不调用 originFunction, 直接返回 42return HookStatus.LR(emulator, 42); }});
HookZz 和 xHook 的分界:如果你要 Hook 的是 SO 内部的函数,用 HookZz;如果是 调用其他 SO 的外部函数,用 xHook。两者管理不同层级的跳板。
框架 5: Whale (Inline Hook) - 暴力函数替换
定位:类似 HookZz 的 replace,但更直接,没有 preCall/postCall 的概念。
适用场景:你不需要观察原始参数,也不需要调用原始函数,就是想"从今天起 free 什么都不做"。
IWhale whale = Whale.getInstance(emulator);whale.inlineHookFunction(module.findSymbolByName("free"),new ReplaceCallback() {@Overridepublic HookStatus onCall(Emulator<?> emulator, long originFunction){// 直接返回, 不做任何事return HookStatus.LR(emulator, 0); } });
Whale 和 HookZz 怎么选
实话说,它们的能力几乎重叠。社区实践的经验:
- Whale 作为后备:如果遇到 HookZz 在某个函数上工作异常(常见于函数开头有特殊指令),试试 Whale.
Tip:不要因为“我不需要观察参数”就选 Whale。 HookZz 的 replace 也能做到完全替换,代码量差不多,但稳定性更好。
框架 6: CodeHook / BlockHook - 指令级核武器
定位:在任意指令地址或基本块边界插入回调。这是 Unidbg 最底层的 Hook,直接挂在 CPU 模拟器上。
适用场景:你想监控 SO 内部某条指令(不是函数)的执行,比如:
- 在算法主循环的某条指令上,dump 当前寄存器状态
// CodeHook: 每次执行某个地址范围的指令都触发emulator.getBackend().hook_add_new(new CodeHook() {@Overridepublicvoidhook(Backend backend, long address, int size, Object user){ System.out.println("executing instruction at 0x" + Long.toHexString(address));long x0 = backend.reg_read(Arm64Const.UC_ARM64_REG_X0).longValue(); System.out.println(" x0 = " + x0); }}, module.base + 0x1B00, module.base + 0x1B00, null); // 只对 0x1B00 这一条指令触发
CodeHook 的强大和代价
- 强大:这是唯一能做到“指令粒度”拦截的 Hook。 Trace 本身就是用 CodeHook 实现的。
- 代价:范围大一点性能就炸掉。每条指令都触发一次 JNI 回调,开销是巨大的。
- 陷阱:CodeHook 仅在 Unicorn / Unicorn2 Backend 上可用;切到 Dynarmic 后**直接抛
UnsupportedOperationException**(见 DynarmicBackend.java 对 hook_add_new(CodeHook, ...) 的实现),不是"偶发不生效"而是完全不支持。要做指令级 hook 就只能用 Unicorn 系列。
使用纪律:
- 范围尽可能窄。不要做 “Hook 整个函数” 这种事,用 HookZz 代替。
- 回调里的代码尽量短。不要在里面打印大量内容,不要做 IO.
- 只在“非做不可”的时候用 —— 高层 Hook 全都不适用时。
选型决策表Hook 框架选型决策树
把上面的内容压缩成一张表,贴在显示器旁边:
| | |
|---|
| xHook | |
| SystemPropertyHook | |
| HookZz (wrap) | |
| HookZz (replace) | |
| Whale | HookZz 的备胎,换一个 Inline Hook 实现 |
| FunctionCallListener | |
| CodeHook | |
| 不要用 CodeHook! 用 Trace | Trace 本身就是 CodeHook 封装,性能更好 |
三个常见的坑
坑 1:Hook 时机 —— 不同框架约束不一样
各框架的"必须在什么时候注册"不能一概而论,混淆会导致 Hook 不生效或生效不完整。一张对照表:
| | |
|---|
| xHook | 必须在目标函数首次被调用之前注册 + refresh() | xHook 改写 PLT/GOT 表项,已经走过 PLT 的调用不会再查表 |
| HookZz | | Inline hook 改函数入口字节,已经在执行的代码不会回头读改后的字节 |
| Whale | 必须在 loadLibrary 之后(要 findSymbolByName 找到目标) + 首次调用之前 | |
| CodeHook / SystemPropertyHook / FunctionCallListener | | 直接挂在 backend / debugger / hook listener 链上,运行时动态匹配 |
实战中最常见的姿势:
// 推荐姿势: loadLibrary 之前注册 xHook 的"基础消毒"xHook.register("libtarget.so", "gettimeofday", fakeTimeCb, true);xHook.refresh();DalvikModule dm = vm.loadLibrary(new File("libtarget.so"), true);dm.callJNI_OnLoad(emulator);// 之后再做 Whale / HookZz 的 SO 内函数 hook (此时 module 已加载, 能 findSymbol)Whale.getInstance(emulator).inlineHookFunction(module.findSymbolByName("free"), freeCb);hookZz.replace(module.base + 0x1A34, envIntegrityCb);
常见误区:很多文章说"xHook 必须在 loadLibrary 之前",更准确的说法是"必须在目标函数被首次调用之前"。Unidbg 自带测试 JniDispatch64.java 里 xHook 是在 loadLibrary + callJNI_OnLoad 之后注册的,照样工作 —— 因为 OnLoad 期间没调那个 hook 目标函数。但实战里**JNI_OnLoad 经常会调 libc 函数**(如初始化时间戳、读 system property),所以保守做法是 xHook 放最前面。
Whale 反而必须在 loadLibrary 之后,因为要先 findSymbolByName 拿到目标函数符号 —— 这跟 xHook 时机相反,新手容易搞混。
坑 2:多个框架 Hook 同一函数的行为
假设你同时用 xHook 和 HookZz 去 Hook malloc,会发生什么?
答案:取决于谁后生效。通常后注册的覆盖前注册的。不要依赖这个行为,因为它在不同版本的 Unidbg 里可能变化。
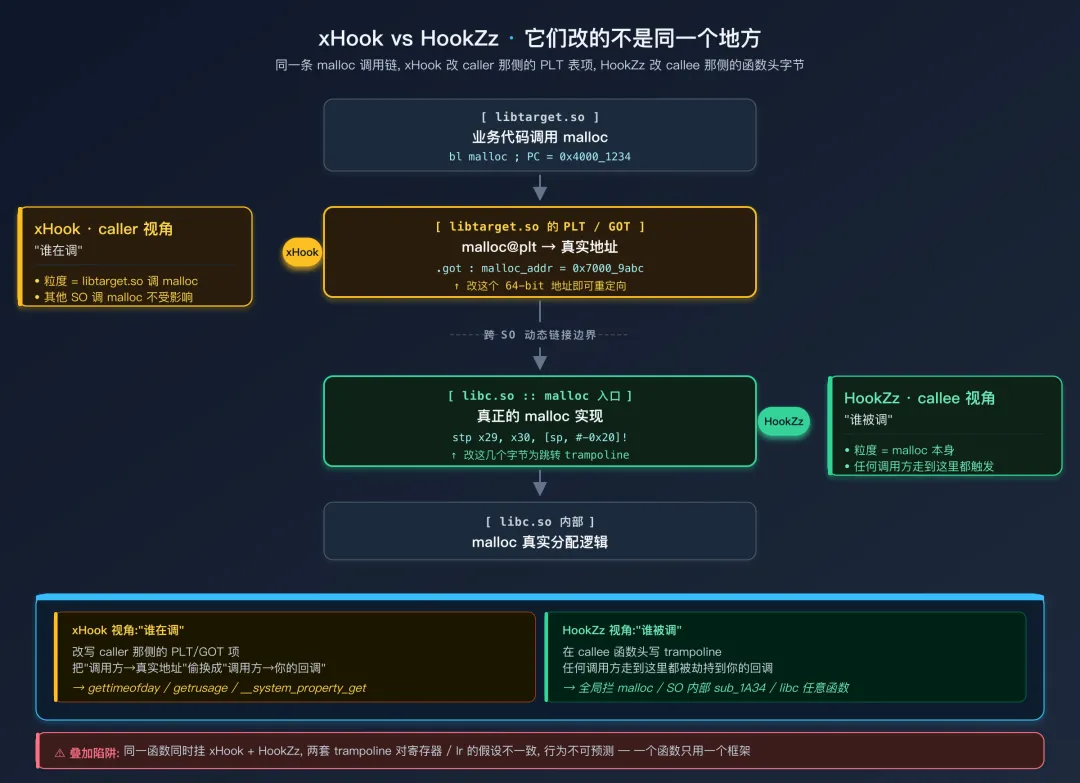
为什么不要混用:两个框架在改不同的地方
设想一种常见的混用动机:一处用 xHook 做“统计所有 malloc 调用次数”(审计用途),另一处用 HookZz 做“拦截超过 1MB 的大 malloc,返回 NULL 模拟 OOM”(故障注入用途)。两个 hook 单独跑都对,一起跑就开始有奇怪问题——计数对不上、OOM 偶发触发、栈回溯偶尔崩。
根因在于两个框架改的不是同一个位置:
- xHook 改的是 PLT/GOT:拦截的是“SO 内部调用
malloc 这个外部符号”的入口,被 hook 的对象是调用方那一侧。 - HookZz 改的是
malloc 函数头:在 libc 真实的 malloc 头部写跳转,被 hook 的对象是被调方那一侧。
两边各自对“调用链”的假设不一样:xHook 的 trampoline 假设跳过去之后调用的是原始 malloc 头;HookZz 的 trampoline 假设进来时是从正常调用点过来的。一旦叠加,两个 trampoline 之间对寄存器保存(尤其是 lr)、对原始指令备份的假设就可能错位,组合行为变成不可预测。
这类问题不属于“哪个框架有 bug”,而是两个 hook 框架对“函数调用”的建模不一致:xHook 建模的是“谁在调”,HookZz 建模的是“谁被调”。同时生效就像在同一段路上同时铺两套红绿灯,结果取决于二者的安装顺序和触发顺序,没法稳定。
xHook 改 caller 侧 PLT;HookZz 改 callee 侧函数头最佳实践:一个函数只用一个 Hook 框架。如果需要多级 Hook(比如既要统计又要拦截),在同一个 Hook 回调内部自己组合逻辑:
// 坏示范: 两个框架各hook一个目的xHook.register("libtarget.so", "malloc", countingCb, true);hookZz.wrap(mallocAddr, oomInjectionCb);// 好示范: 一个 Hook 同时做两件事hookZz.wrap(mallocAddr, new WrapCallback<...>() {@OverridepublicvoidpreCall(...){ counter.incrementAndGet(); // 统计long size = ctx.getXLong(0);if (size > 1024 * 1024) { ctx.setXLong(0, 0); // OOM 注入// 或用 replace + HookStatus.LR 直接返回 NULL } }});
坑 3: Backend 限制
如果你用了 CodeHook,必须确保 Backend 是 Unicorn / Unicorn2. Dynarmic 虽然快,但没法在指令粒度上打断。
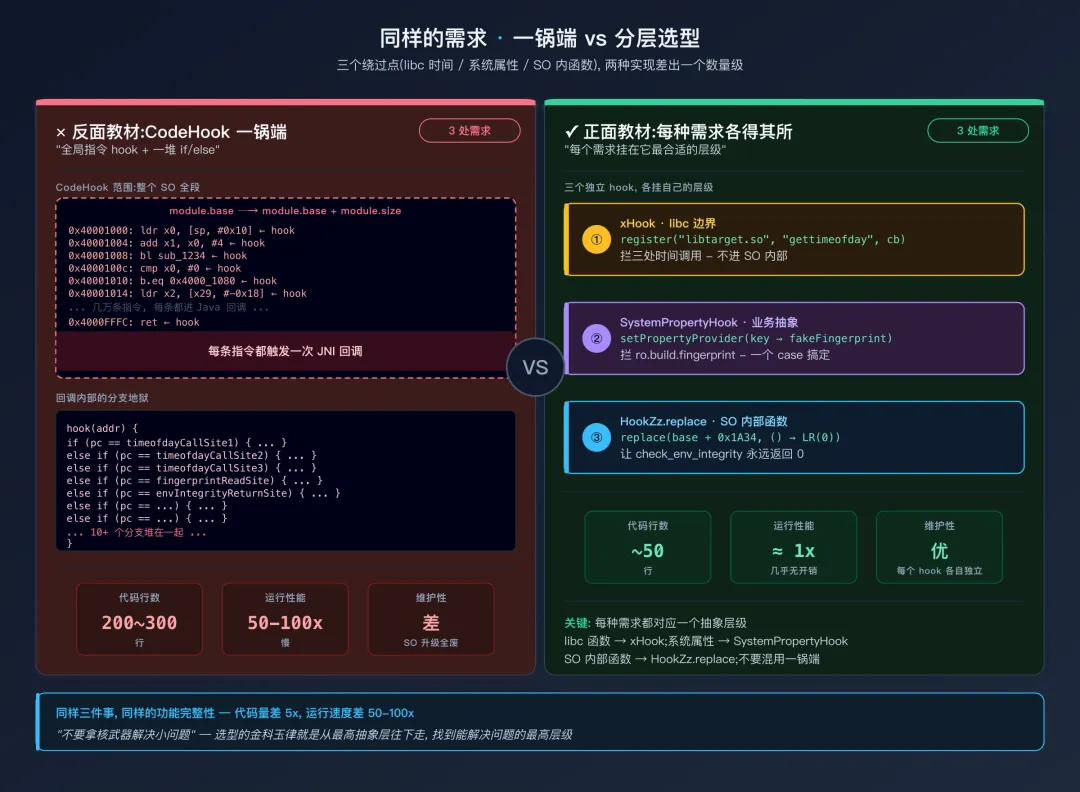
一个典型的选型走样案例
设想一个常见的反检测目标,要对付的样本有三个绕过点:
- SO 会调用
gettimeofday 三次,然后对比时间差。模拟器上每次返回一样,直接被识别。 - SO 会读
ro.build.fingerprint 并和黑名单匹配。 - SO 里有个
check_env_integrity() 函数返回 1 表示“检测到异常”,希望让它固定返回 0.
第一版设计(新手陷阱):
按"我都不知道用啥就先上 CodeHook"的思路,在 SO 全段范围下一个 CodeHook,按 PC 分发到每个目标地址。代码很容易膨胀到 200~300 行,跑起来贼慢,每条指令都走一遍回调。
具体坏在哪里?第一版代码的骨架是这样:
// 反面教材: 用 CodeHook 处理所有事emulator.getBackend().hook_add_new(new CodeHook() {@Overridepublicvoidhook(Backend backend, long address, int size, Object user){long pc = address;// 针对每个敏感地址做判断if (pc == timeofdayCallSite1 || pc == timeofdayCallSite2 || pc == timeofdayCallSite3) {// 改 x0 把 gettimeofday 返回值做手脚 ... } elseif (pc == fingerprintReadSite) {// 改 x0 指向伪造的字符串 ... } elseif (pc == envIntegrityReturnSite) {// 改 x0 = 0 让 check_env_integrity 返回 0 backend.reg_write(Arm64Const.UC_ARM64_REG_X0, 0); }// ... 还有其他 10 来个分支 }}, module.base, module.base + module.size, null);
问题很明显:
- 每条指令都进回调——在
module.base 到 module.base + module.size 的全量 hook,意味着 SO 里每一条指令都要进 Java 层检查 pc 是不是自己关心的那几个地址,这个 JNI 开销是灾难级的,慢 50-100 倍。 - 分支地狱——十几个
if/else 挤在一个回调里,加一个需求就得改这个函数,代码腐烂极快。 - 地址硬编码脆弱——SO 一旦升级,所有
pc == xxx 都要重新对,维护成本爆炸。
CodeHook 一锅端 vs 三种 Hook 分层第二版设计(按层级选):
gettimeofday → xHook(libc 函数)—— 二十来行ro.build.fingerprint → SystemPropertyHook(业务层抽象)—— 十来行check_env_integrity() → HookZz.replace(SO 内部函数)—— 十来行
总量降到几十行,跑起来速度和没 Hook 一样,效果完全一致:
// 正面教材: 每种需求用最合适的框架// gettimeofday -> xHook (libc 层)xHook.register("libtarget.so", "gettimeofday", new FakeTimeCallback(), true);xHook.refresh();// ro.build.fingerprint -> SystemPropertyHook (业务层)SystemPropertyHook propHook = new SystemPropertyHook(emulator);propHook.setPropertyProvider(new SystemPropertyProvider() {@Overridepublic String getProperty(String key){if ("ro.build.fingerprint".equals(key)) {return"google/redfin/redfin:13/TQ3A.230705.001/..."; }returnnull; }});emulator.getMemory().addHookListener(propHook);// check_env_integrity -> HookZz.replace (SO 内部)hookZz.replace(module.base + 0x1A34, new ReplaceCallback() {@Overridepublic HookStatus onCall(Emulator<?> emulator, long originFunction){return HookStatus.LR(emulator, 0); // 直接让函数返回 0 }});
注意 ReplaceCallback 是抽象类不是函数式接口,不能用 lambda 写,必须用匿名内部类——这是新手在 IDE 里第二个最容易栽的坑。
代码量从几百行的 CodeHook 分支地狱压到几十行,运行速度回到“几乎无 hook”的水平,还附带一个隐性好处:可读性暴涨。新同事接手时看第二版,一眼就知道每个 hook 解决什么问题;看第一版则要读完整个分支地狱才能理解意图。
这就是层级选型的威力 —— 同样的功能,代码量差一个数量级,性能差几十倍,可维护性更是云泥之别。
HookZz ctx 范式:算法分步 hook 的工业级写法
层级选型告诉你用哪个 Hook 框架,但怎么用 HookZz 的 ctx 参数才是分析师每天打交道的细节。下面用抖音 TTEncrypt 算法的真实样本(AwemeTTEncrypt.java)说明一种"分步 hook + ctx push/pop 配对"的范式——一个完整的算法被拆成 4 个 Hook,每个 Hook 都有对称的 preCall / postCall。
// 给 AES 函数 (libEncryptor.so:0x3640) 挂 hook, 同时 dump 入参和出参// 函数名按"hookSub<offset>"约定, 方便和 IDA 反汇编的偏移直接对照publicvoidhookSub3640(){ IHookZz hookZz = HookZz.getInstance(emulator); hookZz.wrap(module.base + 0x3640 + 1, new WrapCallback<HookZzArm32RegisterContext>() {@OverridepublicvoidpreCall(Emulator<?> emulator, HookZzArm32RegisterContext ctx, HookEntryInfo info){// 入参: r0 = 输入指针, r1 = 输出指针 Pointer input1 = ctx.getPointerArg(0); Inspector.inspect(input1.getByteArray(0, 0x100), "AES 输入"); Pointer input2 = ctx.getPointerArg(1); Inspector.inspect(input2.getByteArray(0, 0x100), "AES 输出指针 (此时为空)");// 关键: 把指针 push 到 ctx 栈上, 等 postCall 再读 ctx.push(input2); ctx.push(input1); }@OverridepublicvoidpostCall(Emulator<?> emulator, HookZzArm32RegisterContext ctx, HookEntryInfo info){// 关键: 弹出顺序和 push 相反 (LIFO) Pointer output1 = ctx.pop(); Pointer output2 = ctx.pop();// 此时输出指针已经被 SO 填充, dump 出来就是 AES 加密结果 Inspector.inspect(output1.getByteArray(0, 0x100), "AES 输入(再确认)"); Inspector.inspect(output2.getByteArray(0, 0x100), "AES 输出(已填充)"); } });}
整个 TTEncrypt 算法被拆成 4 个独立的 Hook,每个对应一个算法步骤:
| | | |
|---|
hookSub3BB8 | +0x3BB8 | | |
hookSub3640 | +0x3640 | | 每轮 AES 都触发, dump 密钥 + 输入 + 输出 |
hookSub8BAC | +0x8BAC | | dump SHA512 输入 + 输出(用于推导 AES 密钥) |
hookSub8214 | +0x8214 | | |
ctx push/pop 的核心价值:HookZz 的 preCall 和 postCall 是两个独立的回调,它们之间默认不共享变量。如果你想在 postCall 里看 preCall 时拿到的指针(比如"输入参数指向的内存,函数返回后可能已经被填充了输出"),就必须用 ctx 栈传递。这是 HookZz 的线程安全设计——每个 Hook 实例自己维护一个 ctx 栈,避免你自己写 ConcurrentHashMap。
几个关键约束:
- push 顺序 = 出栈顺序的反序(LIFO)。先 push 的最后 pop。
- preCall push 几次, postCall 必须 pop 几次——不配对会泄漏 ctx 栈,长时间跑会累积。
+1 后缀(module.base + 0x3640 + 1)—— ARM32 Thumb 模式标志,必须加;ARM64 不需要这个 +1。Inspector.inspect(bytes, label) 是 Unidbg 自带的工具,按 16 字节一行打印 hex+ASCII,比手写 bytesToHex 强得多。
为什么不用 replace 而用 wrap:分析阶段你想"观察"算法的中间状态,不想替换它的逻辑。等观察清楚了再用 Python 复刻整个算法。这是第十八章「算法还原」的工作流——wrap 是观察工具,replace 是替换工具,两者用途完全不同。
总结
| |
|---|
| |
| |
| |
| xHook 拦 SO 外的库函数,HookZz 拦 SO 内的函数 |
| |
| |
| Hook 时机太晚 / 忘记 xHook.refresh() / 用 CodeHook 做大范围 Hook |
一句话原则:不要拿核武器解决小问题。每一个 Hook 需求,都应该先问自己:“我能用最高层的框架解决吗?” 答案是 yes 的话,就选那个。答案是 no,再往下走一层。能用 SystemPropertyHook 一行代码搞定的,绝不用 CodeHook 写一百行。