大多数 Unidbg 教程到“能调出结果”就结束了。但真实业务里,你常常要把 Unidbg 当成一个线上中间件 —— 接 HTTP 请求,每秒处理几百次签名计算,24 小时不挂。从“能跑”到“能用于生产”之间,有一段工程化的路要走。这一篇就是这条路上的全图。
上一篇把你留在了哪里
第十八篇我们讲了算法还原 —— 那是 Unidbg 的“分析模式”。还原成功之后,你可以扔掉 Unidbg,用 Python 直接算。
但还原不是总是划算的。一个签名算法你愿意花两周还原,因为它每天被调用几十亿次;一个验证码算法你不愿意还原,因为它每天只调几千次,直接用 Unidbg 算就好了。
这种“不还原,直接当服务用”的场景,就是这一篇的主题。我们要把 Unidbg 从一个单线程的分析脚本,变成一个能跑在生产环境的高并发服务。
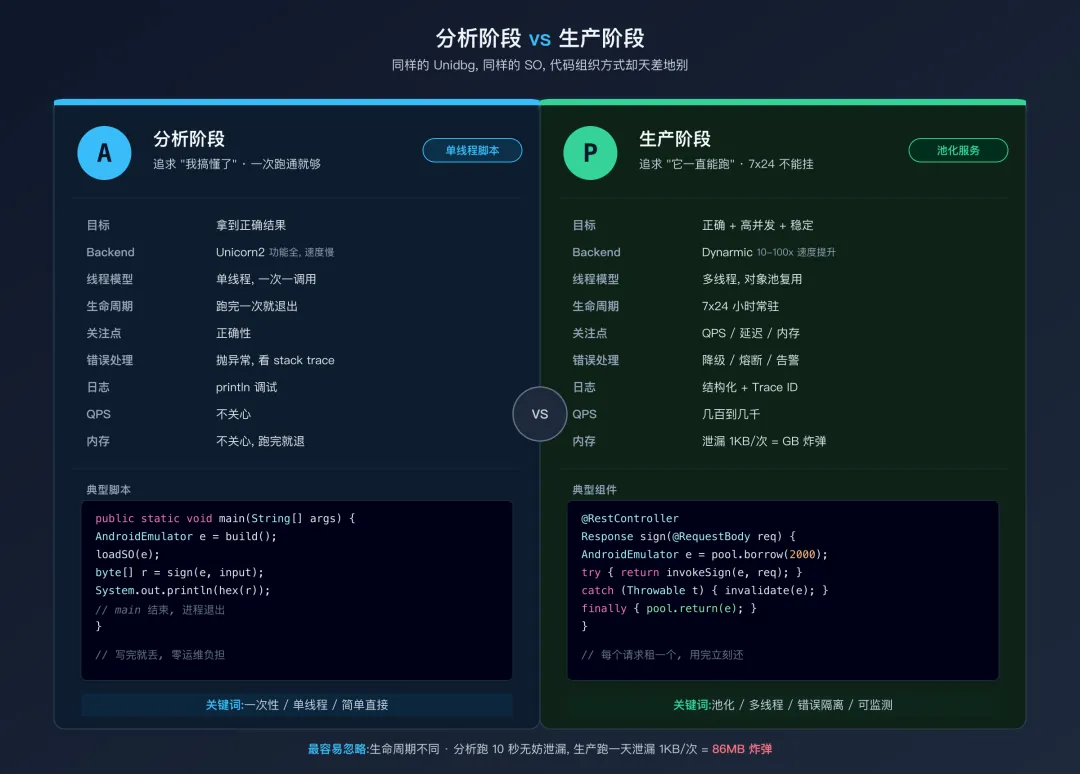
分析阶段 vs 生产阶段:关注点完全不同分析阶段 vs 生产阶段的关键差异
很多人把“分析阶段的代码”直接搬到生产,然后被各种问题轰炸。根本原因是没意识到:
| | |
|---|
| 目标 | | |
| Backend | | |
| 线程模型 | | |
| 生命周期 | | |
| 关注点 | | |
| 错误处理 | | |
| 日志 | | |
最容易被忽略的一条:生命周期。分析阶段的代码跑完就退出,内存泄漏不重要;生产阶段每天跑 86400 秒,哪怕一次调用泄漏 1KB,一天也是 GB 级别的炸弹。
第一个坑:AndroidEmulator 不是线程安全的
新手生产化的第一步,通常是这样:
// 在 Spring Bean 里, 一个全局 AndroidEmulator
@Component
publicclassSignService{
privatefinal AndroidEmulator emulator;
publicSignService(){
this.emulator = AndroidEmulatorBuilder.for64Bit().build();
// ... 加载 SO
}
publicbyte[] sign(byte[] input) {
// 多线程同时调用这个方法 -> 灾难
return invokeSign(emulator, input);
}
}
这是错的。AndroidEmulator 不是线程安全的。内部的:
- 模拟 CPU 寄存器(单例,多线程同时改 → 数据竞争)
这些都是单实例的。多线程并发调用同一个 emulator,你会看到:
- 偶发的 segfault (Backend 抛异常)
这些 bug 几乎不可复现,因为它们依赖时序。一旦在生产环境出现,你会查得想哭。
正确思路:每个并发请求必须用独立的 emulator 实例。这是无法绕过的硬约束。
一种看似聪明的偷懒:单实例 + synchronized
知道"硬约束"之后,新手最常见的第一反应不是"那我搞多个实例",而是:**"那我加把锁不就行了?"** 网上能搜到的"unidbg + Spring Boot" 模板里 80% 都是这种写法:
// 注: 这是反面教材, 用来说明"硬约束为什么硬"
@RestController
@RequestMapping("/qqmusic")
publicclassQQMusicController{
@Autowired QQMusicRecognizer qqMusicRecognizer; // @Component, 全局单例
@RequestMapping(value = "prepareFeature", method = RequestMethod.POST)
public String prepareFeature(@RequestParam("inputData") String inputData) {
synchronized (this) { // ← 关键: 全局锁
return qqMusicRecognizer.prepareFeature(inputData);
}
}
}
这种写法"能跑"——但代价是放弃了并发本身。synchronized 保证了同一时刻只有一个请求在用 emulator,确实规避了线程不安全。但同时:
- QPS 等于单线程吞吐。无论服务器有多少核,所有请求串行通过这把锁。8C 的机器和 1C 的机器在这种部署下表现一样
- 请求堆积时延迟爆炸。signature 计算 50ms,并发 50 请求时第 50 个要等 2.5 秒——而 P99 告警阈值通常就是 200ms
它的根本问题不是"不安全",而是用最粗暴的同步把并发降级成串行——解决了"线程不安全" 这个症状,但完全放弃了"并发"这件事本身。这就是上一节"硬约束"为什么硬:你以为可以用一把锁绕过去,但代价是你不再有一个"高并发服务",只有一个"穿了 HTTP 外衣的串行脚本"。
synchronized 串行 vs 对象池并发的时序对比8 个并发请求、每次 sign 50ms:synchronized 让 R8 等到 400ms 才完成、QPS 卡死在 20、CPU 利用率只有 12.5%;对象池让 8 个请求 50ms 一并跑完,QPS 直冲 160。8C 机器跑出 1C 还是 8C 性能,就在这一处。
它在两种场景下仍然合理:PoC / Demo 阶段(先跑通再优化)和极低流量内部工具(每天调用 < 1000 次)。但凡涉及对外 API、高并发场景、或多核服务器,都不应该停在这一步。
下面这三种方案就是"如何真正满足硬约束"的递进路径——从最简单的 ThreadLocal 到工业级的对象池。
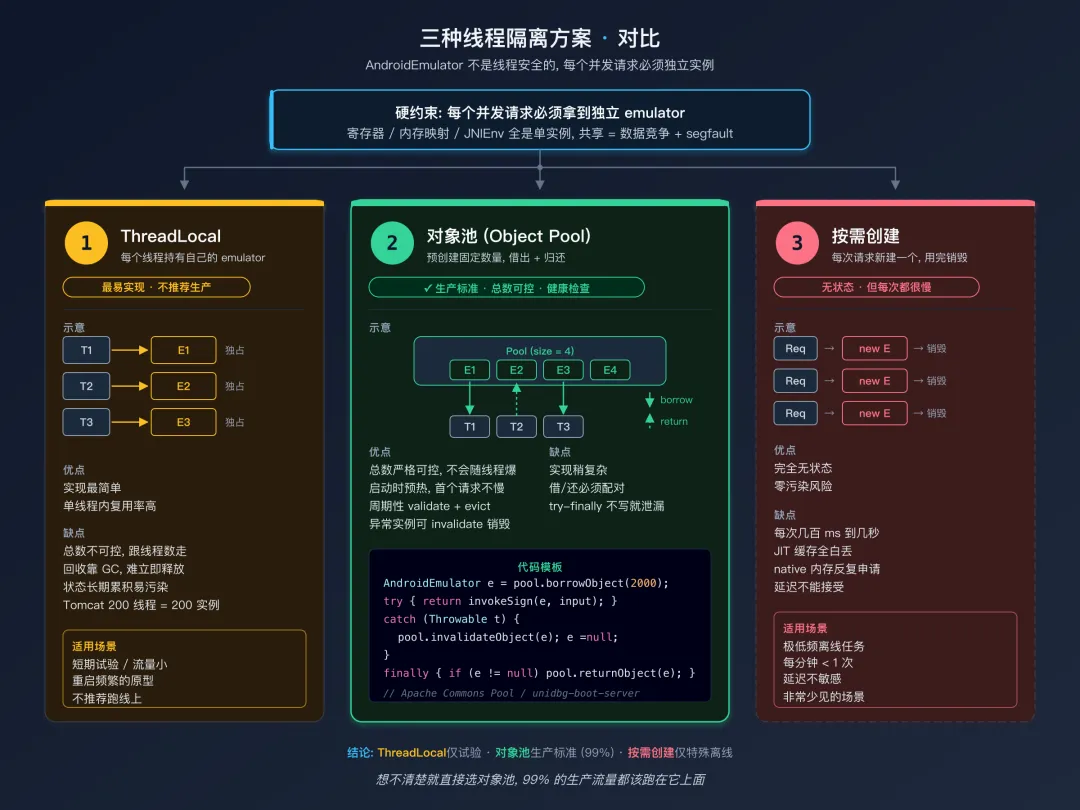
三种线程隔离方案对比三种 Emulator 实例隔离方案
每个请求要独立实例,怎么管理这些实例呢?三种主流方案:
方案 1: ThreadLocal
每个线程持有自己的 emulator,第一次访问时创建,之后复用。
privatestaticfinal ThreadLocal<AndroidEmulator> EMULATOR = ThreadLocal.withInitial(() -> {
AndroidEmulator e = AndroidEmulatorBuilder.for64Bit().build();
// 加载 SO ...
return e;
});
publicbyte[] sign(byte[] input) {
AndroidEmulator e = EMULATOR.get();
return invokeSign(e, input);
}
优点:实现简单,一个线程一个 emulator,复用率高。
缺点:
- 不能控制总数。如果用 Tomcat 默认 200 线程池,你就有 200 个 emulator。内存可能爆掉。
- 回收难。ThreadLocal 不会主动 close emulator,线程死的时候 emulator 也只是被标记为可回收,内存不会立刻释放。
- 状态可能污染。一个线程长期使用同一个 emulator,内部状态(全局变量、堆碎片、文件描述符泄漏)会越积越多。
适用场景:短期试验,流量不大,重启频繁。
方案 2:对象池
预创建固定数量的 emulator,并发请求从池里借,用完归还。
GenericObjectPool<AndroidEmulator> pool = new GenericObjectPool<>(
new EmulatorFactory(),
new GenericObjectPoolConfig<>() {{
setMaxTotal(20); // 最多 20 个实例
setMinIdle(5); // 最少保持 5 个空闲
setMaxWait(Duration.ofMillis(3000)); // pool 2.10+ 推荐, 旧版 setMaxWaitMillis(3000)
}}
);
publicbyte[] sign(byte[] input) throws Exception {
AndroidEmulator e = pool.borrowObject();
try {
return invokeSign(e, input);
} finally {
pool.returnObject(e);
}
}
优点:
- 总数可控。你说 20 就是 20, 不会因为线程多而爆。
- 预热。启动时
pool.preparePool() 把池子填满,第一个请求就不会卡在创建 emulator 上。 - 健康检查。池子可以定期对每个实例做 validation,把坏的实例淘汰。
- 回收清晰。用完归还,长时间没用的实例会被 evict 掉,内存可控。
缺点:
- 实现稍复杂(用 Apache Commons Pool 即可,不算太难)
- 需要做 borrow/return 的异常处理,否则实例会泄漏
适用场景:生产环境的标准方案。 99% 的场景都应该用这个。
方案 3:按需创建
每次请求都创建一个新的 emulator,用完销毁。
publicbyte[] sign(byte[] input) {
AndroidEmulator e = AndroidEmulatorBuilder.for64Bit().build();
try {
// 加载 SO + 调用
return invokeSign(e, input);
} finally {
e.close();
}
}
优点:
- 完全无状态,永远不会有“上一次请求污染下一次”的问题。
缺点:
- 慢。创建一个 emulator + 加载 SO 通常要几百毫秒到几秒。每次请求都付一次,是不能接受的。
适用场景:调用频率极低 (每分钟 < 1 次)、对延迟不敏感的离线任务.
三方案对比总结
Backend 选型:Unicorn2 vs Dynarmic
第三篇讲过 Backend 是什么,这里讲生产环境怎么选。
| | |
|---|
| 执行速度 | | |
| CodeHook 支持 | | 不支持(抛 UnsupportedOperationException) |
| Trace 支持 | | 不支持(同 CodeHook,hook_add_new 抛错) |
| 断点支持 | | 不支持 |
| 稳定性 | | |
| 体积 | | |
生产化的直接结论:
- 分析阶段用 Unicorn2:因为你需要 Trace、CodeHook、断点这些工具。
- 生产阶段切到 Dynarmic:速度快几十倍(第 3 篇实测约 30-40 倍),而你已经不需要那些调试工具了。
怎么切换:
AndroidEmulator emulator = AndroidEmulatorBuilder.for64Bit()
.addBackendFactory(new DynarmicFactory(true)) // 生产
// .addBackendFactory(new Unicorn2Factory(true)) // 分析
.build();
坑:Dynarmic 不是所有指令都完美支持。切换之后必须做基准对比,用 Unicorn2 跑 100 个 case, Dynarmic 跑同样的 100 个 case,全对上才能上线。这一步绝对不能省。
自建服务的五个工程关键点
很多人选择直接用 unidbg-boot-server,这是一个开源的 Spring Boot 封装。内置对象池,HTTP 接口,开箱即用。
但如果你要自建(因为业务复杂、需要特殊定制),下面是五个你必须考虑的关键点:
关键点 1:实例池大小怎么定
经验公式: 池大小 = min(物理 CPU 数 x 2, 物理内存 GB / 单实例内存)
每个 Unidbg 实例大概占用:
- 中 SO (1-10MB): 200-500 MB
- 大 SO (10MB+,含资源文件):500MB-1GB
计算示例:8C16G 的服务器,单实例 300MB:
- 内存上限:16 GB / 0.3 GB ≈ 53 (但要给 OS 和 JVM 留余量,实际 35-40)
别贪多。池大小设到 50 不一定比 16 跑得快,因为 JIT 编译、内存压力会拖累整体。从经验公式开始,跑压测看 P99.
关键点 2:预热是必须的
症状:服务启动后第一个请求耗时 5 秒,后续请求 10ms.
原因:第一个请求触发了池子的延迟创建。你的 LB 还没把流量切过来呢,健康检查就超时了。
解决方案:启动时主动调用一次,让所有实例都被创建并跑通一次。
@PostConstruct
publicvoidwarmUp(){
pool.preparePool();
// 预跑一次 sign, 触发 JIT 编译
for (int i = 0; i < pool.getMaxTotal(); i++) {
AndroidEmulator e = pool.borrowObject();
try {
sign(e, "warmup".getBytes());
} finally {
pool.returnObject(e);
}
}
}
预热一次,后续的请求都是热的。这是生产化的标配,不能省。
关键点 3:健康检查和实例回收
Unidbg 实例会老化。表现:
- 内存逐渐增长(JIT 缓存膨胀、未释放的临时缓冲区)
所以必须定期“换新”:
new GenericObjectPoolConfig<>() {{
setMaxTotal(20);
// 一个实例最多用 1000 次, 然后销毁重建
// setMinEvictableIdleDuration: pool 2.12+; setTimeBetweenEvictionRuns(Duration): pool 2.10+
// 旧版 (< 2.10) 用 setMinEvictableIdleTimeMillis / setTimeBetweenEvictionRunsMillis
setMinEvictableIdleDuration(Duration.ofSeconds(60));
setTimeBetweenEvictionRuns(Duration.ofSeconds(30));
// 借出时验证
setTestOnBorrow(true);
}};
加上一个 validate 方法,让池子定期检查实例是否还能产生正确结果:
@Override
publicbooleanvalidateObject(PooledObject<AndroidEmulator> p){
try {
AndroidEmulator e = p.getObject();
byte[] result = invokeSign(e, KNOWN_INPUT);
return Arrays.equals(result, KNOWN_OUTPUT);
} catch (Exception ex) {
returnfalse;
}
}
实例失败 → 池子自动销毁 + 重建。这是自愈能力,生产服务必备。
更丰富的健康判据
validateObject 只做“已知输入算出已知输出”这一项检查,覆盖的是“实例是不是还能算对”,但对“实例是不是在缓慢劣化”几乎没有发言权。真正的生产级实例池会把健康检查做成多维度的复合判据,任何一条超阈值就触发淘汰:
| | | |
|---|
| KNOWN_INPUT 对 KNOWN_OUTPUT | | |
| | | |
| /proc/<pid>/smaps | | |
| | | |
| | | |
| | | |
代码上合起来是这样:
@Override
publicbooleanvalidateObject(PooledObject<EmulatorWrapper> p){
EmulatorWrapper w = p.getObject();
// 维度 1: 结果正确性
try {
byte[] result = invokeSign(w.emulator, KNOWN_INPUT);
if (!Arrays.equals(result, KNOWN_OUTPUT)) returnfalse;
} catch (Exception ex) {
returnfalse;
}
// 维度 2: RSS 增长
long currentRss = readProcStatm();
if (currentRss > w.initialRss * 2) returnfalse;
// 维度 3: 调用次数
if (w.callCount.get() > 1000) returnfalse;
// 维度 4: 异常连击
if (w.recentFailures.get() > 3) returnfalse;
returntrue;
}
其中“调用次数”这一项尤其值得单列——很多团队只做内存和正确性检查,跑上一周后才发现实例们都老化了但都还算得对,表现是 P99 延迟从 50ms 慢慢涨到 200ms,却没有任何告警触发。调用次数作为硬上限,本质上是一种“预防性淘汰”,避免长寿命实例的慢性劣化。经验值大约是 1000-5000 次,太小浪费(每次重建有冷启动成本),太大失去保护意义。
对应的淘汰策略也有讲究:
- 立即淘汰(invalidate):结果不一致、抛异常、RSS 爆表——这些是“已经坏了”,必须立刻从池子里拿出来销毁。
- 延迟淘汰(mark for eviction):调用次数到上限、P99 超阈值——这些是“该换了但还能用”,打个标记让池子在下次 evict run 时替换,不中断正在进行的请求。
- 告警但不淘汰:RSS 轻微偏高、JIT cache 接近但未超限——这些只是“预警”,留着用同时通知运维关注趋势。
三级响应组合起来,池子的健康就从“要么活着要么崩”变成了“有层次的自我保养”,对长跑的生产服务至关重要。
关键点 4:错误处理和降级
Unidbg 在某些情况下会抛 BackendException、UnsupportedOperationException,可能让整个调用栈崩掉。生产服务不能接受。
public Optional<byte[]> sign(byte[] input) {
AndroidEmulator e = null;
try {
e = pool.borrowObject(2000); // 2 秒等不到实例就放弃
return Optional.of(invokeSign(e, input));
} catch (NoSuchElementException ne) {
// 池子满了, 没有实例
meter.poolExhausted.increment();
return Optional.empty();
} catch (Throwable t) {
// 任何其他异常 -> 实例可能损坏, 销毁
log.error("sign failed", t);
if (e != null) {
try { pool.invalidateObject(e); } catch (Exception ignored) {}
e = null; // 防止 finally 再次归还
}
return Optional.empty();
} finally {
if (e != null) pool.returnObject(e);
}
}
注意关键细节: invalidateObject 之后要把 e 设为 null,否则 finally 会再 returnObject,把已销毁的实例又放回池子。
关键点 5: JVM 参数调优
Unidbg 服务的 JVM 参数和普通 Web 服务不太一样:
java -server \
-Xms4g -Xmx4g \ # 堆大小固定, 避免动态扩展
-XX:+UseG1GC \ # G1 适合大堆 + 低延迟
-XX:MaxGCPauseMillis=200 \ # GC 暂停目标
-XX:MaxDirectMemorySize=2g \ # 限制 JNA/参数传递用到的 DirectByteBuffer
-XX:+AlwaysPreTouch \ # 启动时预占内存, 避免运行时缺页
-XX:+UseStringDeduplication \ # 减少重复字符串占用
-jar app.jar
关键的两个参数:
MaxDirectMemorySize:注意,这只能约束走 Bits.reserveMemory 的路径——ByteBuffer.allocateDirect() 是其中最常见的一条,部分 Unsafe.allocateMemory 调用也会走(取决于具体调用点)。约束不了 Unicorn/Dynarmic 通过 JNI 调到 native 层 malloc/mmap 直接拿走的模拟内存。后者既不计入 -Xmx,也不计入 MaxDirectMemorySize,必须靠容器/主机内存余量来兜底。设这个参数主要是为了防止 JNA 那部分失控扩张拖累整体。- **
AlwaysPreTouch**:让 JVM 在启动时就把堆全部 touch 一遍,避免运行时第一次访问页面缺页中断。启动慢一点,但运行时延迟更稳定。
关于 native 内存排查:JVM 自带的 -XX:NativeMemoryTracking 只跟踪 HotSpot 自身(Class、Code、Compiler、GC、Thread 等)分配的 native 内存,完全感知不到 Unicorn/Dynarmic 通过 JNI 拿走的那部分。要查 Unidbg 的 native 泄漏,正确工具是 jemalloc + jeprof(MALLOC_CONF 开 profiling)、pmap -x <pid>、/proc/<pid>/smaps 比对快照、async-profiler --alloc native 这类,从进程视角看堆外内存的去向。
容器化部署的额外考量
把 Unidbg 服务部署到 K8s,有几个容易踩的坑:
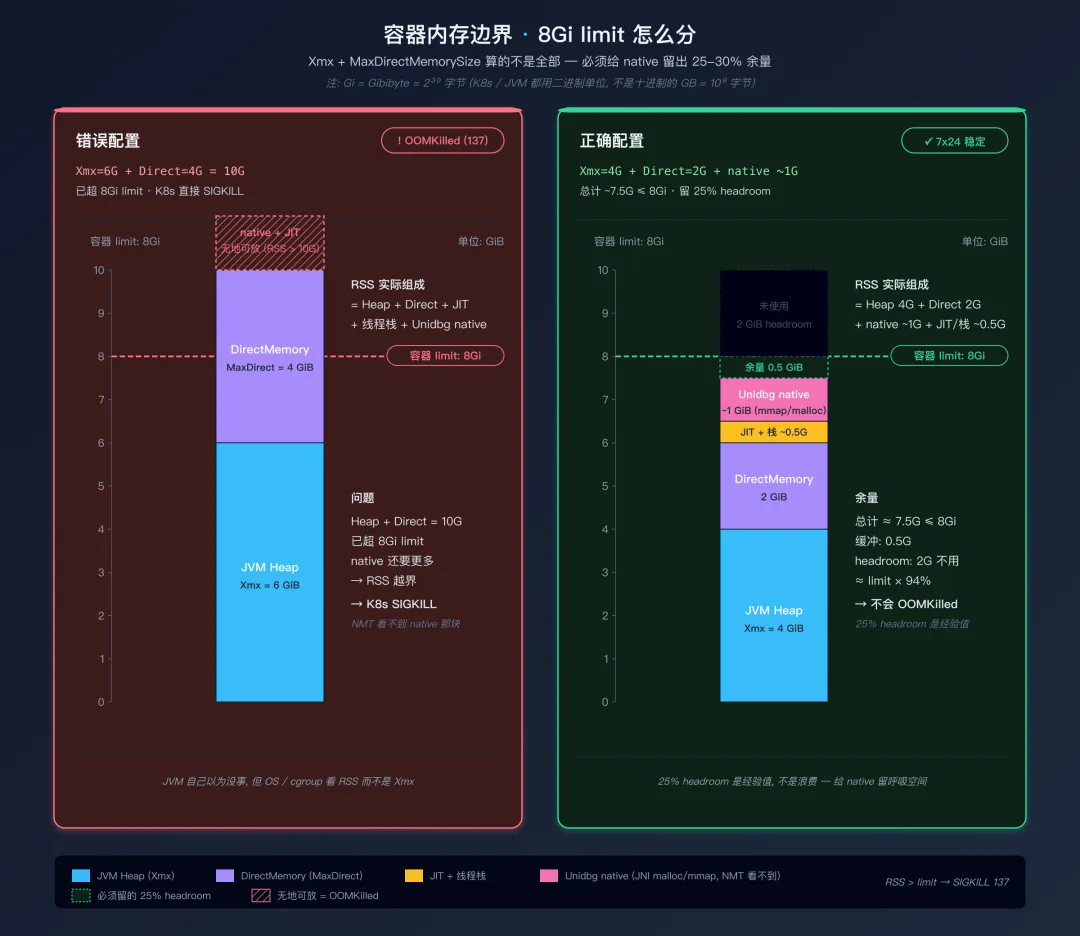
坑 1:内存限制要算上 native 内存
resources:
limits:
memory:"8Gi"
这个 8Gi 是整个容器的总内存,包含:
- DirectMemory (MaxDirectMemorySize)
如果你设 Xmx=6G + MaxDirectMemorySize=4G = 10G,容器只有 8G, K8s 会把你 OOMKilled。必须留 25-30% 的余量给 native.
8Gi 容器内存边界 · 错误配置 vs 正确配置左边那种 Xmx + Direct 直接顶到 limit 的配法是 K8s 上最常见的翻车姿势——光是 Heap + Direct 自己加起来就超了,更别提 JIT 缓存、线程栈、Unidbg 通过 JNI 拿走的 mmap/malloc。后者既不计入 -Xmx 也不计入 MaxDirectMemorySize,NMT 也看不到,全部得靠剩下那 25% headroom 兜底。
坑 2: CPU limit 会拖累 JIT
K8s 的 CPU limit 是通过 cfs_quota 实现的,可能让 JIT 编译卡顿。生产建议:设 request 但不设 limit,或者 limit 至少是 request 的 1.5 倍。
坑 3:镜像里别用 Alpine
Alpine 用 musl libc,而 unidbg 自带的 libdynarmic.so / libunicorn.so 是 glibc 链接的 native 库——直接 System.loadLibrary 时会报 Error loading shared library 或 GLIBC 缺失。要么装 gcompat(musl→glibc 兼容层)凑合用,要么直接换基于 Ubuntu/Debian 的镜像如 eclipse-temurin:17-jdk-jammy,后者省事得多。
监控指标和告警
生产服务必须监控以下指标:
| | |
|---|
| QPS | | |
| P50 / P99 延迟 | | |
| 错误率 | | |
| 池子借出/归还差 | | |
| 池子空闲数 | | |
| JVM 堆使用率 | | |
| DirectMemory 使用率 | | |
| 进程 RSS | | |
最容易暴露问题的两个:
- 池子借出/归还差:这是检测实例泄漏最有效的指标。借出 1000 次 + 归还 990 次 = 漏了 10 个实例。
- 进程 RSS 持续增长:不是 Java 堆增长,而是整个进程内存。一旦持续上涨,通常是 native 内存泄漏——用
pmap -x / smaps 比对快照、jemalloc + jeprof 抓 native 分配 profile 才能定位,JVM 自带的 NMT 看不到。
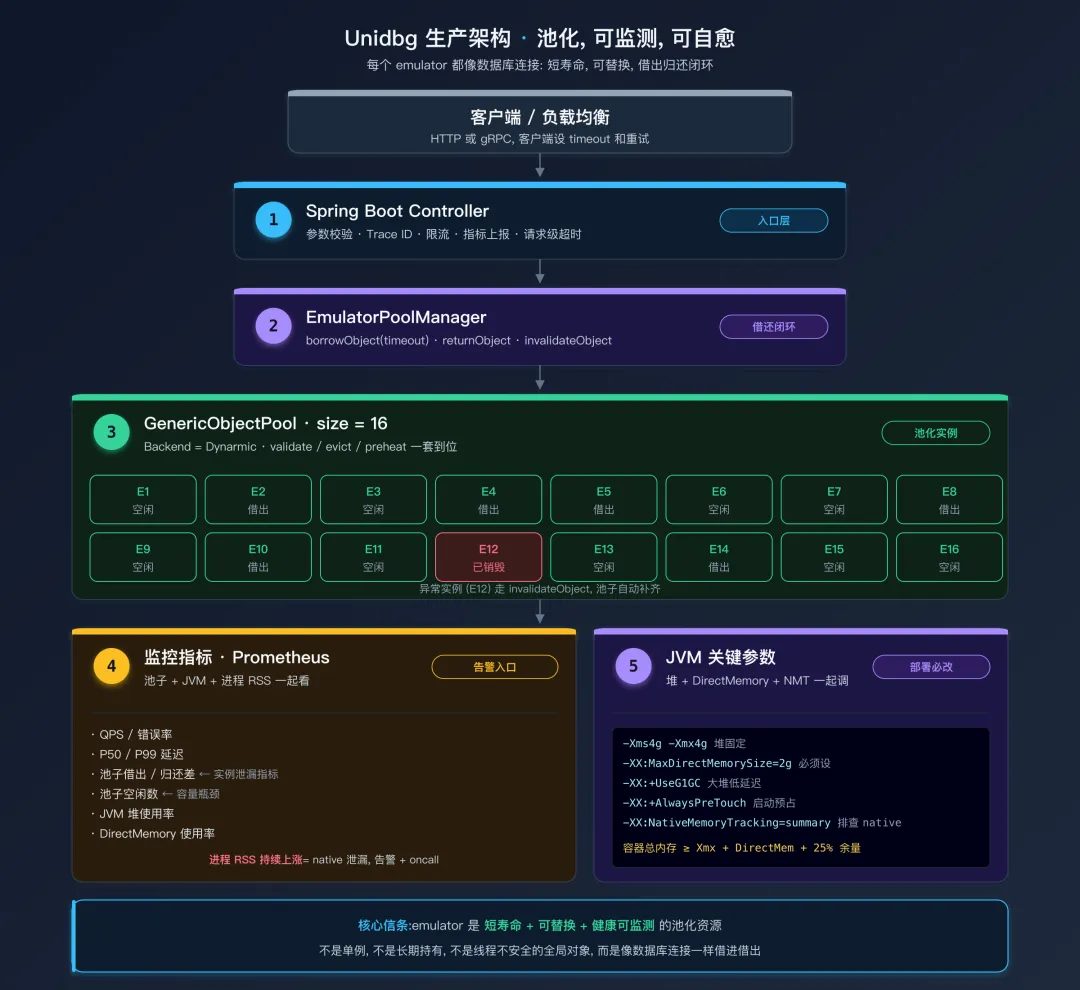
一个完整的生产架构
把上面的所有要点串起来,一个 Unidbg 生产服务大概长这样:
Unidbg 生产服务完整架构核心信条:每个 emulator 实例都是一个短寿命的、可替换的、健康可监测的资源。它不是单例,不是长期持有,不是线程不安全的全局对象,而是像数据库连接一样的池化资源。
一个真实事故复盘
去年帮一个朋友排查问题,症状:Unidbg 服务上线一周后,内存从 4GB 涨到 12GB,然后被 OOMKilled,重启又恢复 4GB。每周一次循环。
第一反应:内存泄漏。但 JVM 堆很稳,始终在 3GB 左右。
线索 1:用 pmap -x 对比启动后和一周后的内存映射快照,发现匿名段(anon)持续增长——而 JVM 堆 + Metaspace + DBB 加起来稳定,说明涨的部分在 Unicorn/Dynarmic 通过 JNI malloc 拿走的那块,HotSpot 自己感知不到。
线索 2:仔细看代码,发现池子里有个细节:
} catch (BackendException ex) {
log.error("backend error", ex);
returnnull;
} finally {
pool.returnObject(e); // <-- 把出错的实例又放回池子!
}
问题:BackendException 抛出之后,emulator 状态可疑(具体取决于异常类型——SVC handler 业务异常通常可恢复,Unicorn 自身 fault 则可能让内存映射处于半坏状态),但代码不分青红皂白把它 return 到池子,下次又被借出来用。最稳妥的做法是统一销毁重建,不去赌"哪种异常可恢复"。一周累积下来,池子里全是"半坏"的实例,每个都泄漏一点点 native 内存。
修复:
} catch (BackendException ex) {
log.error("backend error", ex);
pool.invalidateObject(e); // 销毁 + 让池子创建新的
e = null;
returnnull;
} finally {
if (e != null) pool.returnObject(e);
}
修复后,内存稳定在 4GB,不再增长。
这个事故的教训:
- 抛异常的实例必须销毁,不能归还。这是最容易写错的地方。
- 生产监控里 RSS 比 JVM 堆更重要。JVM 堆告诉你 Java 部分的健康,RSS 告诉你整个进程的健康。
- 故障要靠“长期跑”才能暴露。写完代码跑 10 分钟没问题不等于稳定,上线之前跑一晚上的压测才靠谱。
事故 2:线程池饿死 + 慢请求堆积
另一次事故症状很不一样:服务启动时 QPS 正常,运行 2-3 小时后 QPS 开始掉,P99 从 50ms 飙到 3 秒,错误率涨到 15%。重启又恢复,但几小时后再次出现。
线索挨个看:JVM 堆稳定,RSS 稳定,池子空闲数从 10 降到 0 并且再也没回升。问题出在借出 1000 次只归还了 970 次,长期累积下来池子被“偷偷借走但不归还”的请求耗光了。
根因是业务代码里有一条超长的“死胡同”路径:某个特定类型的输入会触发 SO 里的一个深层嵌套,Unidbg 没挂但也没返回,卡在 Backend 的无限循环里。池子的 borrowObject(2000) 超时只是让调用方拿不到实例,不会让那个卡住的实例还回来,于是实例越借越少,直到池子空了全员排队。
修复分两层:第一层是在 invokeSign 外面加 强制超时 + 强制 invalidate:
Future<byte[]> future = executor.submit(() -> invokeSign(e, input));
try {
byte[] result = future.get(5, TimeUnit.SECONDS);
return Optional.of(result);
} catch (TimeoutException te) {
future.cancel(true); // ⚠️ 见下方陷阱说明
pool.invalidateObject(e);
e = null;
return Optional.empty();
}
⚠️ 必须知道的陷阱:future.cancel(true)不能真正打断卡在 native 层的 Unicorn / Dynarmic 调用——它只向 Java 线程发 InterruptedException,而 native 执行不响应 Java 中断。结果是:JVM 这边以为线程停了,实际 native 层还在跑;这时立刻 invalidateObject(e) 调 emulator.close(),会和正在执行的 native 代码冲突,有概率 SIGSEGV 让整个 JVM 挂掉。
所以第一层只是"看起来在做事",真正可靠的兜底是第二层——emu_stop() 才能从 native 内部主动退出指令循环。生产里第一层用作"调用方拿不到结果时不阻塞"的快速路径,但实例的真正回收必须等第二层触发后再做。
第二层是在 SO 里找到那个死循环点,给 Backend 注册指令计数限制(emulator.getBackend().registerEmuCountHook(N)),超上限 Unicorn 会自动调 emu_stop() 退出当前模拟,把控制权交回 Java——这才是能真正打断 native 死循环的机制。本系列项目里 AwemeTTEncrypt.java:45 就用了 registerEmuCountHook(100000) 做这种保险。
这个事故的关键教训是:池化不等于安全,池化只是把资源集中管起来——但资源如果从池子里出去就再没回来,池化就变成了定时炸弹。所有从池子里借出去的实例都必须有“保底归还或销毁”的兜底路径,哪怕是最诡异的超时场景也要能处理。
事故 3:GC pause 尖峰导致业务抖动
最后一个事故是 GC 引起的。服务平时 P99 是 80ms,偶尔会出现单个 P99 达到 1-2 秒的尖峰,持续几秒后恢复。业务方反馈“不稳定”,但日志里看不到任何错误——因为请求都成功了,只是特别慢。
GC 日志一开就真相大白:Full GC 平均每 10 分钟来一次,每次 Stop-The-World 持续 500-1500ms(这个量级已经是 G1 退化到 Full GC fallback 的征兆,正常 G1 设计期望 STW < 500ms)。根因是 G1 的 Region 规划被频繁申请释放的 DirectByteBuffer 搞崩了:每个 DirectByteBuffer 在构造时会通过 jdk.internal.ref.Cleaner(OpenJDK 9+;早期 OpenJDK 8 是 sun.misc.Cleaner)挂一个清理动作 java.nio.DirectByteBuffer$Deallocator(实现 Runnable,run() 里调 unsafe.freeMemory() 释放堆外字节)。问题是 Cleaner 对象 + Deallocator 对象都跟着 DirectByteBuffer 一起从新生代晋升到老年代,Young GC 回收不掉,只有 Full GC 才会触发它们的 run() 真正释放堆外内存——一旦堆外接近 MaxDirectMemorySize,Bits.reserveMemory 内部会显式调一次 System.gc() 来逼迫释放(前提是 JVM 没设 -XX:+DisableExplicitGC,否则这条路径会被关掉、堆外直接爆 OOM),于是出现规律性的尖峰。
修复路径有三个方向,后来选了第二和第三的组合:
- 方向 A:换 ZGC。ZGC 的 STW 能控制在 10ms 以内,但需要 JDK 17+ 且堆不能太小,对已有部署改动大。
- 方向 B:在池子里复用 DirectByteBuffer。让每个 emulator 实例自己持有固定的 buffer,避免每次调用都申请/释放。改动小,效果明显。
- 方向 C:把
-XX:MaxGCPauseMillis 从 200 收紧到 100,并缩小 Young 区。让 G1 更激进地做 Mixed GC,避免老年代堆积。
两者合起来后,Full GC 频率从 10 分钟一次降到 1 小时一次,持续时间也压到了 200ms 以内,P99 不再有尖峰。这里值得记住的经验是:Unidbg 服务的性能瓶颈经常不在 Unidbg 本身,而在 JVM 的 GC 策略——DirectByteBuffer、大对象、频繁分配都会触发 GC 病理模式,监控 GC 指标和监控 Unidbg 指标同等重要。
总结
| |
|---|
| |
| 否 |
| |
| |
| min(CPU * 2, 内存 / 单实例占用),跑压测验证 |
| 预热 + 健康检查 + 老实例回收 + 错误时销毁 |
| |
| |
一句总结:把每个 emulator 实例当成数据库连接来管理 —— 池化、预热、健康检查、错误时销毁、定期更新。这套思路把 90% 的生产问题都干掉了。