1. 写在前面
咱们接着之前的CUDA学习笔记系列,继续深入优化矩阵乘法的性能。在上一篇 Kernel4 中,
CUDA学习笔记:如何通过提升计算强度来优化矩阵乘法(一)
我们沿着“提升计算强度(计算量 / 访存量)”这条主线做了第一个关键升级:让一个线程不再只计算 C 中的一个元素,而是计算同一列上连续 TM 个元素(TM×1)。这样做的直接收益是:Bs 中的某个标量会在一个线程内被复用 TM 次,从而减少了对 Bs 的重复访问,计算强度显著提升。
但 Kernel4 仍有一个明显的“形状限制”:在列方向(N 方向)上,一个线程仍然只负责 1 列输出。也就是说,一个线程做的工作是“细长条”(TM×1)。如果我们进一步让一个线程同时在行方向与列方向都负责多个输出,就可以进一步提高 shared memory 中加载的数据(As/Bs)的利用率,让每次从 SMEM 取到寄存器的数据产生更多 FMA,从而继续提升计算强度。
因此,本篇博客我们在 Kernel4 的基础上,引入2D Block Tiling(更准确说是:Thread Tile 从 TMx1 扩展为 TM×TN):
每个线程负责计算 C 子块中的一个 TM×TN 的小矩形(thread tile),而不是 TM×1。
2. 基于 2D Block Tiling 实现单线程多行多列计算(TM×TN)
本节只讲“直觉与流程”,尽量不引入复杂索引表达式。索引推导与代码细节放到后面第 3、4 节。
Kernel5 的整体结构:
每个 block 负责 C 中一个 BM×BN 的子块(block tile);
沿 K 维度以 BK 为步长滑动(滑窗),每次从 A 中取 BM×BK 大小的矩阵,从 B 中取 BK×BN大小的矩阵,加载到 shared memory(As/Bs);
在 shared memory 上计算本轮 BK tile 对 C 子块的贡献,累加到寄存器里的部分和,直到走完整个 K。
Kernel5 的关键变化发生在“内层计算”(inner loops)部分:
直观对比(一次 dotIdx 下的“访存 vs 计算”):
当 TM、TN 都大于 1 时,计算量是乘法增长(TM×TN),而读取量是加法增长(TM+TN)——这就是 Kernel5 相比 Kernel4 进一步提升计算强度的本质原因。
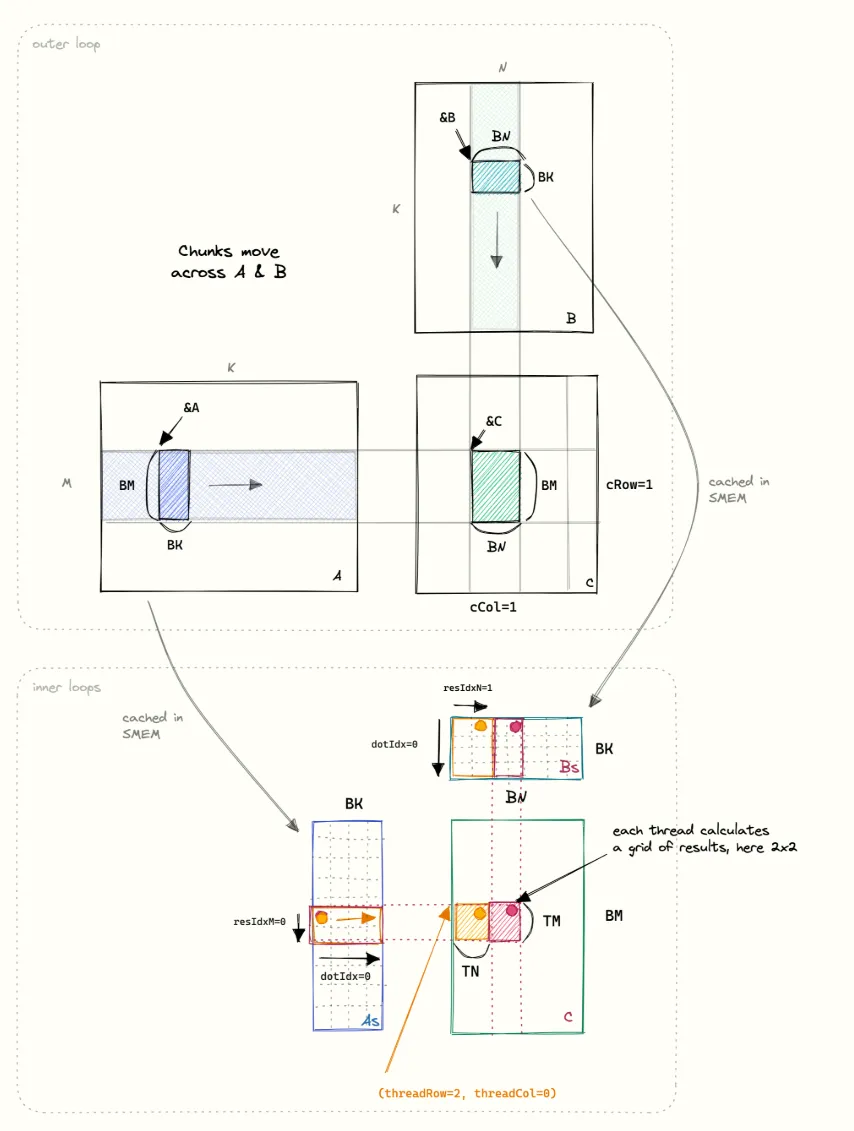
Kernel5 计算流程示意图:
上图从 block 级 与 thread 级 两个视角,完整展示了 Kernel5 的计算流程。
在 outer loop(上半部分) 中,每个 block 固定负责计算 C 矩阵中的一个 BM×BN 子块。计算并不是一次完成的,而是沿着 K 维度以 BK 为步长滑动:每次从矩阵 A 中取一个 BM×BK 的子块,从矩阵 B 中取一个 BK×BN 的子块,并分别缓存到共享内存 As 和 Bs 中。随后,这两个共享内存子块在本轮 inner loop 中保持不变。
在 inner loop(下半部分) 中,Kernel5 的核心思想开始体现。与 Kernel4 不同的是,一个 thread 不再只负责 C 中的一列(TM×1),而是负责 C 中一个 TM×TN 的矩形微块。对于每一个 dotIdx,线程会从 As 中取出 TM 个 A 元素(同一列),同时从 Bs 中取出 TN 个 B 元素(同一行),并在寄存器中执行一次 TM×TN 的 outer-product,直接更新 TM×TN 个结果。
这种做法使得一次 dotIdx 下:
从共享内存加载的数据量仅为 TM+TN
但产生的计算量为 TM×TN 次乘加
下面我们对图中的元素进行逐块说明:
2.1 上半部分:outer loop(Block 级视角)
左下:A 矩阵(BM × K)
for (bkIdx = 0; bkIdx < K; bkIdx += BK) { // load As A += BK;}
右上:B 矩阵(K × BN)
右下:C 矩阵(BM × BN)
✅ 关键理解点:
一个 block:
固定负责 一个 BM×BN 的 C 子块
在 K 方向上反复:
取 A 的 BM×BK
取 B 的 BK×BN
累加到同一块 C
✅ 这就是标准的 block tiling + K 滑窗
另外需要注意中间的标注:cached in SMEM
这句是非常重要但容易被忽略的提示:
As 和 Bs 在 inner loop 期间是“不动的”
也就是说:
2.2 下半部分:inner loop(Thread 级视角)
这部分是 Kernel5 的本质。
左下:As(BM × BK),标了 resIdxM, dotIdx
横轴:dotIdx(0…BK-1)
纵轴:resIdxM / 行方向
👉 一次 dotIdx 对应 As 的“一列”
右上:Bs(BK × BN),标了 dotIdx, resIdxN
横轴:resIdxN, 列方向
纵轴:dotIdx(0…BK-1)
👉 一次 dotIdx 对应 Bs 的“一行”
这两块合起来就是 kernel 里的:
for (uint i = 0; i < TM; ++i) { regM[i] = As[(threadRow * TM + i) * BK + dotIdx];}for (uint i = 0; i < TN; ++i) { regN[i] = Bs[dotIdx * BN + threadCol * TN + i];}
右下 C 微块(TM × TN)
图里标了:
TM:纵向
TN:横向
每个线程计算 TMxTN 个结果,图中是 2x2
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { threadResults[resIdxM * TN + resIdxN] += regM[resIdxM] * regN[resIdxN]; }}
图中每个 thread:
3. Block 和 Thread 的布局
这一节的目的只有一个:把"线程的几何关系”讲清楚。后面所有索引的写法,本质上都是基于这一节的布局。
3.1 block tile 与 thread tile
因此,一个 block 里 thread 的逻辑网格应该是:
这两者相乘就是 blockDim.x:
3.2 threadIdx.x → (threadRow, threadCol)
Kernel5 用 1D 的 threadIdx.x,但逻辑上拆成二维 thread 坐标:
const int threadCol = threadIdx.x % (BN / TN);const int threadRow = threadIdx.x / (BN / TN);
其中:
(BN/TN) 表示列方向一行有多少个 thread;
threadCol 是该 thread 在列方向的编号;
threadRow 是该 thread 在行方向的编号。
3.3 一个 thread 负责的 C 微块坐标
该 thread 负责的 TM×TN 微块左上角坐标(相对该 blocktile)是:
行起点:threadRow * TM
列起点:threadCol * TN
因此该 thread 覆盖:
举例(TM=TN=8):如果 threadRow=1, threadCol=2,它负责 C 子块内:
后面写回索引 C[(threadRow*TM+m)*N + threadCol*TN+n] 就是从这里来的。
4. Kernel5 的代码实现与计算流程解析(按执行顺序)
本节按真实执行流程介绍:GMEM → SMEM → REG → FMA → 写回 GMEM。
4.1 outer loop:BK 滑窗与共享内存缓存(GMEM → SMEM)
Kernel5 的外层循环沿 K 维度以 BK 为步长滑动。每次滑动会把:
A 的 BM×BK 子块加载到 As
B 的 BK×BN 子块加载到 Bs
然后在 SMEM 上计算本轮贡献。
4.1.1 blocktile 定位与指针偏移
const uint cRow = blockIdx.y;const uint cCol = blockIdx.x;A += cRow * BM * K;B += cCol * BN;C += cRow * BM * N + cCol * BN;
这里把 A/B/C 指针移动到当前 block 负责的 tile 起点:
4.1.2 分配 shared memory(As/Bs)
shared float As[BM * BK];shared float Bs[BK * BN];
4.1.3 确定 “谁来搬运?”——装载索引与 strideA/strideB
Kernel5 与 Kernel4 的一个不同点是:一个 thread 可能需要加载多个元素,因此需要用 stride 来做均摊。
const uint innerRowA = threadIdx.x / BK;const uint innerColA = threadIdx.x % BK;const uint strideA = numThreadsBlocktile / BK;
const uint innerRowB = threadIdx.x / BN;const uint innerColB = threadIdx.x % BN;const uint strideB = numThreadsBlocktile / BN;
说明:
4.1.4 GMEM → SMEM 的装载与同步
for (uint loadOffset = 0; loadOffset < BM; loadOffset += strideA) { As[(innerRowA + loadOffset) * BK + innerColA] = A[(innerRowA + loadOffset) * K + innerColA];}for (uint loadOffset = 0; loadOffset < BK; loadOffset += strideB) { Bs[(innerRowB + loadOffset) * BN + innerColB] = B[(innerRowB + loadOffset) * N + innerColB];}__syncthreads();
这两段循环确保 As/Bs 的 tile 被完整搬入 SMEM,__syncthreads() 保证 block 内线程都能看到完整缓存。
4.1.5 指针前移:滑窗沿 K 维度移动
A 在 K 方向向右移动 BK 列;
B 在 K 方向向下移动 BK 行。
4.2 dotIdx 的物理意义
A 的一列 × B 的一行(SMEM → REG 的一次取样)在当前 BK tile 内,我们还要对 dotIdx = 0..BK-1 做累加:
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) { // block into registers for (uint i = 0; i < TM; ++i) { regM[i] = As[(threadRow * TM + i) * BK + dotIdx]; } for (uint i = 0; i < TN; ++i) { regN[i] = Bs[dotIdx * BN + threadCol * TN + i]; } for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { threadResults[resIdxM * TN + resIdxN] += regM[resIdxM] * regN[resIdxN]; } }}__syncthreads();
dotIdx 的物理含义可以这样理解:
接下来每个线程只关心:
4.3 regM / regN 与 TM×TN 的 outer-product(REG 级计算核心)
Kernel5 在每个线程里维护三个“寄存器缓存数组”:
// allocate thread-local cache for results in registerfilefloat threadResults[TM * TN] = {0.0};// register caches for As and Bsfloat regM[TM] = {0.0};float regN[TN] = {0.0};
说明:这些无修饰符的局部变量通常会优先放到寄存器,但在寄存器压力过大时也有可能会被编译器放到 local memory。
4.3.1 从 SMEM 把 A 的 TM 个值缓存到 regM
for (uint i = 0; i < TM; ++i) { regM[i] = As[(threadRow * TM + i) * BK + dotIdx];}
解释:
4.3.2 从 SMEM 把 B 的 TN 个值缓存到 regN
for (uint i = 0; i < TN; ++i) { regN[i] = Bs[dotIdx * BN + threadCol * TN + i];}
解释:
4.3.3 outer-product:用 regM×regN 更新 TM×TN 个输出
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { threadResults[resIdxM * TN + resIdxN] += regM[resIdxM] * regN[resIdxN]; }}
这就是“outer-product(外积)累加”:
regM 是长度 TM 的向量(A 的 TM 个元素)
regN 是长度 TN 的向量(B 的 TN 个元素)
二者外积得到一个 TM×TN 的矩阵,正好对应该线程负责的 C 微块
因此一次 dotIdx 下:
SMEM→REG 读取约 TM + TN 个标量
计算产生 TM×TN 次 FMA(乘法级增长)
从而可以显著提升计算强度。
4.4 写回 C:为什么两个方向都要乘 tiling 系数(REG → GMEM)
当整个 K 方向的滑窗循环完成后,threadResults 保存了该 thread tile 的最终结果,需要写回到 C。
写回循环如下:
for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { C[(threadRow * TM + resIdxM) * N + threadCol * TN + resIdxN] = alpha * threadResults[resIdxM * TN + resIdxN] + beta * C[(threadRow * TM + resIdxM) * N + threadCol * TN + resIdxN]; }}
这里的索引形式是 Kernel5 相比 Kernel4 最直观的区别:
由于 C 是行优先存储(row-major),一维寻址就是:C[row∗N+col]
代入 row/col 即得到上述写回索引:(threadRow * TM + resIdxM) * N + threadCol * TN + resIdxN
Kernel5 的完整数据通路:GMEM(A,B) →(装载)→ SMEM(As,Bs) →(每个 dotIdx 取 TM/TN)→ REG(regM,regN) →(outer-product 累加)→ REG(threadResults) →(写回)→ GMEM(C)。
5. 总结
本篇博客延续"提升计算强度"这条主线,在 Kernel4 1D BlockTiling (TM×1)的基础上进一步引入 2D BlockTiling(TM×TN),把单线程的计算形状从“细长条”扩展为“矩形微块”。
Kernel5 的关键收益来自内层循环中计算模式的变化:在每个 dotIdx 下,线程把 As 的 TM 个元素与 Bs 的 TN 个元素缓存到寄存器中,通过一次 TM×TN 的 outer-product 更新 TM×TN 个输出,使得计算量随 TM×TN 成乘法增长,而读取量仅随 TM+TN 成加法增长,从而显著提高计算强度。
6. 参考
https://siboehm.com/articles/22/CUDA-MMM:《Kernel 5: Increasing Arithmetic Intensity via 2D Blocktiling》
https://github.com/siboehm/SGEMM_CUDA/tree/master