Transformer 核心内容梳理
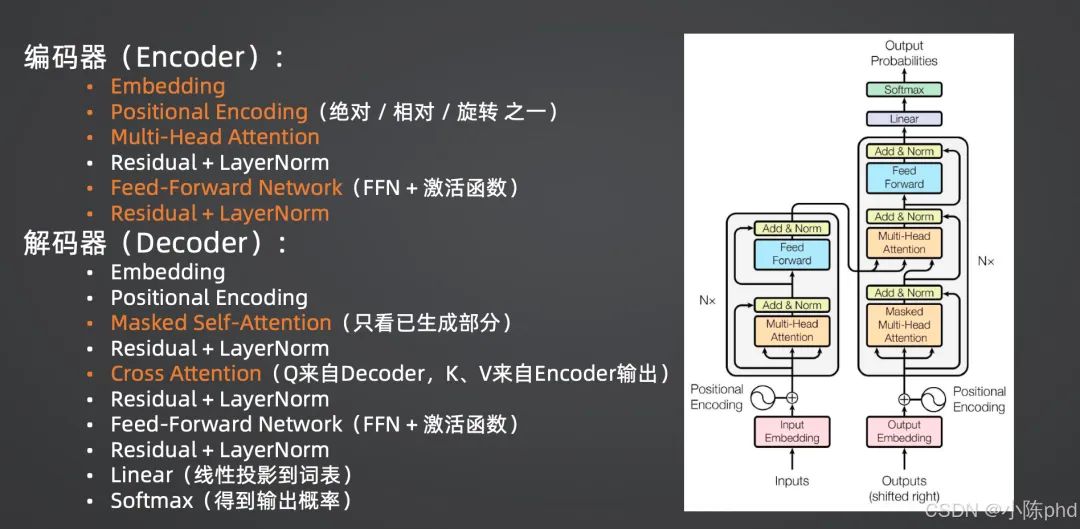 Transformer完整架构示意图
Transformer完整架构示意图上图为Transformer完整架构示意图,清晰展示了编码器、解码器的核心模块及流程,后续我们将逐模块拆解其原理。
1. 引言:打破局限,注意力为核心的创新
如今我们日常使用的大语言模型、AI绘画工具、智能语音转写、机器翻译等AI应用,其底层核心骨架无一例外都基于Transformer架构。这个2017年由Google团队提出的模型,用一句“Attention Is All You Need”的大胆宣言,彻底终结了循环神经网络对序列建模领域长达十余年的垄断,开启了人工智能的大模型时代。
本章我们将从序列建模的核心需求出发,拆解传统方案的致命瓶颈,进而引出Transformer的颠覆性突破,帮你理解这个模型为何能成为AI领域的通用基石。
1.1 序列建模的核心任务与传统方案的先天瓶颈
序列建模是自然语言处理、语音识别、时间序列预测等AI核心任务的基础,其核心目标是:处理有序的序列输入数据,精准捕捉序列中元素之间的依赖关系,最终完成端到端的序列生成、分类、翻译等任务。
以最典型的机器翻译任务为例,输入一句“我今天去了北京,那里的秋天很美”,模型需要输出对应的英文翻译,不仅要完成单词的对应转换,更要捕捉到“那里”与前文“北京”的指代关系、“秋天”与“很美”的修饰关系,这就是序列建模的核心——建模序列元素的长距离、多类型依赖。
在Transformer诞生之前,序列建模领域长期被循环神经网络(RNN)及其改进版本LSTM、GRU主导,同时也有部分基于卷积神经网络(CNN)的探索方案。但这些方案都存在无法通过小修小补解决的先天瓶颈,严重限制了序列建模的能力上限与落地效率。
1.1.1 串行结构导致的并行能力完全缺失
RNN系模型的核心设计逻辑是“串行迭代”:必须按照序列的先后顺序,逐个处理每个token(单词/子词),前一个token的计算结果(隐藏状态),必须作为后一个token计算的输入。
这种设计看似贴合人类阅读文本的顺序,却完全违背了现代AI算力的核心优势——GPU的并行计算能力。哪怕GPU拥有数千个计算核心,在处理RNN模型时,同一时间也只能执行一个token的计算,算力利用率极低。
这直接导致了两个致命问题:一是模型训练效率极低,面对百万级以上的大规模语料,RNN系模型的训练周期往往长达数周,根本无法适配大数据场景;二是模型规模无法扩展,参数量的提升会进一步拉长训练周期,这也是Transformer诞生前,NLP模型始终无法突破亿级参数量的核心上图清晰呈现了RNN的串行计算逻辑:token1计算完成后,才能启动token2的计算,依次迭代,无法并行处理,算力浪费严重。
1.1.2 长距离依赖建模的梯度消失难题
序列建模的核心能力,是捕捉长序列中首尾元素的语义关联。但RNN系模型的串行结构,决定了序列中两个元素的信息传递路径长度,与它们的位置距离完全相等。
比如一篇1000个token的长文本,第1个token和第1000个token的信息传递,需要经过999步的迭代计算。在反向传播更新参数时,梯度需要经过999次连乘才能传递到开头的位置,哪怕每一步的梯度都接近1,最终也会衰减到几乎为0,出现严重的梯度消失问题。
尽管LSTM、GRU通过门控机制,一定程度上缓解了短序列的梯度消失问题,但面对长文本、长对话等场景,依然无法有效捕捉跨段落的长距离语义关联,模型的长文本理解能力始终存在天花板。
1.1.3 CNN方案的折中探索与固有局限
为了解决RNN的并行能力问题,ByteNet、ConvS2S等基于CNN的序列建模方案应运而生,通过卷积操作实现了序列的并行计算。但CNN方案也存在无法回避的短板:卷积核的感受野有限,单次卷积只能捕捉局部相邻token的关联,要捕捉长距离依赖,必须堆叠数十层卷积层,信息传递路径依然会随着序列长度增加而变长,同时计算复杂度也会随层数线性上升,最终在长序列建模上的表现与效率,依然
1.2 Transformer的颠覆性核心突破
2017年,Google团队在顶会NeurIPS上发表了《Attention Is All You Need》,正式提出了Transformer架构,用一套完全基于注意力机制的设计,一次性解决了传统序列建模方案的所有核心瓶颈。
Transformer最核心的创新,也是其颠覆行业的根本原因,在于:彻底抛弃了循环神经网络的串行结构,完全基于自注意力机制构建端到端的序列建模框架,实现了序列建模的范式重构。
这一核心创新,带来了三个改变行业格局的关键突破:
1.2.1 全并行计算,彻底释放GPU算力潜力
Transformer的自注意力机制,实现了序列中所有token的完全并行计算:序列中每个token的特征提取,都不依赖其他token的计算结果,整个序列的所有token可以在同一时间完成计算,完美适配GPU的并行计算架构,算力利用率实现了数量级的提升。
这一突破,直接打破了模型规模的天花板:原本需要数周训练的RNN模型,Transformer仅需几天甚至十几小时就能完成训练;也正是基于全并行的特性,后续的大语言模型才能顺利扩展到百亿、千亿甚至万亿级参数量,开启了大模型时代。
1.2.2 一步到位的长距离依赖捕捉,彻底解决梯度消失问题
在Transformer的自注意力机制中,无论序列长度是100还是10000,序列中任意两个token之间的信息传递路径长度永远为1。模型可以在单次计算中,直接捕捉到序列首尾元素的语义关联,完全不会出现梯度随序列长度衰减的问题,彻底解决了长序列建模的核心痛点。
这一特性,让Transformer在长文档理解、长对话生成、跨段落语义推理等场景中,展现出了传统模型无法比拟的能力优势。
1.2.3 通用的序列建模范式,实现全AI领域的跨场景适配
自注意力机制的核心是建模元素之间的关联,并不依赖序列的模态属性。这意味着,Transformer不仅能处理文本序列,还能轻松适配图像、语音、点云、视频等所有可以转换为序列形式的数据。
也正是基于这一特性,Transformer在诞生后的数年间,快速从NLP领域扩展到计算机视觉、语音识别、自动驾驶、生物计算、多模态理解等几乎所有AI领域,成为了人工智能领域的通用底层架构,真正实现了“一架构通全领域”。
2. 背景:Transformer 出现前的序列建模探索
Transformer的诞生并非偶然,而是序列建模领域长期技术探索、不断解决现有痛点的必然结果。在2017年之前,研究者们围绕“并行计算”和“长距离依赖捕捉”两大核心痛点,进行了大量尝试,形成了多种主流的序列建模方案,同时自注意力机制也已在部分任务中初步应用,为Transformer的最终创新奠定了坚实的技术基础。本章将回顾这些关键探索,帮你理解Transformer创新的上下文与必然性。
2.1 主流并行化序列建模方法:突破串行瓶颈的初步尝试
随着大数据与GPU算力的发展,RNN串行结构的效率瓶颈日益凸显,研究者们开始聚焦“并行化序列建模”,希望在不牺牲建模能力的前提下,提升训练效率。其中,基于CNN的改进方案成为当时的主流,核心代表为ByteNet和ConvS2S,此外还有基于循环结构的并行化改进(如双向RNN、深层RNN),但均未实现质的突破。
2.1.1 ByteNet:基于膨胀卷积的并行序列建模
ByteNet由Google团队于2016年提出,是早期并行序列建模的核心方案之一,其核心思路是用“膨胀卷积(Dilated Convolution)”替代RNN的串行迭代,实现序列的并行计算。膨胀卷积通过在卷积核中插入“空洞”,扩大卷积核的感受野,无需堆叠过多卷积层,就能捕捉到更长距离的序列依赖。
与普通CNN相比,ByteNet的膨胀卷积具有两个核心优势:一是感受野随膨胀率指数增长,比如膨胀率为2的卷积核,感受野是普通卷积核的2倍,能捕捉到更远距离的token关联;二是所有卷积操作均可并行执行,无需依赖前序token的计算结果,大幅提升了训练效率。
但ByteNet依然存在明显局限:尽管膨胀卷积扩大了感受野,但依然无法实现“全局依赖捕捉”——序列中相距极远的token(如首尾token),依然需要通过多层膨胀卷积的信息传递,才能建立关联,信息衰减问题依然存在;同时,膨胀卷积的计算复杂度随序列长度和膨胀率上升而快速增加,在长序列场景下,效率依然无法满足。
2.1.2 ConvS2S:端到端卷积序列建模方案
ConvS2S(Convolutional Sequence to Sequence)是2017年Transformer诞生前,最接近实用化的并行序列建模方案,由Facebook团队提出。其核心设计是采用全卷积架构构建编码器-解码器,完全抛弃RNN结构,实现端到端的并行序列生成。
ConvS2S的编码器由多层1D卷积层组成,每层卷积采用不同的卷积核大小,捕捉不同范围的局部依赖;解码器则采用“因果卷积”(Causal Convolution),确保生成每个token时,只能看到前序token,符合自回归生成的逻辑。同时,ConvS2S还引入了残差连接和层归一化,缓解深层网络的梯度消失问题,提升模型训练稳定性。
在机器翻译任务中,ConvS2S的训练效率远超RNN系模型,且在中短序列翻译任务上,性能接近当时的最优RNN模型。但它的核心短板与ByteNet一致:依赖卷积核的感受野捕捉依赖,无法实现全局依赖的直接建模,长序列场景下的性能依然落后于RNN+注意力的组合方案;此外,因果卷积的设计的也导致解码器的并行能力受到一定限制,无法实现全序列并行生成。
2.1.3 其他并行化探索:局限与不足
除了基于CNN的方案,研究者们还尝试了其他并行化改进,比如:双向RNN(Bi-RNN)通过同时处理序列的正向和反向,提升依赖捕捉能力,但本质依然是串行结构,并行能力未得到根本改善;深层RNN通过堆叠更多层,提升模型表达能力,但梯度消失问题更加严重,训练难度极大。
这些方案的共同问题的是:始终没有摆脱“局部依赖建模”的局限,要么无法实现全局依赖的直接捕捉,要么并行能力与建模能力无法兼顾,成为当时序列建模领域的核心技术瓶颈,也为Transformer的创新留下了巨大的空间。
2.2 自注意力机制的前期应用:从辅助模块到核心潜力
自注意力机制并非Transformer首创,其核心思想最早可追溯到2014年的序列建模研究,当时主要作为“辅助模块”,用于弥补RNN/CNN在依赖捕捉上的不足,并未成为模型的核心骨架。但这些前期应用,验证了注意力机制的有效性,为Transformer“以注意力为核心”的创新提供了关键参考。
2.2.1 Bahdanau Attention:解决RNN编码的信息丢失问题
2014年,Bahdanau等人在《Neural Machine Translation by Jointly Learning to Align and Translate》中,首次将注意力机制引入Seq2Seq模型(RNN为核心),提出了Bahdanau Attention(也称为“加性注意力”)。
传统Seq2Seq模型的编码器,会将整个源序列编码为一个固定长度的向量,再输入解码器生成目标序列。这种方式的致命问题是:当序列较长时,固定向量无法承载所有源序列信息,导致解码器生成的内容与源序列脱节(即“信息丢失”)。
Bahdanau Attention的核心作用,是让解码器在生成每个目标token时,“动态关注”源序列中最相关的token——通过计算解码器当前隐藏状态与源序列所有隐藏状态的相关性,分配不同的注意力权重,再通过加权求和得到当前token的输入特征,从而解决固定向量编码的信息丢失问题。
这一设计,让RNN-based Seq2Seq模型的翻译性能得到了显著提升,尤其是在中长序列翻译任务中,效果改善明显。但此时的注意力机制,仅仅是RNN模型的“辅助模块”,模型的核心骨架依然是串行的RNN结构,无法摆脱并行能力差、长距离依赖捕捉不足的瓶颈。
2.2.2 Luong Attention:优化注意力计算,提升实用性
2015年,Luong等人在Bahdanau Attention的基础上,提出了Luong Attention(也称为“乘性注意力”),优化了注意力的计算方式,提升了模型的效率和实用性。
与Bahdanau Attention的加性计算(通过神经网络计算相关性)不同,Luong Attention采用“点积”的方式计算解码器隐藏状态与源序列隐藏状态的相关性,计算效率更高;同时,Luong Attention还提出了“全局注意力”和“局部注意力”两种模式,全局注意力关注整个源序列,局部注意力仅关注源序列的局部区域,兼顾了建模能力与计算效率。
Luong Attention进一步验证了注意力机制在依赖捕捉上的优势,成为当时RNN-based Seq2Seq模型的标准配置。但与Bahdanau Attention一样,它依然是辅助模块,无法改变RNN串行结构的本质,模型的训练效率和长序列建模能力依然有限
2.2.3 自注意力的初步探索:脱离RNN的尝试
在Bahdanau和Luong Attention之后,部分研究者开始尝试将注意力机制从“辅助模块”升级为“核心模块”,探索脱离RNN的序列建模方案。比如,2016年提出的“Self-Attention”概念,首次尝试让序列中的每个token与自身序列的所有token建立关联,实现全局依赖的直接建模。
这些早期自注意力的探索,虽然在模型结构上还不够完善(比如未引入多头机制、位置编码),在性能上也未超过RNN+注意力的组合方案,但已经验证了一个核心结论:注意力机制可以独立完成序列的依赖建模,无需依赖RNN/CNN的串行或卷积结构。这一结论,成为Transformer架构最核心的理论基础。
2.3 技术痛点的集中爆发:Transformer诞生的必然性
到2016年底,序列建模领域的技术探索陷入了一个“瓶颈期”:基于RNN的方案,并行能力极差,长距离依赖建模困难;基于CNN的并行方案,无法实现全局依赖捕捉,长序列性能有限;注意力机制虽然有效,但仅作为辅助模块,无法发挥其最大潜力。
此时,行业迫切需要一种全新的架构,能够同时解决“并行计算”“长距离依赖捕捉”“全局依赖建模”三大核心痛点。正是在这样的背景下,Google团队整合了前期的技术积累,大胆抛弃RNN和CNN结构,完全基于自注意力机制,设计出了Transformer架构,用一句“Attention Is All You Need”,彻底打破了行业瓶颈,开启了序列建模的新时代。

