多模态数据的表征与对齐——特征、挑战与跨模态对齐
1 引言
多模态学习是指对文本、图像、音频、视频等多种异质信息来源进行协同建模与理解的机器学习范式,其核心支撑技术为多模态表征与跨模态对齐。
- • 多模态表征:将不同结构的模态数据映射为可计算的稠密特征向量,实现异质数据的数值化统一;
- • 跨模态对齐:在统一语义空间中建立异质模态的语义关联,让语义一致的跨模态特征相互匹配。不同模态之间的对齐、关联和转换,使模型能够把来自不同模态的信号放在同一语义空间里理解。
二者共同解决多模态数据异构性与语义割裂问题,是多模态大模型、跨模态检索、AIGC等技术的核心基础。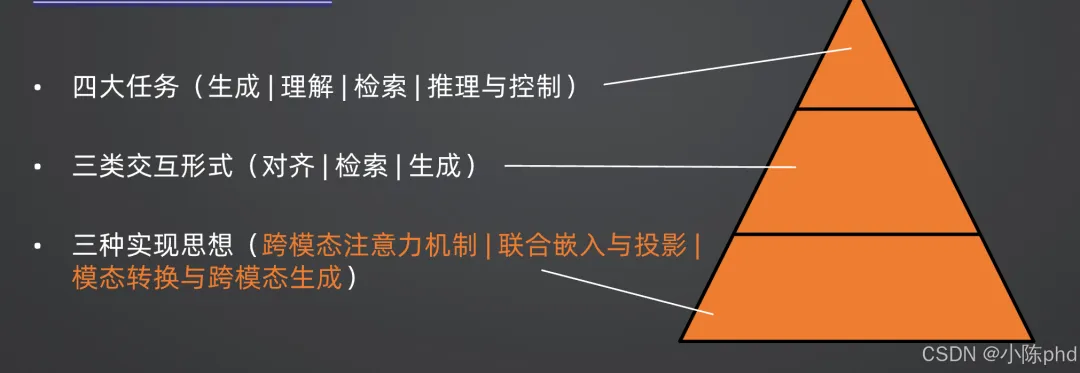
2 多模态数据的核心特征与异质性
2.1 典型模态的基础特征
不同模态的数据,其结构、语义和处理方式存在本质差异,这是多模态研究的起点。
2.1.1 文本(Text)
- • 离散化:由一个个独立词语或字符组成,词汇表是有限的。例如,中文常用汉字约3500个,英文单词表也有明确边界。
- • 序列性:词语按照特定的顺序排列,改变顺序会改变语义。例如,“我喜欢猫”和“猫喜欢我”是完全不同的意思。
- • 抽象性:文本承载的是抽象的概念和信息符号,需要理解深层含义和上下文。例如,“苹果”既可以指水果,也可以指科技公司,需结合上下文判断。
- • 里程碑架构:BERT、GPT等Transformer架构,通过自注意力机制捕捉文本的上下文依赖。
2.1.2 音频(Audio)
- • 时序性:音频是一维的、连续的时序信号,时间维度是其核心特征。
- • 频率特征:声音由不同频率的波组成,通常要转换成语谱图等二维表示处理,才能更好地提取特征。
- • 上下文相关:环境音、语音、音乐的含义依赖于上下文。例如,同样的“啊”在不同语境下可以表示惊讶、痛苦或疑问。
- • 里程碑架构:WaveNet、Wav2Vec、Whisper等,通过卷积或Transformer处理时序和频率信息。
2.1.3 图像(Image)
- • 网格状:图像由像素组成,形成一个二维网格,每个像素点代表特定位置的颜色信息。
- • 局部相关性:相邻像素之间通常有很强的相关性,构成了物体的边缘和纹理。这也是CNN能有效处理图像的原因。
- • 密集性:像素值是连续的,在0~255之间,代表了丰富的视觉细节。
- • 里程碑架构:AlexNet、ResNet、ViT等,从局部卷积特征发展到全局自注意力特征。
2.1.4 视频(Video)
- • 时空性:既有帧的空间信息,也有帧的时间信息,是一个三维数据立方体(高×宽×时间)。
- • 数据量庞大:含有大量的帧,处理起来计算量大,对算力要求极高。
- • 多模态:本身就是多模态,包含视觉(图像帧)和听觉(音频),通常还带有文本字幕。
- • 里程碑架构:I3D、VideoBERT、ViViT等,将图像模型扩展到时间维度。
2.1.5 传感器(Sensor)
- • 时序性:连续的时间序列数据,如IMU的加速度、陀螺仪数据。
- • 多样性:数据类型和格式差异大,包含加速度、温度、压力、LiDAR点云等。
- • 底层性:通常是物理世界的原始测量值,需要复杂的处理提取出高层语义。
- • 里程碑架构:AutoEncoder、LSTM、PointNet等,用于处理时序或不规则点云数据。
2.2 多模态数据的异质性
定义:多模态数据异质性指不同模态在数据结构、语义表达、数据分布上存在的本质差异,是多模态学习的核心前置问题。
- 1. 结构异质性:不同模态的数据维度与格式无天然对应关系。文本是离散符号,音频是连续波形,图像是二维像素矩阵,传感器是多维时序数据,结构上完全不同。
- 2. 语义异质性:同一语义可通过不同模态表达,模态间无直接语义映射。例如,“一只猫”可以用一张猫的图片、“喵”的叫声或“cat”这个词来表达,但这些数据本身没有直接的数学对应。
- 3. 分布异质性:各模态的数据分布、噪声特征、标注成本存在显著差异。图像数据分布复杂,文本标注成本高,传感器数据则充满了环境噪声。
3 多模态表征学习
3.1 表征学习定义
多模态表征学习:将原始异质模态数据通过编码器转换为低维、稠密、语义可分的特征向量,实现异构数据的统一数值化表达,为跨模态对齐提供基础特征支撑。
3.2 单模态表征
定义:针对单一模态原始数据,通过专用编码器映射为固定维度特征向量的过程。
数学表达:其中:
- • :模态专用编码器(CNN/Transformer/RNN);
例如,对于一张猫的图片 ,通过ResNet编码器 ,可以得到一个512维的特征向量 ,这个向量就代表了这张图片的语义信息。
3.3 多模态联合表征
定义:将多种单模态特征通过映射函数投影至同一语义空间,生成融合多模态信息的联合特征。
数学表达:其中:
例如,将文本特征 和图像特征 输入到一个全连接层 ,得到一个新的联合特征 ,这个特征同时包含了文本和图像的信息。
4 跨模态对齐
4.1 跨模态对齐定义
跨模态对齐:在统一语义空间中,让语义相同的异质模态特征相互靠近、语义不同的特征相互远离,建立模态间精准语义关联的技术过程。
4.2 对齐核心度量:余弦相似度
定义:衡量两个特征向量在语义空间中方向一致性的指标,是跨模态对齐的核心相似度度量方式。它只关心向量的方向,而不关心其长度(即数值大小)。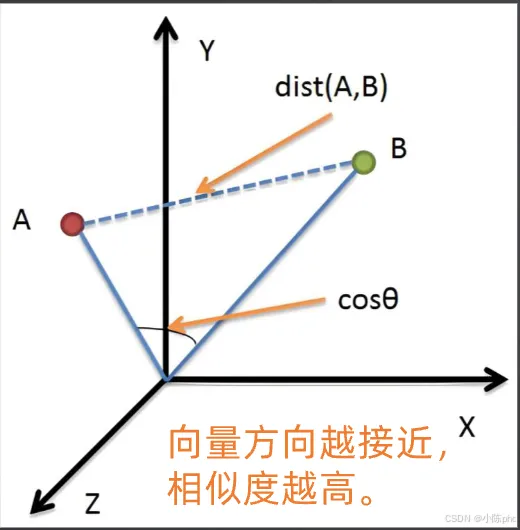
数学表达:其中:
示例:张三购物10次,买了6次零食、1次体育用品、1次办公用品、2次日用品。李四购物10次,买了8次零食、1次购物券、1次日用品。
统一特征空间:[零食, 体育用品, 办公用品, 日用品, 购物券]向量化:张三 ([6, 1, 1, 2, 0]),李四 ([8, 0, 0, 1, 1])
计算点积:计算模长:,余弦相似度:
这个高相似度表明,尽管具体购买物品不同,但两人的购物偏好(方向)是相似的。
4.3 对比学习跨模态对齐
定义:基于对比学习范式,利用大规模成对跨模态数据优化特征分布,实现语义对齐的主流方法(以CLIP图文对齐为例)。
CLIP采用双塔结构,分别对文本和图像进行编码,然后在统一的语义空间中进行对比学习。其核心思想是,让匹配的图文对(正样本对)的特征相似度尽可能高,而不匹配的图文对(负样本对)的相似度尽可能低。
对比损失函数为:
其中:
- • :温度系数,用于调节相似度分布,使模型更关注难分样本;
这个损失函数同时优化了文本到图像和图像到文本的检索任务,确保了模态间的双向对齐。训练完成后,CLIP可以实现零样本(zero-shot)跨模态检索与分类。
4.4 跨模态对齐技术路径
4.4.1 跨模态注意力机制(交互建模)
- • 思想:强调不同模态之间的细粒度交互。与单模态self-attention不同,cross-attention可以让每个词对图像的不同区域施加注意力权重,或者反过来,让图像区域对文本片段进行加权,从而实现更精细的语义对齐。
- • 优势:能捕捉图像区域与文本词语之间的一一对应关系;注意力权重可以直观地显示“模型在看哪里”;特别适用于VQA(视觉问答)、图文推理等需要深度交互的场景。
4.4.2 联合嵌入与投影(对比学习)
- • 思想:把不同模态投影到同一个语义空间中,让相同语义的样本在空间中更接近,不同语义的样本远离。对比学习(Contrastive Learning)是最典型的实现方式,它通过构造正负样本对,让模型自动学会“什么是匹配,什么是不匹配”。
- • 优势:利用大规模成对数据对齐语义,减少人工标注成本;一旦训练完成,可以实现零样本(zero-shot)跨模态检索与分类;目前已被广泛应用在搜索、推荐、跨模态理解等实际场景。
- • 代表工作:CLIP(OpenAI, 2021)。
4.4.3 模态转换与跨模态生成
- • 思想:通过将一种模态的数据“翻译”或是“生成”为另一种模态的数据来隐式地学习它们之间的关系。这种方法不只是对齐或者检索,而是显式地“跨模态创造新内容”。
- • 优势:生成的结果是新模态的数据,易于人类理解和评估;广泛应用于AIGC、多模态内容创作;当前最受关注的商业应用之一。
- • 代表工作:DeepMind Veo 3(文本生成视频)。
4.5 相似度计算:工业界的选择
在统一的语义空间中,如何衡量两个样本的相似性?不同的距离度量有不同的适用场景。
4.5.1 余弦相似度 vs 欧式距离
- • 余弦相似度:只关注向量的“方向”,衡量语义是否一致,不受数值幅度影响。例如,张三消费翻倍,购买比例不变,余弦相似度保持不变。
- • 欧式距离:关注向量的“绝对距离”,在高维空间中易受“维度灾难”影响,放大数值偏差。例如,张三消费翻倍,欧式距离会翻倍。
工业界现象:观看短视频,明明喜欢看篮球新闻/集锦,推荐给用户却是足球新闻/集锦。
- • 原因1:训练时,视频标题/标签噪声大(“XX球星精彩瞬间”),跨模态对齐不到位。
- • 原因2:用欧式距离在高维embedding空间里度量,数值偏差会被放大,导致“看起来很近”的样本被推开。
结论:余弦相似度只看“方向”,能让“篮球”和“篮球”保持近邻,即使热度或播放量的数量级相差很多。
4.5.2 二阶段检索策略
工业界通常采用二阶段检索来平衡效率和精准度:
- 1. 粗排:先用余弦相似度快速找到Top-K候选,保证语义方向一致。
- 2. 精排:再用欧式距离等方法,筛掉方向相近但幅度差异大的样本,提升精准度。
例如,在推荐系统中,先用余弦相似度找到和用户兴趣相似的1000个候选视频,再用欧式距离从中筛选出最符合用户消费频次和客单价的10个视频。
4.5.3 其他距离度量
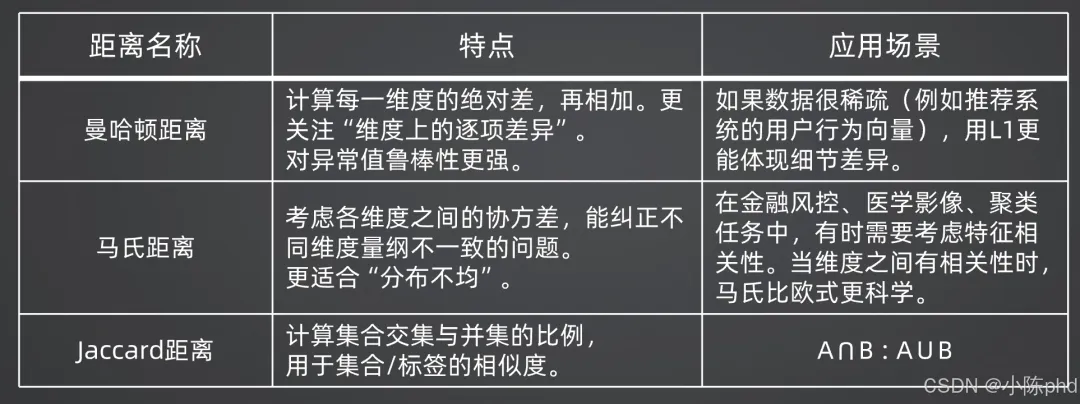
4.5.4 工业界多模态检索的实践流程
在工业级多模态检索系统中,单一相似度度量往往无法同时满足效率、召回率和精准度的要求,因此通常采用“粗排-评估-精排”的分层流程,以平衡性能与效果:
(1)余弦相似度粗排:快速筛选语义候选
工业界首先会使用余弦相似度对海量候选集进行粗排,核心目标是快速判断embedding的语义方向是否一致,过滤掉语义不相关的样本,保留Top-K(如Top 1000)候选。
- • 优势:余弦相似度计算高效,仅需向量点积与模长运算,可在毫秒级完成百万级候选的筛选;同时只关注语义方向一致性,能有效保证召回率,避免漏检核心相关内容。
- • 适用场景:跨模态检索、推荐系统的初筛阶段,如“以文搜图”“以图搜文”等场景的快速候选生成。
(2)检索指标评估:衡量用户感知的召回效果
粗排完成后,需通过检索指标(如Recall@10、Precision@5等)评估召回效果,其中Recall@10是工业界最常用的核心指标之一。
- • Recall@10定义:在检索返回的Top 10个结果中,包含真实相关样本的比例,反映了用户实际感受到的“是否能找到想要的内容”。
- • 作用:用于验证粗排策略的有效性,若Recall@10偏低,说明粗排过滤过严,需调整相似度阈值或候选数量,避免漏检关键内容。
(3)CLIP Score精排:补足语义质量评估
在部分对语义精准度要求高的任务(如AIGC内容筛选、图文匹配验证)中,会引入CLIP Score作为“质量打分”,弥补单一余弦相似度的不足。
- • CLIP Score定义:由CLIP模型计算的图文相似度得分,衡量文本与图像在统一语义空间中的对齐程度,取值范围为0~1,得分越高代表语义贴合度越强。
- • 作用:在粗排候选的基础上,通过CLIP Score对结果进行二次排序,筛选出更贴合用户语义需求的内容,同时可用于评估AIGC生成内容的质量(如文本生成图像的语义一致性)。通过“余弦相似度粗排→检索指标评估→CLIP Score精排”的分层流程,工业界多模态系统既能保证检索效率,又能兼顾召回率与语义精准度,实现了效率与效果的平衡。
5 跨模态对齐的核心挑战
5.1 语义鸿沟挑战
定义:异质模态对同一实体的语义表达存在偏差,导致表征无法完全等价,是跨模态对齐的本质难题。
例如,一张“猫”的图片和“猫”这个词,虽然语义相同,但图片包含了猫的颜色、姿态、背景等丰富信息,而文本则是高度抽象的符号。模型很难将这两种完全不同的信息源完美对齐。
5.2 模态异构适配挑战
不同模态的编码器结构、特征分布差异较大,统一空间映射易出现特征偏移与失真,难以兼顾各模态特征表达。
例如,文本编码器擅长处理抽象概念,图像编码器擅长处理视觉细节,将它们投影到同一空间时,很容易出现某一模态的特征被压制或扭曲的情况。
5.3 数据与噪声挑战
大规模成对标注跨模态数据稀缺,模态内原始噪声会直接破坏对齐精度,弱监督/无监督场景下对齐鲁棒性不足。
例如,在网络爬取的图文数据中,图片和文本往往不匹配(“标题党”),这些噪声数据会严重干扰模型的对齐学习,导致模型学到错误的关联。

