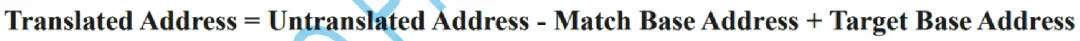1. 简介
PCIe的全称是Peripheral Component Interconnect Express,中文名为高速外围组件互联”,是一种高速串行计算机扩展总线标准。目前PCIe协议已经发布到7.0版本,最高支持256GB/s的单向传输速率。
虽然协议已经发展到了7.0版本,但是目前大多数设备只支持到4.0或者5.0的协议。
1.1. 传输速率
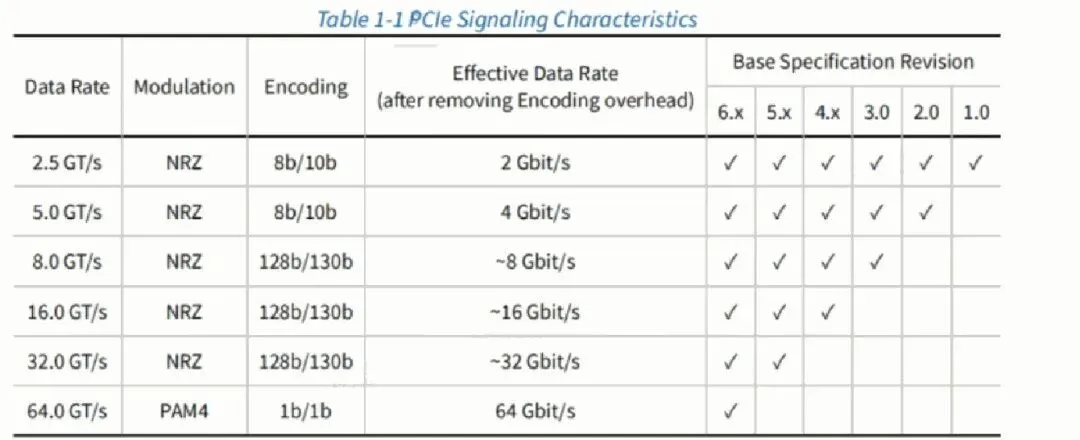
在PCIe协议中使用GT/s表示传输速率,GT是Giga Transation的缩写,表示每秒传输的次数,用于描述物理层通信协议的速率。
这个速率不代表实际的数据传输速率,下表的第四列表示数据传输速率,计算公式为:
Effective data rate = data rate * encoding
在编码时会插入多余的bit用于平衡直流(让数据流中的0和1数量基本相等)和时钟恢复(更多的跳变沿),从而损失了一部分性能。
另外,PCIe6.0的编码方式改为了PAM4,使每个符号可以写携带2bit数据信息,从而实现了传输速率的倍增,实际的链路速率并没有提升。
1.2 拓扑
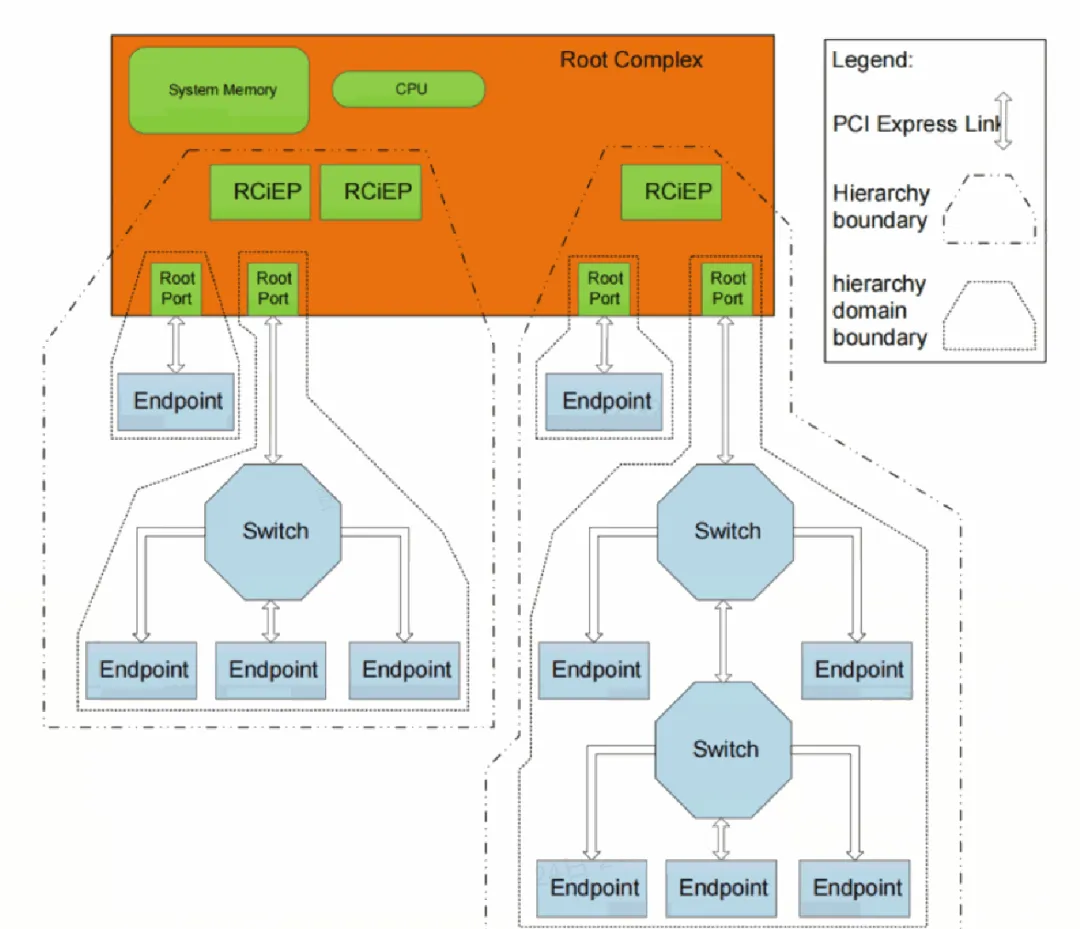
PCIe是一种点对点的通信拓扑,呈现为多叉树状,最上层为Root Complex(根复合体),简称为RC。
传统的计算机架构中一般RC集成在北桥,现在一般集成在CPU中。RC是主机与设备通信的桥梁,一般情况下主机或者设备的通信请求都需要经过RC检验和转发(P2P通信可以不经过RC)。
Switch设备用于拓扑扩展,接收或转发来自RC和EP的报文。PCIe支持三种路由方式:ID路由、地址路由、隐式路由,报文中的配置会指定使用哪种路由方式,Switch的配置空间寄存器会记录下游的设备ID(BDF)和bar地址的范围,用于判断如何处理报文。
Endpoint(EP)是PCIe事务的请求者或完成者,EP可以分为三类:legacy设备(PCI设备)、PCIe设备、RCiEP设备。
2. BDF和枚举
在PCIe拓扑中,使用BDF(bus/device/function)号表示设备,ID是由拓扑结构决定的,主机在枚举 PCIe设备时分配的。
BDF各域段的长度如下,支持256条总线,32个设备,8个function。
与Root Port相连的设备都在bus0上,经过switch后总线号需要增加,这里需要注意的是,switch内部其实是两级结构,switch内部会占用一条总线,跨过一个设备,总线号就要加1。
内核在扫描时,会先根据BIOS上报的根节点创建bus0,然后扫描bus0下面的设备,从device id为0开始遍历,发送配置访问(ID路由)读取Vendor ID和Device ID,若返回全F,则表示不存在该设备,继续扫描下一个,否则创建设备对象。
若设备类型为switch,则创建下一级总线,递归扫描该总线上的设备,因此内核的枚举采用的是深度优先的多叉树搜索算法。
在枚举过程中先记录设备所需的资源(中断、内存等),资源会在所有设备枚举后统一分配。
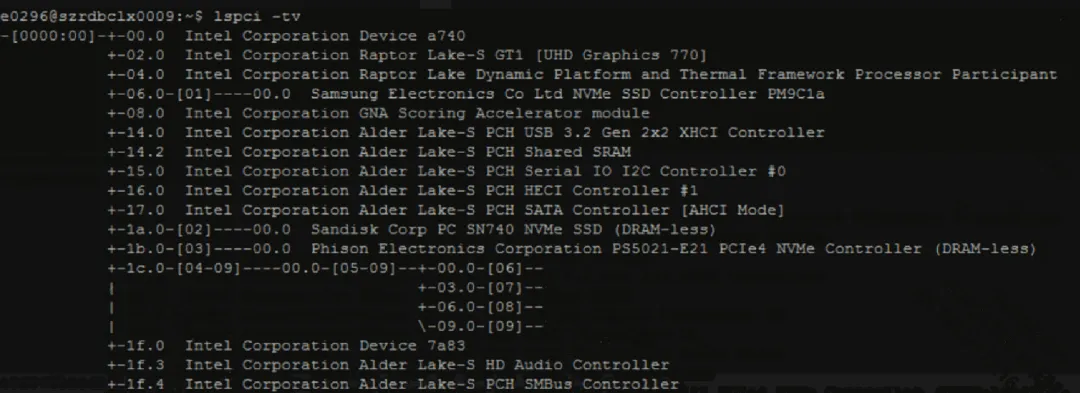
开机后,在linux中使用Ispci -tv命令可以看到主机下的PCIe拓扑,BDF号的格式为:bus:device.function,如下图所示。
PCIe配置空间支持ECAM访问,主机会分配一段256M的地址,用于映射所有设备的配置空间。
ECAM基地址+(Bus<<20)|(Device<<15)|(Function<<12)+寄存器偏移
注:在设备枚举后,若手动修改某些参数,lspci的信息可能不会一同更新,定位问题时以读出来的寄存器状态为准。
3. 协议
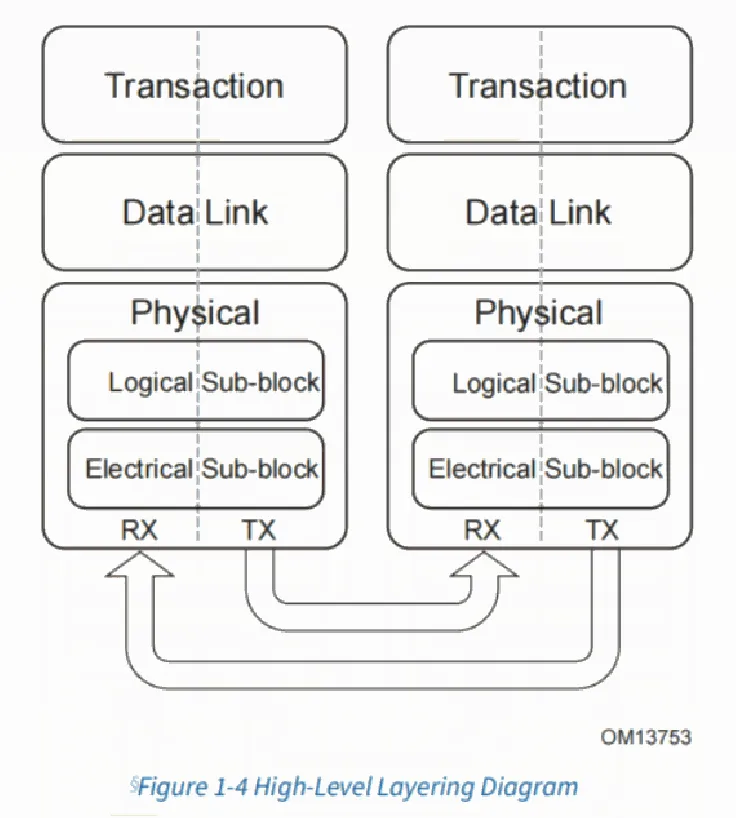
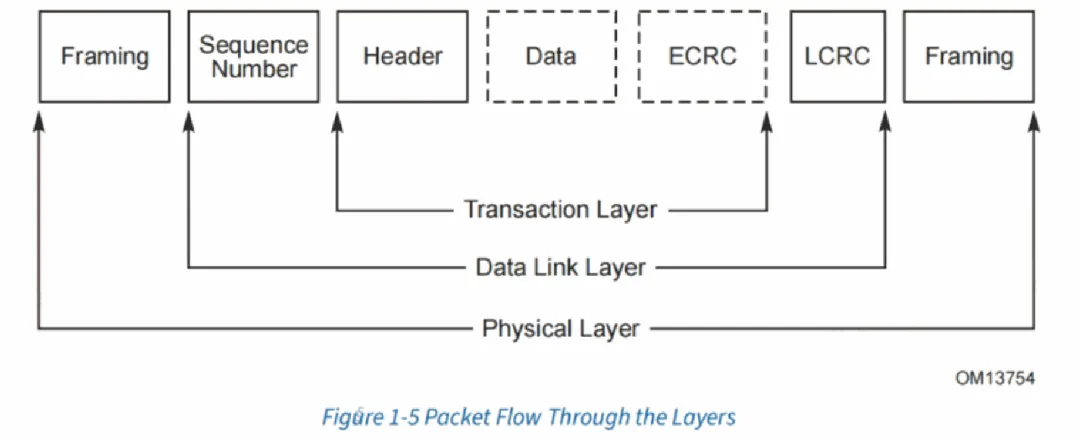
PCIe协议分为三层:事务层、数据链路层以及物理层。
事务层主要负责事务的产生和消费,具体就是TLP(transaction layer packet)包的组装和拆解,TLP报文是PCIe通信的基本单位,任何访问都会被拆解为TLP包。此外,事务层还负责PCIe的流控。
PCIe 6.0使用flit模式,主要特点为固定包大小为256字节,减少数据链路层对数据的分割/重组操作。
数据链路层的主要负责链路管理和数据完整性,包括错误检测和纠错。数据链路层在接收到TLP后,会在报文的首位添加一个报文序列号(SN)和LCC校验码,基于此进行报文的完整性检查和重传。
数据链路层还生成和消费DLLP报文,该报文用于credit更新、ACK/NAK、电源管理以及链路训练等。
注:DLLP指的是产生于数据链路层,也消费于数据链路层的报文,是一种独立的报文,TLP经过数据链路层后添加SN和LCRC的报文不是DLLP,不要混淆了。
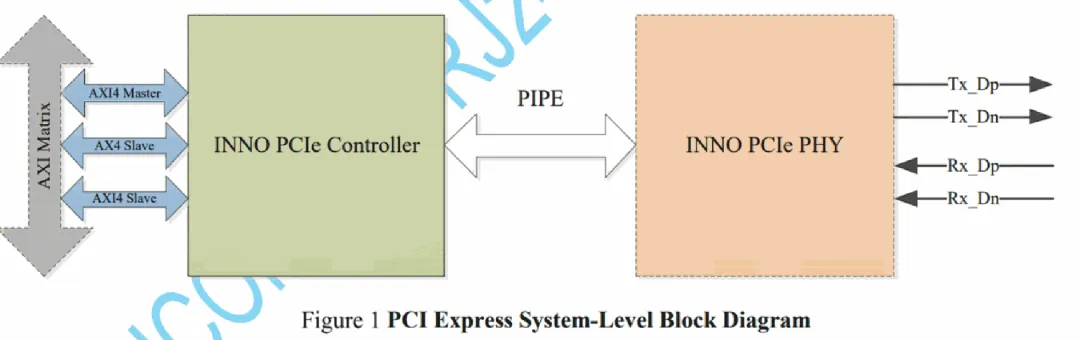
4. IP Feature
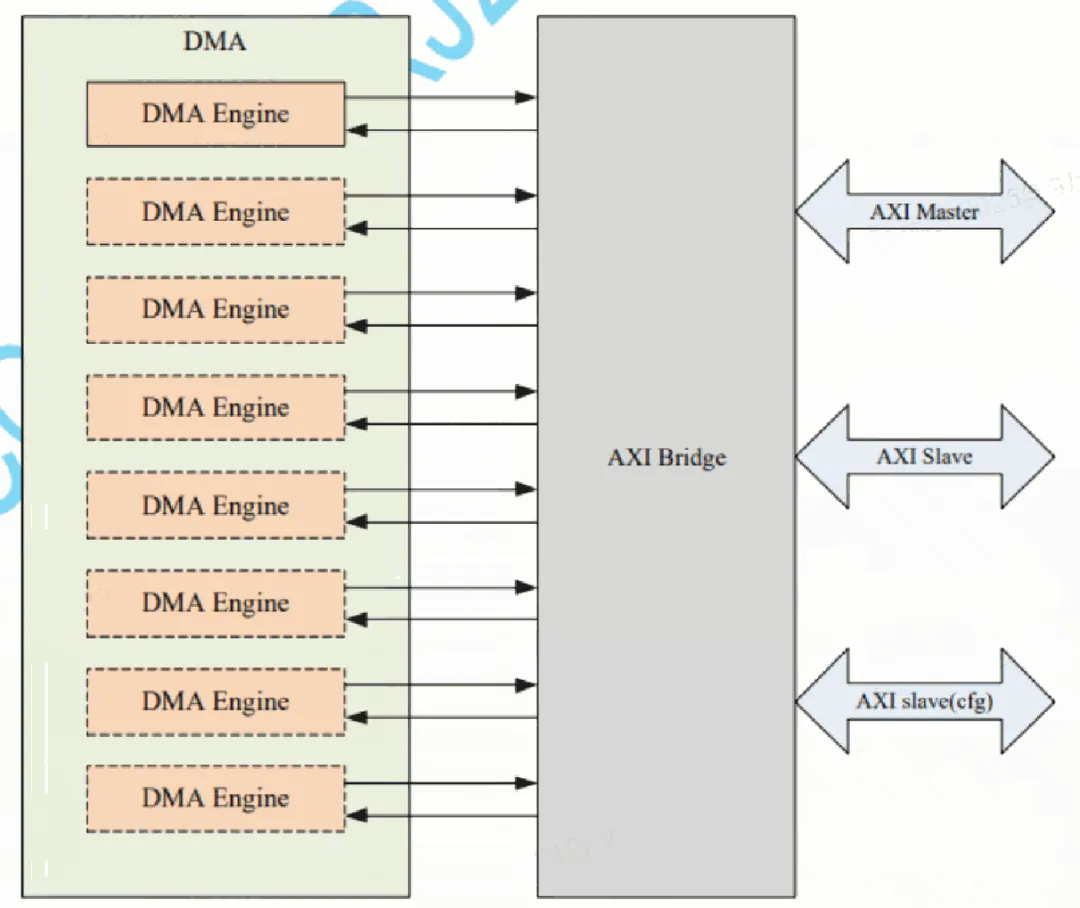
控制器和PHY使用PIPE接口,SoC侧提供了三条总线:AXI4 master、AXI4 slavel以及CFG,控制器内部有一个8通道的DMA,接入AXI Bridge后通过AXI4 master访问SoC空间。
支持特性:
内部地址转换(ATU)
最大1024bye MPS
内嵌DMA
AER
ASPM(链路低功耗)
MSI/MSI-X/INTx
8条虚拟通道(流控)
ECRC
基于ID的ordering
配置空间分配如下:
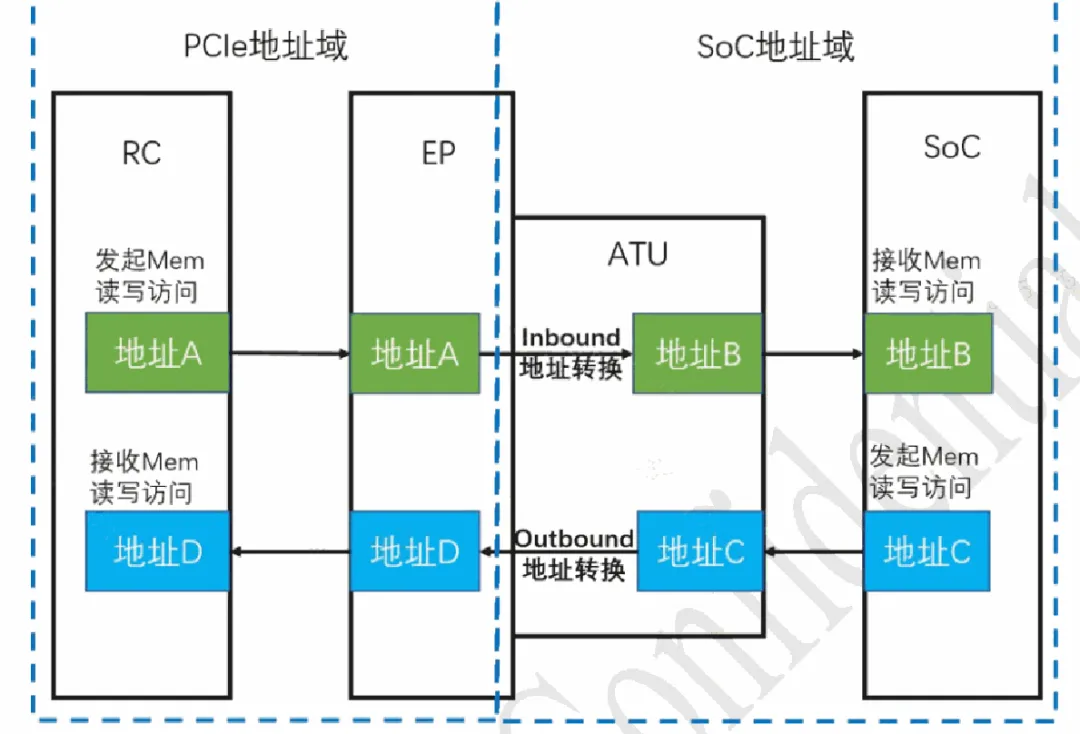
5. ATU
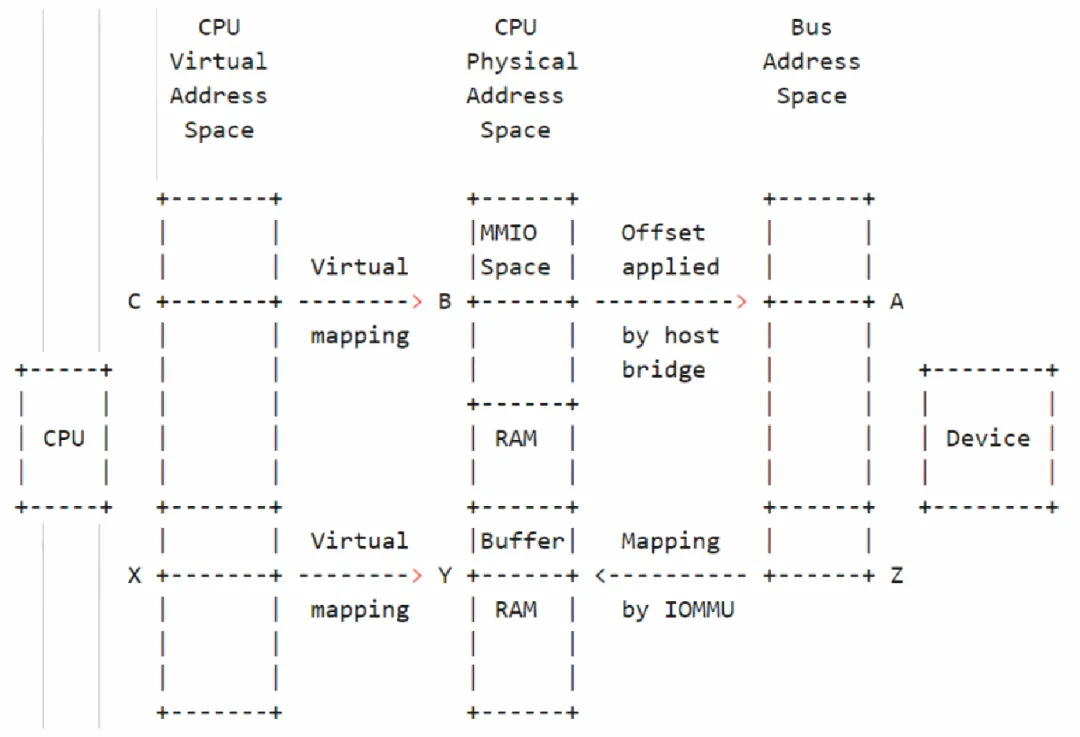
整个系统可以划分为三个地址域:分别为主机域、PCIe域以及SoC域,其中主机域与PCIe域的地址转换由RC和IOMMU完成,因此主机和EP可以互相访问。
PCIe可以通过AXI总线实现和SoC的互相访问,但是主机还不能访问SoC域的地址,同样SoC域也看不到主机域的地址,需要做一次地址转换。
ATU提供地址转换机制,通过配置ATU寄存器,可以将PCIe的bar地址映射到SoC空间,主机通过访问bar地址来访问SoC空间(inbound方向),同时也可以配置SoC侧通过slave,总线访问主机内存(outbound方向),如下图所示。
支持地址模式和bar模式,bar模式是将整个bar地址都线性映射,无法分割,并且映射后的地址要求以bar的大小对齐,优点是不依赖bar地址,通过bar id就可以进行映射。
6. DMA
PCIe的DMA集成在了内部,并且连接到了AXI桥上,因此对于DMA来说,主机地址与SoC地址都是可见的, DMA可以直接访问,不需要通过ATU映射。
如下图所示,共有8路DMA,每条DMA通道可以独立工作,DMA走AXI master总线进行读写访问。
除了向SoC上报中断外,还支持向主机上报MSI中断,需要主机驱动分配好中断号,PCIe内部有记录MSI中断地址的寄存器,在DMA初始化时,将该地址以及上报的中断号写入相应的寄存器,配置remote interrupt使能后,在 DMA完成或者abort时,主机就会收到对应的中断。
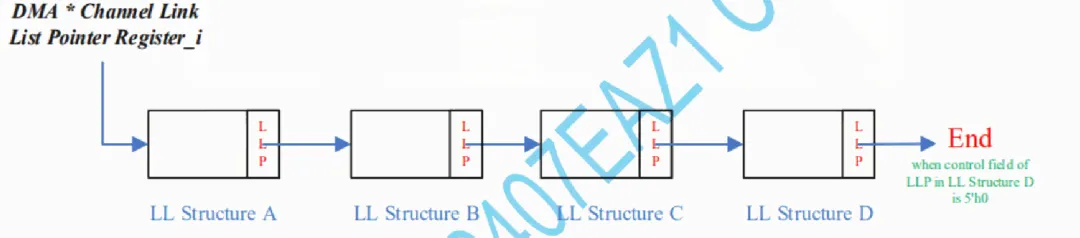
DMA提供了block和link list两种模式,需要注意的是,存放link list数据的内存必须是SoC侧,不能使用主机内存。起始地址需要在启动DMA搬运前写入寄存器,LL structure的最后是一个指针,指向下一块LL structure。
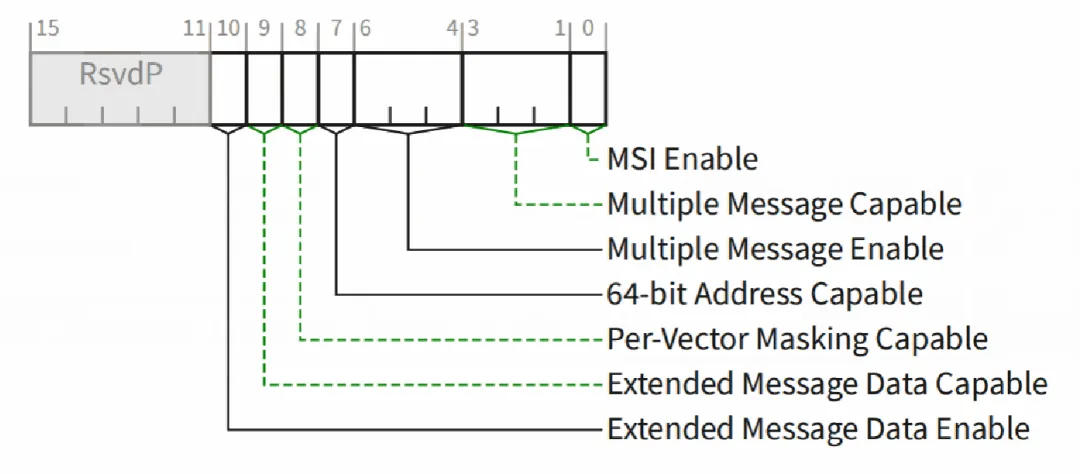
7. MSI中断
MSI指的是消息信号中断,通过往特定的地址写数据来触发CPU中断,设备向主机发送一个 memory writeTLP报文,报文中携带了目标地址和数据。
在不同的CPU架构中,产生中断的地址范围是不同,取决于各自中断控制器的实现方式。在x86架构下,这个地址范围是固定的(0xFEE00000-0xFEF00000),定义为 FSB Interrupt Message区域。
那设备是如何获得这个地址呢,而且每个设备的地址是不同的。中断地址是由设备驱动申请,主机分配的 Iiux内核提供了申请MSI中断的接口,设备驱动在初始化的时候需要向主机申请所需的中断,并且MSI要求中断号必须是连续的,最多支持32个中断。
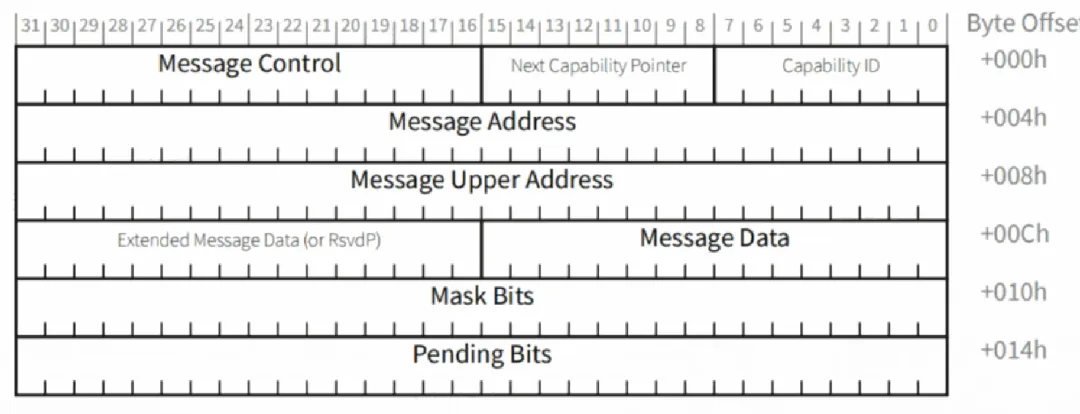
分配的中断地址存放在PCIe配置空间中,即下图Message Address域段。当PCIe设备发送MSI中断时,会将Message Address寄存器和Message Data寄存器的值分别写到TLP报文相对应的域段,Message Data存放中断号。
8. 建链流程
PCIe与主机的建链需要SoC cpu配置EP的Itssm使能后才会开始协商。
perst_n是主机扫描PCIe设备时,向PCIe发送的复位信号,标志着主机开始扫描该设备。设备需要在规定时间内(100ms)拉起tssm_enable,完成与主机的协商建链,等待主机枚举设备,否则可能会错过主机的枚举窗口,导致主机识别设备失败。
尽管协议规定了上电时序的各时间窗口,但在实际生产时,各服务器厂商并未严格按照协议规格设计,一般会提供更宽的时间窗口,以保证主机可以成功枚举设备。
由于perst_n会复位控制器以及phy,因此对于控制器以及phy的配置需要在perst_n信号之后,完成配置后,解复位PHY POR,等待PLL时钟稳定后,解复位控制器并使能ltssm_enable。
9. On-Die Scope
示波器用于构建在 DFE 输入端所接收到的数据的眼图。它的工作方式与普通数字采样示波器相同,时间分辨率为 1/64 UI,电压分辨率为 2 毫伏。
用户可通过寄存器接口手动测量眼高和眼宽,眼睛的高度和宽度在几次测量之间可能会有所不同。所有的测量都要在link training完成后进行。
10. OBS
数字和模拟测试端口被纳入到监测目的的设计中,OBS(Observation)引脚信号可以连接到逻辑分析仪或示波器进行观察。
是一种调试和测试用的辅助信号,主要用于硬件开发阶段的信号完整性分析、协议调试和故障排查。
11. 参考资料
本文首发于公众号【Equilibria】,欢迎关注获取最新文章和独家内容。