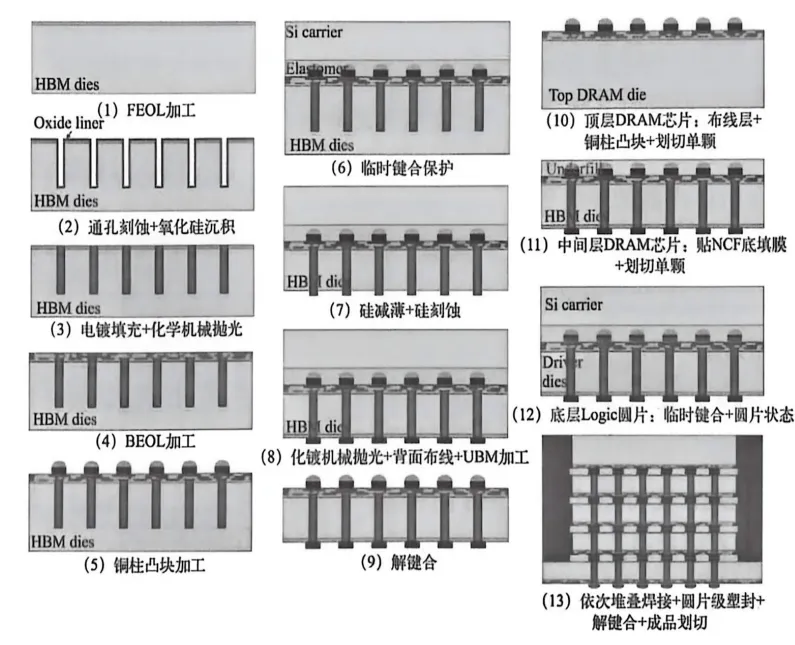
半导体学习笔记系列四·工艺篇(中):原子级雕刻与3D堆叠的艺术
芯片封装是给硅片安身立命,把微末算力拢作人间锋芒,不张扬却托住了所有科技野趣。
一、当晶体管小到不能再小
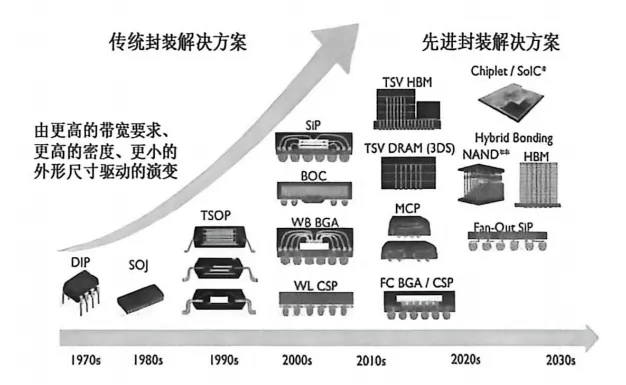
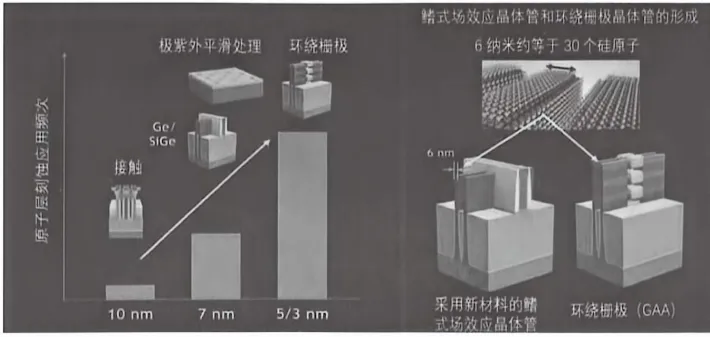
摩尔定律这件事,就像人类的青春期——迟早会结束,只是没人愿意承认。当台积电把晶体管做到3nm、2nm,甚至1.4nm的时候,工程师们发现一件很尴尬的事:光刻机追不上了,漏电控制不住了,成本也高到离谱了。造一颗芯片的钱,够在北京三环内买好几套房。这样下去,除了苹果和英伟达,谁还玩得起?封装技术演进五个阶段
但人类的聪明之处在于,一条路走不通的时候,懂得换一条。既然”把晶体管做得更小”这条路越来越难走,那不如换个思路——不缩小晶体管,而是用更好的方式把芯片连接起来。这就是”后摩尔时代”的核心逻辑,也是先进封装技术崛起的根本原因。说白了,摩尔定律的前半辈子拼的是”微观雕刻”——看谁能在硅片上刻出更细的线条。后半辈子拼的是”宏观集成”——看谁能把更多芯片巧妙地堆在一起,让它们配合得天衣无缝。第一条在制造端,叫做ALE(Atomic Layer Etching,原子层刻蚀)——一种能精确到单个原子的”减法”工艺,把刻蚀这件事推向了物理极限。第二条在封装端,叫做先进封装——TSV、混合键合、HBM、CoWoS、SoIC……一堆缩写背后,是芯片从”平房”搬进”摩天大楼”的产业变革。二、ALE:纳米世界的”精准手术刀”
2.1 减法工艺的终极形态
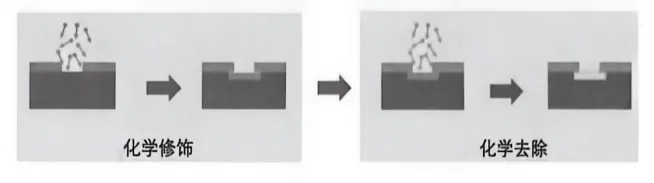
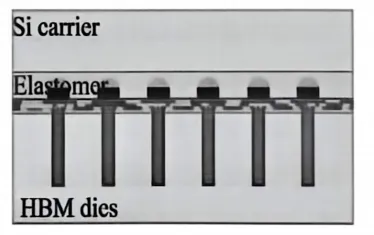
上篇文章我们聊过ALD(Atomic Layer Deposition,原子层沉积),它是一种”加法”工艺,每次循环在硅片上铺一个原子层,像搭积木一样精确。ALD deposition 是材料科学中的”小心翼翼”。ALE则是ALD的镜像——一种”减法”工艺。如果说ALD是搭积木,ALE就是拆积木,每次只拆一层,不多不少。ALE工艺示意
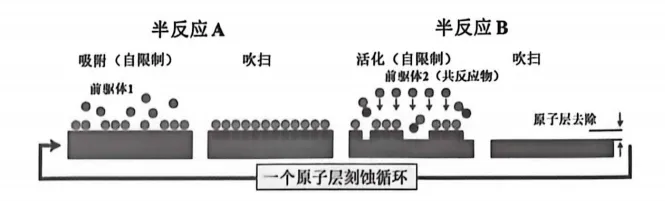
这个想法听起来简单,做起来极其困难。传统刻蚀工艺(比如RIE,Reactive Ion Etching,反应离子刻蚀)就像拿电钻在墙上打洞——快是快,但精度有限,稍微手抖一下,墙就裂了。到了7nm以下的制程,墙皮薄得像纸,电钻一碰就是个窟窿,完全没法用。ALE的聪明之处在于,它不硬来,而是分两步走——两个”半反应”(Half Reaction),像跳双人舞一样配合默契。ALE原理图:半反应A→半反应B
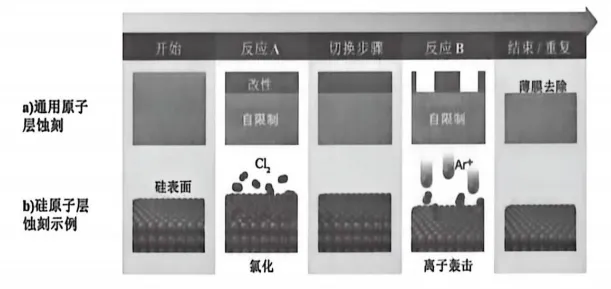
半反应A(改性步骤)。通入前驱体气体A(比如氯气Cl₂),让它吸附到硅片表面。这个反应是自限制的(Self-limiting)——气体只跟最上面一层的硅原子反应,形成一个”改性层”,多的气体不会继续往下啃。这就像一个特别有分寸的客人,只在门口站一站,绝不闯进客厅。半反应B(去除步骤)。通入Ar⁺等离子体或第二种前驱体,能量精确控制在只够去除改性层的水平。这相当于给门口站岗的客人发了个红包,请他离开——刚刚好够请走他,不会伤及屋里的其他人。然后再吹扫,清除副产物。循环往复,每次循环去掉大约一个原子层,厚度约0.1-0.3纳米。说白了,ALE就是用化学的”温柔”替代物理的”粗暴”。原子级的精准,靠的不是力大砖飞,而是对反应机理的深刻理解。2.2 PE-ALE vs 热型ALE:两派武功
ALE内部也分两派,就像少林和武当,路子不同,但目标一致。PE-ALE(Plasma-Enhanced ALE,等离子体增强ALE),是”少林派”——刚猛直接。它的去除步骤用Ar⁺等离子体轰击,能量精确控制。以刻蚀硅为例:先用Cl₂与硅表面反应,形成Si-Cl键( weakened surface layer);然后用低能量的Ar⁺轰击,恰好把 weakened layer 打掉,下面的硅层毫发无伤。PE-ALE刻蚀Si原理
热型ALE则是”武当派”——以柔克刚。它不用等离子体轰击,纯粹靠热能驱动化学反应来去除材料。刻蚀SiO₂的时候,热型ALE用NH₂F/NF₃作为反应气体,与SiO₂反应生成(NH₄)₂SiF₆——一种固态产物。然后升温到150°C左右,这玩意儿就升华跑了,留下一个干净的SiO₂表面。热型ALE刻蚀SiO₂原理
两派各有利弊。PE-ALE适用范围广,刻硅、刻金属都不在话下,但等离子体多少会带来一点晶格损伤——就像请客人出门的时候,虽然没伤及屋里的东西,但门口的门槛被蹭了一下。热型ALE完全不用等离子体,损伤近乎为零,但化学反应的选择性要求极高,不是所有材料都能找到合适的”清洗剂”。2.3 ALE的四大优势
ALE为什么能在先进制程中占据一席之地?说白了,它有四张王牌。第一,原子级精度。每次循环只去掉一个原子层,你想去掉5层就循环5次,想去掉50层就循环50次。这种”数着原子干活”的精度,传统刻蚀工艺想都不敢想。ALE技术优势与应用
第二,高选择性。通过精心设计前驱体和反应条件,ALE可以做到”指哪打哪”——只刻蚀目标材料,对旁边的材料秋毫无犯。比如刻SiO₂的时候不伤Si₃N₄,刻多晶硅的时候不伤氧化层。这在FinFET和GAA的精细结构中至关重要。第三,低损伤。尤其是热型ALE,没有等离子体轰击,不破坏材料的晶格结构。被刻蚀的表面平整得像镜子,界面态密度极低。这对于器件的电学性能影响巨大。第四,均匀性好。自限制反应有个天然的好处:整个晶圆上,不管是中心还是边缘,每个位置的反应都一样——因为反应本身就”自带刹车”。这解决了大面积刻蚀中常见的均匀性问题。当然,ALE也有缺点,而且非常明显:刻蚀速率太慢了。传统RIE一分钟能刻几十甚至几百纳米,ALE一分钟刻0.1到几纳米。这个速度在量产中是个大问题。所以ALE不会替代传统刻蚀,而是用在那些”非精确不可”的关键步骤上。2.4 ALE的应用场景
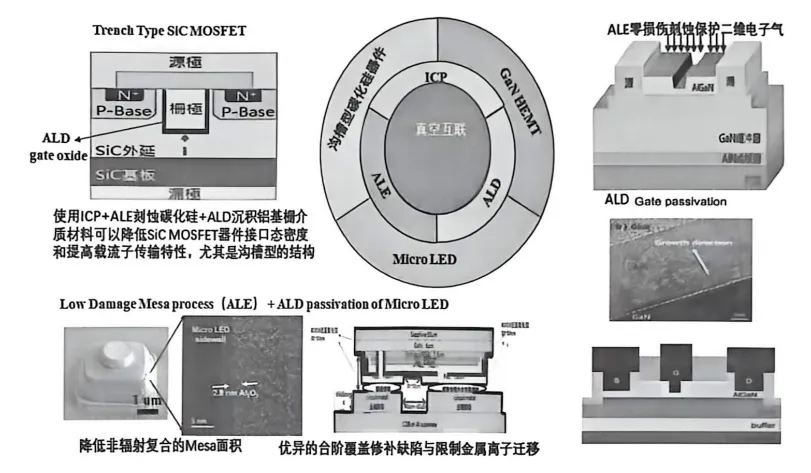
ALE目前最吃香的领域,是3D NAND的高深宽比刻蚀。3D NAND的存储层数已经堆到200多层,甚至300层,要在一个极细的孔里垂直刻蚀这么深的结构,传统RIE的侧壁粗糙度和轮廓控制完全达不到要求。ALE的高选择性和低损伤,让它成为3D NAND刻蚀的”救命稻草”。ALE在3D NAND/FinFET中的应用
其次是FinFET和GAA的精细栅极刻蚀。FinFET的鳍片(Fin)宽度只有几纳米,GAA的纳米片更薄,栅极刻蚀稍有偏差,器件性能就断崖式下跌。ALE的原子级精度,让这些结构成为可能。另外还有自对准接触孔(SAC,Self-Aligned Contact)、高选择性SiO₂/Si₃N₄刻蚀、界面氧化物去除等场景。说白了,只要是对精度要求极高、传统刻蚀”心有余而力不足”的地方,ALE就有用武之地。设备方面,Lam Research、Applied Materials、TEL三大巨头占据了ALE设备的主要市场。国内ALE设备尚在研发阶段,但也在加速追赶。三、TSV与混合键合:让芯片”通天接地”
ALE解决的是”微观雕刻”的问题。接下来我们聊”宏观集成”——先进封装。先进封装的核心思想,可以借用一句北京老话:“地少人多,往高处盖楼。”既然平面上放不下更多晶体管了,那就垂直堆叠。而实现垂直堆叠的基础技术,就是TSV(Through-Silicon Via,硅通孔)。3.1 TSV:在硅片上打”电梯井”
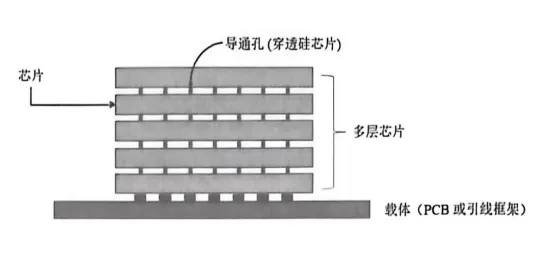
TSV的原理不复杂——在硅晶圆上打垂直的孔,孔壁镀上绝缘层,再填充铜或其他导电材料。这些垂直的”铜柱子”就像摩天大楼里的电梯井,让不同楼层的芯片能够上下互通。TSV结构示意图
第一步,深硅刻蚀。用Bosch工艺(DRIE的一种)在硅片上刻出高深宽比的孔。这个孔的深度可以从几十微米到几百微米不等,直径只有几微米到几十微米。刻一个垂直的深孔而不歪斜,本身就是高难度动作。TSV工艺流程
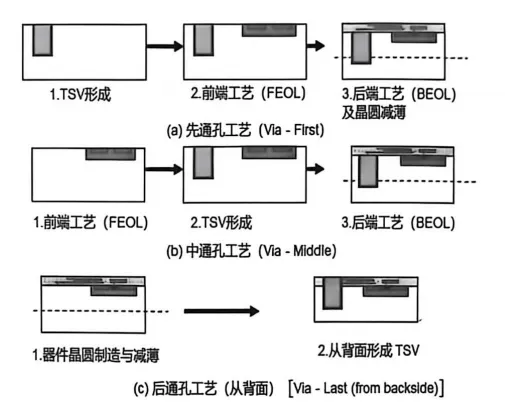
第二步,绝缘层沉积。在孔壁上沉积SiO₂等绝缘材料,防止铜填充后漏电。这步用PECVD或ALD都可以。第三步,阻挡层/种子层沉积。先镀一层Ta/TaN等阻挡层,防止铜扩散到硅里;再镀一层薄铜作为种子层,为后续电镀做准备。第四步,电镀填充。用电镀法把铜填进孔里。这步有个经典难题——高深宽比的孔容易形成空洞(Void),填充不均匀会导致电阻增大甚至断路。解决这个问题需要精密的电镀液配方和工艺控制。第五步,CMP平坦化。用化学机械抛光把表面多余的铜磨掉,露出平整的硅表面,为后续工艺做准备。TSV按工艺时序可以分为先通孔(Via-First)、中通孔(Via-Middle)和后通孔(Via-Last)三种。名字很直白——分别是在制造前、制造中、制造后打孔。各有优劣,适用于不同的场景。TSV应用领域
TSV技术看起来不复杂,但量产中的难点一大堆:高深宽比刻蚀的轮廓控制、电镀填充的无空洞工艺、不同材料的热应力匹配……任何一个环节出问题,整颗芯片就报废了。TSV是3D封装的基石,没有TSV,后面的HBM、CoWoS全都是空中楼阁。3.2 混合键合:让芯片”手拉手”
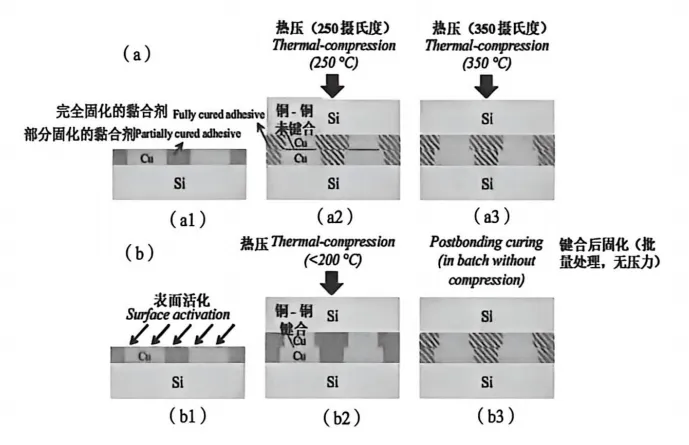
TSV解决了”上下楼之间的电梯”问题。但芯片之间怎么贴合在一起?这就需要键合(Bonding)技术。传统键合用微凸点(Microbump)——在两个芯片之间放一堆 tiny 的焊球,像搭积木一样把它们连起来。但这个方法的间距做不下去,信号传输也有损耗。混合键合(Hybrid Bonding)是一种更优雅的方案——它把两种键合方式混合在一起:电介质键合(SiO₂-SiO₂)+ 金属键合(Cu-Cu)。混合键合技术分类
想象一下,两片晶圆的表面都做好了准备:平坦的SiO₂绝缘层上,嵌着Cu金属焊盘。把两片晶圆对在一起,SiO₂和SiO₂之间通过化学键合紧密贴合,同时Cu和Cu之间在高温高压下熔合在一起。一个界面同时完成了”绝缘固定”和”导电连接”两件事——这就是混合键合的巧妙之处。混合键合关键步骤
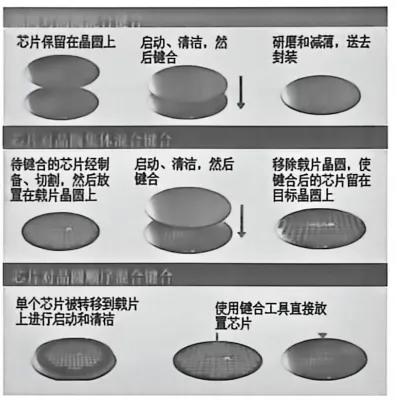
W2W(Wafer-to-Wafer,晶圆对晶圆)。两片完整的晶圆直接键合在一起,精度极高(对准精度可达亚微米级),适合同尺寸、大批量的产品。但缺点是灵活性差——如果其中一片有缺陷,键合后良品率会受拖累。D2W(Die-to-Wafer,芯片对晶圆)。先把晶圆切割成单个芯片(Die),然后挑选好的芯片,逐一键合到另一片晶圆上。灵活性高,可以混配不同尺寸、不同工艺的芯片,但对准精度比W2W差一些,工艺也更复杂。Cu-Cu键合是混合键合中的核心技术。铜金属直接对接,电阻低、间距可以做到极小(小于10微米),信号传输效率高。但铜表面容易氧化,键合前的表面处理(Surface Activation)至关重要。3.3 混合键合的实战应用
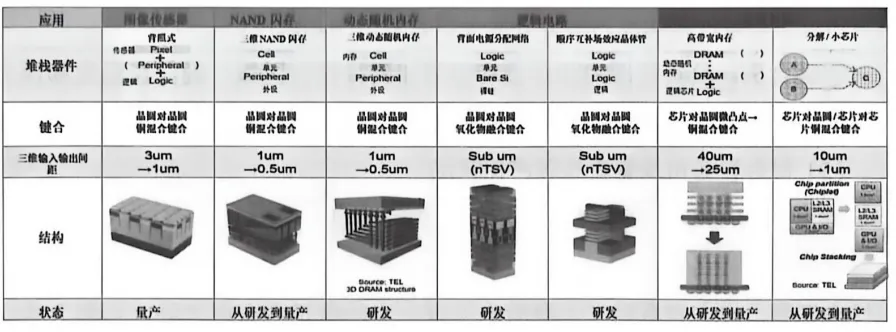
最经典的例子是索尼的CMOS图像传感器(CIS)。从2016年开始,索尼用混合键合把像素层和逻辑层堆叠在一起——像素层负责感光,逻辑层负责信号处理,两层之间用Cu-Cu直接连接。这样做的好处是像素密度大幅提升,感光面积更大,成像质量自然更好。索尼的Exmor RS系列传感器就是混合键合的杰作,后来iPhone的摄像头之所以那么强,背后也有索尼混合键合的功劳。混合键合在CIS和3D NAND中的应用
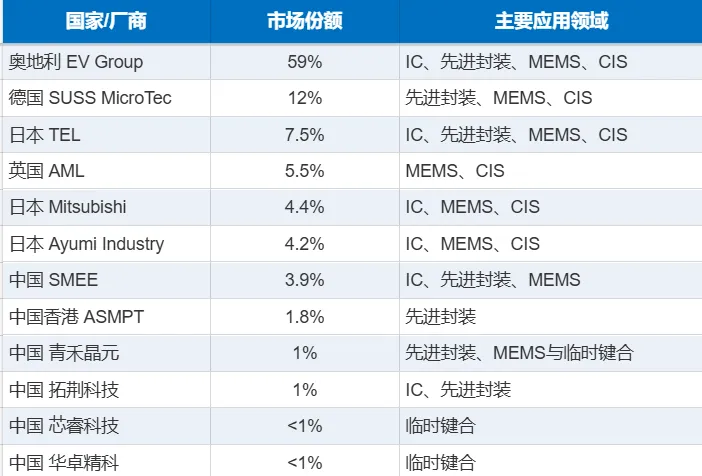
另一个重要应用是长江存储的3D NAND Xtacking架构。长江存储把存储阵列和外围逻辑电路分别做在两片晶圆上,然后通过混合键合(X-tacking技术)把它们垂直连接。这种架构的优势在于存储密度和I/O速度可以同时提升,绕开了传统3D NAND的一些性能瓶颈。AMD的3D V-Cache也是混合键合的代表作。用混合键合把额外的缓存芯片(L3 Cache)堆叠在CPU核心上方,每个CCD上多叠64MB缓存,游戏性能直接起飞。这代技术叫Zen 3 3D V-Cache,后来Zen 4、Zen 5继续沿用,已经成为AMD的杀手锏。说实话,混合键合这个技术的妙处在于——它不依赖更先进的光刻机,就能显著提升芯片性能。在EUV光刻机被卡脖子的今天,混合键合给国产半导体提供了一条”曲线救国”的可行路径。IC包含NAND、DRAM与logic,先封装包含HBM、SoIC与Chiplet目前键合设备市场相对集中,90%的市场主要集中在欧洲与日本厂商,国产设备除了上海微电子有一定的市场占有率之外,后起之秀也不容忽视,尤其是拓荆科技与青禾晶元在先进封装设备国产化的大潮之下,开始有国内先进封装大厂使用并得到不错的验证结果,其他的国产设备商如芯睿科技与华卓精科在临时键合市场站稳脚步之后,开始进军先进封装市场,这些国产设备公司都值得大家期待。四、先进封装技术大观园:大厂各显神通
TSV和混合键合是3D封装的”地基”。在地基之上,各家大厂盖出了风格迥异的”大楼”。这一节,我们走马观花地逛一圈先进封装的技术大观园。先进封装工艺与设备
4.1 SiP:把多个芯片装进一个小盒子
SiP(System in Package,系统级封装)的思路很朴素——把多个功能芯片(处理器、存储器、射频芯片、无源器件等)集成到一个封装里面,像把一套音响系统的各个组件装进一个便携音箱里。SiP结构示意
SiP不追求最先进的工艺节点,而是追求”够用就好”的集成度。一颗SiP里,7nm的CPU、28nm的射频芯片、40nm的电源管理芯片可以和平共处,通过RDL(重分布层)和基板走线连接在一起。对手机、可穿戴设备、物联网终端来说,SiP是一种性价比极高的方案——省PCB面积、降低功耗、加快上市时间。4.2 Fan-Out与InFO:扇出一片新天地
传统WLP(Wafer Level Package,晶圆级封装)的问题是I/O引脚只能分布在芯片正下方(Fan-in),数量受限。Fan-Out(扇出型封装)的做法是——把芯片切割后,重新嵌入到模塑化合物(Molding Compound)中,形成一个更大的”人造晶圆”。这样RDL可以延伸到芯片边缘之外,I/O引脚数量大幅增加,间距也可以做得更细。台积电的InFO(Integrated Fan-Out,集成扇出型封装)是Fan-Out的升级版。2016年,台积电用InFO封装了苹果A10芯片,这是InFO首次大规模量产。InFO的精髓在于把RDL做得极其精细,可以直接在封装内完成高密度互连,不需要额外的基板。苹果从此对台积电死心塌地,InFO也成了台积电封装的招牌菜。4.3 HBM:AI时代的”弹药库”
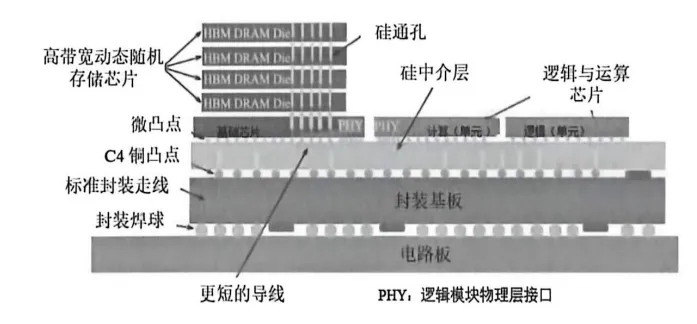
如果要评选当前半导体行业最紧俏的产品,HBM(High Bandwidth Memory,高带宽内存)绝对榜上有名。HBM是什么?简单说,就是用TSV技术把多片DRAM像三明治一样垂直堆叠起来(4层、8层、12层,甚至16层),再通过硅中介层和GPU/CPU紧密封装在一起。这样做的好处是——带宽极高、延迟极低、功耗极低。HBM结构示意图
HBM堆叠结构
HBM的演进路线是:HBM2 → HBM2E → HBM3 → HBM3E。每一代带宽都在翻倍。HBM2的带宽约256GB/s,HBM3已经超过800GB/s,HBM3E更是逼近1.2TB/s。这些数字对于AI训练来说至关重要——大语言模型(比如GPT-4、Claude)的训练需要海量参数在GPU和内存之间来回搬运,传统GDDR显存的带宽根本喂不饱GPU的计算能力,而HBM就是那个”喂饱GPU的粮仓”。HBM工艺流程
HBM的工艺流程极其复杂:从TSV刻蚀、绝缘层沉积、铜填充、晶圆减薄、微凸点制作,到多片DRAM的精确堆叠和键合……每一步都是高难度动作。HBM与GPU集成
目前全球HBM市场被海力士(SK Hynix)、三星、美光三家垄断。其中海力士占据了约50%的市场份额,是英伟达H100/H200/B200系列GPU的主要HBM供应商。HBM的产能直接决定了AI芯片的出货量,所以当下的HBM就像疫情初期的口罩——有价无市,谁掌握了产能,谁就掌握了AI算力的命脉。4.4 CoWoS:台积电的”镇店之宝”
CoWoS(Chip-on-Wafer-on-Substrate,基板上芯片封装)是台积电的2.5D封装王牌技术。它把多个芯片和HBM通过硅中介层(Silicon Interposer)连接在一起,再封装到基板上。硅中介层是CoWoS的灵魂。这是一片带有高密度布线的硅片,上面可以做出比PCB基板精细几十倍的走线,把GPU、HBM、逻辑芯片等高速互联在一起。信号走线在硅中介层上传输,损耗极低、带宽极高。CoWoS结构示意图
CoWoS-S(标准版):用整片硅中介层,TSV密度最高,性能最好。但硅中介层的尺寸越大,良率越低——这限制了能封装的芯片面积。CoWoS-R(有机中介层版):用有机基板替代部分硅中介层,成本更低、可靠性更好,但走线密度略低。适合对成本更敏感的应用。CoWoS-L(局部硅互连版):折中方案——在有机中介层上嵌入局部硅互连(LSI)桥接,既保持了高密度互连的优势,又避免了大尺寸硅中介层的良率问题。目前CoWoS-L被认为是未来几年的主流方向。CoWoS是英伟达AI GPU的御用封装。H100用了CoWoS-S,把一颗GPU和六颗HBM3封装在一起。B200用了更新的方案,CoWoS和HBM的集成密度越来越高。CoWoS的产能一直是AI行业的瓶颈。台积电的CoWoS产能在2023-2024年被英伟达包圆了一大半,其他客户排队都排不上。据说台积电正在疯狂扩产,把部分InFO的产线也改造成CoWoS。在这个AI芯片供不应求的年代,CoWoS产线的每一分钟都在印钞。4.5 表5-1巡礼:大厂各怀绝技
先进封装的江湖里,不止台积电一家在表演。各家大厂都有自己的独门绝技,值得我们逐一打量。世界大厂先进封装技术汇总
FOWLP(Fan-Out Wafer Level Package,扇出型晶圆级封装):英飞凌、恩智浦是主要推手。2D封装,功能密度较低,但成本低、尺寸小,适合汽车电子和射频应用。HMC(Hybrid Memory Cube,混合存储立方体):美光、三星、IBM联合开发。3D封装,用TSV堆叠DRAM,功能密度高。但HBM后来居上,HMC逐渐被边缘化——市场选择了更开放的HBM生态。FOPLP(Fan-Out Panel Level Package,面板级封装):三星力推。把Fan-Out的面积从晶圆级别扩大到面板级别,成本更低、效率更高。但设备投资巨大,良率控制也是挑战。EMIB(Embedded Multi-die Interconnect Bridge,嵌入式多芯片互连桥):Intel的独家技术。在有机基板里嵌入小块的硅桥接芯片,实现芯片之间的高速互连。EMIB不需要完整的硅中介层,成本比CoWoS低,但互连密度也稍逊。Foveros:Intel的3D封装技术,面对面的芯片堆叠。最经典的例子是Lakefield处理器——计算核心和I/O芯片垂直堆叠,功耗极低。Foveros代表了Intel在3D封装上的野心。Co-EMIB:Intel把EMIB和Foveros合在一起——用EMIB在同一平面上连接多个芯片,用Foveros在垂直方向上堆叠芯片。这是一种”2D+3D”的综合方案,代表了Intel对未来封装的理解。TSMC-SoIC(System-on-Integrated-Chips,集成片上系统):台积电的3D封装终极武器。SoIC最大的特点是”无凸点”(No-Bump)直接键合——芯片之间不需要微凸点,直接通过混合键合或TSV实现超高密度互连。TSV密度比传统3D IC高一个数量级。SoIC又分为CoW(Chip-on-Wafer,芯片对晶圆)和WoW(Wafer-on-Wafer,晶圆对晶圆)两种形态。CoW灵活,可以集成不同尺寸的芯片;WoW精度高,适合大批量同构集成。SoIC被台积电归类为FE 3D(前道3D)技术,和InFO/CoWoS的BE 3D(后道3D)走的是不同的路线。X-Cube(三星eXtended Cube):三星的3D封装方案,主攻5G和AI。用TSV和微凸点实现芯片堆叠,功能密度高,是对标台积电CoWoS和SoIC的竞品。这么多技术路线同时存在,说明一件事:先进封装目前还没有出现”一统天下”的标准方案。各家大厂都在按照自己的理解和优势布局,市场会最终选出最优解。五、微观雕刻与宏观集成
写到这里,我们不妨停下来想一想——ALE和先进封装,看似两条毫不相干的路线,其实指向同一个本质。ALE是在纳米尺度上追求极致的”减法”艺术。它把人类的控制精度推到了单个原子的级别,让”雕刻”这件事有了物理意义上的终点。以后不会再有”比原子层更薄的刻蚀”了,因为我们已经到底了。先进封装则是在微米到毫米的尺度上追求极致的”集成”智慧。它不追求单个晶体管的尺寸极限,而是追求”如何把更多晶体管高效地组织在一起”。这是一种系统层面的思维升级——从”做好一颗芯片”到”做好一堆芯片的协奏曲”。两条路线相辅相成。没有ALE的精细加工能力,3D NAND和FinFET的制造会遇到瓶颈;没有先进封装的集成能力,AI芯片的算力释放会被内存带宽卡死。ALE让芯片内部更强大,先进封装让更多芯片协同得更强大。半导体行业正在经历一场从”制程为王”到”集成制胜”的范式转移。光刻机当然还是命根子,但TSV设备、键合设备、RDL设备、测试设备……整条先进封装产业链都在迎来黄金时代。下一篇,我们会聊聊CPO(Co-Packaged Optics,共同封装光学模组)——当电信号的传输速度逼近物理极限,光信号开始登场。这也是目前最火的,我不得不夹带私活说一下萝卜。半导体工艺的篇章,还在继续。我们不妨保持好奇,继续看下去。