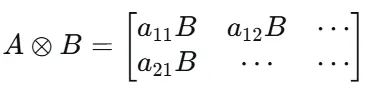import numpy as np # 导入numpy pip install numpya = np.array([[1,2],[3,4]]) # 创建数组a_m = np.matrix([[1,2],[3,4]]) # 创建矩阵print(type(a)) # <class 'numpy.ndarray'>print(type(a_m)) # <class 'numpy.matrix'>print(a)print(a_m)print(a*a) # 对应位置元素相乘print(a_m*a_m) # 矩阵相乘
<class'numpy.ndarray'> <class'numpy.matrix'> [[12] [34]] [[12] [34]] [[ 14] [ 916]] [[ 710] [1522]]
作为一个初学者,我的问题其实很简单,为什么数组和矩阵乘法规则不一样?背后的原因是什么?应用上又有何不同?因为是生物背景出身,对于遥远的高数内容---线性代数已经几乎没有记忆了。所以我花了1.5h恶补了线性代数中的基本常识,包括标量、向量、张量的几何意义,以及线性代数中向量加法、向量数乘、矩阵乘法的运算规则及其对应的几何意义。推荐教程:【【官方双语/合集】线性代数的本质 - 系列合集】https://www.bilibili.com/video/BV1ys411472E?p=2&vd_source=a7acd0333834a83b26b2cfff703ecb97
为什么数组相乘是逐元素相乘,矩阵相乘又是线性代数里矩阵相乘的运算法则?如果你看了上述我推荐的视频,建立了一些基本的对线性代数的几何直观,你就知道矩阵相乘的运算规则是有几何学意义的,它代表着矩阵的变换。而逐元素相乘(Hadamard 积),显然,没有几何学意义。那它存在的价值是什么?1. 标准矩阵乘法:线性变换的复合
规则: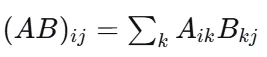
核心思想:“行与列的点积”
它将第一个矩阵的行向量与第二个矩阵的列向量进行内积,本质上是在实现线性映射的串联。
为什么需要它?
因为现实中的很多系统是线性的:旋转、缩放、投影、微分方程、神经网络的全连接层……这些都可以用矩阵表示,而系统的先后作用正好对应矩阵乘法。
如果没有标准乘法,我们就无法用矩阵描述“先做变换 A,再做变换 B”这样的复合过程。
注意:它要求 A 的列数 = B 的行数,这是线性映射可复合的维度条件。
2. Hadamard 积:逐点调制
规则: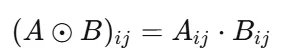
(A⊙B)ij=Aij⋅Bij
核心思想:“对应位置相乘”
它不涉及行与列之间的混合,只是将两个同形状矩阵的每个元素独立相乘。
为什么需要它?
当你想要对矩阵中的每个位置进行独立的缩放、掩码或调制时,就需要它。
例如:
与标准乘法的本质区别:
Hadamard 积不混合不同位置的信息,它只是原地修改数值,不改变数据的“空间结构”。
除了这两种乘法,还有一种叫
3. Kronecker 积:结构的张量积
规则:
核心思想:“将 A 的每个元素替换为 B 的缩放副本”
结果是块矩阵,维度是两者维度的乘积。
为什么需要它?
当你要构造更高维的、具有重复块结构的矩阵时,Kronecker 积非常自然。
例如:
量子力学中描述复合系统(两个粒子)的态空间,其算符就是 Kronecker 积。
图论中,Kronecker 积用于生成大规模网络(图 Kronecker 积模型)。
信号处理中,二维离散傅里叶变换的基矩阵可以由一维基的 Kronecker 积得到。
克罗内克积也是求解某些矩阵方程(如 Sylvester 方程)的工具。
注意:Kronecker 积不要求两个矩阵有任何形状上的兼容性,任何形状都可以做。它的输出维度是原维度乘积,因此常用于升维。
那这个乘积则不需要要求A 的列数 = B 的行数
总结
同一个对象(矩阵)可以定义多种运算规则,因为不同的运算服务于不同的目的。矩阵乘法之所以有“好几种”,并不是数学上的混乱,而是因为现实世界的问题需要不同的“组合方式”来处理数据。
所以我觉得,不能对代码里的运算规则死记硬背,而是要知道背后的原因!几何意义!实际应用的意义和区别!