机器学习基础笔记(1):从房价预测到梯度下降
引言
当我们谈论机器学习时,其实是在谈论如何让计算机从数据中学习规律。这种学习通常发生在两种截然不同的场景下。第一种场景像是一位老师拿着标准答案来教学生,这种学习方式称为监督学习(Supervised Learning)。与之相对,还有一种场景是老师不给任何答案,学生自己翻阅资料、寻找数据中隐藏的规律,这便是无监督学习(Unsupervised Learning)。
监督学习的核心逻辑非常直观。给算法一个输入(Input),它就要吐出一个输出(Output),再去评判这个输出是否接近真实世界的答案。一个最经典的例子就是房价预测。想在某个街区买房子,手里有一些历史成交数据,比如房子的面积、卧室数量、建造年份,你希望根据这些信息来预测一个合理的价格。这种输入到输出的映射,正是监督学习试图解决的问题。
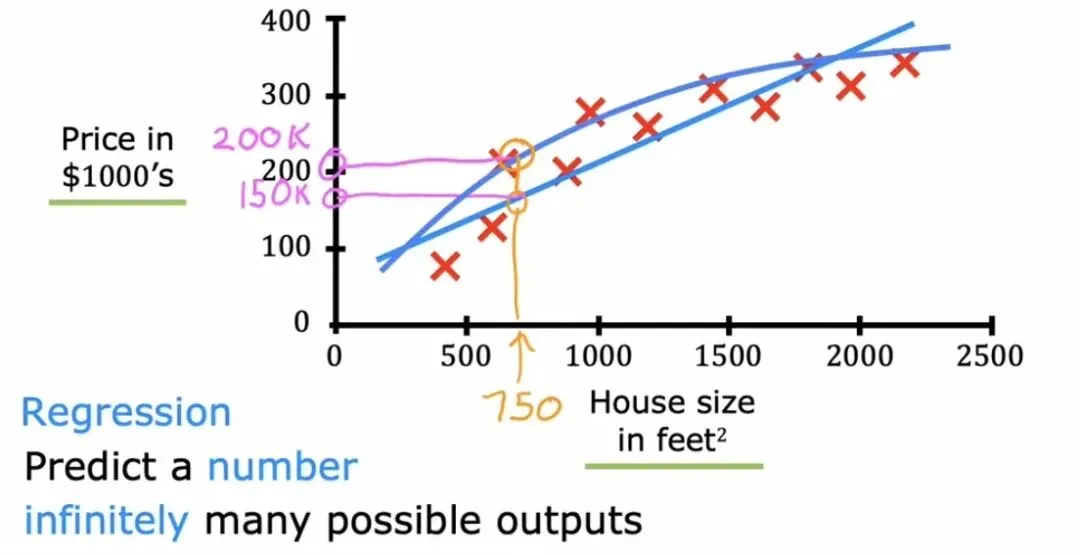 房价拟合示意图
房价拟合示意图面对房价数据,可以选择用一条笔直的线来刻画面积和价格的关系,也就是所谓的线性拟合。但从上面这张图来看,房价随面积增长的趋势并非纯粹笔直,用一条微微弯曲的曲线来描述可能更加贴近真实分布。这就是非线性模型的用武之地。当然,现实世界中的输入很少只有面积这一个维度,房子的价格可能同时受到卧室数量、地段评分、房龄等多个因素影响,这时候输入就变成了一个多维度的向量,问题也随之变得更复杂。
监督学习内部根据输出类型的不同,又可以划分为两大阵营。如果输出是一个连续的数值,比如房价是350万、某天的气温是26.5摄氏度,我们称之为回归(Regression)问题。如果输出是一个离散的类别标签,比如判断一封邮件是不是垃圾邮件、识别一张图片里是猫还是狗,我们称之为分类(Classification)问题。
无监督学习的玩法则完全不同。此时我们不再拥有所谓的标准答案,算法需要自己睁大眼睛,去数据中寻找那些有趣的模式或结构。最常见的无监督学习任务是聚类(Clustering),它会将数据点自动划分成若干个簇,使得同一簇内的点彼此相似,而不同簇的点差异较大。
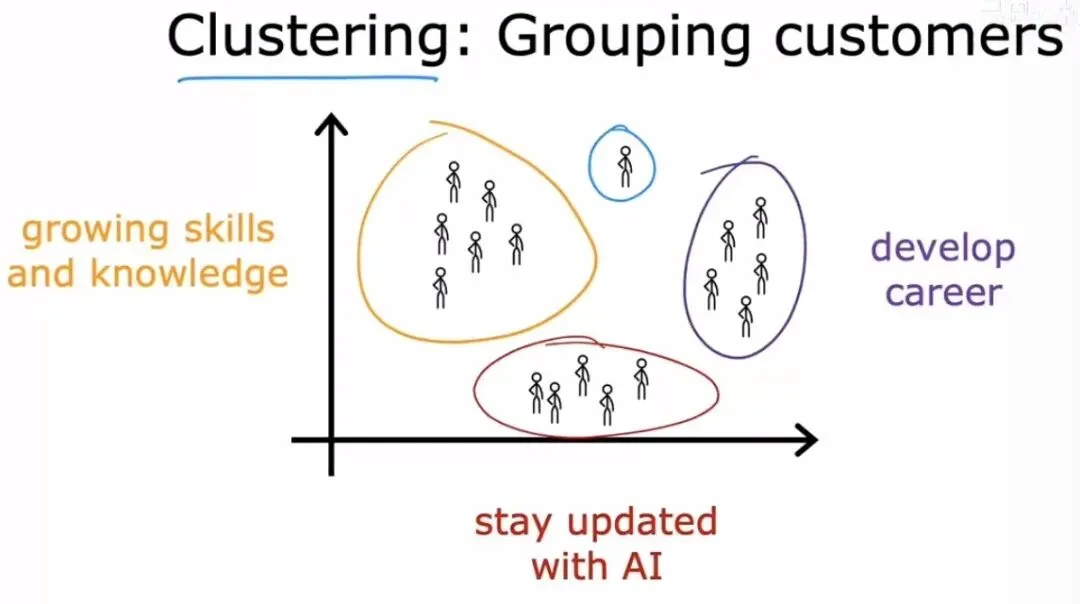 聚类示意图
聚类示意图上图展示了一个典型的聚类结果,不同颜色的点群代表了算法自动发现的类别结构,这在市场细分、社交网络分析等领域有着广泛应用。除此之外,无监督学习中还有一个重要的任务叫异常检测(Anomaly Detection),专门用来揪出数据中那些与众不同的“异类”,比如信用卡交易中的欺诈行为、工业设备传感器数据中的故障信号。
线性回归
现在让我们把目光聚焦到回归问题中最基础也最重要的一员——线性回归模型(Linear Regression Model)。它假设输入特征和输出目标之间存在一种简单的线性关系。为了把这件事说清楚,我们需要先引入一套通用的符号体系。
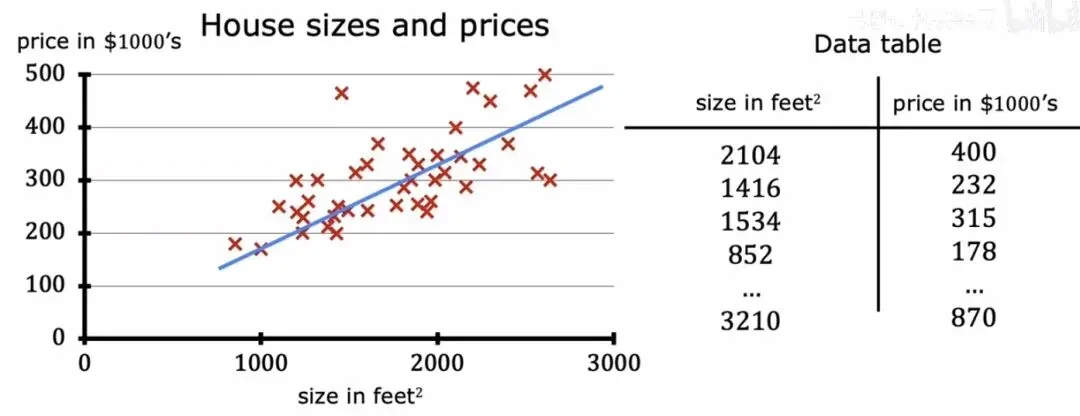 数据表示形式
数据表示形式如上图所示,我们拥有的历史数据通常可以用两种形式来展现:一种是散点图,直观显示数据分布;另一种是表格,每一行代表一个样本。我们把这些用于训练模型的数据集合称为训练集(Training Set),其中包含的样本总数记为小写字母。每一个输入变量被称为特征(Feature)或输入,而我们要预测的那个变量则被称为目标(Target)或输出。一个单独的训练样本可以写成,而第个样本则记为,注意这里的上标不是幂次,而是索引编号。
整个监督学习的流程可以概括为:训练集被喂给一个学习算法(Learning Algorithm),算法从中提炼出一个函数,此后对于任意一个新的输入,我们都可以用这个函数来产生一个估计值。这里的读作 "y hat",用来表示它是一个预测值而非真实值。
那么问题来了,这个函数应该长什么样?对于最简单的情况——只有一个输入变量的线性回归,我们将其称为单变量线性回归(Univariate Linear Regression)。函数的形式可以写成:
这里的 和 是模型的参数(Parameters), 常被称为权重(Weight),控制着直线的斜率; 常被称为偏置(Bias),控制着直线的截距。机器学习训练的过程,本质上就是在寻找一组合适的 和 ,使得这条直线能够最好地拟合训练数据。
代价函数 J
不同的参数组合会产生截然不同的直线。比如取 0.5 和取 2,直线的倾斜程度就完全不一样;取 0 和取 100,直线在纵轴上的起点也天差地别。
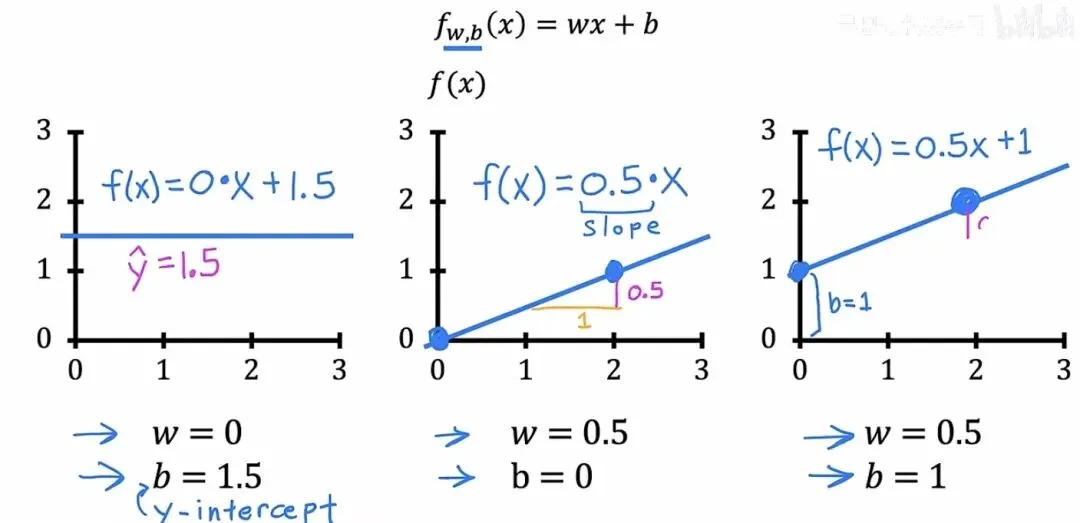 不同参数下的直线
不同参数下的直线那么怎样才能客观地评价一组参数的好坏呢?需要一个数学工具来量化模型的预测值与真实值之间的差距,这个工具就是代价函数(Cost Function),有时也叫损失函数或误差函数。对于线性回归,最常用的代价函数是均方误差(Mean Squared Error),它的表达式如下:
拆解一下这个公式。求和符号里面的 是第 个样本的预测误差,将它平方是为了消除正负号的影响并放大较大的误差,然后对所有 个样本的平方误差求平均。前面的系数 看起来有些奇怪,为什么要多一个 2?这是一个微小的数学技巧,在后续求导的过程中,这个 2 会和平方项导出来的 2 相互抵消,使得最终的导数形式更加简洁。去掉这个 2 当然也可以,但保留它已经是约定俗成的惯例。
代价函数是关于参数和的函数。需要做的事情非常明确,找到让取到最小值的和。为了建立直观感受,我们不妨先简化一下问题,假设偏置固定为 0,只考虑参数。此时模型变成了,代价函数变成了。当时,如果预测值和真实值恰好完全吻合,那么;当时,所有预测值都只有真实值的一半,误差累积起来,就会是一个大于 0 的数。如果把不同对应的值画在二维平面上,可以得到一个开口向上的抛物线。
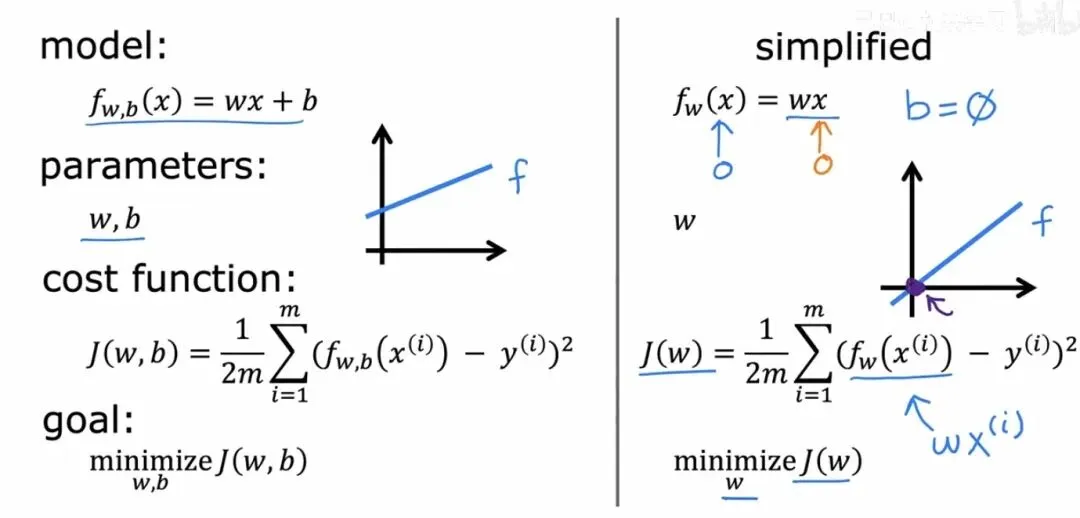 二维代价函数可视化
二维代价函数可视化
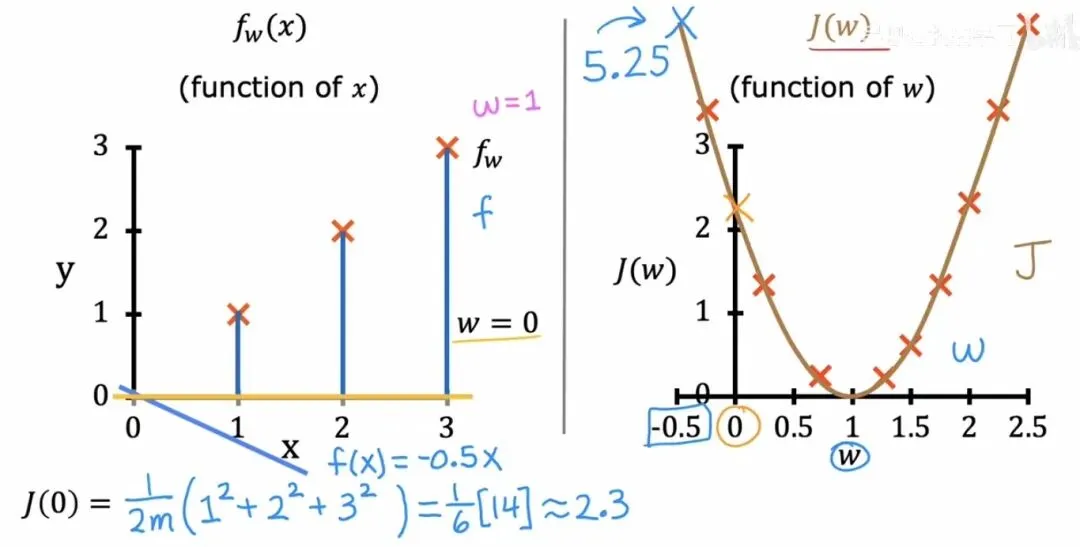 二维代价函数与模型对应关系
二维代价函数与模型对应关系当两个参数和同时存在时,代价函数就变成了一个三维空间中的曲面。想象一片微微起伏的丘陵,它的形状像一只被拉长的碗。
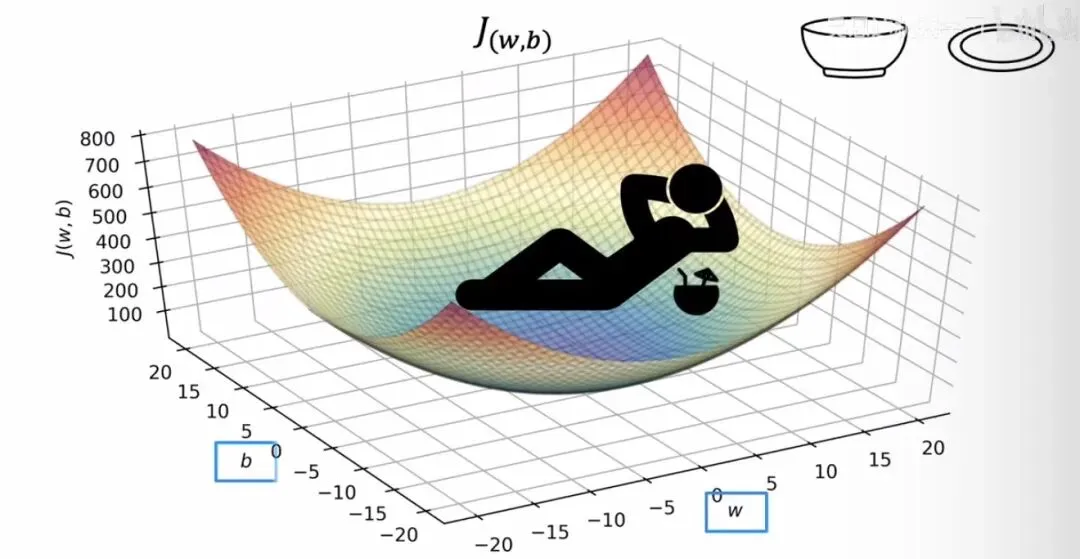 三维代价函数曲面
三维代价函数曲面为了更方便地在二维平面上表示这个三维曲面,常常会借助等高线(Contour Plot)。等高线就像用水平面去切这个碗,切出来的每一圈闭合曲线都对应着同一个值。椭圆形的中心就是碗底,也是我们梦寐以求的全局最低点。
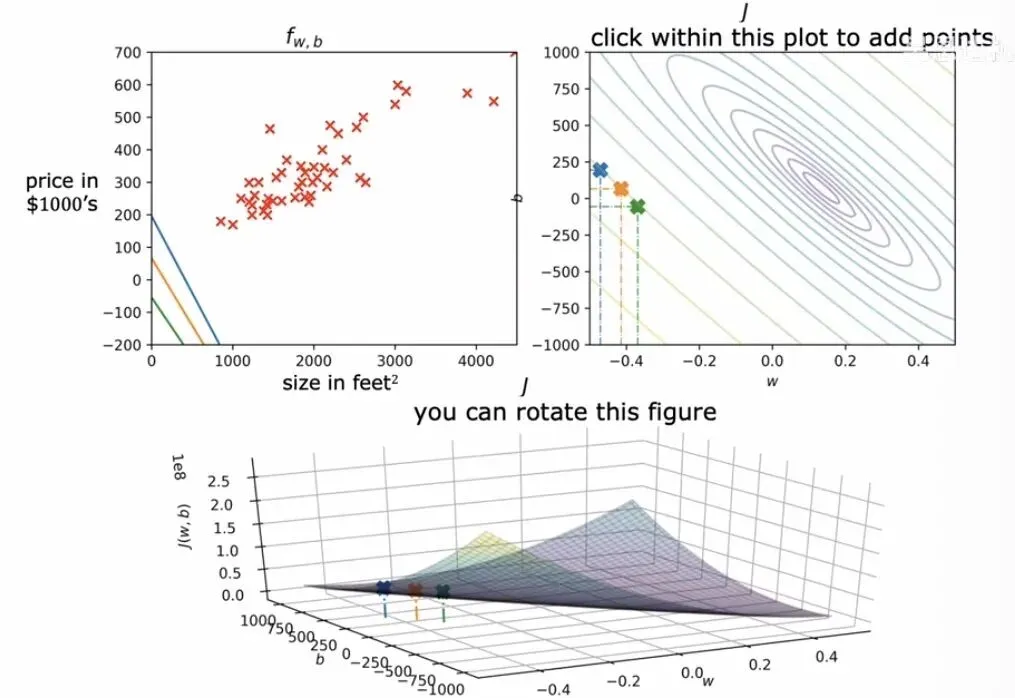 代价函数等高线图
代价函数等高线图我们可以通过等高线图来直观判断当前参数离最优解还有多远。比如下图中的情况,参数取值是,对应的拟合直线斜向下,与数据点向上的整体趋势背道而驰。从等高线图上看,这组参数落在了一个远离中心椭圆圈的边缘位置,说明代价函数的值还相当大,模型还有很大的优化空间。
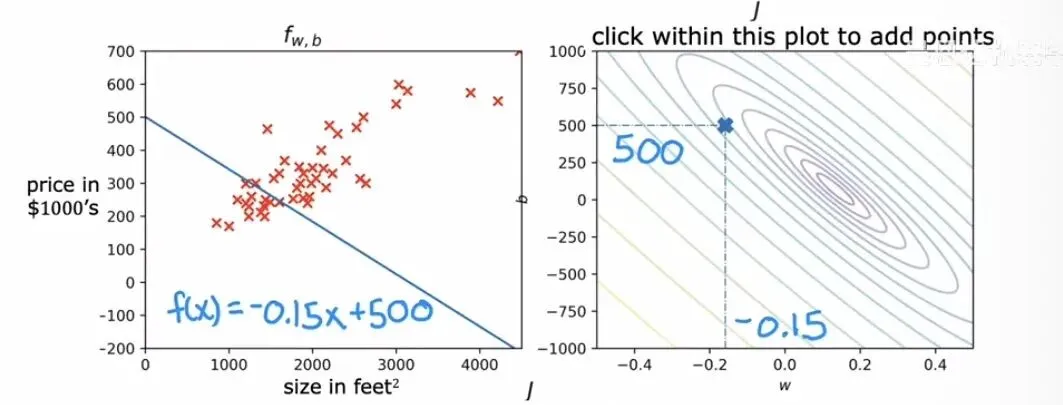 等高线与拟合直线的对应关系
等高线与拟合直线的对应关系显然,靠肉眼盯着等高线图去手动调整参数既不现实也不优雅。我们需要一种系统性的、可以由计算机自动执行的优化方法,而这正是梯度下降即将登场的时候。
梯度下降
梯度下降(Gradient Descent)是一种用途极为广泛的优化算法,它不仅可以用来最小化线性回归的代价函数,事实上几乎任何可微函数的最小化问题都可以用它来求解。在深度学习领域,模型的参数量动辄数百万甚至上亿,梯度下降及其变体几乎是训练这些庞然大物的唯一选择。
假设我们有一个关于若干参数的代价函数,目标是最小化它。梯度下降的策略朴素而有效,首先给所有参数随机设定一个初始值(甚至全设为 0 也无妨),然后计算当前点处代价函数关于每个参数的梯度(也就是偏导数),最后沿着梯度的反方向移动一小步。形象地说,就像一个蒙着眼睛的人站在山坡上,通过脚尖感受脚下地面的倾斜方向,然后向最陡峭的下山方向迈出一小步,如此反复,直到到达某个平坦的谷底。
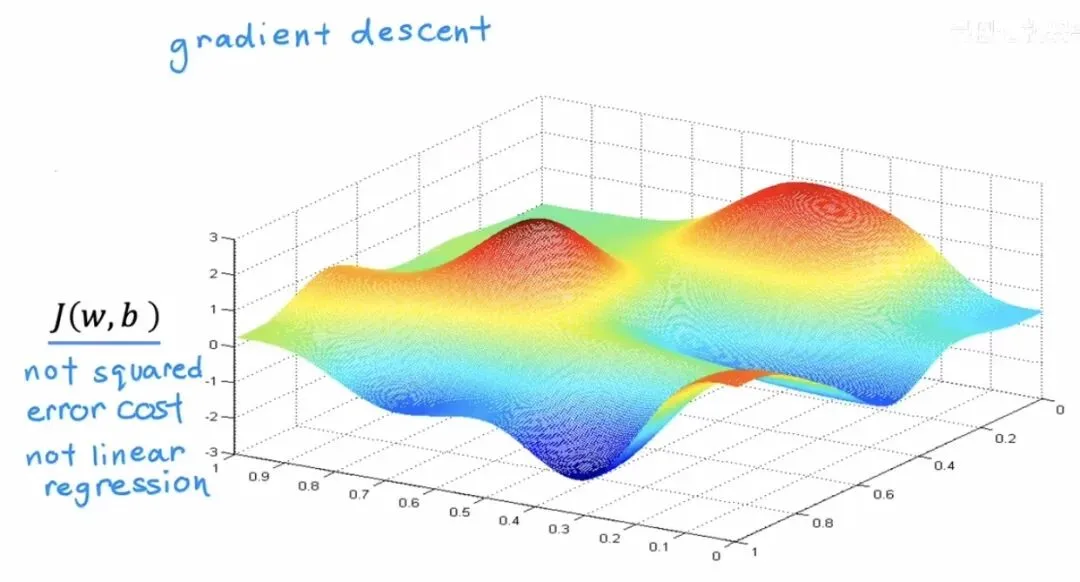 深度学习中常见的复杂代价函数
深度学习中常见的复杂代价函数上图展示了一个在深度学习中可能遇到的代价函数曲面,它不再是简单平滑的碗状,而是布满了起伏的山峰和深邃的峡谷。由于初始点的位置不同,梯度下降可能会将你带到不同的局部极小值点,这也是优化过程中一个需要关注的问题。
梯度下降的更新规则可以用以下两个公式来表达:
公式中的被称为学习率(Learning Rate),它是一个介于 0 到 1 之间的正数,决定了每一步迈出的大小。和分别是代价函数对和的偏导数,它们指示了在当前点处,函数值上升最快的方向。因为我们要最小化函数,所以需要沿着导数的反方向更新参数,也就是减去乘以导数。
在实现梯度下降时有一个至关重要的细节:必须同时更新和。正确做法是先分别计算两个临时值:
然后再将这两个临时值赋值给 和 :
错误的做法是先更新 ,然后用更新后的 去计算 的偏导数,这会导致两个参数的更新步调不一致,算法行为将偏离标准梯度下降的轨迹。
 正确与错误的参数更新方式
正确与错误的参数更新方式为了理解导数项究竟是如何引导参数向最小值移动的,我们可以看一个只含的简化情况。假设代价函数是一条开口向上的抛物线,在某一点处,如果切线斜率为正(导数大于 0),根据更新公式,会减去一个正数,于是变小,向左移动靠近谷底。反之,如果切线斜率为负(导数小于 0),减去一个负数等价于加上一个正数,变大,向右移动靠近谷底。导数项就像一个自动导航仪,时刻根据当前位置的坡度,将参数推向代价更低的方向。
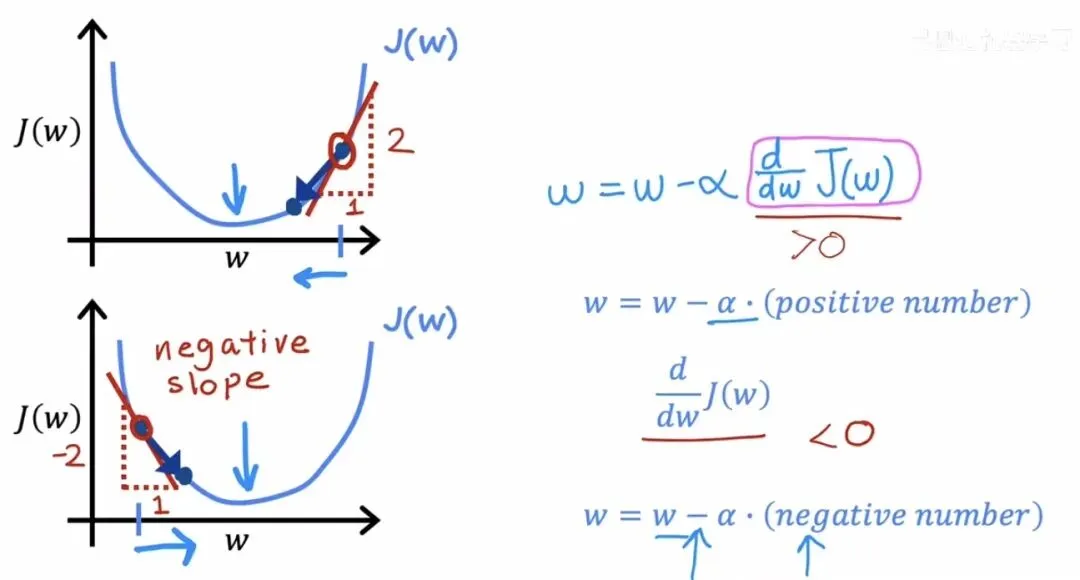 导数项如何引导参数移动
导数项如何引导参数移动学习率的选取对梯度下降的表现有着举足轻重的影响。如果选得太小,每一步迈得谨小慎微,虽然最终能到达谷底,但下降过程会极其缓慢,耗费大量的计算资源。如果选得太大,则可能用力过猛,一步直接跨过谷底,甚至在谷底两侧来回剧烈震荡,代价函数的值不仅不降反而可能越弹越高,永远无法收敛。
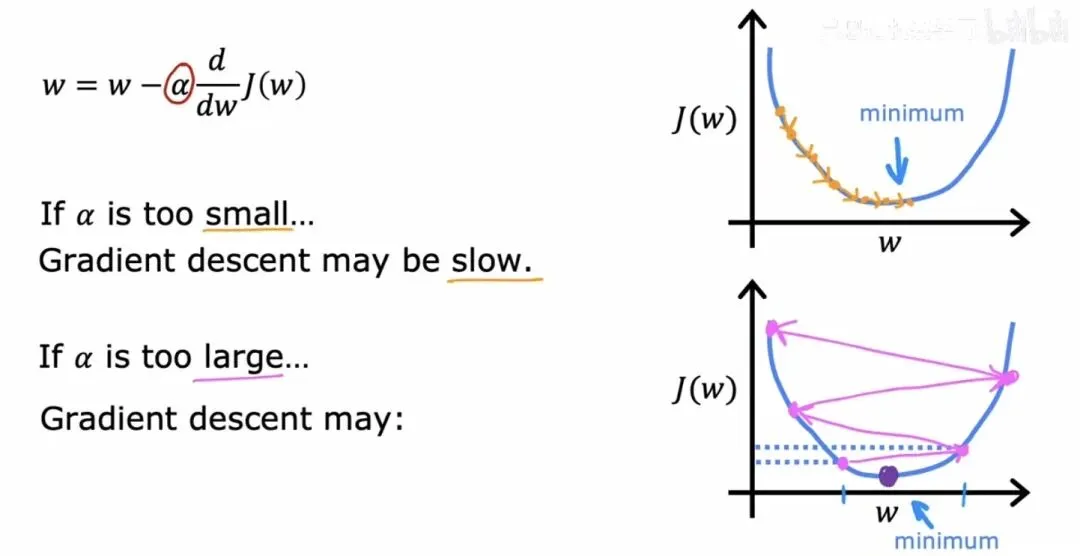 学习率大小的影响
学习率大小的影响还有一个有意思的问题:当参数恰好抵达一个局部最小值时,下一步会发生什么?由于谷底处的切线是水平的,偏导数为零,根据更新公式,和都将保持不变,梯度下降在这里自然停止,即使你强行调大学习率也无济于事。这意味着梯度下降算法在到达局部最优后会自动“熄火”。另外值得注意的是,随着参数逐渐靠近谷底,坡度往往会变得越来越缓,导数的绝对值自然减小,因此即便学习率保持不变,每一步的实际移动幅度也会自动变小,这种天然的减速机制有助于我们稳稳地停在最优点附近。
线性回归中的梯度下降实现
将梯度下降应用到线性回归的代价函数上,我们需要做的就是把均方误差的表达式代入偏导数公式中进行推导。这是一个纯数学计算的过程,我们来一步一步地推演。
已知代价函数为:
对 求偏导时,应用链式法则,外层的平方项导数为 倍,正好与前面的 抵消:
对 求偏导的过程几乎一样,只是内层对 的导数为 1,因此:
现在我们可以写出完整的线性回归梯度下降算法。在每一步迭代中,我们使用所有 个训练样本来计算当前模型预测值与真实值的误差,然后分别累加得到两个偏导数,最后用学习率更新参数。如此循环往复,直到代价函数的值收敛到一个稳定的水平,或者参数的改变已经微乎其微。
有时可能会担心梯度下降会陷入局部最优解而无法找到全局最优,但幸运的是,对于线性回归问题,它的代价函数是一个关于参数的凸函数(Convex Function),碗状的曲面只有一个全局最低点,不存在任何其它可能让人误入歧途的局部极小值。因此,只要学习率设置得当,梯度下降总能找到那个唯一的、最好的解。
下图展示了一次完整的梯度下降训练过程中,拟合直线是如何一步一步从初始的胡乱猜测逐渐调整到最佳位置的。每一步更新参数,直线都向数据点群的方向靠拢一点,直到最后稳定地穿过数据分布的中心。
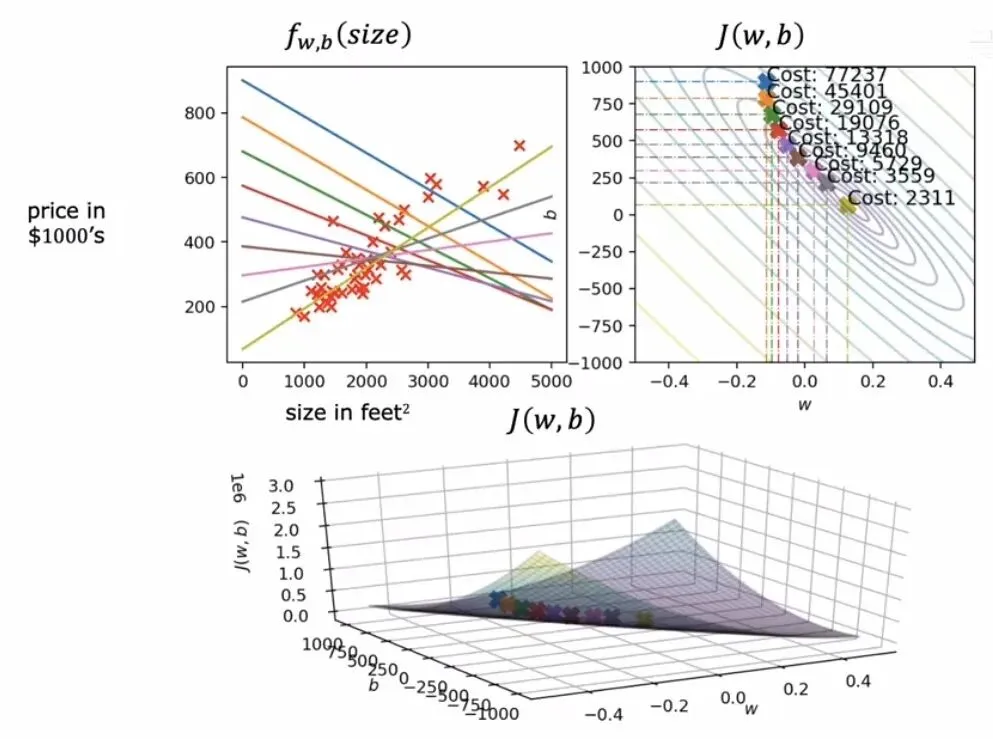 梯度下降过程的可视化
梯度下降过程的可视化批量梯度下降
在上面的算法描述中,我们每一次更新参数和,都需要遍历整个训练集,把所有个样本的误差汇总起来计算梯度。这种训练方式有一个专门的名字,叫作批量梯度下降(Batch Gradient Descent)。这里的“批量”指的是每一次更新都使用了全部的训练数据。
批量梯度下降的优点非常明显:由于每一步的梯度计算都基于整个数据集,它的优化轨迹非常稳定,代价函数会随着迭代次数的增加而单调递减,最终必然收敛。但它也有一个不容忽视的缺点——当训练集规模非常庞大时(比如数百万甚至上亿个样本),每一次小小的参数更新都要扫过全部数据,计算量将大到难以承受。
为了应对这个问题,后续的研究者们提出了两种改进方案。一种叫随机梯度下降(Stochastic Gradient Descent,简称 SGD),它每次只随机抽取一个样本来计算梯度并更新参数,速度极快但梯度方向波动剧烈。另一种叫小批量梯度下降(Mini-batch Gradient Descent),它在二者之间取得了平衡,每次抽取一小批样本(比如 32 个或 64 个)来计算梯度。在深度学习领域,小批量梯度下降是使用最为广泛的训练方式,它既保证了较快的计算速度,又维持了相对稳定的收敛过程。
至此完成了从监督学习的基本概念,到线性回归模型的定义,再到代价函数和梯度下降算法的一整套推演。这条逻辑链条构成了机器学习最为基础且核心的工作流程,定义模型结构、设计衡量好坏的代价函数、运用优化算法寻找最佳参数。后续更复杂的模型,逻辑回归、神经网络还是支持向量机,其背后的思想内核都与这里的内容一脉相承。
文章首发于:
https://lsqkk.github.io/posts/?columns=机器学习笔记
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
