不追求一次跑通,而是建立"报错 → 定位 → 修复"的排错心智模型。
把期望调到正确的位置
前四篇都在讲"原理"。这一篇开始动手。但我必须先泼一盆冷水:你的第一次 Unidbg 调用几乎不可能跑通。
这不是你的问题,这是 Unidbg 的"特性"。回想第二篇讲的世界观 — Unidbg 是一个"残缺的 Android 系统",它的 30% 实现 + 你来补 70% 才是它工作的常态。第一次跑必然会撞上"它没实现"的某个洞。
所以这一篇的目标不是"教你怎么一次跑通一个签名 SO",而是回答一个更重要的问题:当第一次必然失败的时候,你该怎么办?
具体一点:
- 第一次失败时,你能不能立刻知道报错指的是哪一类问题?
- 看到一长串栈帧,你能不能迅速锁定哪一帧才是真正需要修的地方?
- 修一个洞之后又冒出三个新洞,你能不能保持节奏逐个收拾掉而不是一次性放弃?
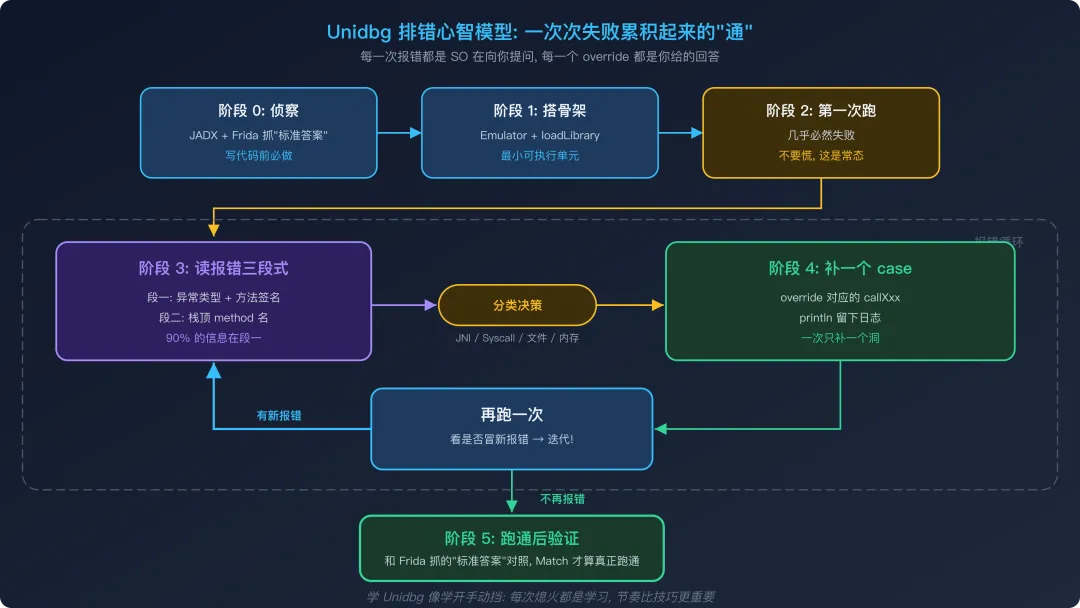
这一套"报错 → 定位 → 修复 → 再次报错"的循环,是 Unidbg 工程师的日常。它不是一种本能,而是一套可以被刻意训练的工作流。这一篇就是带你把这套工作流走一遍。
打个比方:学 Unidbg 像学开手动挡的车。第一次踩离合 99% 会熄火,但教练不会因此让你直接开自动挡。熄火本身不是失败 — 重新点火,再来一次,才是学车的真正内容。
阶段 0:动手前的侦察
直接打开 IDE 写代码是最常见的新手错误。Unidbg 的工作量是"补环境" — 而补什么环境,取决于 SO 想要什么。所以在写第一行 Java 代码之前,你应该已经掌握以下情报:
Unidbg 排错心智模型: 一个迭代闭环情报 1:Java 层调用是什么样
打开 JADX,反编译目标 APK。你需要找到三件东西:
1. Native 方法的声明
// 假设我们要分析 com.example.app.NativeBridge
publicclassNativeBridge{
static {
// 注意 SO 名字: libexample 或者 example
System.loadLibrary("example");
}
// Native 方法的完整声明
publicstaticnative String sign(byte[] data, boolean useV2);
}
从这里你能拿到:
- SO 文件名:
example → 实际文件叫 libexample.so
这四点信息直接决定了你后面在 Unidbg 里怎么调用这个函数,缺一不可。
2. 调用方的代码
光知道方法签名还不够。你需要看真实代码里怎么传参给这个 Native 方法:
// HTTP 拦截器中的真实调用
String body = request.body().toString();
byte[] payload = (timestamp + ":" + body).getBytes(StandardCharsets.UTF_8);
String signature = NativeBridge.sign(payload, true); // 注意第二个参数
这一步揭示了 SO 的实际使用语义:第一个参数不是"任意 byte[]",而是时间戳 + 冒号 + body 的 UTF-8 编码。如果你瞎传一个 byte 数组进去,跑出来的签名肯定对不上真机。
3. 关键的 JNI 上下文
很多 Native 方法的第一个参数是 Context 或者类似的对象 — 这意味着 SO 内部会通过 JNI 反查这个 Context 拿一些信息(包名、版本号、设备 ID)。如果你看到这种签名:
publicstaticnative String sign(Context ctx, byte[] data);
那你就要做好心理准备:这个 SO 大概率会调一堆 getPackageName、getPackageInfo、getSystemService 之类的 JNI 函数。这些都需要在你的 AbstractJni 子类里逐一应答 — 每一个都是一个潜在的报错点。
情报 2:真机上跑出来的"标准答案"
写 Unidbg 之前,你必须先用 Frida 在真机上跑一遍目标函数,记录下入参和返回值。理由有二:
理由一:你需要一个对照基准
Unidbg 跑通之后,你怎么知道结果是对的?只有真机上同入参跑出来的结果做对照,才能验证。没有对照的"跑通"是假的跑通。
理由二:很多 SO 的入参格式是非平凡的
签名函数的入参可能不是表面上的"那个字段",而是一段经过 Java 层组装的、包含分隔符 / 时间戳 / 设备 ID 的复合数据。光看 Java 代码可能猜不准,Frida hook 一下立刻就清楚了。
一个最小化的 Frida 脚本模板:
// frida -U -l hook.js -f com.example.app
Java.perform(function () {
var NativeBridge = Java.use("com.example.app.NativeBridge");
// Hook 目标 native 方法
NativeBridge.sign.implementation = function (data, useV2) {
// 打印入参 (转 hex 方便复制)
var hex = "";
for (var i = 0; i < data.length; i++) {
hex += ("0" + (data[i] & 0xff).toString(16)).slice(-2);
}
console.log("[+] sign() called");
console.log(" data (hex): " + hex);
console.log(" data (str): " + Java.use("java.lang.String").$new(data));
console.log(" useV2: " + useV2);
// 调用原方法拿返回值
var ret = this.sign(data, useV2);
console.log(" returned: " + ret);
return ret;
};
});
跑一次目标 App 的真实场景(比如发起一次登录请求),把控制台输出的 data (hex) 和 returned 各保存一组。这就是你后面要让 Unidbg 复现的"标准答案"。
情报 3:SO 文件本身
把目标 SO 单独从 APK 里提取出来。最简单的办法是把 APK 当 zip 解压:
# APK 本质就是 zip
unzip -o target.apk -d target_extracted
ls target_extracted/lib/
# arm64-v8a/ armeabi-v7a/ ...
# 选 ARM64 (现代 Android 设备的默认架构)
cp target_extracted/lib/arm64-v8a/libexample.so ./
现在你有了完整的"侦察包":APK 文件 + SO 文件 + Java 层调用代码 + Frida 跑出来的入参/返回值样本。可以开始写 Unidbg 代码了。
阶段 1:环境准备
Java 版本
Unidbg 要求 JDK 8 或 JDK 11。新一些的 JDK(17/21)也能跑,但 Unidbg 的某些反射操作可能触发 --add-opens 的警告甚至错误。如果你不想折腾 JVM 参数,用 JDK 11 是最稳妥的选择。
# 验证 JDK 版本
java -version
# 输出应该类似:
# openjdk version "11.0.21" 2023-10-17
Maven 项目骨架
Unidbg 是 Java 项目,最直接的引入方式是 Maven。新建一个项目,pom.xml 大致是这样:
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>unidbg-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<!-- Unidbg 没有发布到 Maven 中央仓库, 用 jitpack -->
<repository>
<id>jitpack.io</id>
<url>https://jitpack.io</url>
</repository>
</repositories>
<dependencies>
<!-- Unidbg 的 Android 支持 (包含 JNI / Dalvik VM 模拟) -->
<dependency>
<groupId>com.github.zhkl0228</groupId>
<artifactId>unidbg-android</artifactId>
<version>0.9.8</version>
</dependency>
</dependencies>
</project>
关于版本号:0.9.x 是当前主流稳定版。如果你想用最新主分支特性,可以把版本号改成 master-SNAPSHOT,但 jitpack 拉取时间会变长。第一次跑建议先用稳定版。
项目结构项目结构
把 APK 和 SO 都放在 resources/target/ 下。APK 一定要放完整的,不能只放 SO — Unidbg 的 createDalvikVM 会从 APK 中读取签名、包名、resources 等信息,缺了 APK 后续会有一连串奇怪的问题。
阶段 2:搭建最小可执行骨架
骨架的目标是"让代码能跑到 module.callFunction(...) 那一行",先不管会不会成功。
package com.example;
import com.github.unidbg.AndroidEmulator;
import com.github.unidbg.Module;
import com.github.unidbg.linux.android.AndroidEmulatorBuilder;
import com.github.unidbg.linux.android.dvm.AbstractJni;
import com.github.unidbg.linux.android.dvm.DalvikModule;
import com.github.unidbg.linux.android.dvm.DvmObject;
import com.github.unidbg.linux.android.dvm.VM;
import com.github.unidbg.linux.android.dvm.array.ByteArray;
import java.io.File;
publicclassSignDemoextendsAbstractJni{
privatefinal AndroidEmulator emulator;
privatefinal VM vm;
privatefinal Module module;
publicSignDemo(){
// -------- 1. 创建模拟器 --------
// ARM64 是现代 App 的主流架构, 优先选 64 位
// setProcessName 很重要: SO 内部可能用它做完整性校验
emulator = AndroidEmulatorBuilder.for64Bit()
.setProcessName("com.example.app")
.build();
// -------- 2. 创建 Dalvik VM (即 Unidbg 的"假 ART") --------
// 必须传入完整 APK, Unidbg 会读取签名 / 包名 / 资源
vm = emulator.createDalvikVM(new File("src/main/resources/target/target.apk"));
// 把当前类注册为 JNI 回调处理器
// SO 里所有 JNI 调用最终都会回到这个类的 callXXX 方法上
vm.setJni(this);
// 开启详细日志, 调试阶段必开
// 这会打印每一次 JNI 调用 / 系统调用 / 文件访问的细节
vm.setVerbose(true);
// -------- 3. 加载目标 SO --------
// 第二个参数 true 表示自动执行 .init_array 和 JNI_OnLoad
// 这一步会跑 SO 的初始化代码 (有些 SO 会在这里做反调试 / 反模拟器检测)
DalvikModule dm = vm.loadLibrary(
new File("src/main/resources/target/libexample.so"),
true
);
module = dm.getModule();
}
public String callSign(byte[] data, boolean useV2){
// -------- 4. 调用目标 native 函数 --------
// 关键: 参数顺序必须严格匹配 JNI 调用约定
// arg0: JNIEnv* — 用 vm.getJNIEnv() 获取
// arg1: jclass / jobject — 静态方法传 jclass, 实例方法传 this 对应的 jobject
// arg2..: 实际参数 — 按签名顺序逐个传入
DvmObject<?> result = module.callStaticJniMethodObject(
emulator,
"sign([BZ)Ljava/lang/String;",
new ByteArray(vm, data),
useV2
);
// 返回值是 DvmObject, 转 String
return (String) result.getValue();
}
publicstaticvoidmain(String[] args){
SignDemo demo = new SignDemo();
// 用 Frida 抓到的同一组入参跑一次, 拿来和真机结果对照
byte[] input = "1700000000:hello world".getBytes();
String sig = demo.callSign(input, true);
System.out.println("sign result = " + sig);
}
}
这段代码刻意只有"必要"的部分。注意几个细节:
extends AbstractJni:继承之后你才能 override resolveClass / callObjectMethod 等方法 — 这就是补 JNI 环境的入口setVerbose(true):第一次跑必须开,关掉的话报错信息会少一半callStaticJniMethodObject vs callFunction:前者会自动按 JNI 约定填充 JNIEnv* 和 jclass,更省心;后者更底层,需要自己构造参数
关键基本功:JNI 方法签名
签名是 "sign([BZ)Ljava/lang/String;" 这一行神秘的字符串。理解它是 Unidbg 的核心基本功 — 不理解签名,每一次调用都会是猜谜游戏。
签名的结构
JNI 方法签名遵循一个紧凑的格式:
方法名(参数1参数2参数3...)返回值
以 sign([BZ)Ljava/lang/String; 为例:
JNI 方法签名解析每一个"字母"代表一个 Java 类型。完整的对照表:
| | |
|---|
Z | boolean | |
B | byte | |
C | char | |
S | short | |
I | int | |
J | long | |
F | float | |
D | double | |
V | void | |
L<类全名>; | | |
[<类型> | | |
几个例子练习
()V void method()
(I)Z boolean method(int)
([BI)Ljava/lang/String; String method(byte[], int)
(Ljava/lang/String;)[B byte[] method(String)
([[I)V void method(int[][]) ← 二维数组
(Landroid/content/Context;I)Ljava/lang/String; String method(Context, int)
几个常见坑:
Z 是 boolean,不是 byte — 这是最常见的错误。B 才是 byte,Z 来自 Pascal 的传统- 类全名末尾的
; 不能省 — Ljava/lang/String; 是对的,Ljava/lang/String 会被解析失败 - 包名分隔符是
/ 不是 . — Java 里写 java.lang.String,签名里写 java/lang/String - 返回值在括号外,不在括号内 —
(I)V 是 void method(int),不是 int method(void)
不要死记,从 JADX 直接复制
最高效的做法是让 JADX 替你生成签名:
- 右键 → "Copy as → Smali method signature" 或者切到 smali 视图
- Smali 视图直接显示完整签名,复制粘贴到 Unidbg 代码里
如果 JADX 没装这个功能(旧版本可能没有),你也可以从 smali 文件里搜:
.method public static native sign([BZ)Ljava/lang/String;
.end method
中间那段就是你要的签名 — 包括方法名 + 括号 + 参数 + 返回值,整段直接复制就行。
第一次运行:报错的三段式结构
骨架写完,按下 Run。99% 的概率你会看到一段报错,类似这样:
[10:12:34 437] WARN [c.g.u.l.a.d.AbstractJni] (AbstractJni:743) -
java.lang.UnsupportedOperationException:
android/content/pm/PackageManager->getPackageInfo(Ljava/lang/String;I)Landroid/content/pm/PackageInfo;
at com.github.unidbg.linux.android.dvm.AbstractJni.callObjectMethodV(AbstractJni.java:743)
at com.github.unidbg.linux.android.dvm.AbstractJni.callObjectMethodV(AbstractJni.java:412)
at com.github.unidbg.linux.android.dvm.DalvikVM64$53.handle(DalvikVM64.java:1024)
at com.github.unidbg.linux.ARM64SyscallHandler.hook(ARM64SyscallHandler.java:127)
at com.github.unidbg.arm.backend.UnicornBackend$11.hook(UnicornBackend.java:347)
at unicorn.Unicorn$NewHook.onInterrupt(Unicorn.java:128)
...
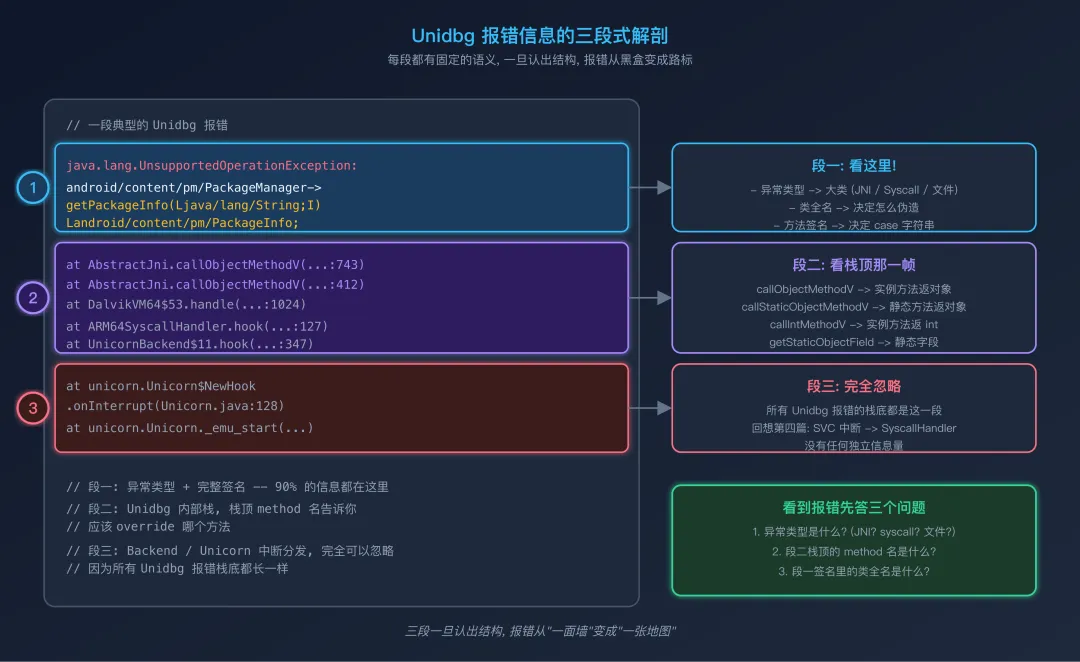
第一次看到这种东西可能想立刻关闭终端。但只要你识别出报错的三段式结构,它会立刻变得平易近人。
Unidbg 报错信息的三段式解剖段一:异常类型 + 调用签名(第 1-3 行)
这是你最需要看的部分。它告诉你两件事:
java.lang.UnsupportedOperationException:
android/content/pm/PackageManager->getPackageInfo(Ljava/lang/String;I)Landroid/content/pm/PackageInfo;
- 异常类型:
UnsupportedOperationException → 这是 Unidbg 抛的"我没实现" - 完整签名:
PackageManager->getPackageInfo(...) → 谁调谁、签名是什么
读到这里你就已经知道:
- SO 通过 JNI 调了
PackageManager.getPackageInfo(String packageName, int flags) - 这是一个实例方法(看后面的
callObjectMethodV 而不是 callStaticObjectMethodV) - 你需要在
AbstractJni 子类里 override callObjectMethodV,识别这个签名,返回一个伪造的 PackageInfo
段二:调用栈中段(紧挨签名的那几行)
at com.github.unidbg.linux.android.dvm.AbstractJni.callObjectMethodV(AbstractJni.java:743)
at com.github.unidbg.linux.android.dvm.AbstractJni.callObjectMethodV(AbstractJni.java:412)
at com.github.unidbg.linux.android.dvm.DalvikVM64$53.handle(DalvikVM64.java:1024)
这几行告诉你"在 Unidbg 内部走的路径"。重点看最上面那一帧(AbstractJni.callObjectMethodV) — 它直接告诉你应该 override 哪个方法。
不同的 JNI 调用对应不同的 override 入口:
| |
|---|
callObjectMethodV | callObjectMethodV |
callStaticObjectMethodV | callStaticObjectMethodV |
callIntMethodV | callIntMethodV |
callBooleanMethodV | callBooleanMethodV |
getStaticObjectField | getStaticObjectField |
getObjectField | getObjectField |
resolveClass | resolveClass |
记住这个对应表,看到栈顶就知道动手的位置。这是 Unidbg 排错最核心的基本功之一。
段三:调用栈底部(接近 unicorn.Unicorn 那几行)
at com.github.unidbg.linux.ARM64SyscallHandler.hook(ARM64SyscallHandler.java:127)
at com.github.unidbg.arm.backend.UnicornBackend$11.hook(UnicornBackend.java:347)
at unicorn.Unicorn$NewHook.onInterrupt(Unicorn.java:128)
这几行可以完全忽略 — 它们告诉你的是"这个异常是从 SVC 中断回调里抛出来的",但回想第四篇,所有 Unidbg 报错都从那里抛出,所以这一段没有信息量。
新手最常见的错误:看着栈底的 Unicorn.onInterrupt 一筹莫展,以为是 Backend 出了问题。其实那只是"中断分发的固定起点",真正的问题永远在栈顶的那一行 JNI 方法上。
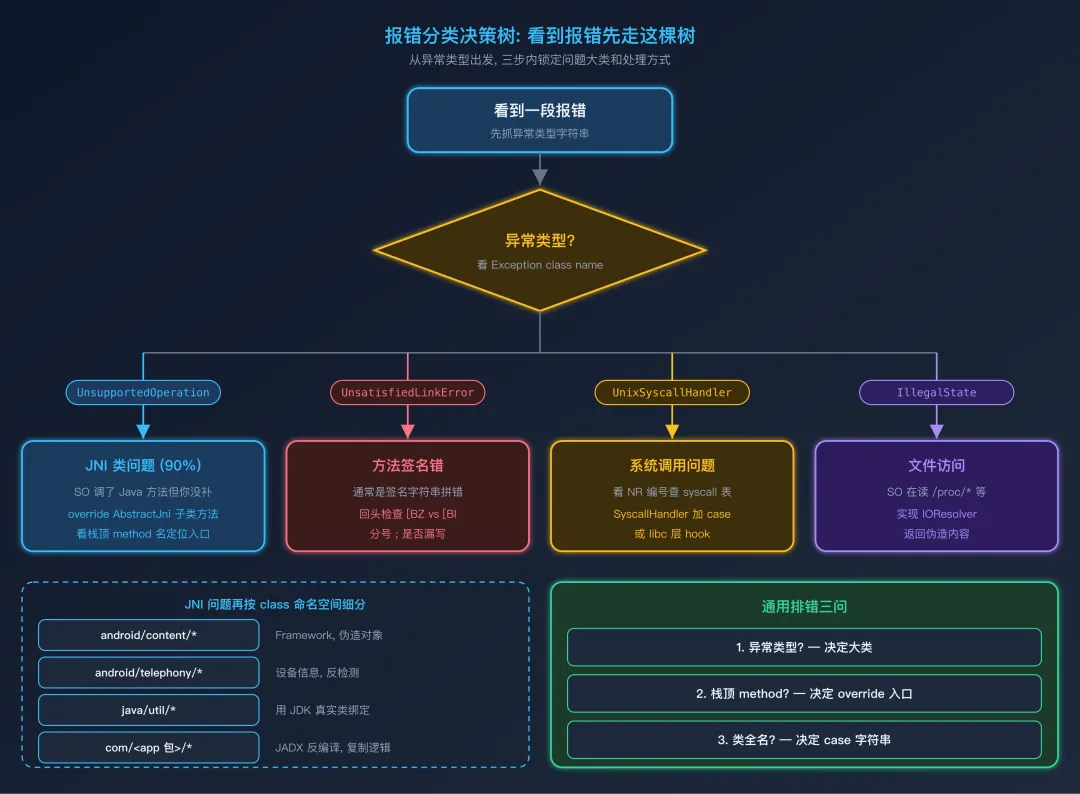
报错分类决策树:判断这是哪一类问题
读懂三段式之后,下一个问题是:这个报错属于哪一类? 因为不同类的报错,处理路径完全不同。
Unidbg 报错的分类决策树决策点 1:异常类型是什么?
java.lang.UnsupportedOperationException: ... → JNI 类问题
java.lang.UnsatisfiedLinkError: ... → 方法签名错或 SO 加载问题
com.github.unidbg.unix.UnixSyscallHandler... → 系统调用类问题
java.lang.IllegalStateException: resolve failed → 文件访问问题
java.lang.IllegalStateException: invalid memory → 内存越界
决策点 2:JNI 类问题里的细分
如果是 UnsupportedOperationException,再看签名所在的类:
| | |
|---|
android/content/... | | 大概率反 ContextManager,需要伪造对象 |
android/telephony/... | | |
java/util/... | | |
java/lang/String | | |
com/<目标 App 包名>/... | | |
决策点 3:syscall 类问题
如果是 syscall 报错(少见但存在),关键看报错里的 NR 或 intno:
syscall NR=387 not implemented → 查 ARM64 syscall 表, NR=387 是 statx
解决方案: 在 SyscallHandler 里加实现, 或者
在 libc 层 hook 包装函数 (之后会讲)
决策点 4:文件访问问题
报错里出现 resolve failed + 文件路径:
IllegalStateException: resolve failed: /proc/self/maps
^^^^^^^^^^^^^
SO 在读这个文件
处理思路:实现一个 IOResolver,对这个路径返回一个伪造的 FileResult(第八篇会展开讲)。
一个实战清单
把这套决策树编成"看到报错先问的三个问题":
- 异常类型是什么?→ 决定大类(JNI / syscall / 文件 / 内存)
- 栈顶的 method 名是什么?→ 决定 override 哪个方法
只要养成"看到报错先答这三个问题"的习惯,90% 的 Unidbg 报错都不再是黑盒。
修第一个洞:override 一个 JNI 方法
回到刚才的 getPackageInfo 报错。按上面的决策树:
- 异常类型:
UnsupportedOperationException → JNI 类 - 栈顶 method:
callObjectMethodV → override 这个 - 签名类全名:
android/content/pm/PackageManager → Android Framework, 需要伪造
动手补:
@Override
public DvmObject<?> callObjectMethodV(BaseVM vm, DvmObject<?> dvmObject, String signature, VaList vaList) {
switch (signature) {
// ===== PackageManager.getPackageInfo (String, int) =====
// SO 通常用这个方法拿包签名 / versionCode / versionName
case"android/content/pm/PackageManager->getPackageInfo(Ljava/lang/String;I)Landroid/content/pm/PackageInfo;": {
String packageName = (String) vaList.getObjectArg(0).getValue();
int flags = vaList.getIntArg(1);
System.out.println("[JNI] getPackageInfo(" + packageName + ", " + flags + ")");
// 返回一个 PackageInfo 的 DvmObject 占位
// 注意: 仅返回对象本身还不够, SO 接下来肯定会读取 packageInfo.signatures 等字段
// 那时会再次报错, 你需要继续 override getObjectField 来响应
return vm.resolveClass("android/content/pm/PackageInfo").newObject(null);
}
}
// 没匹配到的签名, 交还给父类 (会再次抛 UnsupportedOperationException)
returnsuper.callObjectMethodV(vm, dvmObject, signature, vaList);
}
注意这段代码的几个细节:
- 用
switch 结构:每多补一个 JNI 方法就多一个 case。这种风格在样本复杂时会变得很长,但线性可读性比抽象出 Map<String, Function> 更有价值 - 加 println 日志:每次匹配到一个 JNI 调用就打印参数。这会成为你"理解 SO 在做什么"的最重要信息源
- 没匹配到时调用 super:保持父类的报错语义不变 — 这样下一次报错你能立刻知道又有新的 JNI 调用没补
跑一次。getPackageInfo 不再报错了,但很可能立刻冒出下一个报错:
java.lang.UnsupportedOperationException:
android/content/pm/PackageInfo->signatures:[Landroid/content/pm/Signature;
at com.github.unidbg.linux.android.dvm.AbstractJni.getObjectField(...)
正如代码注释里说的,SO 现在要读 packageInfo.signatures 字段。继续补:
@Override
public DvmObject<?> getObjectField(BaseVM vm, DvmObject<?> dvmObject, String signature) {
switch (signature) {
case"android/content/pm/PackageInfo->signatures:[Landroid/content/pm/Signature;": {
// 这是 App 的签名信息, SO 通常用它做完整性校验
// 你需要返回一个 Signature[] 数组, 数组里的每个 Signature 对象包含真实签名 byte
// 真实签名可以从 APK 文件中提取 (apksigner verify --print-certs 拿到)
DvmClass signatureClass = vm.resolveClass("android/content/pm/Signature");
byte[] realSignature = loadRealSignatureFromApk();
DvmObject<?> sig = signatureClass.newObject(realSignature);
return ProxyDvmObject.createObject(vm, new DvmObject<?>[]{sig});
}
}
returnsuper.getObjectField(vm, dvmObject, signature);
}
每次跑、每次报错、每次 case 加一个 — 这就是 Unidbg 工程师最日常的工作循环。
参数传递的统一规则:一张类型映射表
补环境的另一个高频问题是"传参数给 native 函数时类型不对"。这一节给你一张完整的类型映射表 — 所有参数问题都能从这张表里查答案。
| | | |
|---|
boolean | Z | | true |
byte | B | | (byte) 0x12 |
char | C | | 'a' |
short | S | | (short) 100 |
int | I | | 42 |
long | J | | 1700000000L |
float | F | | 3.14f |
double | D | | 3.14 |
String | Ljava/lang/String; | new StringObject(vm, str) | new StringObject(vm, "hello") |
byte[] | [B | new ByteArray(vm, bytes) | new ByteArray(vm, data) |
int[] | [I | new IntArray(vm, ints) | new IntArray(vm, new int[]{1,2,3}) |
| L<类>; | vm.resolveClass(...).newObject(thiz) | |
对象类型的传递示例:
// 假设 native 方法签名是: doSomething(Landroid/content/Context;I)V
// 第一个参数是 Context, 第二个是 int
// 1. 创建一个伪造的 Context 对象
DvmClass contextClass = vm.resolveClass("android/content/Context");
DvmObject<?> contextObj = contextClass.newObject(null);
// 2. 调用函数
module.callStaticJniMethod(emulator, "doSomething(Landroid/content/Context;I)V",
contextObj, // arg1: Context
42// arg2: int
);
**调用时的"包装"和"解包"**:
- 传入参数时:基本类型直传,对象/数组要 包装 成 Unidbg 的
DvmObject / ByteArray 等 - 拿到返回值时:基本类型直接拿,对象/数组拿到的是
DvmObject<?>,需要 .getValue()解包
// 调用返回 String 的方法
DvmObject<?> result = module.callStaticJniMethodObject(emulator, "sign([B)Ljava/lang/String;",
new ByteArray(vm, data));
String signature = (String) result.getValue(); // ← 解包
// 调用返回 byte[] 的方法
DvmObject<?> result = module.callStaticJniMethodObject(emulator, "encrypt([B)[B",
new ByteArray(vm, data));
byte[] encrypted = (byte[]) result.getValue(); // ← 解包
记住一个原则:Unidbg 内部的世界是 DvmObject,外部的世界是 Java 原生类型。所有参数进入 Unidbg 时要包装,所有返回值离开 Unidbg 时要解包。这是边界,也是你和 Unidbg 之间的"翻译层"。
排错的心智模型:节奏比技巧更重要
补了一两个洞之后,你会进入一个节奏:
跑 → 报错 → 看栈顶 → 加 case → 跑 → 报错 → 看栈顶 → 加 case → ...
这个循环可能持续几十次。能不能撑住,取决于你有没有掌握节奏。下面是几个我自己常用的节奏管理原则:
原则 1:一次只修一个洞
最常见的失败模式是"一次性想修五个洞"。报错列出了第一个未实现的 JNI,你顺手把第二、第三个看起来相关的也补上。结果是:跑出新报错时你不知道是哪一个补的有问题。
正确做法:每次只 override 一个方法,跑一次,确认这个洞补上了再补下一个。慢一点,但每一步都是确定的。
原则 2:补的时候打日志,删的时候不要犹豫
每补一个 JNI 方法,加一行 println 打印参数。这会让你在后面看 SO 行为时有"上帝视角"。当某个补的洞已经稳定不再报错,也不要删 println,留着它。
直到最后整段流程跑通、需要做生产化的时候,再统一删除/降级日志(用 if (debug) 包起来即可)。
原则 3:看不懂的方法名先返回 null
有些 JNI 方法名你看了也不知道在干什么(比如混淆过的)。这时不要尝试理解,先 return null 让流程往下走:
case"com/example/obfuscated/aB->c()Ljava/lang/Object;":
System.out.println("[JNI-NULL] " + signature);
returnnull; // 占位返回, 后面再回头分析
返回 null 之后,如果 SO 接下来崩溃了,说明这个返回值很重要 — 你再回头分析。如果 SO 继续往下跑没事,说明这个方法是可以"降级处理"的,你可以一直 return null。这是减少分析量最有效的策略之一。
原则 4:跑通之后立刻验证正确性
"不报错"和"结果正确"是两回事。跑通的瞬间,立刻和阶段 0 用 Frida 抓到的"标准答案"对照:
publicstaticvoidmain(String[] args){
SignDemo demo = new SignDemo();
// 用 Frida 抓到的同一组入参跑
byte[] input = "1700000000:hello world".getBytes();
String unidbgResult = demo.callSign(input, true);
// Frida 跑出来的标准答案 (从你的笔记里复制过来)
String fridaResult = "a3f8e2d1c4b0...";
System.out.println("Unidbg: " + unidbgResult);
System.out.println("Frida: " + fridaResult);
System.out.println("Match: " + unidbgResult.equals(fridaResult));
}
**Match 为 true 才是真正的"跑通"**。如果是 false,说明虽然没报错,但补环境的某个值有问题(往往是某个返回 null 的方法其实需要返回真实值)— 这时你需要回头追查。
总结:第一次跑通的本质
第一次让 SO 在 Unidbg 上跑起来,本质上不是"写代码",而是"和一个未知的 SO 做对话":
- 你能答什么(每个 override 就是你给的一个回答)
这个对话过程没有捷径。但是有节奏 — 一次一个洞、看栈顶、查决策树、补 case、对照验证。掌握这个节奏比记住任何 API 都重要。
如果第一个 SO 跑通时你长出一口气,恭喜你 — 你已经完成了 Unidbg 学习曲线最陡峭的那一段。后面的工作不会变简单,但会变得不再令人不知所措。