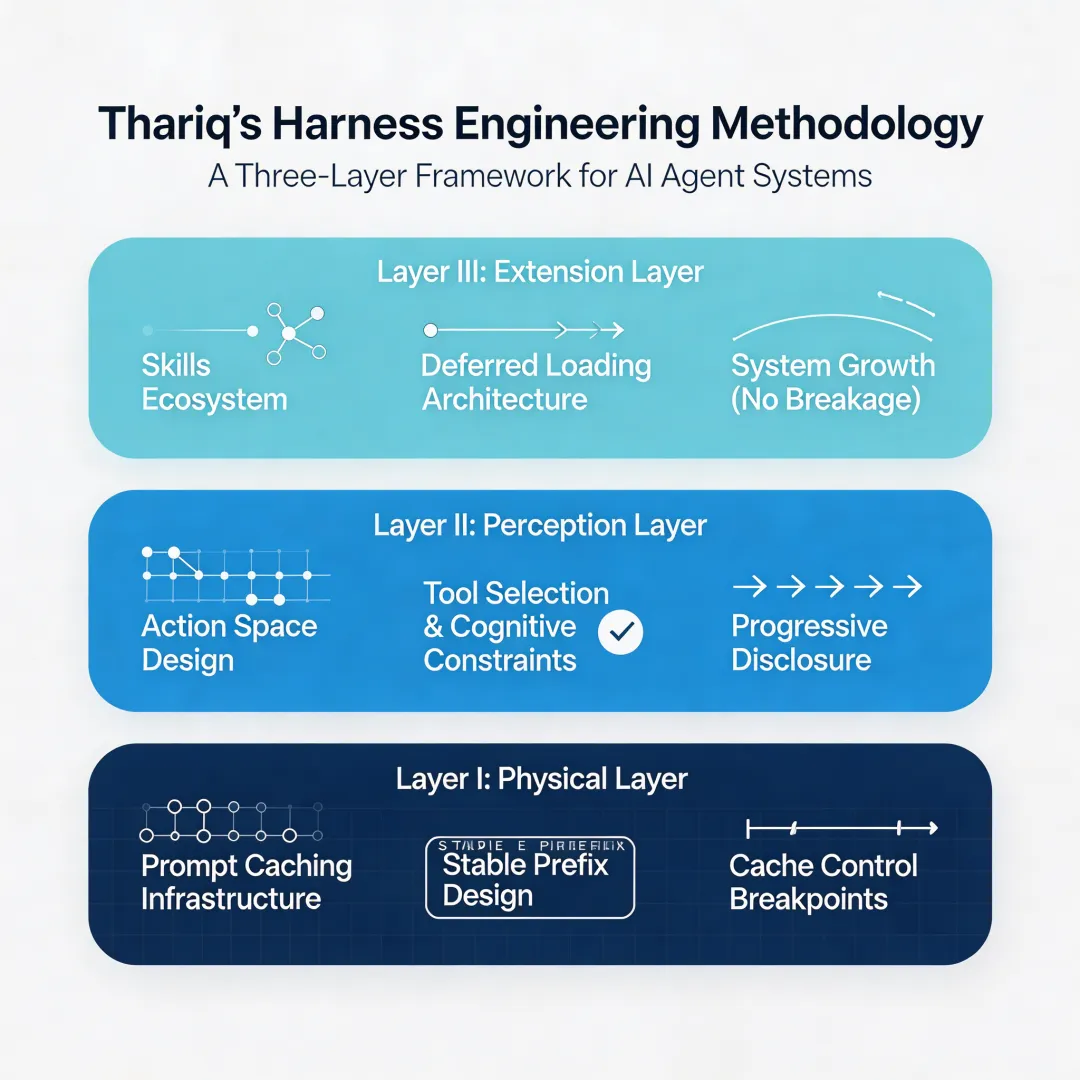
在AI编程助手层出不穷的今天,ClaudeCode凭借其独特的“代理式”交互和强大的上下文理解能力,逐渐成为许多开发者手中的利器。但工具的价值,终究取决于使用它的人。Thariq的“Learning from ClaudeCode”系列三篇文章,恰好提供了一套从“会用”到“用好”的系统性思考。在反复阅读并实践后,我将其中关于工作流优化、提示词技巧以及避坑指南的核心内容,结合自己的体会,整理成了这份笔记。相信无论你是刚开始接触,还是已经重度使用,都能从中获得新的视角。I物理层Prompt Caching Is Everything经济现实:什么使长期 agent 成为可能不理解缓存约束,你构建的所有上层设计都可能在某个时刻无声地崩塌。II感知层Seeing like an Agent行动空间设计:在约束内让 agent 看得见、做得到工具不是越多越好,也不是越少越好——关键在于工具的形状与 agent 的认知结构匹配。III扩展层How We Use Skills能力的生态系统:不破坏前两层的前提下让系统生长Skills 是在不修改 cached prefix、不增加工具集的情况下扩展 agent 能力的机制。
一、Prompt Caching提示缓存
这不是优化,是物理
Thariq提示缓存至关重要。在Claude Code,我们围绕提示缓存构建整个系统……我们根据提示缓存命中率运行警报,如果太低则声明SEVs (在 Claude Code 项目中,提示缓存的命中率不是一个普通的性能指标,而是核心 KPI。如果这个指标下跌,就意味着系统的根基动摇了,因此必须像对待“服务器宕机”那样的严重事故(SEV)一样,放下手头的一切工作去修复它。)
1.1 为什么提示缓存如此重要?
Prompt Caching 的工作机制是 前缀匹配——API 从请求开头开始缓存,直到每个 cache_control 断点。这意味着:你的前缀必须是稳定的、可预测的、在跨会话之间几乎不变的。
在大型语言模型(LLM)的应用中,“提示缓存”是一种优化技术。当多次请求使用相同的上下文前缀(比如系统提示词、超长的文档或代码库)时,缓存可以让第二次及以后的请求速度更快、成本更低(因为不需要重复计算那些相同的部分)。
对于 Claude Code 这种很可能涉及频繁编译、代码补全或代码库理解的场景,如果每次请求都要重新计算整个代码库的上下文,那成本是无法接受的,延迟也会很糟糕。
1.2 围绕提示缓存构建整个系统
这意味着开发者在设计架构时做了这样的假设:
● 假设命中率高: 绝大多数请求都能复用缓存中的内容。
● 基于缓存的交互设计: 很多复杂的逻辑是在缓存命中的前提下设计的,如果不命中,响应时间可能会从 0.5 秒变成 5 秒,甚至因为成本过高而无法运行。
1.3 “命中率太低则声明SEV”—— 这意味着什么?
如果命中率太低,说明假设失效了:
- 成本失控: 大量请求变成了全量计算,可能给公司带来巨大的算力开销(GPU 成本激增)。
- 速度变慢: 用户会感到响应迟钝,产品体验急剧下降。
- 系统过载: 原本设计用来处理增量计算的服务器,突然要处理大量全量计算,可能导致后端服务雪崩
1.4 使用启发- 把“系统指令”或“核心文档”放在最前面
提示缓存通常是前缀匹配的。也就是说,缓存的是对话最开始的那一段内容。
● 启示: 如果你有一些经常要用到的背景信息(比如公司的代码规范、某个库的API文档、项目的架构说明),尽量把它们放在每次对话的固定开头。
● 操作建议: 可以准备一个固定的“提示词模板”,每次开始复杂工作前,先把模板贴进去。这样,即使在不同对话中,只要前缀相同,系统也可能复用缓存(取决于服务端的实现策略)。
二、Seeing like an Agent
工具的形状是认知的外骨骼
"如果给你一道很难的数学题,你想要什么工具?这取决于你自己的技能。纸是最低配置,但你会受到手动计算的限制。计算器会更好,但你需要知道如何操作更高级的选项。最快最强的选项是电脑,但你必须知道如何用它写代码并执行。”
这个类比揭示的是:工具的最优集合不是由任务决定的,而是由 agent 的认知能力决定的。 你需要给它与它的能力形状匹配的工具。问题是:你怎么知道它的能力形状是什么?答案只有一个——观察,实验,读输出,"see like an agent"。
工具数量的悖论。 工具太少,能力受限。工具太多,认知过载——Claude Code 维护约 20 个工具,每增加一个都要认真权衡,因为每个额外的选项都是 agent 在每一步必须考虑的认知负担。Claude Code 当前的工具数量不是历史积累的结果,是持续精简后的答案。
渐进式披露(Progressive Disclosure)解决了这个悖论。 这是第二篇文章里最重要的概念,也是连接第二篇和第三篇的枢纽。如果你不能无限增加工具,但你需要无限扩展能力,怎么办?让 agent 按需发现能力——不是在初始化时把所有东西装进 working memory,而是在需要的时候去读,去找,去组合。
核心洞见: "Seeing like an Agent" 的本质不是同理心练习,是认识论工程:你必须从 agent 的感知视角来设计它的行动空间,而不是从你作为设计者的视角。Agent 看到的是工具定义,是 schema,是被提示召唤的可能性——而不是你认为你告诉了它什么。
三、Skills
在不破坏物理的前提下,让系统长出手脚
第一层:工具集不能中途改变(缓存约束)。第二层:工具集必须精简(认知约束)。第三层回答:那如何在这双重约束下让 harness 的能力持续扩展?
Skills 是这个问题的答案。但理解它需要先破除一个常见误解。Skills 不是 Markdown 文件。 它们是文件夹——包含脚本、模板、数据、配置、甚至动态 hook 的文件夹。这个区别在执行层面是天壤之别。当 Skill 只是文字说明时,agent 需要从头推理所有执行上下文;当 Skill 是一个可探索的文件夹时,agent 可以直接发现它需要的东西。探索的认知负荷远低于推理的认知负荷。
3.1 背景:缓存约束是什么?
之前提到,Claude Code 整个系统围绕提示缓存构建,缓存命中率至关重要。提示缓存通常基于会话前缀:如果每次请求的起始部分(如系统提示词)发生变化,缓存就会失效,需要重新计算,导致成本上升、速度变慢。
因此,系统设计面临一个核心矛盾:既要不断添加新功能(Skills),又要保持系统提示前缀的稳定性,以维持高缓存命中率。
3.2 Skills 的解决思路:渐进式披露
文中的“Skills”可以理解为 AI 的扩展能力模块(例如代码分析、文件操作等)。传统的做法可能是:每安装一个新 Skill,就把该 Skill 的完整指令、示例、逻辑全部塞进系统提示里。但这样一来,系统提示就会越来越长,且每次变化都会导致前缀改变 → 缓存未命中。
而这里描述的 Skills 采用了“渐进式披露”(Progressive Disclosure):
● 安装时仅添加极轻量的“存根”:只在系统提示中增加该 Skill 的名字和一句话描述(可能仅几十个字符)。这意味着系统提示的前缀几乎不变,缓存依然可以命中绝大部分内容。
● 完整内容延迟加载:Skill 的详细指令、脚本、示例等并不预先放在系统提示中,而是保存在外部。只有当 AI 的 Agent 根据上下文决定调用这个 Skill 时,才动态地读取其完整内容(可能通过函数调用、工具调用或即时注入的方式)。
3.3.为什么这种设计有效?
● 对缓存友好:系统提示主体(前缀)保持稳定,缓存可以持续复用。新增 Skill 的微小变动(几十个字符)对缓存的影响可以忽略不计,或者通过巧妙设计(如将 Skill 列表放在提示的末尾)避免破坏前缀匹配。
● 灵活扩展:理论上可以支持成千上万个 Skills,而不会无限膨胀系统提示的长度(因为只有名字和描述在提示里)。这避免了长上下文带来的成本和处理延迟。
● 按需加载:AI 只有在真正需要某个 Skill 时才加载其完整定义,符合“需要时才计算”的原则,节省了每次请求的计算资源。
3.4. 类比理解
这就像浏览器的图片懒加载:网页先加载一个轻量的占位符(名字/描述),只有当用户滚动到图片位置时,才加载高清原图(完整 Skill 内容)。这样初始加载快,缓存友好,用户体验也好。
或者像软件开发的动态链接库:主程序只保留一个函数名(存根),实际代码在运行时按需加载。
3.5. 对使用者的意义
如果你在使用类似 Claude Code 这样深度优化缓存的工具,这个设计意味着:
● 安装更多 Skill 不会拖慢初始响应:因为系统提示几乎没变,缓存依然快。
● Skill 的调用可能会有短暂的首次加载延迟:当第一次调用某个 Skill 时,可能需要加载其完整内容(类似冷启动),但之后同一会话中再次调用就会很快(可能也被缓存了)。
● 你可以放心地安装大量扩展,而不必担心每次对话都要重新处理巨量的提示词。
核心洞见: Skills 不是对工具集的替代,而是工具集的补充——在不破坏 cached prefix 稳定性(物理约束)、不增加工具集认知负担(认知约束)的前提下,通过渐进式披露无限扩展 agent 的领域能力。
综合
三层架构的统一逻辑
现在可以把三层放在一起看了。
大多数人构建 AI 应用的方式是 自上而下 的:我想要 agent 做什么 → 我怎么告诉它 → 技术细节最后再搞。
Thariq 的三篇文章描述的是一种相反的工程哲学:自下而上——先理解物理约束,再在约束内设计认知接口,最后构建扩展生态。
// Thariq 方法论的推演路径// Layer I: 约束确立Caching → 前缀稳定性是第一设计原则→ 工具集一旦确定,会话内不可变→ 动态信息只能通过消息注入// Layer II: 在约束内设计Action Space → 工具必须精简(约 20 个是现实答案)→ 工具形状必须匹配 agent 认知结构→ 渐进式披露 > 一次性上下文爆炸// Layer III: 在约束内扩展Skills → 不修改 cached prefix(不破坏 Layer I)→ 不增加工具集(不破坏 Layer II)→ 通过 deferred loading + 渐进式披露扩展能力
这三层还有一个更深的统一性:它们都是对同一个根本问题的回答——如何在 agent 的认知限制内,实现超越这个限制的系统能力。
Caching 解决的是 agent 无法承担无限计算的问题。Action Space 设计解决的是 agent 无法处理无限选项的问题。Skills 解决的是 agent 无法在单次会话内掌握所有领域知识的问题。这三个问题的本质是同一个:agent 是资源有限的存在,harness engineering 是在这个现实前提下构建无限延伸能力的艺术。
这套哲学有一个自我指涉的美妙之处,Thariq 在 Skills 那篇里隐约提到了:最好的 Skill 是用 agent 来写的;最好的 harness 改进,是用 agent 来分析 agent 的失败而产生的。这不是循环,这是一种自举——让 agent 参与构建容纳自己的结构。
这大概是"以 LLM 的视角让 LLM 自己长出手脚"这件事,在工程层面最诚实的一次表达。
参考文章:
《Prompt Caching Is Everything》
https://x.com/trq212/status/2024574133011673516
https://x.com/trq212/status/2027463795355095314
https://x.com/trq212/status/2033949937936085378