什么是skill
通俗理解,Skill 就是给 AI 的技能说明书,让 AI 在与人类对话交互时可以自行查阅并执行。
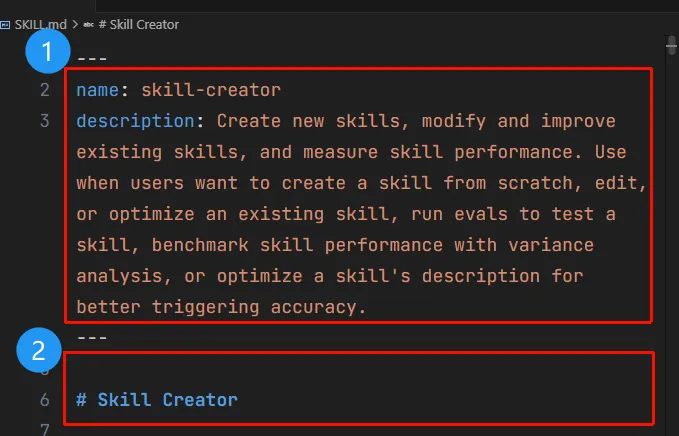
一个 Skill 以文件夹的形式存在,其中必须包含 SKILL.md 这个文件——它就是这个技能的说明书,类似玩游戏时道具栏里的物品说明。 SKILL.md 分为两部分:frontmatter(前置元数据) 和 body(主体)
frontmatter(前置元数据):在官方定义中称为 Metadata 元数据,属于第一层加载。在我们与 AI 交互时,这部分内容每次都会被加载进上下文,供 AI 判断当前任务的意图是否需要调用这个技能。其中 name 是技能名称,description 是技能描述,简短地告诉 AI 在什么情况下应该调用此技能。
body(主体):主体分为两部分——Instructions(说明) 和 Resources and code(资源与代码)。
Instructions(说明):属于第二层加载,当 AI 决定调用这个技能时,这部分内容才会被加载进上下文。Resources and code(资源与代码):属于第三层加载,非必需。当 AI 在 Instructions 中发现提及了某个资源文件名时,会直接调用 shell 执行对应脚本,而不会将代码本身加载进上下文。这些资源文件需要与 SKILL.md 放在同一文件夹下,AI 执行该 Skill 时会优先在此目录中查找对应脚本。
这三层加载机制,可以学一个比较”高大上“的词——渐进式披露(Progressive Disclosure)。 意思是:信息不会在一开始就全部塞进上下文,而是随着任务的推进,按需、分阶段地逐层展开。
对应到 Skill 的三层结构就是:
- 第一层(frontmatter):每次对话都加载,只披露最轻量的元信息,够 AI 判断"要不要用这个技能"即可
- 第二层(Instructions):决定调用后才加载,披露具体的操作说明
- 第三层(Resources & Code):执行过程中按需加载,只在真正用到某个资源时才调取,甚至不进入上下文,直接 shell 执行
这样设计的原因是:上下文窗口是有限资源。如果每个 Skill 的所有内容都在对话开始时全量加载,多个 Skill 叠加很快就会撑满。渐进式披露让 AI 像翻阅一本书一样,先看目录决定要不要读这章,再翻开正文,最后才去附录查资料——而不是把整本书一次性摊开在桌上。
| | | |
|---|
| | | YAML 前导块的 name 和 description |
| | | |
| | | 捆绑文件通过 bash 执行,无需将内容加载到上下文中 |
复杂skill结构
claude官方推出的skill中,有一个叫做 skill-creator,无需自己写skill,利用它可以让 AI 帮你生成技能。
在这个技能详情,定义了一个复杂的skill的结构
skill-name/├── SKILL.md 必需│ ├── YAML 头信息(name、description 必需)│ └── Markdown 指令└── 捆绑资源(可选) ├── scripts/ 确定性/重复性任务的可执行代码 ├── references/ 需要时加载进上下文的文档 └── assets/ 输出用到的文件(模板、图标、字体)
scripts/ — 预先写好的脚本,AI 判断需要时直接调用 shell 执行。适合那些结果必须精确、不能让 AI 自由发挥的操作——因为 AI 每次自己生成代码并不稳定,可能这次成功,下次就是失败,但是用固定脚本兜底结果会更可靠。references/ — AI 执行时按需查阅的参考文档,会被读入上下文。 比如公司数据表的字段说明、API 文档等。 比如某一环节需要调用 nano-banana 生图模型, 可以把 nano-banana 的 API 文档规范放在 references/nano-banana-api.md 里, AI 需要构造请求时再去读它,而不是把整份文档一开始就塞进上下文。assets/ — 直接用于最终产出的静态文件,AI 不需要读懂,只负责在合适的时机把它放进输出里。比如让他执行完写作skill之后,产出一个编辑好样式的md文件,这个样式模板就可以放这个文件夹下面
一句话区分三者:scripts 是让 AI 跑的,references 是让 AI 读的,assets 是让 AI 搬的。
Skill 的核心优势
CC的skill本质源于之前提到的设计原则——渐进式披露,文件不使用就不占上下文,按需加载:
- 按需读取:Skill 可以包含几十个 references 文件,但 AI 只加载当前任务用到的那一个,其余文件零 token 消耗
- 脚本只看结果:AI 执行
scripts/ 里的脚本时,代码本身不进上下文,只有输出结果(比如"验证通过")才占 token,比让 AI 临时写代码高效得多 - 资源体积没有上限:放多少 API 文档、数据集、示例都不影响性能,用不到的内容不产生任何代价
skill运行逻辑和获取
自动调用:AI 对话时会扫描已安装 skill 的 frontmatter,通过 description 判断是否需要触发。安装的 skill 越多,每次对话的固定 token 开销就越高。
手动调用:通过 /技能名 命令直接触发,省去 AI 的意图识别。
获取渠道:官方仓库 github.com/anthropics/skills 涵盖了大多数常用场景,够用。
在 Claude Code 里:将 skill 文件夹放入项目的 .claude/skills/ 目录即可生效在 Claude.ai 里:进入 Settings → Features,上传 skill 的 zip 压缩包(需要 Pro 及以上套餐)心得
说白了,skill 适合机械重复类的任务,前期定义好流程,后面就能甩手交给 AI 跑。但现实是,我们日常真正高频重复的场景并没有那么多——有人装了 200 个 skill,实际用上的可能也就十几个,其余的除了每次对话白白消耗 token,就像收藏夹里吃灰的文章,躺着没人理。
所以 skill 的价值不在于装得多,而在于打磨得精。一个真正贴合自己工作流的 skill,前期多花时间雕琢,后面省下来的时间会成倍还回来。