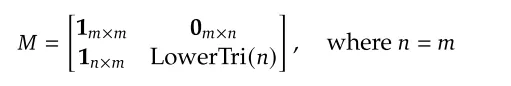1. 写在前面
我们知道,传统视觉语言模型(Vision Language Model, VLM)在将视觉信息输入到大语言模型(Large Language Model, LLM)时,通常会按照固定的块(patch)大小,遵循严格的光栅扫描顺序(即从上到下、从左到右)处理视觉token,并对其进行固定位置编码。对于希望深入了解该部分内容的同学,可参考ViT(Vision Transformer)论文中关于图像分块、视觉token生成流程及位置编码方式的详细阐述。
但这种处理方式与人类视觉的自然感知机制存在显著差异,尤其针对具有复杂布局的图像时,这种差异更为突出。人类视觉遵循由语义理解引导的因果驱动流,后一次的注视焦点往往依赖于前一次的注视结果,高度依托视觉语义信息,而非单纯的空间坐标位置。
不妨试想这样一种场景:当我们查看一张包含文字的图片,尤其是布局复杂、包含大量公式与表格的文档图像时,并不会机械地遵循光栅扫描顺序进行浏览。相反,我们通常会先聚焦于自身感兴趣的内容,再顺着该内容的因果逻辑的延伸,逐步拓展阅读这条因果链条上的其他部分——这正是人类视觉感知的核心特点。
受人类这种认知机制的启发,重新审视视觉语言模型(尤其是编码器部分)的架构设计就显得尤为必要。究其原因,LLM的训练本质上基于一维(1D)数据,而图像属于二维(2D)结构,若强行以预定义的光栅扫描顺序处理二维图像的视觉信息,势必会引入不必要的归纳偏置,同时忽略图像内部蕴含的关键语义关联,进而影响模型的理解效果。
为解决这一核心问题,在DeepSeek-OCR相关工作的基础上,DeepSeek团队提出了DeepSeek-OCR2,其核心就是DeepSeek Encoder V2架构。该架构赋予了编码器(Encoder)强大的因果推理能力,使其视觉Token能够按照内容的因果关系进行重排。这种重排后的视觉Token,更契合解码器自回归的理解逻辑,从而有效提升了模型处理复杂图像的准确性。
2. 模型架构
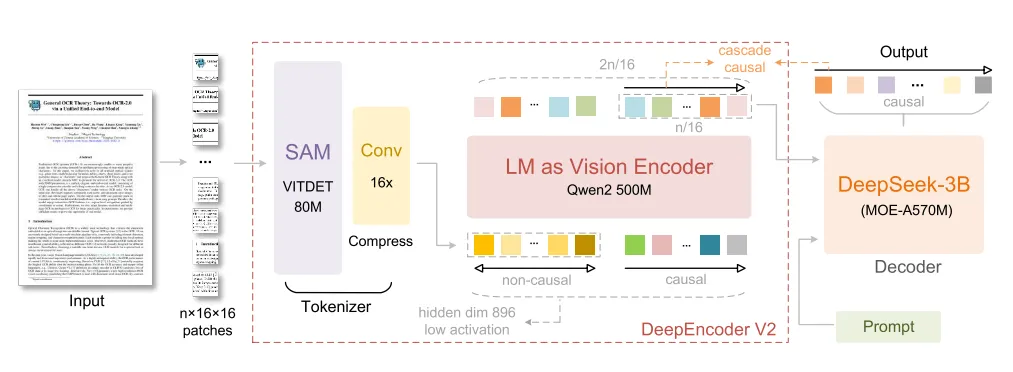
首先来看DeepSeek-OCR2的整体模型架构:
DeepSeek-OCR 2采用编码器-解码器架构,核心创新在于全新设计的DeepEncoder V2编码器,结合MoE解码器实现高效视觉因果流建模。以下是具体架构解析:
2.1 整体架构
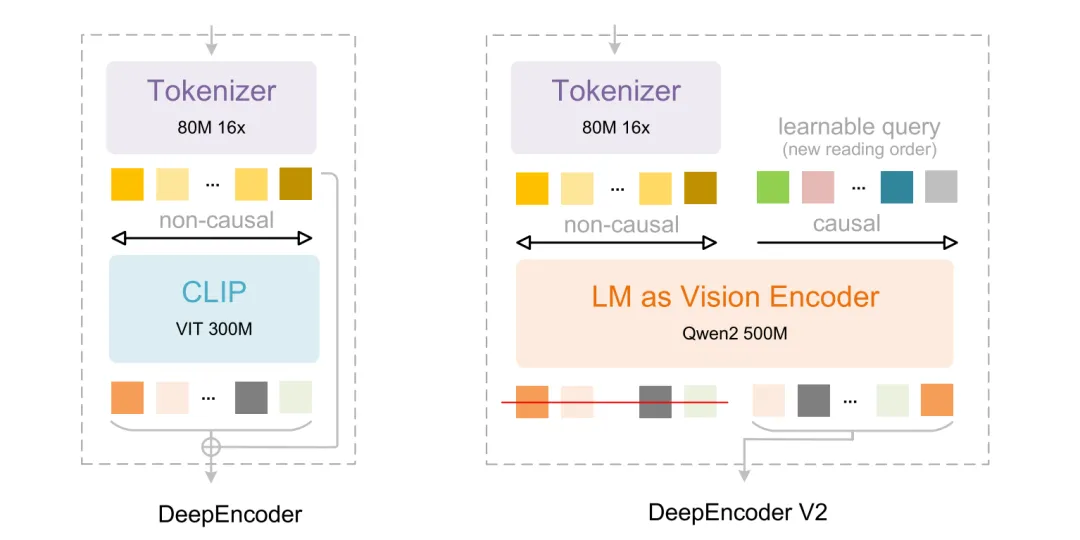
2.2 DeepEncoder V2 核心设计
如上图所示,这里是DeepSeek-OCR2最核心的部分。从DeepEncoder到DeepEncoder V2,核心变化在于用LLM架构取代了CLIP组件,以实现视觉因果流。同时,引入可学习的Query作为因果流token,并以视觉token作为前缀,通过定制的注意力mask,维持视觉token的全局感受野,而因果流token则可以获得视觉token的重排序能力。最终只有因果流token输送到解码器,从而实现因果感知的视觉理解。
2.1.1 视觉 Tokenizer
功能:将图像压缩为视觉 tokens,保留全局语义信息。
架构:采用 80M 参数的 SAM-base 模型 + 2 个卷积层,输出维度从 1024 降至 896,与后续 LLM 编码器对齐。
优势:通过窗口注意力实现 16× token 压缩,降低计算成本和激活内存。
2.2.2 语言模型作为视觉编码器(LM as Vision Encoder)
2.2.3 因果流查询(Causal Flow Query)
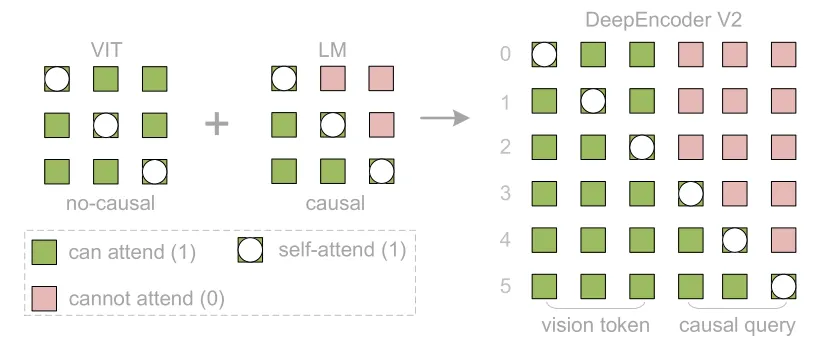
2.2.4 注意力掩码(Attention Mask)
其中 m 为视觉 tokens 数,n 为查询 tokens 数( n = m )。
2.3 解码器(DeepSeek-MoE Decoder)
2.4 核心创新与优势
1. 视觉因果流建模:通过因果查询 tokens 动态重排序视觉信息,模拟人类语义驱动的阅读顺序,突破传统光栅扫描的局限。
2. 高效压缩:视觉 tokens 数量控制在 256-1120,低于 Gemini-3 Pro 的 1120,平衡性能与效率。
3. 统一模态潜力:LLM 风格编码器可通过模态特定查询扩展至音频、文本等,迈向通用多模态编码。
3. 核心概念深入理解
3.1 视觉因果流
3.1.1 什么是视觉因果流?
视觉因果流(Visual Causal Flow)指的是:视觉编码器内部对序列做 “前一半非因果 + 后一半因果” 的注意力,并且只取后半段(因果部分)的输出作为图像的表示。在代码里对应 CustomQwen2Decoder + Qwen2Decoder2Encoder:
输入序列 Concat:[图像 patch 特征 | 可学习 Query 特征],对应 token_type_ids:前半为 0(非因果),后半为 1(因果)。
注意力规则(_create_custom_4d_mask):
输出:只取后半段(query 位置)的表示,即 “causal flow query”。
所以,视觉因果流说的就是图像采用非因果的方式编码成 token 表示,然后再和一组采用因果编码的 query 表示拼接在一起,送入自回归编码器模型进行注意力计算,最后只输出因果表示的部分。
Qwen2Decoder2Encoder forward中代码流程:
def forward(self, x: torch.Tensor) -> torch.Tensor: x = x.flatten(2).transpose(1, 2) bs, n_query, _ = x.shape if n_query == 144: param_img = self.query_768.weight elif n_query == 256: param_img = self.query_1024.weight batch_query_imgs = param_img.unsqueeze(0).expand( bs, -1, -1 ) # (batch_size, num_queries, hidden_size) x_combined = torch.cat([x, batch_query_imgs], dim=1) token_type_ids = torch.cat([ torch.zeros(bs, n_query, dtype=torch.long), torch.ones(bs, n_query, dtype=torch.long), ], dim=1) y = self.model(x_combined, token_type_ids)[0] y = y[:, n_query:, :] # causal flow query return y
3.1.2 为什么要提出视觉因果流?
主要有如下三点原因:
和语言模型一致:下游是因果语言模型(decoder-only),视觉编码也采用“因果读出”,接口和训练更统一,减少“双向视觉 + 单向语言”的不一致。
更贴近“顺序阅读”:用因果的 query 按顺序从图像里抽取信息,而不是一次性全图双向读取。
实现上:用 非因果(图像内部) + 因果(query) 的混合注意力,既保留图像内部全局关系,又让视觉表示以因果方式流出,便于和 LLM 的因果生成对齐。
3.2 可学习 Query
3.2.1 什么是可学习 Query?
可学习 Query 是一组与分辨率绑定的、不依赖图像内容的可学习 Embedding 向量,用来从视觉 Token 表示中按照因果方式“读出”视觉信息:
self.query_768 = nn.Embedding(144, hidden_dimension)self.query_1024 = nn.Embedding(256, hidden_dimension)
前向推理时:
将 图像 patch 的特征 与 可学习 query 的 embedding 在序列维度拼接:x_combined = [x | batch_query_imgs]。
前半段是图像(非因果),后半段是 query(因果);encoder 只输出后半段:y = y[:, n_query:, :]。
可学习 Query 通过因果注意力从图像中聚合信息,得到固定长度的视觉表示(144 或 256 个向量)。
3.2.2 可学习 Query 是如何对视觉 token 进行重排序的?
这里需要澄清一点,论文里说的「重排序」并不是说把视觉 token 的物理顺序打乱再排一遍,而是:用一组可学习的 query 通过 attention 从视觉 token 里“按学习到的规则”抽取信息,得到一个新的、固定长度的序列。可以理解为「按语义/任务重新组织视觉信息」。对应到代码:
输入:x 是 patch 特征,形状 (B, n_query, C),对应 2D 网格的展平顺序(如 12×12→144 或 16×16→256),即“空间顺序”。
拼接:x_combined = [x | batch_query_imgs],前半是 视觉 token(空间顺序),后半是 可学习 query embedding(固定 144/256 个向量)。
注意力:在 CustomQwen2Decoder 里,前半非因果、后半因果;每个 query 位置都可以 attend to 所有视觉 token(以及前面的 query)。
输出:只取应该 query 的后半段
y = y[:, n_query:, :]即得到 144/256 个向量,顺序是 query 的位置顺序(1, 2, …, 144/256)。因此:
“重排序” = 从「按空间排列的 patch 序列」变成「按 query 位置排列的 144/256 个向量」。
每个位置的内容 = 该 query 对所有视觉 token 做 attention 的加权和;权重是 attention 动态算出来的,所以同一张图里“谁重要”是由模型学出来的。
不同 query 位置可以学到关注不同区域/不同语义(例如有的偏全局、有的偏某一行),所以这 144/256 个向量相当于按“学习到的语义/任务顺序”重新组织了视觉信息,这就是论文里说的“对视觉 token 进行重排序”在实现上的含义。
3.2.3 Query 是怎么学习的?
query_768 = nn.Embedding(144, hidden_dimension)、query_1024 = nn.Embedding(256, hidden_dimension)学的是 144/256 个固定的向量(embedding 的 weight),不随输入图像变化。
整个模型(SAM → Qwen2Decoder2Encoder → projector → LLM)端到端训练,损失是语言模型 loss(如 next-token prediction)。梯度路径:LLM loss → projector → Qwen2Decoder2Encoder 的输出 y[:, n_query:, :] → CustomQwen2Decoder 里的 attention。
所以梯度会反传到 query embedding 的参与部分:每个 query 位置的向量会根据“我这样参与 attention,能否让后面的 LLM 预测得更好”被更新。
也就是说:学习的是“每个槽位(query 位置)该怎么从视觉 token 里抽取、重组信息”,而不是为每张图单独生成一套新 query。所以:Query 是在训练时通过端到端梯度学出来的;推理时用的就是这套已经学好的 144/256 个向量。
3.2.4 推理时固定的 query embedding 如何对不同图像生效?
3.2.5 总结
→ projector → LLM → loss
所以:“可学习查询对视觉 token 重排序”= 用固定的、学习好的 query 槽位,通过 attention 从当前图像的视觉 token 中按学习到的规则抽取并重组成 144/256 的语义顺序;Query 在训练时通过端到端 loss 学习,推理时参数固定,但重排序的结果随每张图的内容变化。、
3.3 统一模态
统一模态指通过共享LLM架构实现跨模态特征编码的技术路径。其核心是将图像、音频、文本等不同模态输入,通过模态专属的可学习查询(modality-specific learnable queries)映射到同一语义空间,实现参数共享与统一建模。
该机制包含三个关键要素:
模态适配层:为每种模态设计专用特征提取器(如视觉用CNN/ViT、音频用梅尔频谱+卷积),输出原始模态特征
查询驱动编码:为各模态训练独立的查询向量(如视觉查询、音频查询),通过交叉注意力从原始特征中提取模态关键信息
统一Transformer主干:采用共享的Transformer编码器处理不同模态的查询-特征对,利用自注意力实现模态内/模态间关系建模
与传统多模态架构相比,其优势在于:
参数效率:避免为每种模态设计独立编码器,通过查询向量差异化适配不同模态
语义对齐:统一向量空间天然支持跨模态检索与生成任务
扩展灵活性:新增模态仅需训练对应查询向量,无需重构主干网络
潜在挑战包括模态差异带来的特征对齐难度,以及如何设计查询学习机制以捕获模态独特属性。该方向代表了从"模态专用架构"向"通用智能体"演进的重要探索。
4. 总结
DeepSeek-OCR 2 通过 DeepEncoder V2 的双向+因果注意力融合和动态 token 排序,实现了更接近人类视觉认知的文档理解,在保持高压缩率的同时,在 OmniDocBench 上实现 3.73% 的整体性能提升,尤其优化了复杂布局的阅读顺序推理。
但DeepSeek-OCR 2的核心意义,并非局限于OCR任务精度的提升,更在于其提出了一种新颖的架构设计——基于LLM的编码器与基于LLM的解码器级联结构。这两个一维(1D)因果推理组件的级联,为实现真正意义上的二维(2D)推理提供了可行路径:编码器通过Query对视觉信息进行因果重排,解码器则利用重排后的视觉Token执行具体的视觉任务推理。
更为重要的是,该架构具备演进为统一全模态编码器的巨大潜力。其核心逻辑在于,不同模态的任务可采用专属的Query,而Wk、Wv投影层以及注意力机制、FFN(前馈网络)等核心模块则可实现参数共享。基于这一设计,通过模态专属的可学习Query,编码器能够同时完成文本压缩、语音特征提取,并在相同的参数空间内重新组织多模态内容。
DeepSeek-OCR对光学字符的压缩处理,标志着对原生多模态任务的初步探索,同时也是提升大模型上下文token效率的有效手段——毕竟“一图胜千言”,高效的视觉token压缩能极大缓解大模型上下文窗口的压力。
而DeepSeek-OCR 2所采用的基于LLM的编码器架构,进一步推动了多模态融合与上下文token压缩技术的发展。这种基于共享编码器的框架与其他模态的集成将产生怎样的创新突破,值得我们后续持续关注与探索。
5. 参考
https://github.com/deepseek-ai/DeepSeek-OCR-2
https://huggingface.co/deepseek-ai/DeepSeek-OCR-2