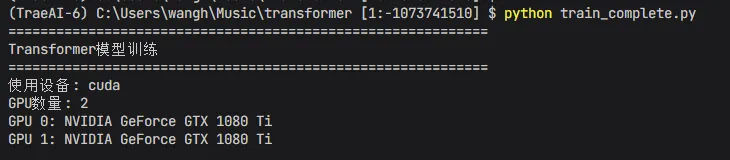
# -*- coding: utf-8 -*-"""完整训练脚本 - 包含BPE分词器、Transformer模型和训练循环"""import torch # 导入PyTorch深度学习框架import torch.nn as nn # 导入PyTorch神经网络模块import torch.optim as optim # 导入PyTorch优化器模块from torch.utils.data import Dataset, DataLoader # 导入数据集和数据加载器import os # 导入操作系统接口模块import time # 导入时间模块import math # 导入数学函数模块from collections import Counter # 导入计数器工具import pickle # 导入序列化模块import json # 导入JSON处理模块from tqdm import tqdm # 导入进度条工具class BPETokenizer: """BPE分词器""" def __init__(self, vocab_size=5000): # 初始化分词器,设置词表大小 self.vocab_size = vocab_size # 保存词表大小 self.vocab = {} # 创建词汇表字典(token到ID) self.inv_vocab = {} # 创建反向词汇表字典(ID到token) self.merges = [] # 创建合并规则列表 self.special_tokens = ['<PAD>', '<SOS>', '<EOS>', '<UNK>'] # 定义特殊标记 for i, token in enumerate(self.special_tokens): # 遍历特殊标记 self.vocab[token] = i # 将特殊标记添加到词汇表 self.inv_vocab[i] = token # 将ID映射到特殊标记 def get_vocab_size(self): # 获取词表大小的方法 return len(self.vocab) # 返回词汇表长度 def train(self, texts, verbose=True): # 训练BPE分词器的方法 if verbose: # 如果需要显示详细信息 print("开始训练BPE分词器...") # 打印训练开始信息 word_freqs = Counter() # 创建词频计数器 for text in tqdm(texts, desc="统计字符频率", disable=not verbose): # 遍历所有文本 words = text.split() # 分割文本为单词 for word in words: # 遍历每个单词 word_freqs[word + '</w>'] += 1 # 统计单词频率 vocab = set() # 创建词汇集合 for word in word_freqs: # 遍历所有单词 for char in word: # 遍历单词中的字符 vocab.add(char) # 将字符添加到词汇集合 for token in self.special_tokens: # 遍历特殊标记 vocab.add(token) # 将特殊标记添加到词汇集合 for i, token in enumerate(self.special_tokens): # 遍历特殊标记 self.vocab[token] = i # 将特殊标记映射到ID self.inv_vocab[i] = token # 将ID映射到特殊标记 idx = len(self.special_tokens) # 设置起始索引 for char in sorted(vocab): # 遍历排序后的字符 if char not in self.special_tokens: # 如果不是特殊标记 self.vocab[char] = idx # 将字符映射到ID self.inv_vocab[idx] = char # 将ID映射到字符 idx += 1 # 索引递增 num_merges = self.vocab_size - len(self.vocab) # 计算需要合并的次数 if verbose: # 如果需要显示详细信息 print(f"需要合并 {num_merges} 次") # 打印合并次数 for i in range(num_merges): # 执行合并循环 pairs = Counter() # 创建符号对计数器 for word, freq in word_freqs.items(): # 遍历词频字典 symbols = word.split() # 将单词分割为符号 for j in range(len(symbols) - 1): # 遍历相邻符号对 pairs[(symbols[j], symbols[j+1])] += freq # 统计符号对频率 if not pairs: # 如果没有符号对 break # 退出循环 best_pair = max(pairs, key=pairs.get) # 找到最高频的符号对 new_symbol = best_pair[0] + best_pair[1] # 合并符号对 self.merges.append(best_pair) # 保存合并规则 if new_symbol not in self.vocab: # 如果新符号不在词汇表中 self.vocab[new_symbol] = idx # 添加新符号到词汇表 self.inv_vocab[idx] = new_symbol # 添加反向映射 idx += 1 # 索引递增 new_word_freqs = {} # 创建新词频字典 for word, freq in word_freqs.items(): # 遍历旧词频字典 new_word = word.replace(' '.join(best_pair), new_symbol) # 应用合并规则 new_word_freqs[new_word] = freq # 保存新词频 word_freqs = new_word_freqs # 更新词频字典 if verbose and (i + 1) % 500 == 0: # 每500次合并打印一次 print(f"合并 {i+1}/{num_merges}: {best_pair} -> {new_symbol}") # 打印合并信息 if verbose: # 如果需要显示详细信息 print(f"BPE分词器训练完成,词表大小: {len(self.vocab)}") # 打印完成信息 def encode(self, text): # 编码文本的方法 words = text.split() # 分割文本为单词 encoded = [] # 创建编码结果列表 for word in words: # 遍历每个单词 word += '</w>' # 添加词尾标记 symbols = list(word) # 将单词转换为符号列表 while len(symbols) > 1: # 当符号数量大于1时 merged = False # 设置合并标志 for pair in self.merges: # 遍历合并规则 for i in range(len(symbols) - 1): # 遍历符号位置 if symbols[i] == pair[0] and symbols[i+1] == pair[1]: # 如果匹配符号对 symbols[i:i+2] = [pair[0] + pair[1]] # 合并符号对 merged = True # 设置合并标志 break # 退出内层循环 if merged: # 如果已合并 break # 退出外层循环 if not merged: # 如果没有合并 break # 退出循环 for symbol in symbols: # 遍历符号 if symbol in self.vocab: # 如果符号在词汇表中 encoded.append(self.vocab[symbol]) # 添加ID到编码结果 else: # 如果符号不在词汇表中 encoded.append(self.vocab['<UNK>']) # 添加未知标记ID return encoded # 返回编码结果 def decode(self, ids): # 解码ID序列的方法 text = [] # 创建解码结果列表 for idx in ids: # 遍历ID序列 if idx in self.inv_vocab: # 如果ID在反向词汇表中 token = self.inv_vocab[idx] # 获取对应的token if token not in self.special_tokens: # 如果不是特殊标记 text.append(token.replace('</w>', ' ')) # 添加解码文本 return ''.join(text) # 返回解码结果 def save(self, filepath): # 保存分词器的方法 with open(filepath, 'wb') as f: # 以二进制写模式打开文件 pickle.dump({ # 序列化分词器数据 'vocab': self.vocab, # 保存词汇表 'inv_vocab': self.inv_vocab, # 保存反向词汇表 'merges': self.merges, # 保存合并规则 'vocab_size': self.vocab_size # 保存词表大小 }, f) # 写入文件 def load(self, filepath): # 加载分词器的方法 with open(filepath, 'rb') as f: # 以二进制读模式打开文件 data = pickle.load(f) # 反序列化分词器数据 self.vocab = data['vocab'] # 加载词汇表 self.inv_vocab = data['inv_vocab'] # 加载反向词汇表 self.merges = data['merges'] # 加载合并规则 self.vocab_size = data['vocab_size'] # 加载词表大小 return self # 返回分词器实例class MultiHeadAttention(nn.Module): # 多头注意力机制类 """多头注意力机制""" def __init__(self, d_model, num_heads): # 初始化方法 super().__init__() # 调用父类初始化 self.d_model = d_model # 保存模型维度 self.num_heads = num_heads # 保存注意力头数 self.d_k = d_model // num_heads # 计算每个头的维度 self.W_q = nn.Linear(d_model, d_model) # 创建查询权重矩阵 self.W_k = nn.Linear(d_model, d_model) # 创建键权重矩阵 self.W_v = nn.Linear(d_model, d_model) # 创建值权重矩阵 self.W_o = nn.Linear(d_model, d_model) # 创建输出权重矩阵 def forward(self, query, key, value, mask=None): # 前向传播方法 batch_size = query.size(0) # 获取批次大小 Q = self.W_q(query) # 计算查询向量 K = self.W_k(key) # 计算键向量 V = self.W_v(value) # 计算值向量 Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # 重塑并转置查询向量 K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # 重塑并转置键向量 V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) # 重塑并转置值向量 scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5) # 计算注意力分数 if mask is not None: # 如果有掩码 scores = scores.masked_fill(mask == 0, -1e9) # 应用掩码 attention_weights = torch.softmax(scores, dim=-1) # 计算注意力权重 output = torch.matmul(attention_weights, V) # 加权求和 output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # 合并多头 output = self.W_o(output) # 输出变换 return output, attention_weights # 返回输出和注意力权重class FeedForward(nn.Module): # 前馈神经网络类 """前馈神经网络""" def __init__(self, d_model, d_ff, dropout=0.1): # 初始化方法 super().__init__() # 调用父类初始化 self.linear1 = nn.Linear(d_model, d_ff) # 创建第一线性层 self.linear2 = nn.Linear(d_ff, d_model) # 创建第二线性层 self.dropout = nn.Dropout(dropout) # 创建Dropout层 self.relu = nn.ReLU() # 创建ReLU激活函数 def forward(self, x): # 前向传播方法 x = self.linear1(x) # 第一线性变换 x = self.relu(x) # ReLU激活 x = self.dropout(x) # Dropout正则化 x = self.linear2(x) # 第二线性变换 return x # 返回输出class TransformerBlock(nn.Module): # Transformer块类 """Transformer块""" def __init__(self, d_model, num_heads, d_ff, dropout=0.1): # 初始化方法 super().__init__() # 调用父类初始化 self.attention = MultiHeadAttention(d_model, num_heads) # 创建多头注意力层 self.norm1 = nn.LayerNorm(d_model) # 创建第一层归一化 self.norm2 = nn.LayerNorm(d_model) # 创建第二层归一化 self.feed_forward = FeedForward(d_model, d_ff, dropout) # 创建前馈网络 self.dropout = nn.Dropout(dropout) # 创建Dropout层 def forward(self, x, mask=None): # 前向传播方法 attn_output, _ = self.attention(x, x, x, mask) # 自注意力计算 x = self.norm1(x + self.dropout(attn_output)) # 残差连接和层归一化 ff_output = self.feed_forward(x) # 前馈网络计算 x = self.norm2(x + self.dropout(ff_output)) # 残差连接和层归一化 return x # 返回输出class PositionalEncoding(nn.Module): # 位置编码类 """位置编码""" def __init__(self, d_model, max_len=5000): # 初始化方法 super().__init__() # 调用父类初始化 pe = torch.zeros(max_len, d_model) # 创建位置编码矩阵 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 创建位置索引 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 计算分母项 pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置用sin pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置用cos self.register_buffer('pe', pe.unsqueeze(0)) # 注册为缓冲区 def forward(self, x): # 前向传播方法 return x + self.pe[:, :x.size(1), :] # 添加位置编码class Transformer(nn.Module): # Transformer模型类 """Transformer模型""" def __init__(self, vocab_size, d_model=512, num_heads=8, num_layers=6, d_ff=2048, max_len=512, dropout=0.1): # 初始化方法 super().__init__() # 调用父类初始化 self.d_model = d_model # 保存模型维度 self.embedding = nn.Embedding(vocab_size, d_model) # 创建词嵌入层 self.pos_encoding = PositionalEncoding(d_model, max_len) # 创建位置编码层 self.transformer_blocks = nn.ModuleList([ # 创建Transformer块列表 TransformerBlock(d_model, num_heads, d_ff, dropout) # 创建单个Transformer块 for _ in range(num_layers) # 创建多个Transformer块 ]) self.fc = nn.Linear(d_model, vocab_size) # 创建输出全连接层 self.dropout = nn.Dropout(dropout) # 创建Dropout层 def forward(self, x, mask=None): # 前向传播方法 x = self.embedding(x) # 词嵌入 x = self.pos_encoding(x) # 添加位置编码 x = self.dropout(x) # Dropout正则化 for block in self.transformer_blocks: # 遍历Transformer块 x = block(x, mask) # 通过Transformer块 output = self.fc(x) # 输出变换 return output, None # 返回输出class TextDataset(Dataset): # 文本数据集类 """文本数据集""" def __init__(self, data, seq_len): # 初始化方法 self.data = data # 保存数据 self.seq_len = seq_len # 保存序列长度 self.all_tokens = [] # 创建所有token列表 for seq in data: # 遍历数据序列 self.all_tokens.extend(seq) # 拼接所有token self.num_samples = max(0, len(self.all_tokens) - seq_len) # 计算样本数量 def __len__(self): # 获取数据集长度 return self.num_samples # 返回样本数量 def __getitem__(self, idx): # 获取单个样本 x = self.all_tokens[idx:idx + self.seq_len] # 获取输入序列 y = self.all_tokens[idx + 1:idx + 1 + self.seq_len] # 获取目标序列 return torch.LongTensor(x), torch.LongTensor(y) # 返回张量对def load_and_encode_data(file_paths, tokenizer, max_lines_per_file=None): # 加载并编码数据的函数 all_lines = [] # 创建所有行列表 for file_path in file_paths: # 遍历文件路径 if os.path.exists(file_path): # 如果文件存在 print(f"加载文件: {file_path}") # 打印文件名 with open(file_path, 'r', encoding='utf-8') as f: # 打开文件 lines = [line.strip() for line in f.readlines() if line.strip()] # 读取并清理行 if max_lines_per_file is not None: # 如果限制了每个文件的行数 lines = lines[:max_lines_per_file] # 每个文件截取前N行 all_lines.extend(lines) # 添加到总行列表 print(f"读取了 {len(lines)} 行文本") # 打印读取行数 print(f"总共读取了 {len(all_lines)} 行文本") # 打印总行数 print("编码数据:") # 打印编码开始信息 encoded_data = [] # 创建编码数据列表 for line in tqdm(all_lines, desc="编码进度"): # 遍历所有行 seq = [tokenizer.vocab['<SOS>']] # 添加开始标记 seq.extend(tokenizer.encode(line)) # 编码文本 seq.append(tokenizer.vocab['<EOS>']) # 添加结束标记 encoded_data.append(seq) # 添加到编码数据列表 print(f"编码完成,共 {len(encoded_data)} 个文本片段") # 打印编码完成信息 return encoded_data # 返回编码数据def train_model(model, train_loader, val_loader, device, num_epochs, learning_rate, save_dir): # 训练模型的函数 optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=0.01) # 创建AdamW优化器 criterion = nn.CrossEntropyLoss(ignore_index=0) # 创建交叉熵损失函数 scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_epochs, eta_min=1e-6) # 创建学习率调度器 best_val_loss = float('inf') # 初始化最佳验证损失 train_losses = [] # 创建训练损失列表 val_losses = [] # 创建验证损失列表 print(f"\n开始训练,共 {num_epochs} 个epoch") # 打印训练开始信息 print(f"训练批次数: {len(train_loader)}, 验证批次数: {len(val_loader)}\n") # 打印批次信息 for epoch in range(1, num_epochs + 1): # 遍历所有epoch start_time = time.time() # 记录开始时间 model.train() # 设置为训练模式 train_loss = 0 # 初始化训练损失 for x, y in tqdm(train_loader, desc=f"Epoch {epoch}/{num_epochs} [训练]", leave=False): # 遍历训练批次 x, y = x.to(device), y.to(device) # 移动数据到设备 optimizer.zero_grad() # 清零梯度 outputs, _ = model(x) # 前向传播 B, S, V = outputs.shape # 获取输出形状 outputs = outputs.reshape(-1, V) # 重塑输出 y = y.reshape(-1) # 重塑目标 loss = criterion(outputs, y) # 计算损失 loss.backward() # 反向传播 torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪 optimizer.step() # 更新参数 train_loss += loss.item() # 累加损失 train_loss /= len(train_loader) # 计算平均训练损失 train_losses.append(train_loss) # 保存训练损失 model.eval() # 设置为评估模式 val_loss = 0 # 初始化验证损失 with torch.no_grad(): # 禁用梯度计算 for x, y in tqdm(val_loader, desc=f"Epoch {epoch}/{num_epochs} [验证]", leave=False): # 遍历验证批次 x, y = x.to(device), y.to(device) # 移动数据到设备 outputs, _ = model(x) # 前向传播 B, S, V = outputs.shape # 获取输出形状 outputs = outputs.reshape(-1, V) # 重塑输出 y = y.reshape(-1) # 重塑目标 loss = criterion(outputs, y) # 计算损失 val_loss += loss.item() # 累加损失 val_loss /= len(val_loader) # 计算平均验证损失 val_losses.append(val_loss) # 保存验证损失 scheduler.step() # 更新学习率 epoch_time = time.time() - start_time # 计算epoch时间 print(f"Epoch {epoch:3d}/{num_epochs} | Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f} | Time: {epoch_time:.1f}s | LR: {optimizer.param_groups[0]['lr']:.6f}") # 打印epoch信息 if val_loss < best_val_loss: # 如果验证损失更优 best_val_loss = val_loss # 更新最佳验证损失 torch.save({ # 保存模型 'model_state_dict': model.state_dict(), # 保存模型参数 'optimizer_state_dict': optimizer.state_dict(), # 保存优化器状态 'epoch': epoch, # 保存epoch数 'train_loss': train_loss, # 保存训练损失 'val_loss': val_loss, # 保存验证损失 }, os.path.join(save_dir, 'best_model.pt')) # 保存到文件 print(f" ✓ 保存最佳模型 (Val Loss: {val_loss:.4f})") # 打印保存信息 if epoch % 10 == 0: # 每10个epoch torch.save({ # 保存检查点 'model_state_dict': model.state_dict(), # 保存模型参数 'optimizer_state_dict': optimizer.state_dict(), # 保存优化器状态 'epoch': epoch, # 保存epoch数 'train_loss': train_loss, # 保存训练损失 'val_loss': val_loss, # 保存验证损失 }, os.path.join(save_dir, f'checkpoint_epoch_{epoch}.pt')) # 保存到文件 history = { # 创建训练历史字典 'train_losses': train_losses, # 保存训练损失列表 'val_losses': val_losses, # 保存验证损失列表 } history_path = os.path.join(save_dir, 'training_history.json') # 创建历史文件路径 with open(history_path, 'w', encoding='utf-8') as f: # 打开文件 json.dump(history, f, indent=2) # 写入JSON print(f"\n训练历史已保存到: {history_path}") # 打印保存路径 return best_val_loss, train_losses, val_losses # 返回训练结果def main(): # 主函数 print("=" * 60) # 打印分隔线 print("Transformer模型训练") # 打印标题 print("=" * 60) # 打印分隔线 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 选择设备 print(f"使用设备: {device}") # 打印设备信息 if torch.cuda.is_available(): # 如果有CUDA print(f"GPU数量: {torch.cuda.device_count()}") # 打印GPU数量 for i in range(torch.cuda.device_count()): # 遍历GPU print(f"GPU {i}: {torch.cuda.get_device_name(i)}") # 打印GPU名称 data_files = ["斗破苍穹.txt", "凡人修仙传.txt"] # 设置数据文件列表 save_dir = "checkpoints" # 设置保存目录 tokenizer_path = os.path.join(save_dir, "tokenizer.pkl") # 设置分词器路径 os.makedirs(save_dir, exist_ok=True) # 创建保存目录 if os.path.exists(tokenizer_path): # 如果分词器已存在 print(f"\n加载已有分词器: {tokenizer_path}") # 打印加载信息 tokenizer = BPETokenizer() # 创建分词器实例 tokenizer.load(tokenizer_path) # 加载分词器 print(f"分词器已加载,词表大小: {len(tokenizer.vocab)}") # 打印词表大小 else: # 如果分词器不存在 print("\n训练新的BPE分词器...") # 打印训练信息 tokenizer = BPETokenizer(vocab_size=5000) # 创建分词器实例 all_lines = [] # 创建所有行列表 for file_path in data_files: # 遍历数据文件 if os.path.exists(file_path): # 如果文件存在 with open(file_path, 'r', encoding='utf-8') as f: # 打开文件 lines = f.readlines() # 读取所有行 all_lines.extend([line.strip() for line in lines if line.strip()]) # 清理并添加行 tokenizer.train(all_lines[:100000000], verbose=True) # 训练分词器 tokenizer.save(tokenizer_path) # 保存分词器 print(f"分词器已保存到: {tokenizer_path}") # 打印保存路径 encoded_data = load_and_encode_data(data_files, tokenizer, max_lines_per_file=None) # 加载并编码数据,读取所有行 split_idx = int(len(encoded_data) * 0.9) # 计算划分索引 train_data = encoded_data[:split_idx] # 获取训练数据 val_data = encoded_data[split_idx:] # 获取验证数据 print(f"训练集: {len(train_data)}, 验证集: {len(val_data)}") # 打印数据集大小 seq_len = 64 # 设置序列长度 train_dataset = TextDataset(train_data, seq_len) # 创建训练数据集 val_dataset = TextDataset(val_data, seq_len) # 创建验证数据集 print(f"训练样本数: {len(train_dataset)}, 验证样本数: {len(val_dataset)}") # 打印样本数 batch_size = 128 # 设置批次大小 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0) # 创建训练加载器 val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=0) # 创建验证加载器 vocab_size = len(tokenizer.vocab) # 获取词表大小 d_model = 256 # 设置模型维度 num_heads = 4 # 设置注意力头数 num_layers = 4 # 设置层数 d_ff = 512 # 设置前馈网络维度 print(f"\n创建Transformer模型...") # 打印创建信息 model = Transformer( # 创建模型 vocab_size=vocab_size, # 设置词表大小 d_model=d_model, # 设置模型维度 num_heads=num_heads, # 设置注意力头数 num_layers=num_layers, # 设置层数 d_ff=d_ff, # 设置前馈网络维度 max_len=seq_len, # 设置最大序列长度 dropout=0.1 # 设置dropout率 ).to(device) # 移动到设备 num_params = sum(p.numel() for p in model.parameters()) # 计算参数数量 print(f"模型参数数量: {num_params:,}") # 打印参数数量 best_val_loss = float('inf') # 初始化最佳验证损失 current_round = 1 # 初始化当前轮数 while True: # 训练循环 print(f"\n{'='*60}") # 打印分隔线 print(f"第 {current_round} 轮训练") # 打印轮数 print(f"{'='*60}") # 打印分隔线 best_val_loss_round, train_losses, val_losses = train_model( # 训练模型 model=model, # 传入模型 train_loader=train_loader, # 传入训练加载器 val_loader=val_loader, # 传入验证加载器 device=device, # 传入设备 num_epochs=50, # 设置epoch数 learning_rate=1e-3, # 设置学习率 save_dir=save_dir # 传入保存目录 ) if best_val_loss_round <= 0.1: # 如果达到目标 print(f"\n{'='*60}") # 打印分隔线 print(f"✅ 训练成功!验证损失: {best_val_loss_round:.4f} <= 0.1") # 打印成功信息 print(f"{'='*60}") # 打印分隔线 break # 退出循环 if len(val_losses) >= 10: # 如果有足够的验证损失 recent_losses = val_losses[-10:] # 获取最近10个损失 loss_decrease = recent_losses[0] - recent_losses[-1] # 计算损失下降量 if loss_decrease < 0.01: # 如果下降缓慢 print(f"\n{'='*60}") # 打印分隔线 print(f"⚠️ Loss下降缓慢,调整参数继续训练") # 打印警告信息 print(f"最近10个epoch loss下降: {loss_decrease:.4f}") # 打印下降量 print(f"{'='*60}") # 打印分隔线 new_lr = 1e-4 # 设置新学习率 print(f"调整学习率为: {new_lr}") # 打印新学习率 best_val_loss_round, train_losses, val_losses = train_model( # 继续训练 model=model, # 传入模型 train_loader=train_loader, # 传入训练加载器 val_loader=val_loader, # 传入验证加载器 device=device, # 传入设备 num_epochs=50, # 设置epoch数 learning_rate=new_lr, # 设置新学习率 save_dir=save_dir # 传入保存目录 ) if best_val_loss_round <= 0.1: # 如果达到目标 print(f"\n{'='*60}") # 打印分隔线 print(f"✅ 训练成功!验证损失: {best_val_loss_round:.4f} <= 0.1") # 打印成功信息 print(f"{'='*60}") # 打印分隔线 break # 退出循环 print(f"\n当前验证损失: {best_val_loss_round:.4f} > 0.1,继续训练...") # 打印当前损失 current_round += 1 # 轮数递增 if current_round > 5: # 如果超过最大轮数 print(f"\n{'='*60}") # 打印分隔线 print(f"❌ 训练未达到目标,已达到最大训练轮数") # 打印失败信息 print(f"最佳验证损失: {best_val_loss_round:.4f}") # 打印最佳损失 print(f"{'='*60}") # 打印分隔线 break # 退出循环 print(f"\n最终最佳验证损失: {best_val_loss:.4f}") # 打印最终损失 if best_val_loss <= 0.1: # 如果达到目标 print("✅ 训练成功!") # 打印成功信息 else: # 如果未达到目标 print("❌ 训练未达到目标") # 打印失败信息if __name__ == "__main__": # 如果作为主程序运行 main() # 调用主函数
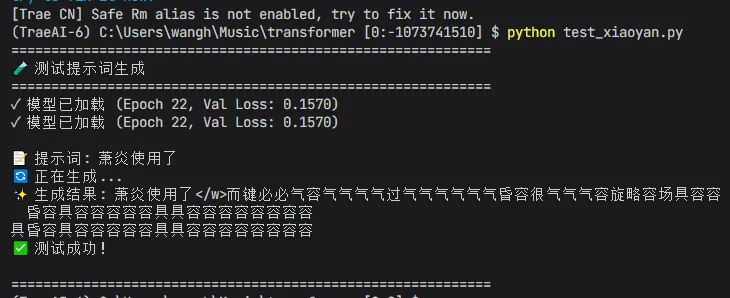
# -*- coding: utf-8 -*-"""测试脚本 - 验证"萧炎使用了"的生成功能"""import torchimport torch.nn as nnimport mathimport pickleclass PositionalEncoding(nn.Module): """位置编码""" def __init__(self, d_model, max_len=5000): super().__init__() pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) self.register_buffer('pe', pe.unsqueeze(0)) def forward(self, x): return x + self.pe[:, :x.size(1), :]class MultiHeadAttention(nn.Module): """多头注意力机制""" def __init__(self, d_model, num_heads): super().__init__() self.d_model = d_model self.num_heads = num_heads self.d_k = d_model // num_heads self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) self.W_o = nn.Linear(d_model, d_model) def forward(self, query, key, value, mask=None): batch_size = query.size(0) Q = self.W_q(query) K = self.W_k(key) V = self.W_v(value) Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2) scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) attention_weights = torch.softmax(scores, dim=-1) output = torch.matmul(attention_weights, V) output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) output = self.W_o(output) return output, attention_weightsclass FeedForward(nn.Module): """前馈神经网络""" def __init__(self, d_model, d_ff, dropout=0.1): super().__init__() self.linear1 = nn.Linear(d_model, d_ff) self.linear2 = nn.Linear(d_ff, d_model) self.dropout = nn.Dropout(dropout) self.relu = nn.ReLU() def forward(self, x): x = self.linear1(x) x = self.relu(x) x = self.dropout(x) x = self.linear2(x) return xclass TransformerBlock(nn.Module): """Transformer块""" def __init__(self, d_model, num_heads, d_ff, dropout=0.1): super().__init__() self.attention = MultiHeadAttention(d_model, num_heads) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.feed_forward = FeedForward(d_model, d_ff, dropout) self.dropout = nn.Dropout(dropout) def forward(self, x, mask=None): attn_output, _ = self.attention(x, x, x, mask) x = self.norm1(x + self.dropout(attn_output)) ff_output = self.feed_forward(x) x = self.norm2(x + self.dropout(ff_output)) return xclass Transformer(nn.Module): """Transformer模型""" def __init__(self, vocab_size, d_model=256, num_heads=4, num_layers=4, d_ff=512, max_len=64, dropout=0.1): super().__init__() self.d_model = d_model self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoding = PositionalEncoding(d_model, max_len) self.transformer_blocks = nn.ModuleList([ TransformerBlock(d_model, num_heads, d_ff, dropout) for _ in range(num_layers) ]) self.fc = nn.Linear(d_model, vocab_size) self.dropout = nn.Dropout(dropout) def forward(self, x, mask=None): x = self.embedding(x) * math.sqrt(self.d_model) x = self.pos_encoding(x) x = self.dropout(x) for block in self.transformer_blocks: x = block(x, mask) output = self.fc(x) return output, Nonedef load_model(): """加载模型和分词器""" device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') print(f"🚀 设备: {device}") with open("checkpoints/tokenizer.pkl", 'rb') as f: data = pickle.load(f) vocab = data['vocab'] inv_vocab = data['inv_vocab'] merges = data['merges'] print(f"📦 词表大小: {len(vocab)}") checkpoint = torch.load("checkpoints/best_model.pt", map_location=device) model = Transformer(len(vocab)).to(device) model.load_state_dict(checkpoint['model_state_dict']) model.eval() print(f"✓ 模型已加载 (Epoch {checkpoint['epoch']}, Val Loss: {checkpoint['val_loss']:.4f})") return model, vocab, inv_vocab, merges, devicedef encode(text, vocab, merges): """编码文本""" words = text.split() encoded = [] for word in words: word += '</w>' symbols = list(word) while len(symbols) > 1: merged = False for pair in merges: for i in range(len(symbols) - 1): if symbols[i] == pair[0] and symbols[i+1] == pair[1]: symbols[i:i+2] = [pair[0] + pair[1]] merged = True break if merged: break if not merged: break for symbol in symbols: if symbol in vocab: encoded.append(vocab[symbol]) else: encoded.append(vocab['<UNK>']) return encodeddef decode(ids, inv_vocab): """解码ID序列""" text = [] for idx in ids: if idx in inv_vocab: token = inv_vocab[idx] if token not in ['<PAD>', '<SOS>', '<EOS>', '<UNK>']: text.append(token.replace('</w>', ' ')) return ''.join(text)def generate_text(model, prompt, vocab, inv_vocab, merges, device, max_length=50, temperature=0.8): """生成文本""" tokens = [vocab['<SOS>']] tokens.extend(encode(prompt, vocab, merges)) with torch.no_grad(): for _ in range(max_length): input_seq = torch.LongTensor([tokens[-64:]]).unsqueeze(0).to(device) outputs, _ = model(input_seq) logits = outputs[0, -1, :] / temperature if temperature == 0: next_token = logits.argmax(dim=-1).item() else: probs = torch.softmax(logits, dim=-1) next_token = torch.multinomial(probs, 1)[0].item() tokens.append(next_token) if next_token == vocab['<EOS>']: break generated_text = decode(tokens, inv_vocab) return generated_textdef test_prompt(): """测试特定提示词""" print("=" * 60) print("🧪 测试提示词生成") print("=" * 60) model, vocab, inv_vocab, merges, device = load_model() test_prompts = ["萧炎使用了"] for prompt in test_prompts: print(f"\n📝 提示词: {prompt}") print(f"🔄 正在生成...") try: generated = generate_text(model, prompt, vocab, inv_vocab, merges, device, max_length=50, temperature=0.8) print(f"✨ 生成结果: {generated}") print("✅ 测试成功!") except Exception as e: print(f"❌ 生成失败: {str(e)}") import traceback traceback.print_exc() print("\n" + "=" * 60)if __name__ == "__main__": test_prompt()