如果想从事算法行业,强烈推荐大家学习大模型!2025年大模型大规模爆发,2026年作为Agent落地元年,涌现出大批AI应用,生成式人工智能已在各行各业生根发芽。
大模型属于生成式模型,和机器学习、深度学习中的判别式模型有明显区别。这一波AI热潮至少能持续3-5年,现在正是入局大模型的最佳时机。
这一期就给大家推荐一套实用的生成式人工智能入门教程,
生成式人工智能是一种能生成文本、图像及其他类型内容的AI技术,任何人只需输入一句自然语言提示,就能轻松使用它。这一部分主要介绍生成式AI的定义、LLM的基本原理,以及其核心应用场景。
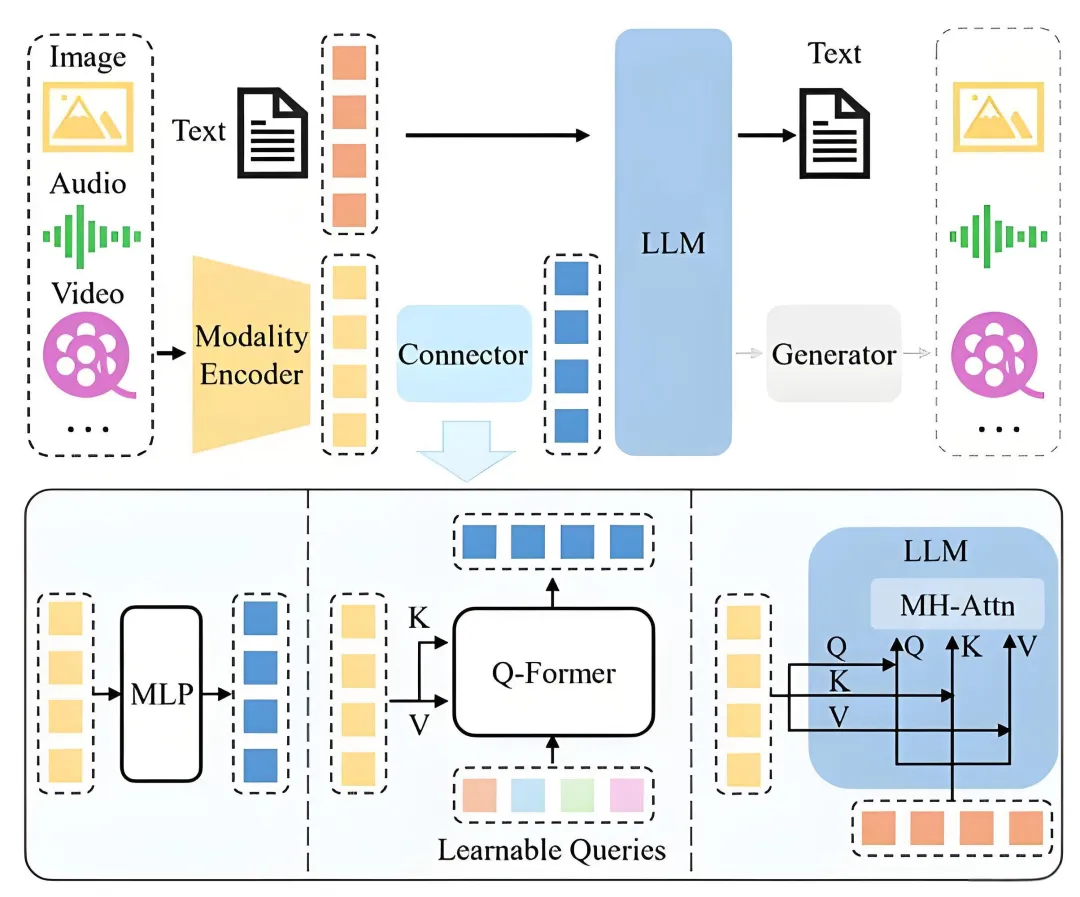
本章主要介绍不同领域的LLM,LLM应用于不同领域时,需要在模型结构和数据上做相应调整。我们会在Azure中测试、迭代并比较不同模型,以适配你的具体使用场景,最后还会讲解LLM的部署方法。
本章主要介绍负责任人工智能的原则,以及如何负责任地使用生成式人工智能,比如如何识别、测量并缓解潜在危害。这部分内容比较简单,大家大概过一遍即可。
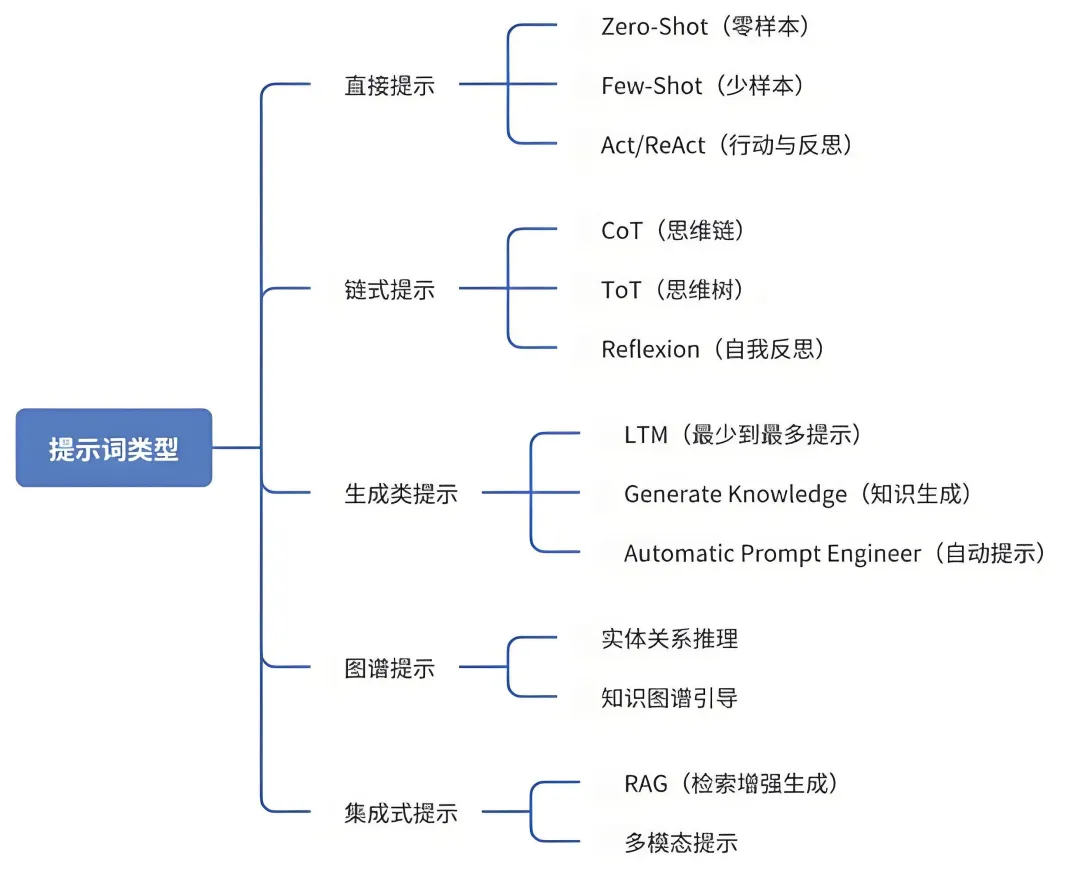
本章核心讲解提示词工程,学习大模型必然要了解Prompt是什么,以及如何设计效果更好的Prompt。通过Prompt优化模型效果,无需进行微调,经济又高效,也是目前热门的研究方向,最后会分享一些高级提示词技巧。
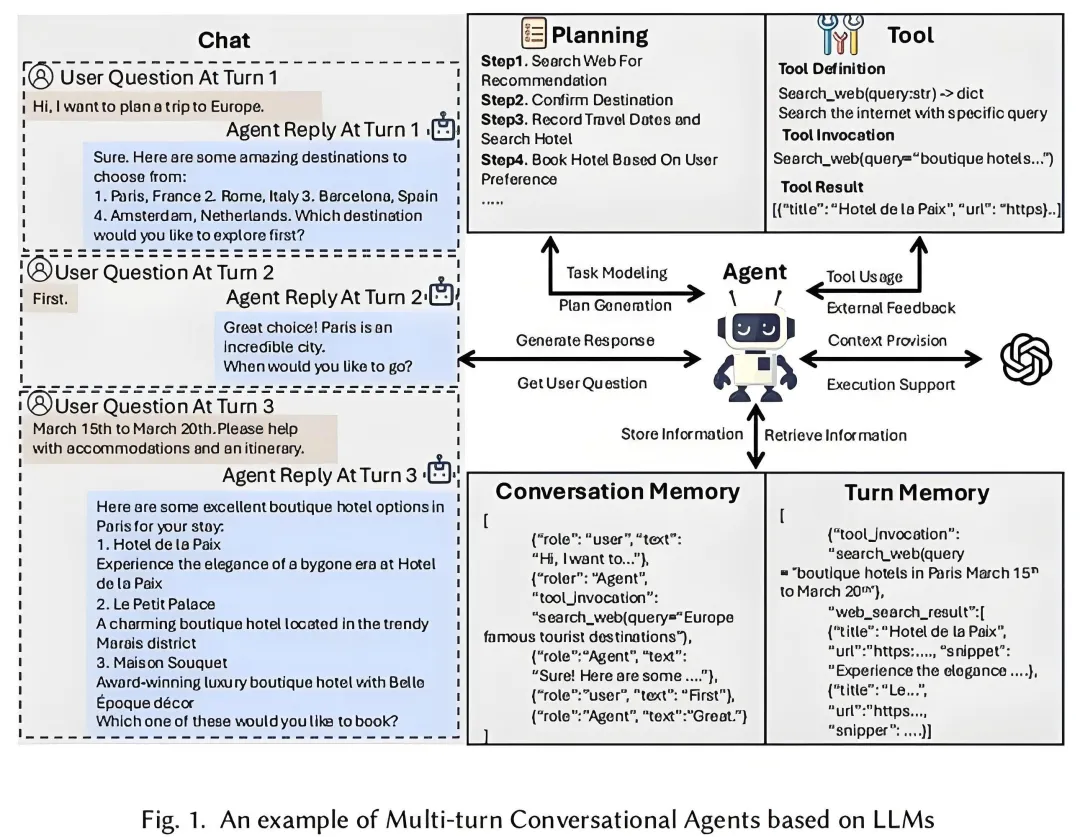
本章主要介绍高效构建和集成聊天应用的技术,以及如何对应用进行定制与微调,同时讲解有效监控聊天应用的策略和关键考虑因素。
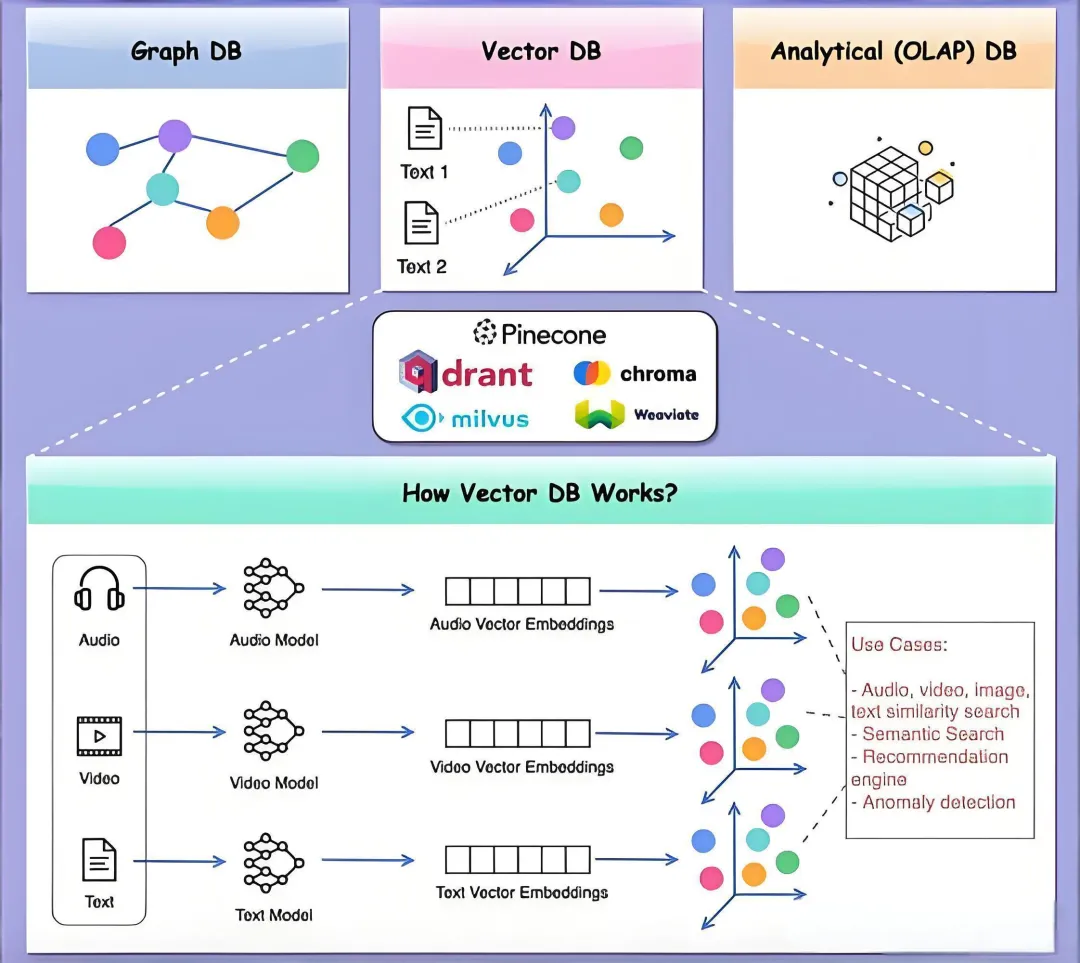
这部分内容涵盖广泛,主要介绍聊天应用搭建、搜索应用与向量数据库、图像生成应用、代码AI应用,以及如何通过函数调用集成外部应用、设计AI应用的用户体验、保护生成式AI应用,还有生成式AI应用的生命周期管理等。
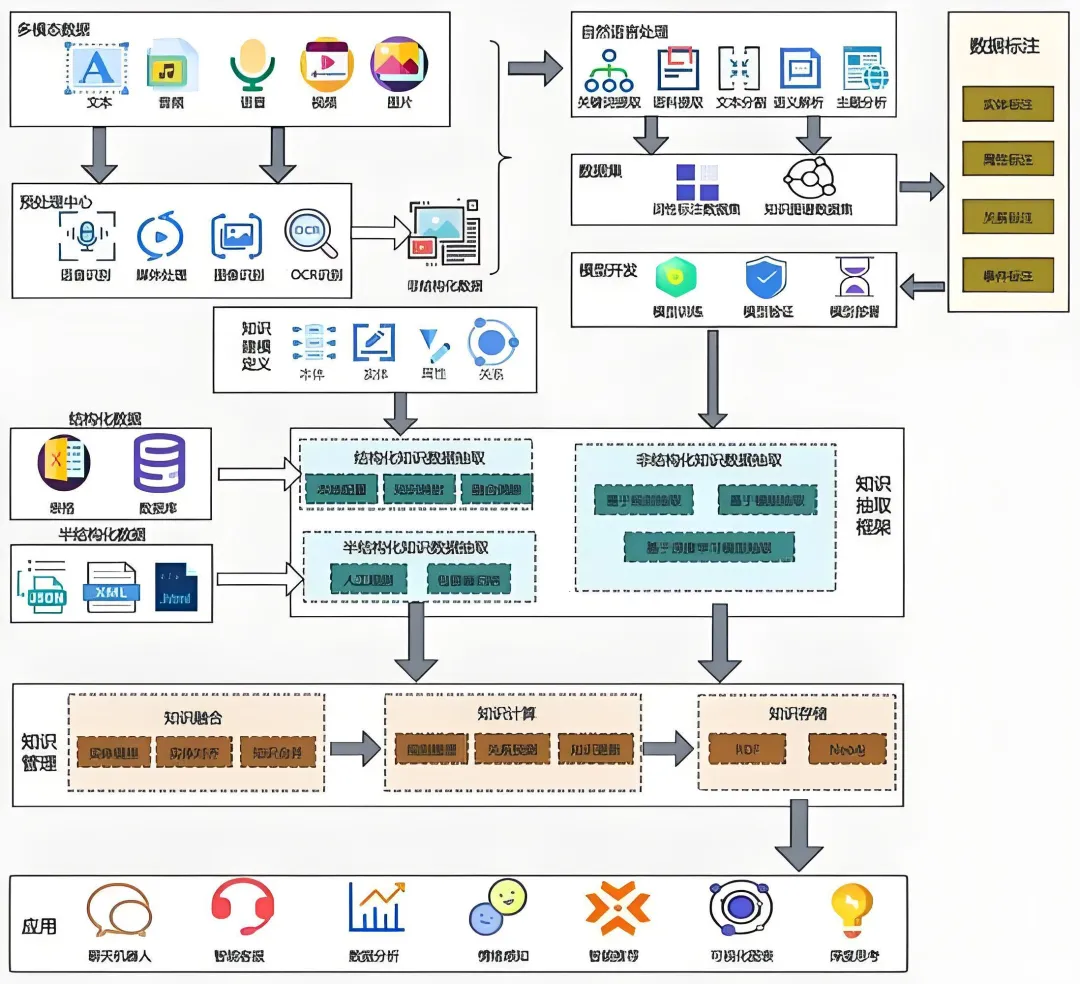
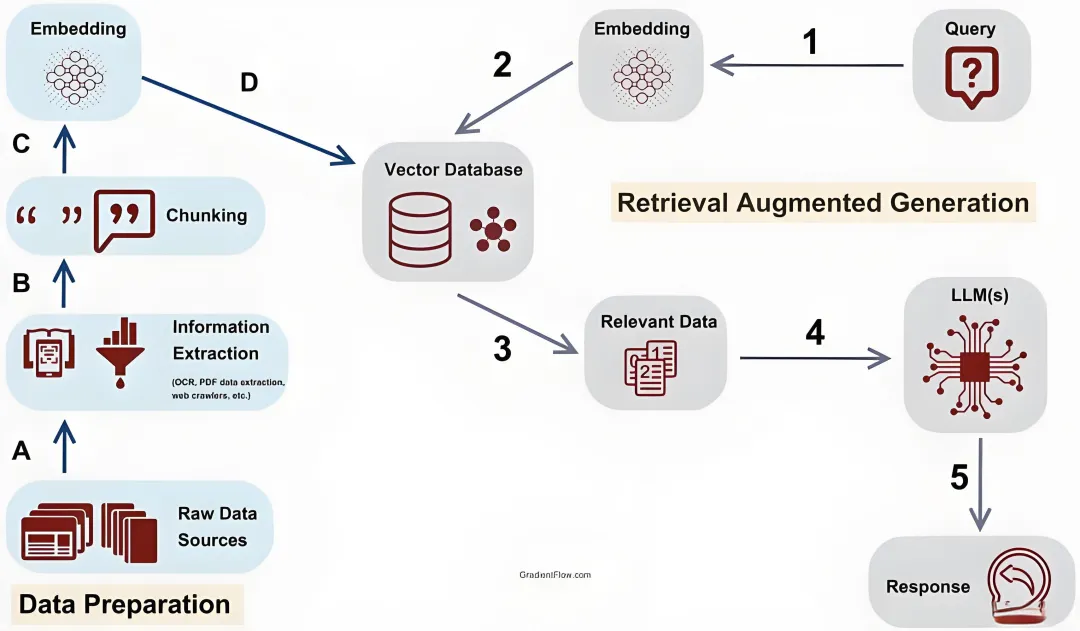
本章讲解RAG在数据检索和处理中的重要性,教大家设置RAG应用、将数据基础化到LLM,以及如何在LLM应用中有效集成RAG和向量数据库。
第十六-十七节:开源模型与Hugging Face本章主要介绍如何使用Hugging Face上的开源模型构建应用。Hugging Face开源了大量模型,我们可以将其下载到本地或部署到服务器,再用自己的数据进行微调等操作。
本章主要讲解大模型的微调方法。大模型经过预训练开源发布后,我们可以在预训练模型的基础上,通过监督微调或强化学习优化,让通用大模型在特定任务(specific task)上表现更好。
此外,教程还包含SLMs构建、使用Mistral模型构建、使用Meta模型构建等相关内容。
大家可以针对性学习以上内容,其中应用相关部分难度不大,且大多不是重点,可根据自身需求选择性跳过。
2. 发送口令“AI教程”领取(人工回复可能有时差,都会发给大家的,不用着急)