本课程讲解大语言模型(LLM)基础应用,核心包括提示词工程与 OpenAI API 开发,适合有基础编程能力的学习者快速上手生成式 AI 实战。
课程先教如何设计清晰、有效的提示词,引导模型输出稳定结果;再通过 Python 调用 API,实现文本生成、摘要、图像生成等功能,并完成可复用的小项目。
面向有变量、函数、JSON 基础的学习者,适合数据科学、ML 工程师、产品及技术从业者提升 AI 落地能力。
LLM 功能强大且持续迭代,但存在错误与风险;推理型 LLM 在复杂逻辑任务表现优异,提示工程的核心是清晰、简洁、结构化地引导模型输出。
知识来源
生成机制
基础模型特性
传统聊天机器人
生成式 AI 机器人
Token 本质
上下文决定 Token 值
计费与限制(关键)
ChatGPT Plus 可以零代码完成完整数据分析流程数据读取 → 清洗 → 划分 → 回归 → 分类 → 可视化 → 解释 → 优化建议
当前模型上限极大
限制持续变大
更详细 = 更少追问 = 更低总令牌
详细提示 = 更高准确率
单用户 / 单次使用
百万级用户 / 大规模系统
API 允许你:
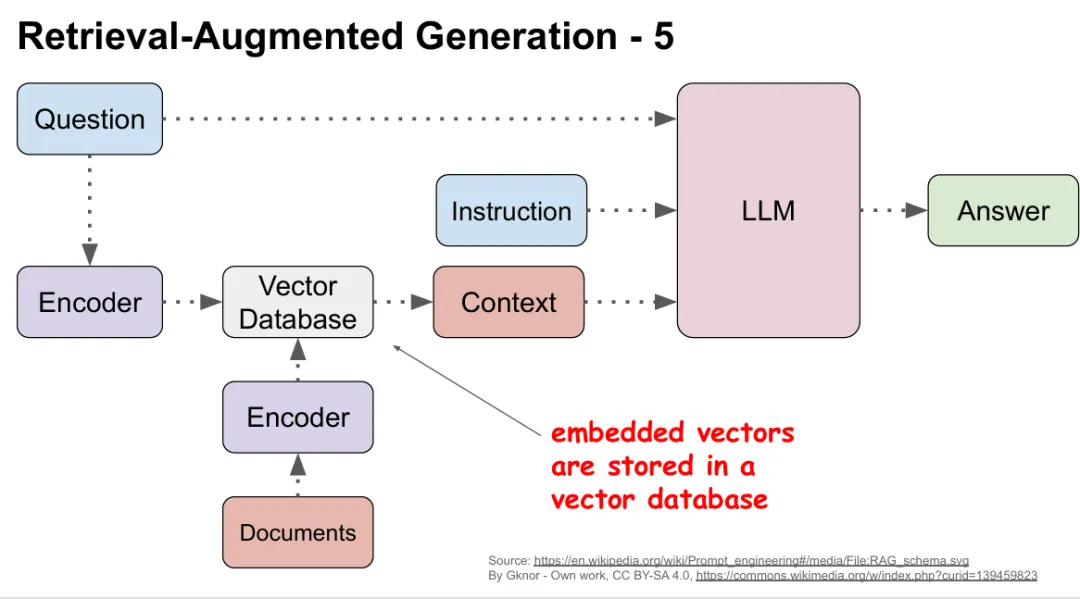
Retrieval-Augmented Generation:让 LLM 调用外部文档知识,不修改模型参数
存储向量,支持高效相似性检索
只更新模型一小部分,节省资源
这部分是 RAG 最核心的技术底层
向量搜索 = 在向量数据库里快速找到最相似的向量因为数据量巨大,不能一个个暴力计算,所以需要高效算法:
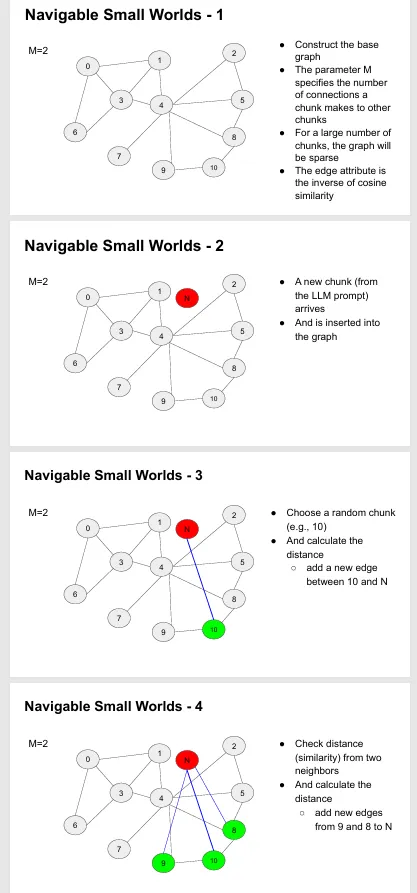
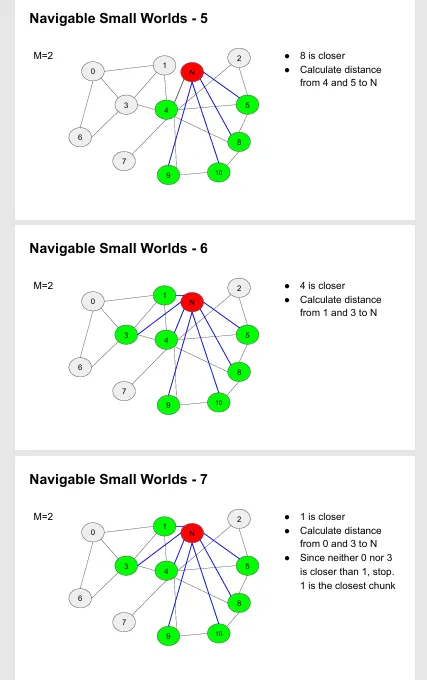
可导航小世界算法(向量搜索的基础算法)
分层可导航小世界算法(目前工业界最常用)
FAISS(Facebook AI Similarity Search)
向量嵌入把文本变数字,余弦相似度衡量相似性,NSW 是基础向量搜索,HNSW 是分层超快版本,FAISS 是最常用工具,它们一起让 RAG 能快速从海量文档里找到相关内容。
RAG(Retrieval-Augmented Generation)
一种用图结构组织和表示领域知识的数据模型,以 ** 实体(Entities)和关系(Relationships)** 形式存储。
给模型指令(Instruction),让模型按指令执行任务。
不更新整个模型,只更新一小部分参数→ 省显存、省数据、速度快、过拟合风险低
量化版 LoRA,更小、更快。
RAG 不改变模型,低成本;微调会更新模型,效果强但成本高;PEFT 只改少量参数,高效省资源,是当下最主流的轻量化定制方法。