内容小结:这篇学习了表的复制,实则是使用了insert into与子查询结合的做法;其次,写出了表的复制的思路;两者,介绍了合并查询功能,语句为union (all会保留重复数据);然后,进一步介绍了外连接功能,(left/right)join...on后引导条件,要注意分辨主表;最后介绍了几类常见的约束及用法细节,有主键约束、unique与 not null约束、外键约束及chech约束。在 SQL 里,表的复制本质就是:根据一张已经存在的表,快速造出一张结构 / 数据都一样的新表,相当于给表做个 “副本”。而且它和上篇学的子查询当临时表思路几乎一模一样,只是这次不是临时用一下,而是真的建一张永久新表。
考虑下面场景,为了对某个sql语句进行效率测试,我们需要大量数据时,可以使用此法为表创建海量数据。我们复制前先新建一个表,这个语句我们之前已经学习过。
CREATE TABLE my_tab01 (id INT, `name` VARCHAR(32), sal DOUBLE, job VARCHAR(32), deptno INT);
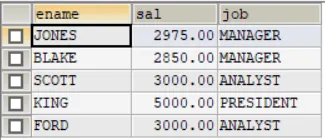
上面代码操作后可使用下面语句查看表格属性,接着进行自我复制-- 演示如何自我复制-- 1.先把emp表的记录复制到my_tab01INSERT INTO my_tab01 (id, `name`, sal, job, deptno)SELECT empno, ename, sal, job, deptno FROM emp;
上面方法通过insert into与select查询结合,直接实现数据复制效果-- 2.自我复制INSERT INTO my_tab01SELECT * FROM my_tab01;
其实与方法一相同,只是复制自己的数据,更方便快捷。再回忆一下原本添加数据的语句:-- 固定格式INSERT INTO 表名(字段1, 字段2, 字段3) VALUES(值1, 值2, 值3);
表中的数据去重操作并不是一个固定的语句,这里只是提供一个可以参观的思路。下面我们先创建一个有重复数据的表进行举例示范:
1. 先创建一张表my_tab02;
2. 让my_tab02表中出现重复记录;
CREATE TABLE my_tab02 LIKE emp;
这个语句把emp表的结构(列)复制到my_tab02,只复制表的结构字段,并不复制具体数据
INSERT INTO my_tab02SELECT * FROM emp
把emp表的数据复制到my_tab02中去。好的,带有重复数据的表格创建完毕,下面来看去重操作的思路:
(1)先创建一张表my_tmp,该表的结构和my_tab02一样
(2)把my_tmp的记录,通过distinct关键字处理后,把记录复制到my_tab
(3)清除到my_tab02的记录
(4)把my_tab表的记录复制到my_tab02
(5)drop掉临时表my_tmp
-- (1)先创建一张表my_tmp,该表的结构和my_tab02一样CREATE TABLE my_tmp LIKE my_tab02;-- (2)把my_tmp的记录,通过distinct关键字处理后,把记录复制到my_tabINSERT INTO my_tmpSELECT DISTINCT * FROM my_tab02;-- (3)清除到my_tab02的记录DELETE FROM my_tab02;-- (4)把my_tab表的记录复制到my_tab02INSERT INTO my_tab02SELECT * FROM my_tmp;-- (5)drop掉临时表my_tmpDROP TABLE my_tmp;
其实自然可以有其它方法,比如到第(3)时,直接将my_tab02表删除,然后将my_tmp表改名为my_tab02
合并查询,就是将多条select语句查询结果,从上到下[拼接]在一起,就像摞积木一样。合并查询(UNION / UNION ALL)不看表结构、不看列名、不看表本身,只看你SELECT 出来的结果集,只卡两个硬性规则:- 1. 两次查询的列数必须完全相同
- 2. 对应位置上的列,数据类型要兼容(数字对数字、字符串对字符串、日期对日期)
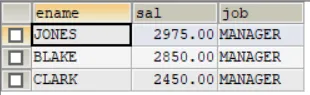
虽然不要求表结构一致,但是往往也要考虑真实场景下的要求,不然不同含义的数据放在一起,也没有意义。下面结合例子来讲,union all操作用于取两个结果集的并集,不会取消重复行。SELECT ename,sal,job FROM emp WHERE sal>2500
SELECT ename,sal,job FROM emp WHERE job='MANAGER'
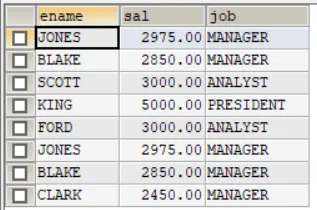
SELECT ename,sal,job FROM emp WHERE sal>2500UNION ALLSELECT ename,sal,job FROM emp WHERE job='MANAGER'
原本是多少条数据,合并后就得到多少条数据,不会变化。而使用union连接时,是会自动去除重复数据的。想要搞清楚外连接,可以对比内接连来理解。前面学到的多表查询,是利用where子句对两张表或者多张表形成的笛卡尔积进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的,不显示。
SELECT * FROM 表A, 表B WHERE 表A.字段 = 表B.字段
即A,B两表通过where后的条件羁绊互相完善表的信息,往往最终的表格的字段数对比A,B两表会增加,但是行数却不大于两表中行数最小的一个。
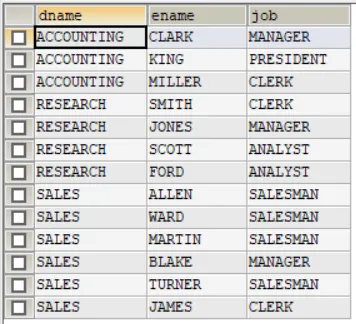
思考:列出部门名称和这些部门的员工名和工作,同时要求显示出那些没有员工的部门。
若使用前面学习地的多表查询的SQL,看得到的效果
SELECT dname, ename, jobFROM emp,deptWHERE emp.deptno=dept.deptnoORDER BY dname ASC
上面得到了三个部门及相关信息,其实一共有四个部门,还有一个部门没有显示出来,因为有一个部门中没有员工数据。这样并不能满足上面情境的需求。但外连接就可以实现这一点。
相比于内连接,外连接会保证主表中行数据的完整性,即使其它表中没有与主表中行数据相匹配的数据,也会保留主表行数据的完整性。同样提及匹配,正常的多表查询,我们将where后的条件作为连接羁绊
SELECT* FROM 表A, 表B WHERE 表A.字段 = 表B.字段
对于外连接,我们将on后的条件作为连接羁绊。
SELECT* FROM 表A left join 表B # 这是左连接,那么左面的表就是主表 on 表A.字段 = 表B.字段
外连接分为左外连接与右外连接,具体介绍如下:
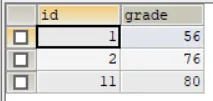
结合一个例子看:显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空。
SELECT `name`, stu.id, grade FROM stu, exam WHERE stu.id=exam.id
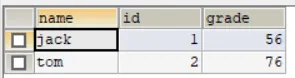
现在我们进行左外连接:select ... from 表1 left join 表2 on 条件SELECT `name`, stu.id, grade FROM stu LEFT JOIN exam ON stu.id=exam.id
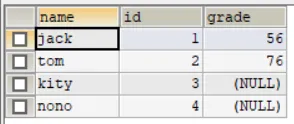
现在用右外连接:select ... from 表1 right join 表2 on 条件
SELECT `name`, stu.id, grade FROM exam RIGHT JOIN stu ON stu.id=exam.id
SQL 中的「约束」就是给数据库表的列,提前定好的「硬性规矩」。不满足规矩的数据,直接不让存进表里,用来保证数据干净、正确、不混乱,专业叫法叫保证数据完整性。比如:员工姓名不能是空的,员工 ID 不能重复,工资不能是负数,部门 ID 必须是部门表里真实存在的 ID等等。这些规矩,就是约束(Constraint)。
用于唯一 的标示表行的数据,当定义主键约束后,该列不能重复
CREATE TABLE t17 (id INT PRIMARY KEY, `name` VARCHAR(32), email VARCHAR(32));
- 一张表中只能有一个主键,但是可以有复合主键(如下)
-- id 与 `name`组成了复合主键,这两个加一起不重复就可以CREATE TABLE t18 (id INT, `name` VARCHAR(32), email VARCHAR(32),PRIMARY KEY (id, `name`));
使用desc可以查看表的结构,也可以看到primary key的情况。与主键联合使用的有一个auto_increment-- 自增长的使用-- 创建表CREATE TABLE t23 (id INT PRIMARY KEY AUTO_INCREMENT, email VARCHAR(32) NOT NULL DEFAULT '', `name` VARCHAR(32) NOT NULL DEFAULT '');
DESC t23INSERT INTO t23VALUES(NULL, 'tom@qq.com', 'tom'); # 这里给的为空值,但是会自动填充INSERT INTO t23 # 这里给的为空值,但是会自动填充 (email, `name`) VALUES('hs@qq.com', 'hs');SELECT * FROM t23
- 自增长默认从1开始,也可以通过命令alter table 表名 auto_increment=xx
CREATE TABLE t19 (id INT UNIQUE NOT NULL, `name` VARCHAR(32), email VARCHAR(32));
- 如果没有指定not null,则unique字段可以有多个null,而且not null与unique是没有先后书写顺序的
这个概念有些难理解。外键约束就是给两张有关系的表定死规则:从表的关联字段,只能填主表里真实存在的主键值,绝不允许乱填无效数据,保证表与表之间的数据关联合法、不混乱。- 主表(父表)就是被引用的表,字段是主键 / 唯一约束,是标准来源。
- 从表(子表)就是引用主表的表,里面设置外键,依赖主表的数据。
dept 部门表(主表 / 父表) | emp 员工表(从表 / 子表) |
| |
(1)往子表插数据时:不能瞎填。如 dept 里只有部门10、20、30,往 emp 里加一个员工,部门填 40👉 会报错,不让你插入
(2)删主表数据时:不能随便删。如果 dept 里 10 部门下还有员工数据,你直接执行 DELETE FROM dept WHERE deptno=10👉 外键会报错,不让删,这时必须先把 10 部门的员工全部删掉 / 改部门,才能删部门。
此外,可以设置外键常见的联动规则,当删除 / 更新主表时,子表自动跟着变,语句如下:
FOREIGN KEY (子表字段) REFERENCES 主表(主键)ON DELETE 联动规则 -- 删除主表数据时触发ON UPDATE 联动规则 -- 更新主表主键时触发
SET NULL:主表删,子表对应字段设为 NULL
RESTRICT / NO ACTION:默认,不让删(最安全)
-- 外键在从表中,建立的时候,先建主表,后建从表-- 创建 主表 my_classCREATE TABLE my_class( id INT PRIMARY KEY, -- 班级编号 `name` VARCHAR(32) NOT NULL DEFAULT '');-- 创建从表 my_stuCREATE TABLE my_stu( id INT PRIMARY KEY, -- 学生编号 `name` VARCHAR(32) NOT NULL DEFAULT '', class_id INT, -- 学生所在班级的编号-- 下面指定外键关系FOREIGN KEY(class_id) REFERENCES my_class(id))
-- 测试数据INSERT INTO my_classVALUES(100, 'java'),(200, 'web')SELECT * FROM my_classINSERT INTO my_stuVALUES(1, 'tom', 100),(2, 'jack', 200)INSERT INTO my_stuVALUES(3, 'hml', 300) -- 这里会失败,因为300号班级不存在
- 外键指向的表的字段,要求是primary key或unique
- 外键字段的类型要和主键字段的类型一致(长度可以不同)
- 外键字段的值,可以是null,否则必须在主键字段中出现过
CHECK 约束就是给数据表的列,自定义一套「业务规矩」。之前学的约束都是固定死的规矩,而 CHECK 约束是可以根据自己需要设定的。比如,假定在sal列上定义check约束,并要求sal列值在1000-2000之间,当添加值不符合时,会提示出错。
CREATE TABLE t22( id INT PRIMARY KEY, `name` VARCHAR(32), sex VARCHAR(6) CHECK (sex IN ('man','woman')), sal DOUBLE CHECK (sal> 1000 AND sal <2000));
在比较老的版本中,check是不生效的,就是超出条件的相关值还可以正常输入,但实际上这个语句是有校验功能的
现有一个商店的数据库 shop_db,记录客户及其购物情况,由下面三个表组成:
- (1)商品 goods 表(商品号 goods_id,商品名 goods_name,单价 unitprice,商品类别 category,供应商 provider);
- (2)客户 customer 表(客户号 customer_id,姓名 name,住址 address,电邮 email,性别 sex,身份证 card_id);
- (3)购买 purchase 表(购买订单号 order_id,客户号 customer_id,商品号 goods_id,购买数量 nums);
建表要求在定义中要求声明 [进行合理设计]:
- (5)单价 unitprice 在 1.0 - 9999.99 之间。
-- 现有一个商店的数据库 shop_db,记录客户及其购物情况,由下面三个表组成:CREATE DATABASE shop_dbUSE shop_db -- 在当前数据库中进行操作
-- 商品 goods(商品号 goods_id,商品名 goods_name,单价 unitprice,商品类别 category,供应商 provider);CREATE TABLE goods( goods_id INT PRIMARY KEY, goods_name VARCHAR(32) NOT NULL DEFAULT '', unitprice DECIMAL(10,2) NOT NULL DEFAULT 0CHECK (unitprice>=1.0 AND unitprice<=9999.99), category INT NOT NULL DEFAULT 0, provider VARCHAR(20) NOT NULL DEFAULT '');
-- 客户 customer(客户号 customer_id,姓名 name,住址 address,电邮 email,性别 sex,身份证 card_id);CREATE TABLE customer( customer_id INT, `name` VARCHAR(32) NOT NULL DEFAULT '', address VARCHAR(32) NOT NULL DEFAULT '', email VARCHAR(32) UNIQUE NOT NULL, sex ENUM('男', '女') NOT NULL, -- 这里使用的枚举类型 card_id CHAR(18));
DESC customer --查看表的结构-- 修改表中字段的类型,在进行外键关联时,两个字段的类型要保持一致ALTER TABLE customer MODIFY COLUMN customer_id CHAR(8) PRIMARY KEY;
-- 购买 purchase(购买订单号 order_id,客户号 customer_id,商品号 goods_id,购买数量 nums);CREATE TABLE purchase( order_id INT PRIMARY KEY, customer_id CHAR(8) NOT NULL DEFAULT '', goods_id INT NOT NULL DEFAULT 0, nums INT NOT NULL DEFAULT 0,FOREIGN KEY (customer_id) REFERENCES customer(customer_id),FOREIGN KEY (goods_id) REFERENCES goods(goods_id));