Unidbg学习笔记(三):五个后端引擎的性能与取舍
- 2026-05-28 14:07:56
后端选择不是"哪个最快"的问题,而是"你要用 Unidbg 做什么"的问题。不同场景下的最优解完全不同。
什么是 Backend
在前两篇中,我们多次提到"Backend"这个词。现在是时候正式解释它了。
Backend 是 Unidbg 中真正执行 ARM 指令的那一层。当你在 Unidbg 中调用一个 SO 函数时,SO 的 ARM 机器码不会被 JVM 直接执行(JVM 只认识 Java 字节码),它需要一个"翻译官"或"代理执行者"来处理。这个角色就是 Backend。
Unidbg 把 Backend 抽象为一个接口(com.github.unidbg.arm.backend.Backend),所有与 CPU 模拟相关的操作 — 读写寄存器、读写内存、执行指令、设置 Hook — 都通过这个接口调用。具体的实现可以替换,上层代码完全无感知。
// Unidbg 中选择 Backend 的方式
// 分析场景:使用 Unicorn2(支持 Trace 和 Hook)
AndroidEmulator emulator = AndroidEmulatorBuilder.for64Bit()
.addBackendFactory(new Unicorn2Factory(true)) // true 表示启用多线程支持
.build();
// 生产场景:使用 Dynarmic(追求极致性能)
AndroidEmulator emulator = AndroidEmulatorBuilder.for64Bit()
.addBackendFactory(new DynarmicFactory(true))
.build();
// macOS 开发场景:使用 Hypervisor(利用硬件虚拟化加速)
AndroidEmulator emulator = AndroidEmulatorBuilder.for64Bit()
.addBackendFactory(new HypervisorFactory(true))
.build();
// 不指定时,Unidbg 按以下优先级自动选择:
// Dynarmic → Hypervisor → KVM → Unicorn2 → Unicorn
一个类比帮助理解:如果 Unidbg 是一个翻译公司,Backend 就是翻译员。公司接到一份 ARM 文档(SO 代码),需要翻译成本地语言(x86 指令)才能执行。五个 Backend 就是五个翻译员,各有不同的翻译方式和特长:
有的逐字翻译(Unicorn),慢但可以随时停下来解释每个词 有的先通读全篇再意译(Dynarmic),快但翻译过程中不方便打断 有的直接请母语者朗读(Hypervisor/KVM),最快但完全无法插入注释
五个 Backend 的实现原理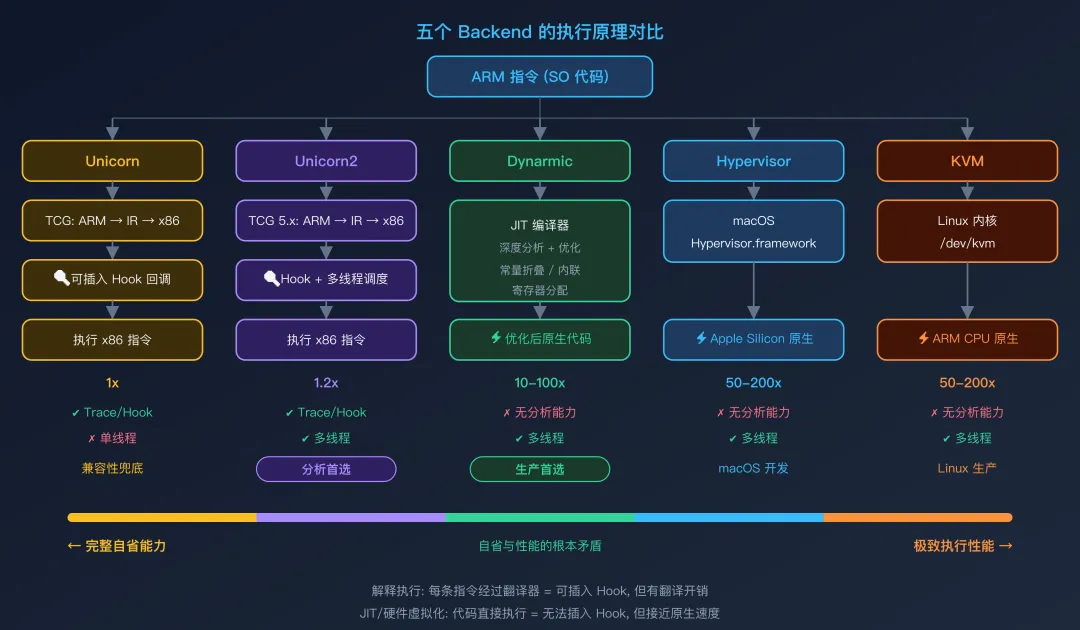
五个 Backend 的执行原理对比
Unicorn:最经典的解释执行
Unicorn 是 Unidbg 最早支持的 Backend,基于 QEMU 的 TCG(Tiny Code Generator)引擎。
工作原理:
Unicorn 的执行方式被称为解释执行(Interpretation)。它以"翻译块"(Translation Block,TB)为单位工作:
从 SO 代码中取出一个基本块(从当前 PC 到下一个分支指令之间的连续指令序列) 将基本块中的每条 ARM 指令翻译为 TCG 中间表示(IR,Intermediate Representation) 再将 IR 翻译为宿主机的 x86 指令 执行翻译后的 x86 指令 翻译结果被缓存在 TB Cache 中,下次执行到同一个基本块时直接复用
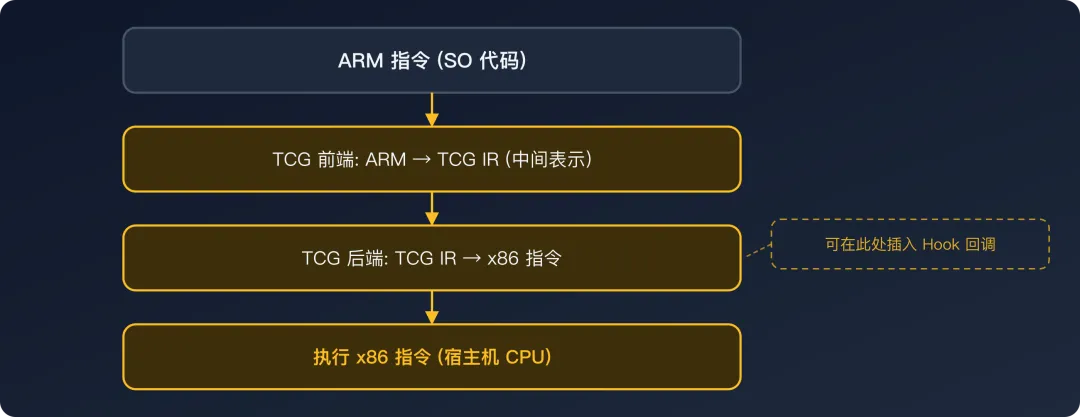
关键特性:
由于每条指令都要经过翻译器,翻译器可以在每条指令的翻译前后插入回调代码。这就是 Unicorn 能支持指令级 Hook 和内存监控的原因 — 它在翻译 ARM 指令为 x86 指令时,可以额外插入一段"在执行这条指令前/后调用用户回调函数"的 x86 代码。
局限:
翻译本身有开销,即使有 TB Cache,每次进入新的翻译块仍需查找缓存 不支持多线程 — Unicorn 的 TCG 翻译器不是线程安全的 基于较老版本的 QEMU(2.x),某些 ARM 指令可能有兼容性问题
适用场景:需要最大兼容性的场景,或作为其他 Backend 不可用时的兜底方案。
Unicorn2:改进版,分析的首选
Unicorn2 是 Unicorn 的重大升级版,基于更新的 QEMU 版本,修复了大量指令模拟的 Bug,并加入了多线程支持。
相比 Unicorn 的改进:
Unicorn2 保留了 Unicorn 的所有分析能力(指令 Hook、内存监控、Trace),同时获得了更好的兼容性和多线程支持。
**为什么是"分析的首选"**:
逆向分析的核心需求是看清楚程序在做什么 — 这需要指令级 Trace、内存断点、寄存器监控 Unicorn2 是唯一同时支持这些分析能力且支持多线程的 Backend 多线程支持解决了 JNI_OnLoad中线程死锁的问题(第二篇提到的经典场景)
适用场景:日常逆向分析、算法还原、补环境调试 — 推荐作为默认 Backend。
Dynarmic:JIT 编译,生产环境的王者
Dynarmic 是一个 ARM 动态重编译器(Dynamic Recompiler),最初为 Nintendo 3DS/Switch 模拟器开发,后被 Unidbg 引入。
工作原理:
Dynarmic 采用 JIT 编译(Just-In-Time Compilation,即时编译)方式工作:
取出一段 ARM 代码(比解释执行的粒度更大,可以跨基本块) 对这段代码做深度优化分析(常量折叠、死代码消除、寄存器分配优化) 一次性编译为高度优化的本机代码 后续每次执行都直接运行编译好的本机代码,不再经过翻译步骤
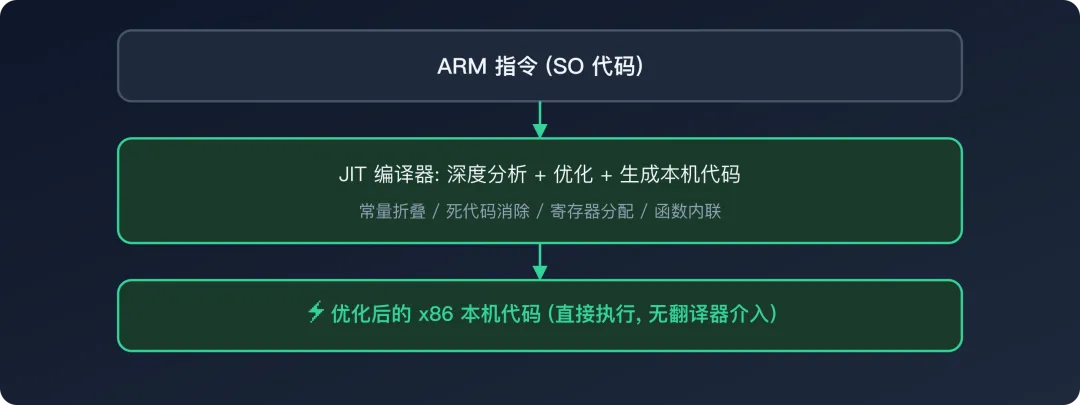
为什么比 Unicorn 快 10-100 倍:
解释执行和 JIT 编译的差异,可以类比为"同声传译"和"提前翻译好的稿件":
Unicorn(同声传译):每句话都要当场翻译。即使同一句话说了十遍,每遍都要重新翻译一次(虽然有 TB Cache,但每次执行到翻译块边界仍有调度开销)。翻译过程中还可以随时打断来做注释(Hook)。
Dynarmic(提前翻译稿件):第一次遇到一段话时,花时间把它翻译并润色成自然流畅的目标语言。之后每次需要这段话,直接照着翻译好的稿件读,速度接近母语者。但翻译好之后不方便再在中间插入注释。
具体到性能差异的来源:
代价:
不支持指令级 Hook — 代码被编译为本机代码后直接执行,没有逐指令翻译的步骤,也就没有地方插入回调 不支持内存监控 — 同理,内存访问指令被编译为直接的 x86 内存操作 不支持 Trace — 无法记录每条指令的执行 编译的"第一次"有延迟(冷启动时间略长)
适用场景:生产环境(高并发签名计算服务)、不需要分析能力的批量调用。
Hypervisor:macOS 独享的硬件加速
Hypervisor Backend 利用 macOS 的 Hypervisor.framework,这是 Apple 提供的用户态虚拟化框架。
工作原理:
在搭载 Apple Silicon(M1/M2/M3/M4)的 Mac 上,CPU 本身就是 ARM 架构。Hypervisor.framework 允许在用户态创建一个轻量级虚拟机,让 ARM 代码直接在硬件上执行,几乎没有翻译开销。
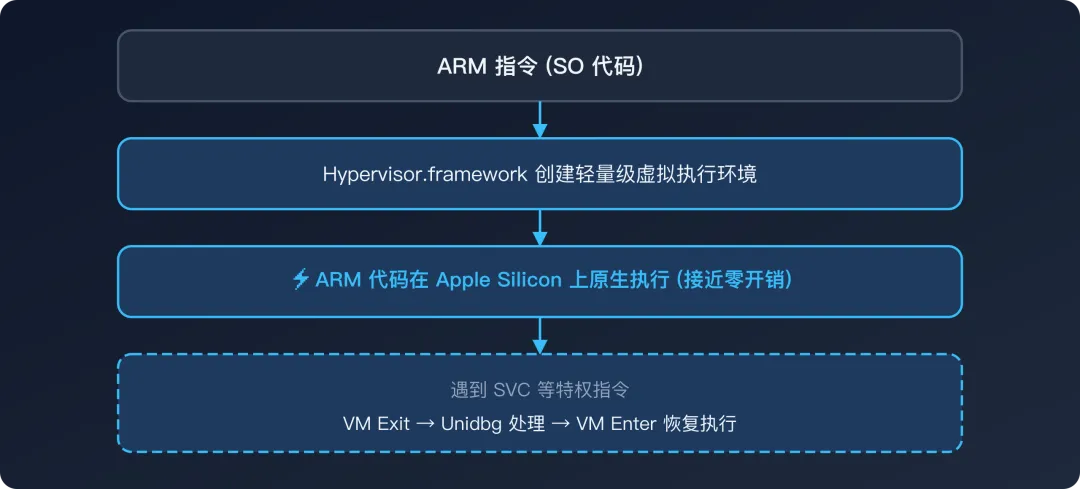
关键细节:
SO 代码中的普通 ARM 指令(计算、内存访问、分支)直接在 CPU 上执行,速度等同原生 当遇到特权指令(如 SVC系统调用)时,CPU 触发 VM Exit,控制权返回 Unidbg,由 Unidbg 处理后再恢复执行因此性能取决于 VM Exit 的频率 — 纯计算代码几乎原生速度,频繁系统调用的代码会有一些开销
限制:
仅支持 macOS + Apple Silicon — Intel Mac 上不可用(因为 Intel Mac 是 x86 架构,不能直接执行 ARM 代码) 仅支持 ARM64 — 不支持 ARM32(32 位 SO) 不支持指令级 Hook、内存监控、Trace 调试能力极有限
适用场景:在 Apple Silicon Mac 上开发和测试 Unidbg 项目时使用。日常开发中切到 Hypervisor 可以大幅缩短等待时间。
KVM:Linux 服务器上的近原生执行
KVM(Kernel-based Virtual Machine)Backend 利用 Linux 内核的虚拟化模块。
工作原理:
与 Hypervisor 类似,KVM 也是利用硬件虚拟化让 ARM 代码直接在 CPU 上执行。区别在于:
KVM 工作在 Linux 系统上 需要 ARM 架构的 Linux 服务器(比如 AWS Graviton、华为鲲鹏、飞腾等 ARM 服务器) 通过 /dev/kvm设备接口创建虚拟机

与 Hypervisor 的对比:
适用场景:在 ARM Linux 服务器上部署 Unidbg 生产服务。如果你的服务器是 ARM 架构(如 AWS Graviton 实例),KVM 是性能最高的选择。
性能实测对比
口说无凭,我们用相同的样本和操作来对比五个 Backend 的真实性能。
测试环境
测试机器:MacBook Pro (Apple M2 Pro, 16GB RAM)
JDK:OpenJDK 17
Unidbg:最新主分支
测试样本:某电商 App 的签名 SO(ARM64,约 2MB)
测试操作:加载 SO + 调用签名函数
测试结果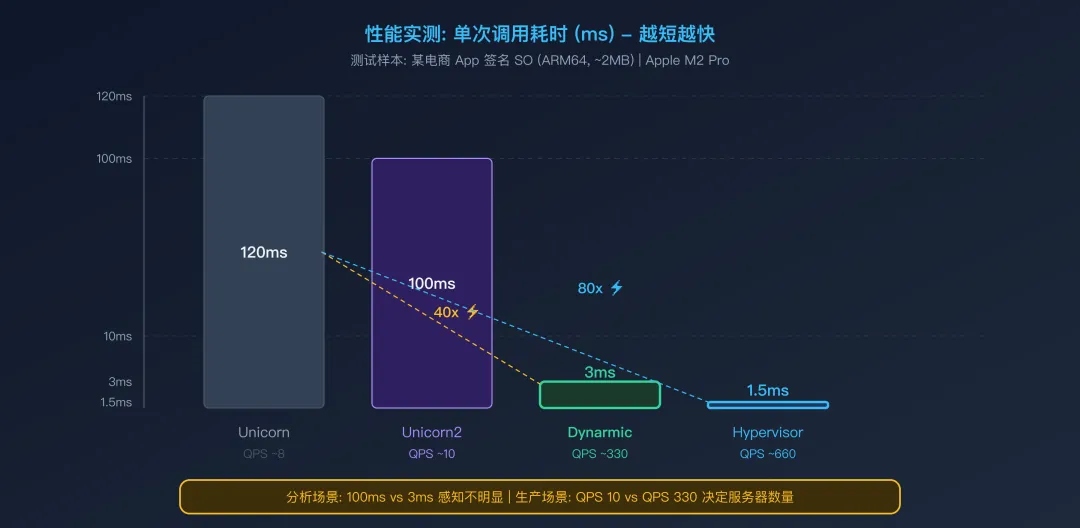
性能实测对比:单次调用耗时
| 冷启动 | ||||
| 单次调用 | ||||
| 吞吐量 | ||||
| 内存占用 |
注:KVM 未在此测试中包含(需要 ARM Linux 环境)。根据社区反馈,KVM 的性能与 Hypervisor 处于同一量级(50-200x Unicorn)。具体数字因 CPU 型号和内核版本而异。
数字背后的含义
冷启动时间(首次加载 SO + 首次调用函数):
Unicorn/Unicorn2 需要翻译大量指令,首次执行较慢 Dynarmic 的 JIT 编译也需要时间,但编译后的代码质量更高 Hypervisor 几乎不需要翻译,启动最快
单次调用耗时(SO 已加载,直接调用函数):
这是最关键的指标。Dynarmic 比 Unicorn 快约 40 倍,Hypervisor 比 Unicorn 快约 80 倍。
对逆向分析来说,100ms vs 3ms 的差异感知不明显(你不会连续调用几千次) 对生产服务来说,这是 QPS 8 vs QPS 330 的差异 — 决定了你需要多少台服务器
吞吐量:
单线程 QPS 330(Dynarmic)意味着一个线程每秒可以完成 330 次签名计算 配合多线程实例池(比如 8 个 Emulator 实例),可以达到 ~2600 QPS Unicorn 的 QPS 8 意味着相同的吞吐量需要 40 倍的实例数
为什么 Dynarmic 如此之快
用一个具体的例子来感受差异。假设 SO 代码中有一个循环执行 AES 加密:
// SO 代码(C 语言伪代码)
for (int round = 0; round < 10; round++) {
state = sub_bytes(state);
state = shift_rows(state);
state = mix_columns(state);
state = add_round_key(state, round_keys[round]);
}
Unicorn 的处理:
这个循环的每次迭代包含约 200 条 ARM 指令。10 次迭代 = 2000 条指令。每条指令都需要:查找 TB Cache → 如果命中则跳转到缓存的翻译结果 → 执行 → 回到调度器。每次 TB 边界切换(分支指令、循环回跳)都有调度开销。
Dynarmic 的处理:
JIT 编译器识别出这是一个循环,将整个循环(包括 10 次迭代中的分支回跳)编译为一段优化过的 x86 代码。优化包括:
把 state变量分配到 x86 寄存器中(避免内存读写)内联 sub_bytes、shift_rows等子函数(消除函数调用开销)展开循环(如果迭代次数较少) 编译后的代码可以直接由 CPU 的分支预测器和缓存系统加速
结果:同样 2000 条 ARM 指令,Dynarmic 编译后可能只有 400 条高质量的 x86 指令,而且没有调度器介入。
能力矩阵:你能做什么取决于你选了谁
性能只是一个维度。另一个同等重要的维度是分析能力 — 即你能对正在执行的代码做多细粒度的观察和干预。
完整能力矩阵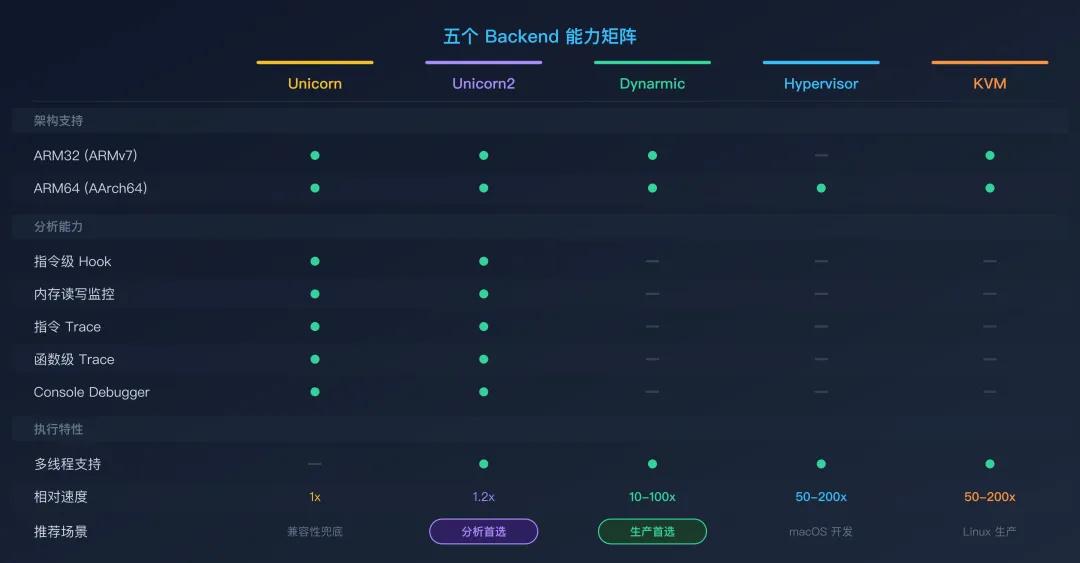
五个 Backend 能力矩阵
三类关键能力详解
指令级 Hook(Code Hook)
指令级 Hook 允许你在每条 ARM 指令执行前或执行后触发一个回调函数。回调中你可以:
查看当前 PC 地址(Program Counter,程序计数器) 读取所有寄存器的值 读取或修改内存内容 决定是否继续执行
// 指令级 Hook 示例 — 仅在 Unicorn/Unicorn2 上可用
emulator.getBackend().hook_add_new(new CodeHook() {
@Override
publicvoidhook(Backend backend, long address, int size, Object user){
// address: 当前执行的 ARM 指令地址
// 每条指令执行时都会触发这个回调
if (address == targetFunctionAddress + 0x1A8) {
// 读取 X0 寄存器(通常存放第一个函数参数或返回值)
long x0 = backend.reg_read(Arm64Const.UC_ARM64_REG_X0).longValue();
System.out.println("关键地址处 X0 = 0x" + Long.toHexString(x0));
}
}
}, beginAddress, endAddress, null);
这个能力对于算法分析至关重要:你可以精确追踪数据在加密算法每一步中的变化。
内存读写监控(Memory Hook)
内存监控允许你在指定内存区域被读取或写入时触发回调:
// 内存监控示例 — 监控密钥缓冲区的读取
emulator.getBackend().hook_add_new(new ReadHook() {
@Override
publicvoidhook(Backend backend, long address, int size, Object user){
// 当密钥缓冲区被读取时触发
byte[] data = backend.mem_read(address, size);
System.out.println("密钥被读取: " + bytesToHex(data));
}
}, keyBufferAddress, keyBufferAddress + keyLength, null);
这对于定位加密密钥存储位置和密钥使用时机非常有用。
Trace(指令追踪)
Trace 记录程序执行的每一条指令,包括地址、反汇编、寄存器变化:
// 开启指令 Trace — 仅在 Unicorn/Unicorn2 上可用
// 参数:起始地址,结束地址(0 表示全范围 Trace)
emulator.traceCode(module.base, module.base + module.size);
输出类似:
0x40001000: mov x0, #0x1 ; X0=0x0 → X0=0x1
0x40001004: ldr x1, [sp, #0x10] ; X1=0x0 → X1=0x7f001234
0x40001008: bl 0x40002000 ; 跳转到子函数
...
一次 Trace 可能产生数百万行输出。分析时通常只对感兴趣的地址范围开启 Trace,配合 IDA/Ghidra 的反汇编结果交叉对照。
自省能力与执行效率的根本矛盾
到这里你可能会问:为什么不能做一个既快又能分析的 Backend?
答案是:自省能力和执行效率存在根本性的矛盾。
"自省能力"(Introspection)是指执行引擎"看到自己在做什么"的能力 — 知道当前在执行哪条指令、即将读写哪个内存地址、寄存器的每一次变化。
要获得自省能力,执行引擎必须在每一步操作中"停下来看一眼"。但"停下来"本身就是开销:
这不是工程能力的问题,而是物理定律的约束:
要观察一个系统,就必须与它交互 与它交互就必然影响它的行为(至少影响它的速度) 观察的粒度越细(指令级 vs 函数级 vs 不观察),影响越大
量子力学的海森堡不确定性原理在这里有一个有趣的类比:你观测得越精确,对被观测系统的干扰就越大。指令级 Trace 给你最精确的执行信息,但也带来最大的性能损失。
这就是为什么 Unidbg 需要五个 Backend 而不是一个"完美的" Backend — 不同的需求需要在这个光谱上选择不同的位置。
决策树:如何选择你的 Backend
综合性能、能力和适用场景,下面是一棵完整的决策树:
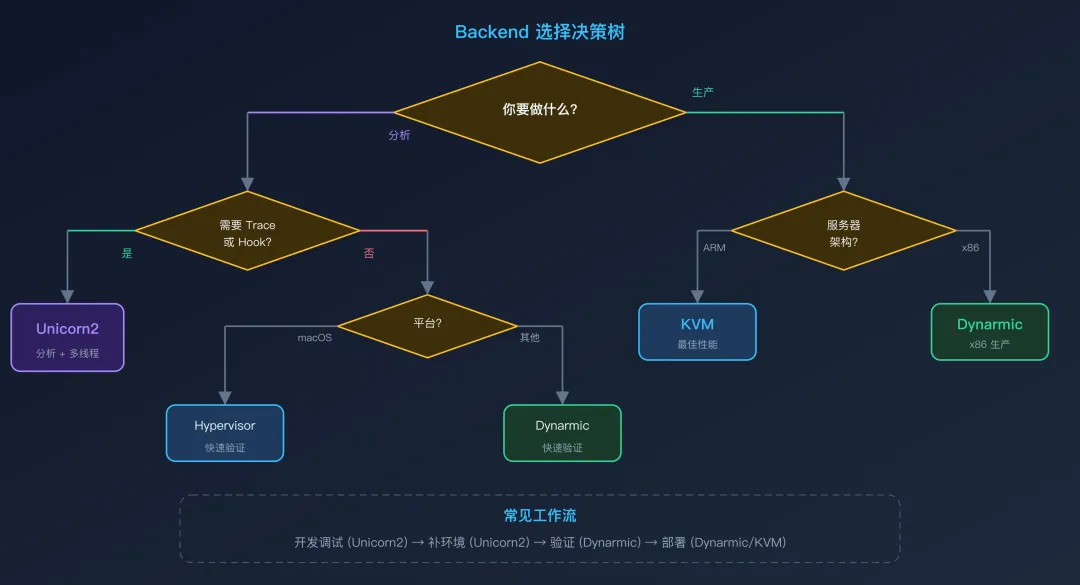
关于 SO 架构的补充说明:如果你的目标 SO 是 ARM32(armeabi-v7a),需要排除 Hypervisor(仅支持 ARM64)。ARM32 的分析用 Unicorn2,生产用 Dynarmic 或 KVM。
实际推荐
对于大多数人:
| Unicorn2 | ||
| Dynarmic | ||
| Hypervisor | ||
| Dynarmic | ||
| Unicorn2 |
一个常见的工作流:
开发调试阶段:用 Unicorn2,开启 verbose 日志,必要时开 Trace 补环境阶段:用 Unicorn2,利用指令 Hook 定位问题 验证正确性:切到 Dynarmic,确认结果一致(排除 Unicorn 的指令模拟差异) 部署生产:用 Dynarmic 或 KVM,配合实例池实现高并发
切换 Backend 的注意事项
Backend 切换很简单(只需要改一行代码),但有几个需要注意的点:
1. 分析代码需要条件编译
如果你的代码中使用了 Trace 或 Code Hook,切换到 Dynarmic/Hypervisor/KVM 时会报错或静默失效。建议用条件判断:
// 仅在支持 Trace 的 Backend 上开启
if (emulator.getBackend() instanceof Unicorn2Backend
|| emulator.getBackend() instanceof UnicornBackend) {
emulator.traceCode(beginAddr, endAddr);
}
// 或者用 try-catch 优雅降级
try {
emulator.traceCode(beginAddr, endAddr);
} catch (UnsupportedOperationException e) {
System.out.println("当前 Backend 不支持 Trace");
}
2. 结果可能有细微差异
不同 Backend 对某些边界情况(浮点精度、未对齐内存访问、特殊指令行为)的处理可能有细微差异。建议在切换 Backend 后重新验证输出结果是否一致。
3. 多线程行为差异
Unicorn:不支持多线程,JNI_OnLoad 中的线程创建会失败或死锁 Unicorn2:协作式伪多线程,大部分情况可工作 Dynarmic/Hypervisor/KVM:更好的多线程支持
如果你在 Unicorn2 上补好了环境,切换到 Dynarmic 后可能因为线程调度行为的差异而出现新问题。通常问题不大,但值得留意。
总结:没有银弹,只有取舍
五个 Backend 不是五个"版本"(1.0、2.0、3.0...),而是五个方向 — 它们在"自省能力"和"执行效率"的光谱上占据不同的位置:
理解这个光谱(参见上方五个 Backend 执行原理对比图底部的频谱条),你就不会问"哪个 Backend 最好",而会问"我现在需要在光谱的什么位置"。
分析时你需要看清每一步 → 选左侧。 生产时你需要跑得快 → 选右侧。 开发中你经常在两者之间切换 → 记住切换只需要改一行代码。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 《政府采购需求管理办法》学习笔记(五)
- 中药之清虚热篇学习笔记
- 2026.4.13更新【免费学习资料大全】,有需自取,均免费分享→
- 学习笔记 丨 进入社会尽量少说话,不管是职场中,还是为人处世
- S4 HANA生产模块学习笔记-评估MRP结果(异常消息)
- 高级经济实务知识产权学习笔记之3#
- 6700字学习笔记 | 个人IP与自媒体变现-学习沙龙
- 【注会CPA】2026注册会计CPA资料+25注会完整版学习资料汇总(注会cpa网课2026+注会资料2026电子版pdf+电子资料)免费分享
- 《道德经》36 国之利器 学习笔记
- 《心电图学习笔记》真假危急值6+2 现象?
