Nano-vLLM 是一个 用于学习原理、做研究原型或者教学演示的轻量级实现,可以更直观地理解 LLM 推理系统是如何工作的,比如请求调度、KV Cache 管理,以及 Prefill / Decode 的推理流程。
先来看下项目的整体结构,核⼼代码在nanovllm关键模块如下:
engine/llm_engine.py :对外API 与推理主循环
engine/scheduler.py:请求调度(批处理、抢占、结束处理)
engine/block_manager.py:KV Cache block 分配器与前缀缓存复⽤
engine/model_runner.py :模型执⾏、上下⽂构造、CUDA Graph、KV Cache 绑定
layers/attention.py :写⼊KV Cache + FlashAttention prefill/decode 路径
models/qwen3.py :Qwen3 模型定义,接⼊并⾏线性层与注意⼒层
推理流程
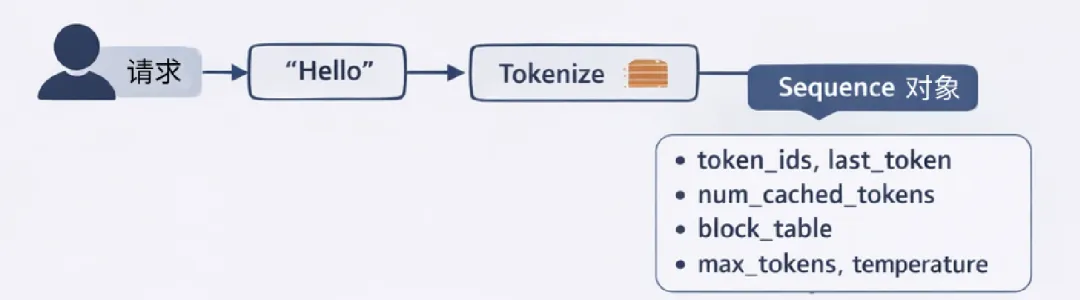
当用户调用 LLM.generate()提交prompt时,系统首先通过tokenizer将文本转换为token id。随后推理框架会创建一个Sequence对象,用于记录该请求在整个生成过程中的状态信息,包括 token 序列、KV Cache映射关系以及采样参数等。最后该Sequence 会被加入 Scheduler.waiting队列,等待调度器在后续步骤中选择执行。
from nanovllm import LLM, SamplingParamsllm = LLM("/path/to/model")outputs = llm.generate(["hello"], SamplingParams())
随后每个请求会被封装成一个 Sequence 对象,并进入调度系统的 waiting 队列。在推理框架内部,Sequence 是一个非常核心的数据结构,它不仅保存当前生成到哪一个 token,还记录该序列在 KV Cache 中对应的 block 映射关系、已经命中的前缀缓存数量、以及采样参数等信息。
推理过程 generate() 函数其内部不断调用 step()执行一次推理循环。每次循环固定包含三个阶段:
首先由 scheduler.schedule()决定本轮需要执行的 batch,并判断当前阶段是 prefill还是 decode。随后 model_runner.run()负责执行模型前向计算,并返回每条序列的新 token。最后 scheduler.postprocess()将生成的 token 回填到对应的 Sequence对象,同时判断是否命中 EOS 或达到最大生成长度,并在必要时释放 KV Cache 资源。
只要系统中仍然存在 waiting 或 running 的序列,主循环就会继续执行,直到所有请求都完成为止。
KV Cache管理
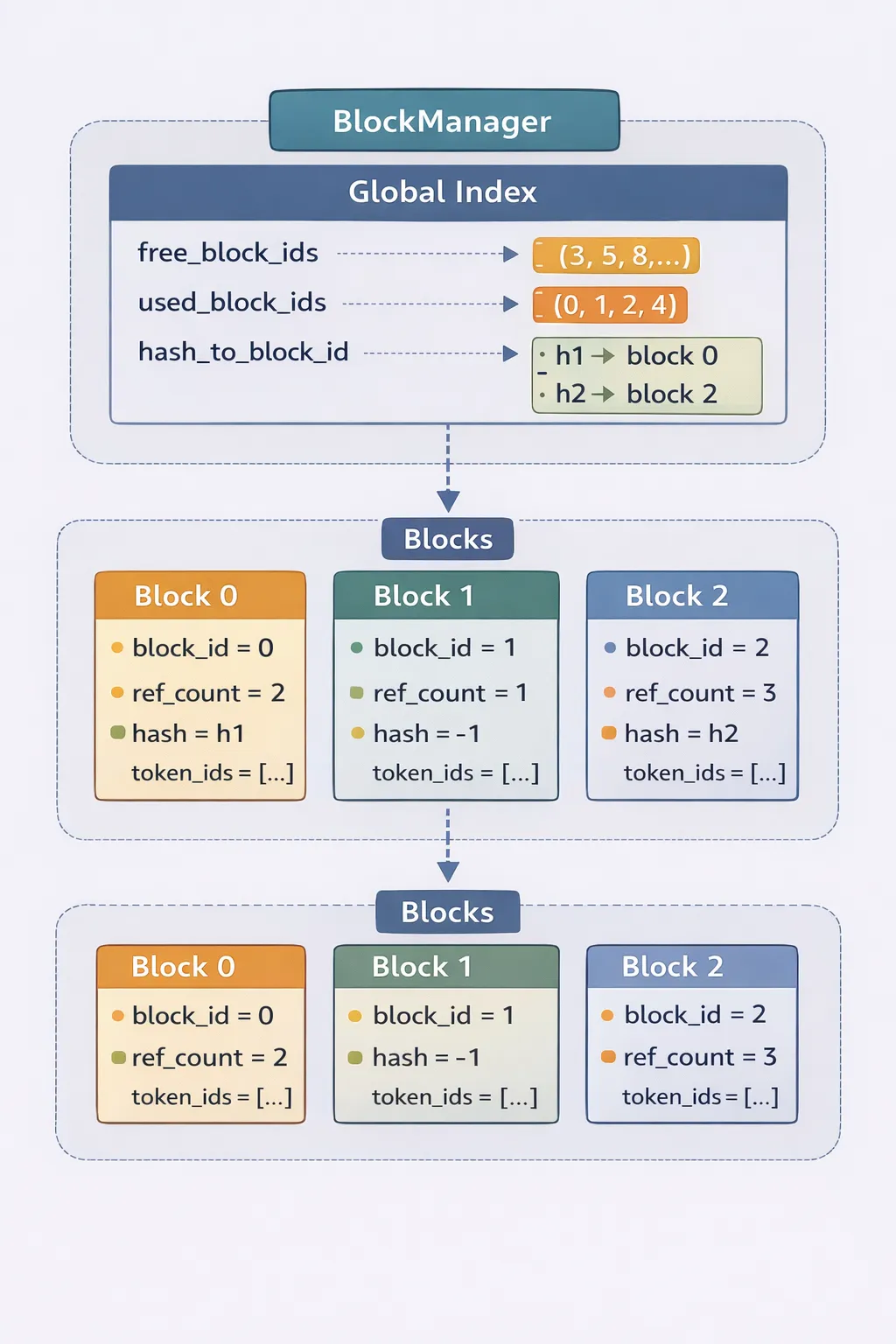
KV Cache 被划分为固定大小的 block,每个 block 维护引用计数、哈希值以及对应的 token 序列。BlockManager通过 free_block_ids、used_block_ids和 hash_to_block_id三个全局索引结构管理所有 block,从而支持高效分配、复用和回收。
当新的请求进入系统时,nano-vLLM 会按 block 计算前缀哈希并查找hash_to_block_id。如果命中并且token序列完全一致,则直接复用已有 block,并增加其引用计数。一旦某个 block 未命中,后续 block 都会重新分配。这种机制允许多个请求共享相同的前缀KV Cache,从而避免重复执行 prefill 计算。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
