学历更高的人收入真的更高吗?
央行加息后,股市会怎么走?
国家出台的试点政策,到底有没有起到效果?
这些我们日常关心的、从个人生活到宏观经济的问题,本质上都是“变量之间的关系验证”。
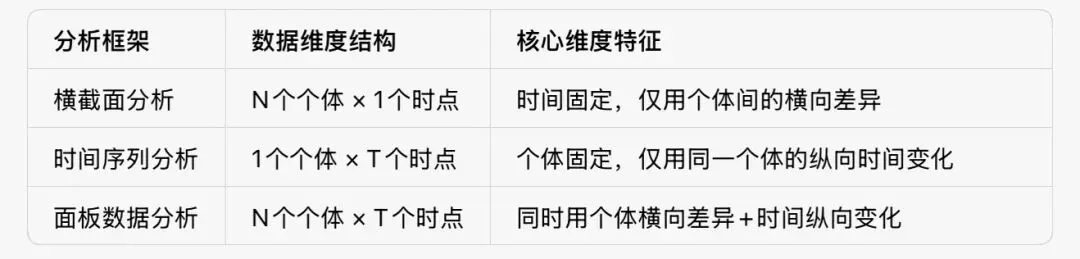
现代量化实证研究中,解决这类问题的三大核心工具,就是:横截面分析、时间序列分析和面板数据分析。
它们共同构成了实证计量研究的基础框架,覆盖了绝大多数实证研究的场景,是所有做量化分析、学术研究的人必须掌握的入门基础。

一、底层逻辑:所有实证数据,都有两个核心维度
1. 截面维度(个体维度):不同的样本个体
比如不同的人、企业、地区、国家。
2. 时间维度:不同的观测时点
比如年、月、日。
三大分析框架,刚好对应了这两个维度的所有可能的组合。
换句话说,你能拿到的任何用于实证分析的结构化数据,都必然属于这三类中的一种,这也是它们能成为“主流基础框架”的核心前提:
下面以“教育对收入的影响”为例,具体拆解三个框架。
二、三大框架逐个拆解:
是什么、解决什么、怎么用
(一)横截面分析:同一时间,比不同
横截面分析是三大框架里最基础、最容易入门的范式。
其核心是固定同一个时间点,对比不同个体的特征差异,验证变量之间的关系。
举个🌰:
想知道“学历高的人收入是不是更高”,可以拿2024年1000个受访者的调研数据进行对比。
这些数据都来自同一个年份,不同个体。
包含每个人的学历、年收入,还有年龄、行业、工作年限这些信息——对比不同学历的人的收入差异,这就是最典型的横截面分析。
其核心逻辑很简单:在同一个时间点,排除了整体经济形势、行业周期这些对所有人都一样的时间因素,只看个体特征的差异带来的结果差异。
适用场景🎬:
单次调研的数据分析:比如消费者行为调研、用户画像分析;
同一时点不同个体的差异研究:比如同一年不同上市公司的绩效对比、不同地区的经济水平差异分析;
实证研究的异质性分析:比如验证同一政策对不同类型企业的影响差异。
优势与局限❓:
优势:数据获取门槛低,单次调研、同一年的统计数据就能做,模型简单直观,容易理解;
局限:很难排除“不可观测的个体差异”,比如没法区分“高学历的人收入高,是因为学历本身,还是因为他天生更聪明、更努力”,内生性风险高,很难做严谨的因果推断。
(二)时间序列分析:同一个体,看变化
如果说横截面分析是“横向比不同”,那时间序列分析就是纵向看变化:
固定同一个体,追踪这个个体在不同时间点的变化,研究变量的动态规律和相互影响。
举个🌰:
还是用“教育对收入的影响”的例子:
追踪同一个人,从他20岁到50岁的所有数据,看他的学历变化(比如本科毕业、读了在职研究生)之后,他的年收入有没有随之增长,这就是时间序列分析的核心逻辑。
它解决的核心问题是,
“同一个体的变量怎么随时间变化,变量之间有没有领先-滞后的影响关系”。
适用场景🎬:
宏观经济研究:比如GDP增长、通货膨胀率的趋势与周期分析;
金融市场研究:比如股价、利率的波动规律,政策对市场的影响时效分析;
单个个体的长期变化研究:比如某家企业的长期经营绩效变化、某个人的职业发展轨迹分析。
优势与局限❓:
优势:可以捕捉变量的动态变化规律,研究长期趋势、周期波动和滞后影响,是宏观经济、金融领域的基础工具;
局限:很难排除“共同时间冲击”的影响,比如你没法区分“这个人读了研究生之后收入涨了,是因为学历的作用,还是因为那几年整个行业都在涨薪”,同时容易受时间趋势、伪回归的干扰。
(三)面板数据分析:两者结合,找因果
面板数据分析是现在实证研究中最主流、最常用的框架,它本质上是前两个框架的结合:
同时追踪多个个体,在多个时间点的观测数据,同时利用个体的横向差异和时间的纵向变化,做更严谨的因果推断。
举个🌰:
还是回到“教育对收入的影响”的例子:
追踪1000个人,从2010年到2024年的年度数据,既可以对比同一个人不同时间的学历和收入变化,也可以对比同一时间不同人的差异。
它可以解决前两个框架的核心缺陷:
通过“个体固定效应”,把“天生聪明、性格特质”这些不随时间变化的个人固有差异剔除掉;通过“时间固定效应”,把“经济形势、行业周期”这些对所有人都一样的时间冲击剔除掉,最终得到“教育本身对收入的净因果效应”。
双重差分法(DID)、合成控制法、事件研究法这些顶刊常用的因果识别方法,都是面板数据分析框架下的衍生方法。
适用场景🎬:
政策效果评估:比如自贸区试点、环保政策的实施效果验证;
严谨的因果推断研究:比如企业治理结构对绩效的影响、教育的回报率测算;
同时包含个体差异和时间变化的所有研究场景,是目前实证研究的主流载体。
优势与局限❓:
优势:结合了前两个框架的优势,同时弥补了两者的核心缺陷,可以有效剔除混淆因素,实现更可信的因果识别,是现代因果推断的核心工具;
局限:数据获取难度高,需要长期追踪多个个体的面板数据,模型设定更复杂,对分析能力的要求更高。
三、三者的关系:互补递进的完整体系
这三个框架是不是越复杂越好?
面板数据一定比另外两个高级?
其实不是,它们不是孤立的、有高低之分的方法,而是底层逻辑一致、能力互补、应用场景递进的完整体系。
1. 底层逻辑一脉相承:三个框架的核心都是基于经典的回归分析,底层的统计理论完全一致,只是针对不同的数据结构做了适配调整,学习路径是完全连贯的。
2. 能力上互补递进:横截面和时间序列是单维度的基础框架,解决基础的关联问题;面板分析是双维度的进阶框架,解决更严谨的因果识别问题,三者覆盖了从入门级的描述性分析,到顶刊级的因果推断的全流程实证需求。
如果只是想研究某一年不同地区的消费差异,横截面分析就完全够用;
如果想研究中国经济的周期波动规律,时间序列分析是更合适的工具;
如果想严谨地验证一个政策的效果,面板分析是最优选择。
四、常见误区
1. 误区1:横截面分析只能做相关性,不能做因果推断
横截面分析同样可以做因果推断,只是需要通过工具变量、随机对照试验(RCT)数据等识别策略,解决内生性问题,只是难度比面板分析更高。
2. 误区2:面板数据一定比另外两个框架更高级、更好
方法的好坏取决于研究问题和可获得的数据,适合的才是最好的,强行用复杂的面板模型解决简单的问题,反而会画蛇添足。
3. 误区3:加了控制变量就能解决所有内生性问题
控制变量只能解决可观测的混淆因素,无法解决不可观测的遗漏变量、反向因果等问题。
要得到可信的因果效应,需要更严谨的识别策略,而不是只靠加控制变量。