一、接入千问大模型
1 阿里云的千问地址
https://bailian.console.aliyun.com/cn-beijing/?tab=model#/api-key
2 获取apiKey
右侧菜单栏API KEY里创建api key,这个key不能泄露,因为千问的免费token是有额度的,用完就收费了,泄漏了可能别人拿着这个key偷偷把你额度用完,我这里改了这个key,是无效的:
sk-212d409edfwd785f1rwgrre2de12db0
3 安装OpenAI库
通过pip安装
pip install openai
云服务器安装Python3和pip
cd /usr/local/apt install python3-pip python3-dev -ypip3 install openai
查看安装路径
root@VM-0-11-ubuntu:/usr/local# which python3/usr/bin/python3root@VM-0-11-ubuntu:/usr/local# python3 -m sitesys.path = ['/usr/local','/usr/lib/python310.zip','/usr/lib/python3.10','/usr/lib/python3.10/lib-dynload','/usr/local/lib/python3.10/dist-packages','/usr/lib/python3/dist-packages',]USER_BASE: '/root/.local' (doesn't exist)USER_SITE: '/root/.local/lib/python3.10/site-packages' (doesn't exist)ENABLE_USER_SITE: True
4 阿里云的示例代码
访问大模型服务平台百炼控制台网站,在模型广场选择模型,下方可以看到代码案例
fromopenaiimportOpenAIimportosclient = OpenAI(# 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx"api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)messages = [{"role": "user", "content": "你是谁"}]completion = client.chat.completions.create(model="qwen3-max", # 您可以按需更换为其它深度思考模型messages=messages,extra_body={"enable_thinking": True},stream=True)is_answering = False# 是否进入回复阶段print("\n"+"="*20+"思考过程"+"="*20)forchunkincompletion:delta = chunk.choices[0].deltaifhasattr(delta, "reasoning_content") anddelta.reasoning_contentisnotNone:ifnotis_answering:print(delta.reasoning_content, end="", flush=True)ifhasattr(delta, "content") anddelta.content:ifnotis_answering:print("\n"+"="*20+"完整回复"+"="*20)is_answering = Trueprint(delta.content, end="", flush=True)messages定义了提示词,client.chat.completions.create返回回答。
可以直接用python运行,可以看到输出大模型的回答。
5 Ollama简介
阿里云是云端部署和调用大模型,免费额度用完需要付费,Ollama可以在本地部署和管理大模型,使得大模型跑在本地,需要自己电脑硬件性能好。可以使得开发人员不用关心大模型怎么运行怎么调用。
Ollama支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。
ollama地址:ollama.com,打开models查看支持的模型。
ollama提供命令行访问和RestFul Api访问大模型
ollama是什么?
是一款旨在简化大语言模型在本地部署的运行的开源软件。
6 Ollama的部署
只需要进入官网点击download就可以下载安装。
安装完成后,可以选择模型直接本地运行,本地一般选择蒸馏模型。
蒸馏模型就是对原先的大模型的一个简化版本,具备原先模型的简化功能,可以在本地跑,但是也需要性能,显卡没有8g内存都跑不动。
这里为什么需要用显卡内存,因为GPU适合向量运算和矩阵运算这种大量重复运算,适合大规模运算,CPU核心少不适合大量相同任务运算。
这里有个坑,本地下载十分慢,还需要显存比较大,我就没下载只了解。
代码调用方式和之前千问案例是一样的,改下url和模型就行了,能安装的就选蒸馏模型跑就完事了,qwen3:4b类似这种模型,4b是可选参数的意思,表示需要4g显存。
fromopenaiimportOpenAIimportosclient = OpenAI(# 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx"api_key=os.getenv("DASHSCOPE_API_KEY"),base_url="https://localhost:11434/v1",)messages = [{"role": "user", "content": "你是谁"}]completion = client.chat.completions.create(model="qwen3:4b", # 您可以按需更换为其它深度思考模型messages=messages,extra_body={"enable_thinking": True},stream=True)is_answering = False# 是否进入回复阶段print("\n"+"="*20+"思考过程"+"="*20)forchunkincompletion:delta = chunk.choices[0].deltaifhasattr(delta, "reasoning_content") anddelta.reasoning_contentisnotNone:ifnotis_answering:print(delta.reasoning_content, end="", flush=True)ifhasattr(delta, "content") anddelta.content:ifnotis_answering:print("\n"+"="*20+"完整回复"+"="*20)is_answering = Trueprint(delta.content, end="", flush=True)7 什么是transformer
之前看大模型说到transformer,就查了下是什么,说是所有模型计算的底层架构,本质是一个神经网络结构。
然后又说这个叫注意力机制,我又查了什么叫注意力机制,是根据向量点积算相似度,得出词语之间的关系。让模型看到一句话就知道重点关注哪几个词,把每个词变成一个向量,通过向量点积计算两个词的相似度,相似度越高权重越大,最后按权重把向量加权求和,得到“带重点”的新向量。
我又查了为什么要用向量运算和矩阵运算,是怎么计算文本相似度的,上面是把文本转成向量,本质上是计算数字,得到相关性,大模型每生成一个字,都要做几百万次这种运算,GPU正好适合这种计算,几十上百层的神经网络都在做向量乘以权重矩阵得到新向量,不断的压缩,提炼信息特到更高维度的特征向量,一个字一个字的预测下一个字的生成。
上面又说了特征向量,我又去查特征向量,说是把特征变量比如:语义、词性、情感、关联度等等转成特征向量,用来理解语义预测下一个字。
总结来说应该就是把文本转向量数字,通过向量之间关联性计算文本之间的关联性。
二、OpenAI库的基础使用
1 获取client对象
client = OpenAI( # 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx" api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://localhost:11434/v1",)2 调用模型
completion = client.chat.completions.create( model="qwen3:4b", # 您可以按需更换为其它深度思考模型 messages=messages, extra_body={"enable_thinking": True}, stream=True)主要参数:
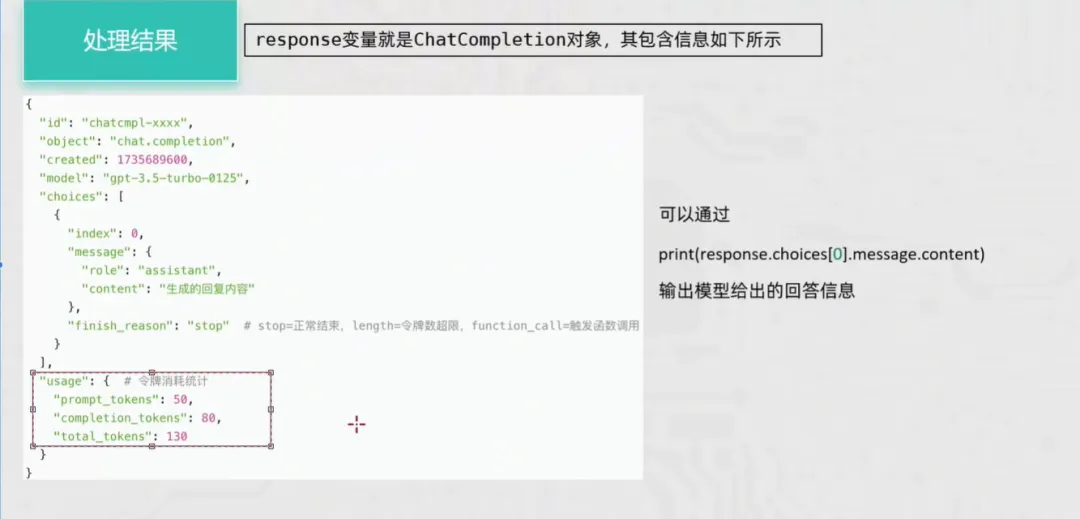
3 处理结果
这里的response是上面例子的completion。
4 总结
openai是Open ai公司发布的python SDK,方便与编程调用其产品,现许多模型服务商都兼容OpenAI SDK的调用。SDK全称software development kit(软件开发工具包)。
使用主要就三个流程
创建客户端对象
和模型对话,可以提供三个角色使用
system:设定模型的行为和规则
assistant:设定模型的回答,用户设定
user:用户的提问
处理结果
OpenAI库的流式输出
设置参数stream等于true,输出会变成一段一段的,end=""结束符表示输出之间用什么间隔,flush=True表示立刻刷新缓冲区直接输出,防止输出被输出到缓冲区没出现。
client = OpenAI( # 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx" api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)messages = [ {"role": "user", "content": "你是谁"}, {"role": "system", "content": "你是一个java编程专家,有良好的编程思维和丰富的系统设计经验"}, {"role": "assistant", "content": "嗯,你说的对"}]completion = client.chat.completions.create( model="qwen3-max", # 您可以按需更换为其它深度思考模型 messages=messages, extra_body={"enable_thinking": True}, stream=True)print("\n" + "=" * 20 + "思考过程" + "=" * 20)for chunk in completion: delta = chunk.choices[0].delta print(delta.content, end="", flush=True)附带历史消息调用模型
调用模型传入的参数是messages,其要求是list对象,即表明其支持非常多的消息在内,我们可以基于此,将历史消息填入,让模型知晓对话的上下文,更好的回答。
client = OpenAI( # 如果没有配置环境变量,请用阿里云百炼API Key替换:api_key="sk-xxx" api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",)messages = [{"role": "system", "content": "你是一个ai助手,回答很简洁"}, {"role": "user", "content": "小明爱唱歌"}, {"role": "assistant", "content": "好的"}, {"role": "user", "content": "小红今天吃了一顿饭"}, {"role": "assistant", "content": "好的"}, {"role": "user", "content": "谁爱唱歌?"}]completion = client.chat.completions.create( model="qwen3-max", # 您可以按需更换为其它深度思考模型 messages=messages, extra_body={"enable_thinking": True}, stream=True)print("\n" + "=" * 20 + "思考过程" + "=" * 20)for chunk in completion: delta = chunk.choices[0].delta print(delta.content, end="", flush=True)