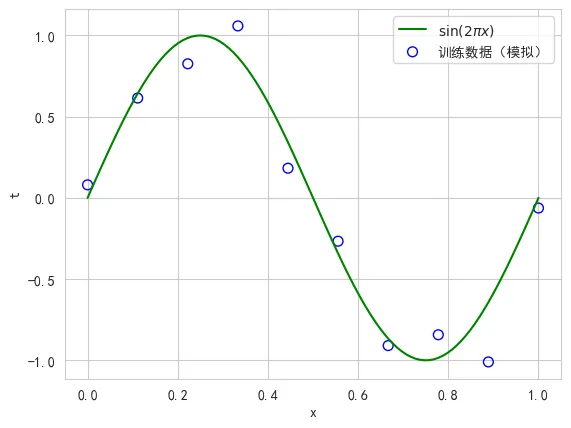
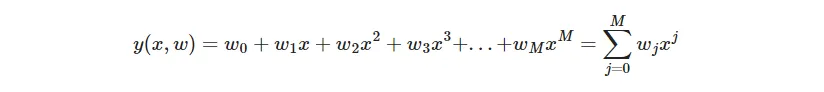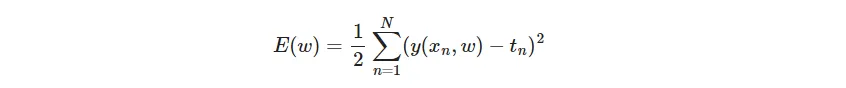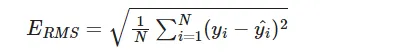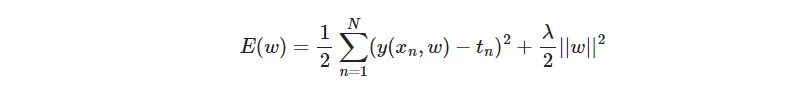被称为机器学习圣经的《模式识别与机器学习》(简称PRML)一书中以一个简单的多项式曲线拟合为例开展模式识别的相关概念的阐述,示例虽简单背后反应的思想却是一样的,因此不仅要读懂,最好还能好好动手实践一番,这样才能对概念背后的原理有更深入的理解。所谓模式识别就是使用计算机程序从已知数据集中学习数据背后的规律,并用于预测未知数据的目标值。预测未知数据才是模式识别的根本目的,这被称为模型的“泛化”能力,可见具有良好泛化能力的模型才是我们追求的目标。示例使用一个人工构造的sin(2πx)加入少量的高斯噪声作为训练数据,这样做的好处是已经事先知道了数据背后的规律(就是正弦曲线sin(2πx)),使得我们可以很好的评估拟合的效果。生成模拟数据
可以使用numpy和matplotlib实现样本数据的生成和曲线绘制,其中np.random.normal为随机高斯分布方法,scale参数为标准差。from matplotlib import pyplot as pltimport seaborn as snssns.set_style("whitegrid")plt.rcParams["font.family"] = ["SimHei"] # 多字体备选plt.rcParams["axes.unicode_minus"] = False # 解决负号问题生成理想曲线的数据样本x = np.linspace(0, 1, 100)y = np.sin(2 np.pi x)生成加入指定标准差的高斯噪声的模拟训练样本x_train = np.linspace(0, 1, 10)np.random.normal(loc=0, scale=1, size=x_train.shape) loc为均值,scale为标准差y_train = np.sin(2 np.pi x_train) + np.random.normal(scale=0.25, size=x_train.shape) 绘制理想曲线plt.plot(x, y, color='g', label="\sin(2\pi x)")绘制训练数据样本散点图plt.scatter(x_train, y_train, s=50, edgecolors='b', facecolors='none', label="训练数据(模拟)")plt.xlabel("x")plt.ylabel("t")plt.legend()
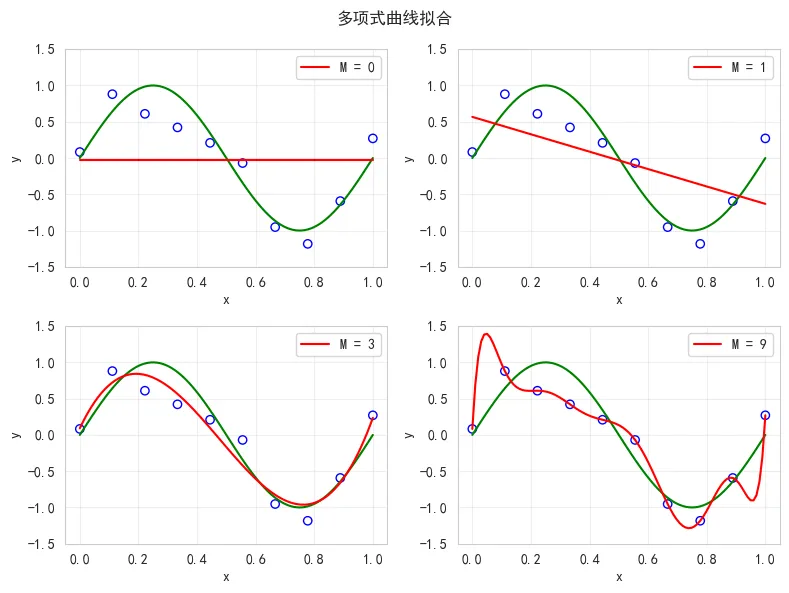
不同阶数曲线拟合结果
可以使用多项式函数来拟合这个曲线,其中M是多项式的阶数,M=0函数曲线就是一个水平直线、M=1函数曲线是一个斜率为w1的直线、M=2函数曲线是一个抛物线,这些都是我们熟知的函数曲线,显然要模拟近似正弦曲线至少需要阶数M>=3,这个阶数属于超参数需要事先指定好。显然我们的目标就是求出多项式的系数w,因为我们已经知道理想曲线是什么,当然也就知道目标值(有参考目标的学习过程称为监督学习),一种自然的思路是根据已知(x,y)的模拟数据求解平方和误差函数最小情况下的w值,这就是最小二乘法,求解这个方式涉及求偏导,这里不做展开,求解多项式系数w的过程就是在进行模型训练。scikit-learn已经封装了多项式求解的方法,以下代码分别实现了多项式阶数为0、1、3、9四种情况下的曲线拟合效果。from sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegressionsklearn要求输入的特征矩阵为二维(样本数,特征数)xtrain = x_train.reshape(-1, 1)y_train = y_train.reshape(-1, 1)fig = plt.figure(figsize=(8, 6))fig.suptitle("多项式曲线拟合")for i, degree in enumerate([0, 1, 3, 9]):# 2 行 2 列plt.subplot(2, 2, i + 1)# PolynomialFeatures负责实现多项式函数:相当于把输入x转换为各次方的值,如x^0、x^1、...poly = PolynomialFeatures(degree=degree)x_train_poly = poly.fit_transform(x_train.reshape(-1, 1))# 利用线性模型训练,其实就是根据最小二乘求解多项式系统wmodel = LinearRegression()model.fit(x_train_poly, y_train)# 打印多项式系数features_name = [f"w{i}" for i in range(model.coef.size)]print(f"\n多项式阶数 M = {degree}")for w, v in zip(featuresname, model.coef[0]):print(f"{w if w!="1" else "w0"} = {v}")# 预测结果x_test = np.linspace(0, 1, 100).reshape(-1, 1)x_test_poly = poly.transform(x_test)y_predict = model.predict(x_test_poly)# 绘制理想曲线plt.plot(x, y, color='g')# 绘制训练数据散点图plt.scatter(x_train, y_train, facecolor='none', edgecolor="b")# 绘制预测值曲线plt.plot(x_test, y_predict, color='r', label=f"M = {degree}")plt.ylim(-1.5, 1.5)plt.xlabel("x")plt.ylabel("y")plt.legend()plt.grid(alpha=0.3)plt.tight_layout()plt.show()
运行结果示例如下,显然M=3情况下曲线拟合效果最好,而M=9虽然所有曲线都经过了训练数据,训练误差为0,这是因为阶数越高控制能力越强,但是预测未知数据显然是差的,这就是过拟合问题。多项式阶数 M = 0w0 = 0.0多项式阶数 M = 1w0 = 0.0w1 = -1.1993101218628495多项式阶数 M = 3w0 = 0.0w1 = 8.53834791221029w2 = -27.822934601311594w3 = 19.428480131913982多项式阶数 M = 9w0 = 0.0w1 = 73.33144166977539w2 = -1427.6779856267246w3 = 12194.370607823726w4 = -56836.95444500933w5 = 156517.494913042w6 = -260895.32561547981w7 = 257873.71638993613w8 = -138774.10789772362w9 = 31275.340430983375
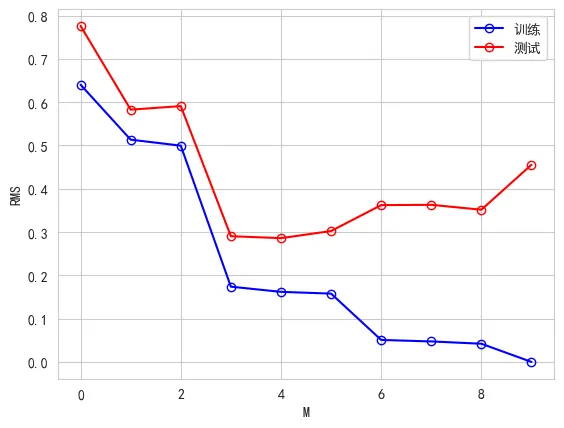
误差曲线
均方根误差曲线RMS定义如下,它类似上面平方和误差的均值我们可以绘制不同阶数下的RMS曲线来直观感受训练误差和预测误差的变化情况,阶数越高训练误差越小,但是由于出现过拟合的问题导致泛化能力变差,测试误差在阶数大于4之后出现了变大的情况。不同阶数M对应的均方根误差曲线RMSdef rms(y_i, y_r):return np.sqrt(np.mean(np.square(y_i - y_r)))x_test = np.linspace(0, 1, 100).reshape(-1, 1)测试数据的目标值np.random.seed(42)y_test = np.sin(2np.pix_test) + np.random.normal(scale=0.25, size=x_test.shape)不同阶数M的模型训练与预测rms_train = []rms_pred = []M_list = list(range(0, 10))for M in M_list:poly = PolynomialFeatures(degree=M)model = LinearRegression()# 训练模型,就是多项式系统wmodel.fit(poly.fit_transform(x_train.reshape(-1, 1)), y_train)# 求测试集均方根误差y_pred = model.predict(poly.fit_transform(x_test))rms_pred.append(rms(y_test, y_pred))# 求训练集均方根误差y_pred_train = model.predict(poly.fit_transform(x_train))rms_train.append(rms(y_train, y_pred_train))训练集误差曲线plt.plot(M_list, rms_train, 'o-', color="b", ms=6, mfc="none", label="训练")测试集误差曲线plt.plot(M_list, rms_pred, 'o-', color="r", ms=6, mfc="none", label="测试")plt.legend()plt.xlabel('M')plt.ylabel('RMS')
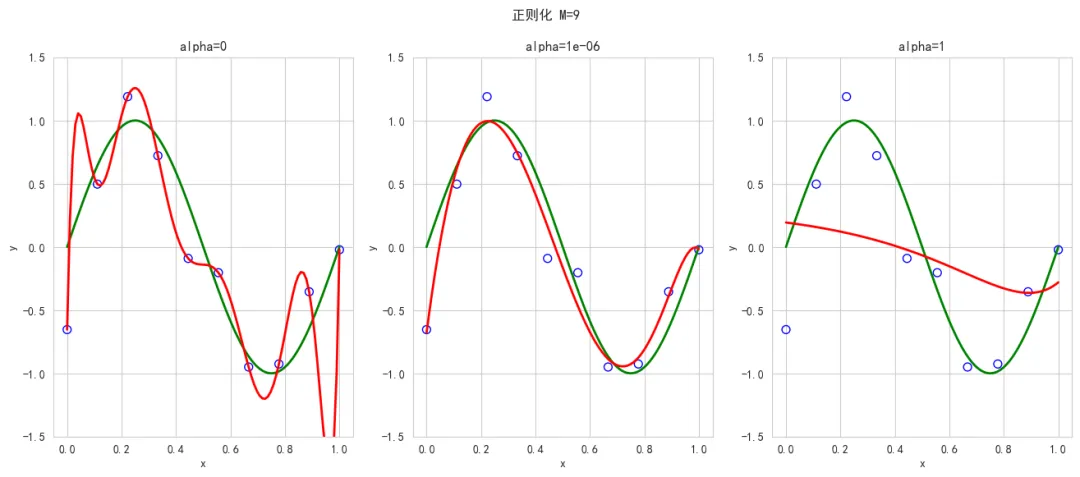
过拟合与正则化
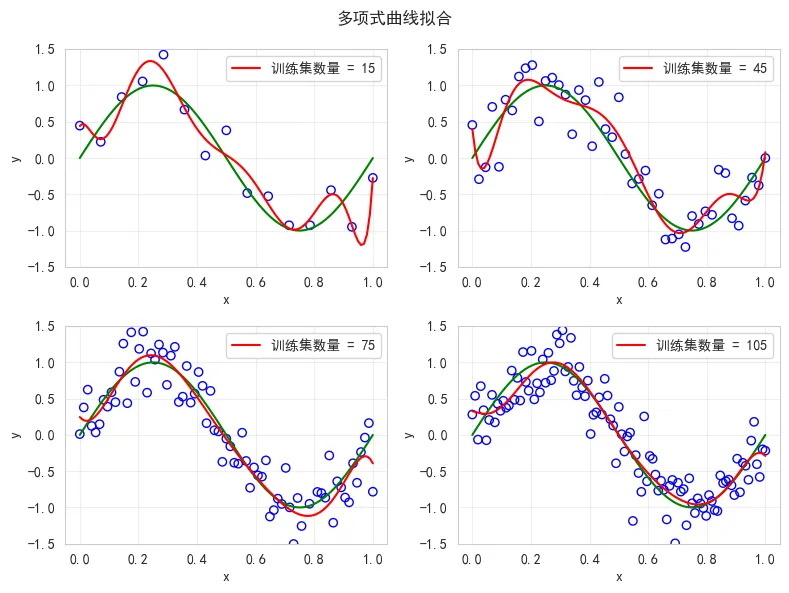
根据前面的结果可以发现M=9的拟合曲线对应的多项式系数w波动特别大,这是出现过拟合的一个典型特征,抑制过拟合问题就可以通过抑制多项式的系统w的波动来实现,有两个方法可以达到这个效果。一个是增加训练数据的样本数,下图是测试了训练数据不断增加情况下M=9曲线拟合的变化(可以参考前面曲线拟合的代码自行修改验证),显然随着训练数据的不断增加拟合的效果也越来越好。但是现实中,增加训练数据往往并不容易做到,存在客观现实的制约。另一种方式在平方和误差函数中加入惩罚项以抑制系数w的大幅变化,这种技术称为正则化。其中λ用来控制惩罚项的影响效果,如下代码基于正则化实现了不同系统下对M=9曲线过拟合的抑制效果,alpha类似于系数λ,显然值越大对过拟合的抑制效果越明显,但显然并不是越大结果越好。from sklearn.linear_model import Ridgex_train = np.linspace(0, 1, 10).reshape(-1, 1)y_train = np.sin(x_train 2 np.pi) + np.random.normal(scale=0.3, size=x_train.shape)x = np.linspace(0, 1, 100).reshape(-1, 1)y = np.sin(x 2 np.pi)fig = plt.figure(figsize=(16, 6))fig.suptitle("正则化 M=9")正则化项系统alphas = [0, 1e-6, 1] # 1e-6 = 1 * 10^(-6)for i, alpha in enumerate(alphas):plt.subplot(1, 3, i + 1)plt.title("alpha={}".format(alpha))plt.scatter(x_train, y_train, s=50, edgecolors='b', facecolors='none')plt.plot(x, y, 'g-', lw=2)poly = PolynomialFeatures(degree=9, include_bias=False)model = Ridge(alpha=alpha)# 训练模型model.fit(poly.fit_transform(x_train), y_train)# 绘制预测曲线y_pred = model.predict(poly.fit_transform(x))plt.plot(x, y_pred, 'r-', lw=2)plt.ylim(-1.5, 1.5)plt.xlabel("x")plt.ylabel("y")
参考文献
1.《模式识别与机器学习》中文版,1.1 示例:多项式曲线拟合,第3页。