备注
我对编程一无所知,对计算机这类专业知识更是陌生。近来尝试涉足此领域,却发现因根基浅薄,只能摸索前行,时常连前一步如何走过都已模糊。于是提笔记下点滴,权作备份。以我眼下所能触及的层次,AI对研究的辅助尚处几乎不可用的境地,参考意义寥寥。倘若偶有路过的网友瞥见此文,还望不吝赐教,指点迷津。(此为AI润色的文绉绉版)
基本思路:本地数据库+云端大模型api
实现平台:CherryStudio
主要思路:源文件(PDF、epub、md、docx、txt等)→文档预处理→嵌入式(embedding)模型进行向量化→云端大模型问答
源文件
即用以构建数据库的文档。其中,PDF、epub是较为常见的电子书格式。而md(即markdown)、docx是常见的笔记文件格式。当然,有时可能也会涉及到图片或者其它文件格式,但比较少见,我暂时未实践过。
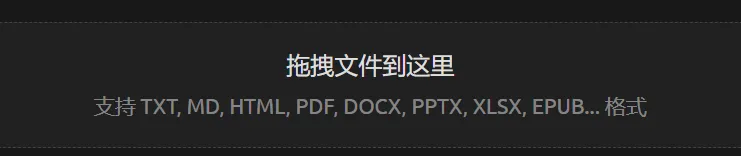
根据官方介绍,CherryStudio支持的文件格式包括TXT, MD, HTML, PDF, DOCX, PPTX, XLSX, EPUB等,理论上来说,这些格式的文档均可以直接导入到CherryStudio,通过平台接入的工具直接完成后续环节,而用户只需要等待处理完成,便可以直接进入到最终环节,即基于知识库的问答。
但在实践过程中,往往会出现很多问题,这就涉及到下一个环节。
注意:doc格式是不被CherryStudio支持的,需要手动另存为docx格式才行。否则,虽然显示上传成功,但进行问答时,CherryStudio无法从中获得任何有效数据。
文档预处理
如前所述,凡是官方写明支持的文档格式,理论上来说均可以直接导入至CherryStudio的知识库中。
对于不支持的文档格式,则需要通过其它方式转换为这几类文档。如azw3、mobi等格式或许可以通过calibre转换为epub。
注意:doc格式也是不被calibre支持的,如果想用calibre转换为其它格式,也需要先手动另存为docx格式才行。
对于受支持的文档格式类型,CherryStudio也并非开箱即用:
md、txt、HTML、docx等几类格式的文件,只需要配置嵌入式(embedding)模型便可。(将在下一个环节涉及)
PDF、EPUB等往往需要依赖文档处理服务商进行预处理,才能更好地被嵌入式模型处理。其中,扫描版PDF,即文字不可复制的图片型PDF,必须依赖文档处理服务商的预处理,否则完全不可用。
PPTX, XLSX可能也需要依赖文档处理服务,但我目前并未用过,暂且不论。
文档的预处理环节,可以分为两种途径:
【1】CherryStudio内部配置文档处理服务商。这种方式优点是方便,一旦配置好,即可将上述所有受支持的文档类型直接上传到CherryStudio的知识库,知识库会自动走完处理流程。但缺点是不稳定,很容易失败。
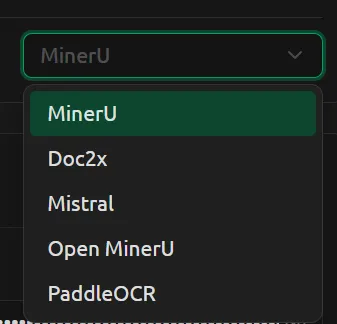
文档处理服务商的配置方式:CherryStudio平台中,点击设置,选择文档处理一栏,选择对应的文档处理服务商,并根据要求配置相关参数。下面介绍几种我用过的。
MinerU:这是通过MinerU提供的api服务接入,用户可前往(https://mineru.net/)申请api,完全免费,但需要填写一份申请表,审批应该是全自动的,很快就通过了。每人每天可以解析1000份文档,并有2000页的优先解析额度,超过额度可能会需要排队。申请之后,回到CherryStudio,填入网页提供的api密钥,api地址填https://mineru.net即可。这一方式优点是解析速度快,缺点是不稳定,可能会出现解析错误或者返回的解析结果是空的(表现为问答时检索不到任何内容)。处理大文档时尤其如此,处理小文档如十几页的论文,则一般没问题。
Open MinerU:即将MinerU部署到电脑本地,部署过程较为复杂,虽然我成功了,但暂时无法将整个过程讲明白。这一方案的优点是没有额度限制,跑在电脑本地可能也更稳定。缺点是部署麻烦,且每一次电脑开机后需要手动启动服务;另外,这一方案对电脑性能要求较高,如果是纯CPU运行,解析一页PDF大概需要六七分钟,这也是我基本放弃这一方案的原因。(据说带独显的电脑处理速度很可观,等我攒钱买个电脑再来测试。)
PaddleOCR:这是百度提供的开源OCR大模型,据说MinerU也是基于这一模型。PaddleOCR实际上也包括云端api和本地部署两种方案,但在CherryStudio中没有单独的选项。
- 用户可以通过(https://aistudio.baidu.com/paddleocr)申请api,流程与MinerU很相似。申请通过以后,PaddleOCR提供VL1.5、VL、V5、V3等几个版本的模型可供调用,每个模型每天有6000页解析额度,但单个文档限100页,否则超出部分不解析。所有大模型的访问令牌(Access Token)是共用的,但API URL各不相同,用户可以在每个模型下面的同步解析代码中找到开头为“API_URL =”“TOKEN =”两行代码,等号后面的就是需要填入到CherryStudio的内容。
- 本地部署PaddleOCR我目前尚未成功过,暂不介绍。
使用方式:在设置中配置好以后,即可在知识库中调用。CherryStudio的知识库界面还有个单独的设置按钮,点进设置-高级设置,即可选择需要调用的文档处理服务商。因为文档预处理是一次性的,只在导入文档时才会调用,所以知识库建立以后,文档处理服务商可以随时更换。
【2】特殊情况:对于大型PDF文档,上述API模式失败率几乎百分之百,(也可能是我运气不好),本地部署又对电脑性能、编程能力要求较高。故替代方案就是将预处理环节独立到CherryStudio之外单独进行,再将处理好的文档导入到CherryStudio知识库中。
MinerU客户端:这是我目前认为处理大型PDF的最佳方案,速度快、稳定、准确率高,且似乎没有额度限制,不过有时候可能需要排队。MinerU处理后会直接生成md格式文档,到对应文件夹中即可找到。不过它对一些繁体竖排估计的处理不是特别理想。
识典古籍整理平台:这个平台可以自己建一个团队(一个人也行),然后便可上传古籍PDF,借助平台进行OCR,还能手动校对,准确率较高。识别结果可以下载为txt文档。遗憾的是,平台本身巨量的已经文本化的古籍数据没办法下载,只有自己上传识别的才能下载。
除了上述两种方式,或许也可以借助一些其它工具,文档预处理的目的就是将文档提取文字,并转换为更适合向量化的md、txt格式文档。
用嵌入式模型向量化
这个环节只能在CherryStudio中进行。现在的大模型有很多类别,其中一类为embedding模型,即嵌入式模型。它的作用可理解为一个翻译器,将用户上传的文档拆分并翻译为云端大模型可识别的语言,这就是所谓的向量化。
嵌入式模型主要在两个环节发挥作用,一是导入文档时,嵌入式模型将文档向量化,生成向量库(存在本地)。二是每一次问答时,嵌入式模型将用户的提问向量化,并到向量库中检索匹配,再将匹配结果发送给云端大模型。
由于嵌入式模型的作用是贯穿始终的,所以CherryStudio中,每个知识库的嵌入式模型都只能在建立时选定,此后不可再更改,若强行更改,则会新建一个知识库副本,重新做向量化。
嵌入式模型也有本地和云端两个方案:
本地部署:嵌入式模型体积不大,本地部署是完全可行的。如QWen3系列的嵌入式模型,包含0.9b、4b、8b三个版本,只要内存足够,即使电脑没有独立显卡,也完全可以本地部署。这一方案的优点是完全免费,因为模型部署在本地,完全不需要购买tokens,断网也能用。缺点是如果电脑性能一般,过程会比较慢,而且失败率可能偏高。我的电脑是轻薄本,32GB内存,跑过beg-m3、QWen3的0.6b、4b和nomic等几个模型,能跑,但经常失败,体验最好的是beg-m3。部署工具我推荐ollama,操作很简单。
云端API:通过申请API接入云端模型。我现在主要就是用硅基流动提供的QWen3的8b版本。这一方案的优点是速度较快,成功率高,对电脑性能完全没要求(当然最起码要能运行CherryStudio)。缺点是要钱,且必须联网。不过大体来说,嵌入式模型的tokens价格较低,支出不会太大。API平台我现在主要用硅基流动。
虽然说不贵,但总体看来嵌入式模型用量还是挺大的,主要是导入了好几本书
在CherryStudio的设置中,第一栏就是模型服务,在这里选择对应的API平台,填入API地址、密钥等就能配置好,然后点击添加模型,通常只需要填入模型名称即可,模型名称建议直接从网页复制,否则容易写错。配置好以后,建立知识库时就能直接选。
大模型问答
CherryStudio的首页即为大模型问答界面。在对话界面,最顶端可以选择这一窗口的默认对话模型,可以随时改。输入栏的下方有一排按钮,在这里,可以选择是否开启联网、是否关联数据库作为资料来源,同时也可以@其它大模型,同时@多个大模型,便可以一次性调用等多个大模型进行问答,并对比问答结果。
对话大模型的本地部署和云端API配置,均与嵌入式大模型相同。但本地部署非常考验电脑性能,我部署的最大的大模型也就9b,不仅速度极慢,而且效果很差。带独显的电脑会好很多,但即使是5090,能跑的大模型大小也还十分有限,跟云端大模型比不了,不过处理一些简单的问题应该没问题。因此,除非涉及非常需要保密的内容,否则建议直接用API接入云端模型。国内的DeepSeek、QWen等,token的价格其实都比较便宜,Kimi之类的会贵一点。