一、什么是注意力机制
注意力机制(Attention Mechanism)是深度学习中一种模拟人类视觉注意力的技术。其核心思想是:当我们处理信息时,不需要关注全部内容,而是将注意力集中在关键部分。- Query(查询值):当前要查询的信息,可以理解为“我要找什么”
- Key(键值):用于匹配查询的索引,可以理解为“我有什么”
- Value(真值):实际存储的信息,可以理解为“内容是什么”
注意力机制的本质是:通过计算 Query 与 Key 的相关性,为 Value 加权求和,从而拟合序列中每个词与其他词的相关关系。二、核心公式
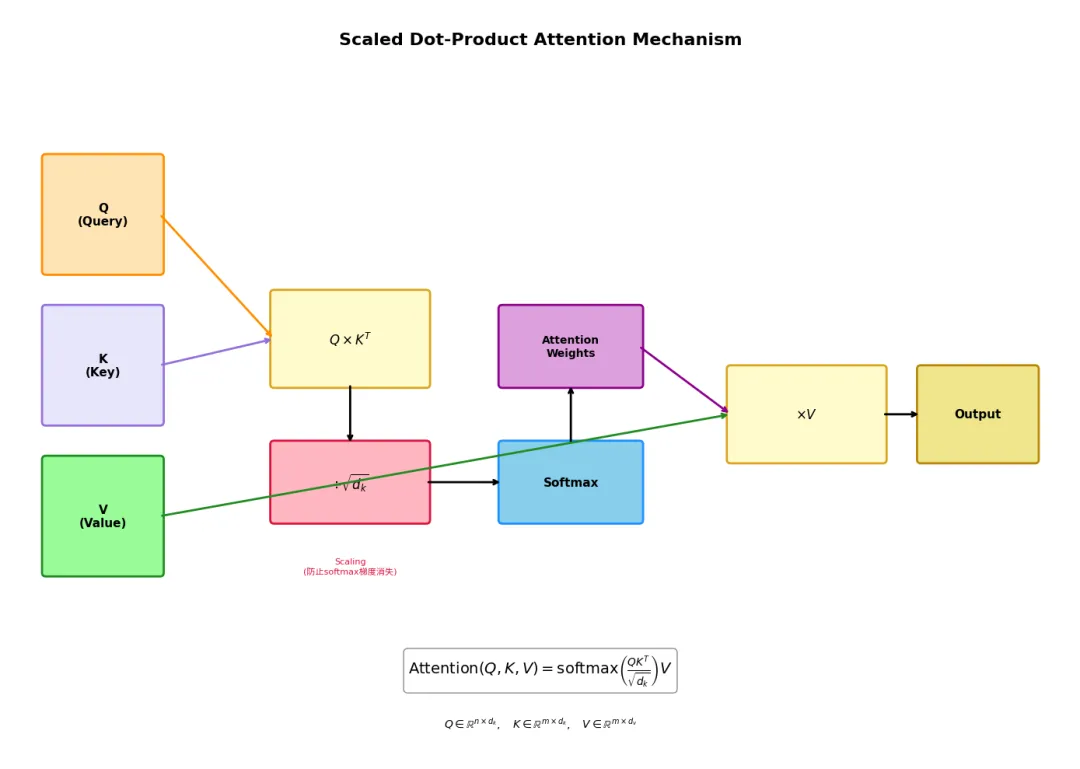
2.1 缩放点积注意力
Attention(Q, K, V) = softmax(QKᵀ / √(dₖ)) V
- Q ∈ R^(n×dₖ):Query矩阵,n为查询序列长度
- K ∈ R^(m×dₖ):Key矩阵,m为键值序列长度
2.2 多头注意力
MultiHead(Q, K, V) = Concat(head₁, ..., headₕ)Wᴼ
headᵢ = Attention(QWₖᵢ,KWₖᵢ, VWᵥᵢ)2.3 核心示意图
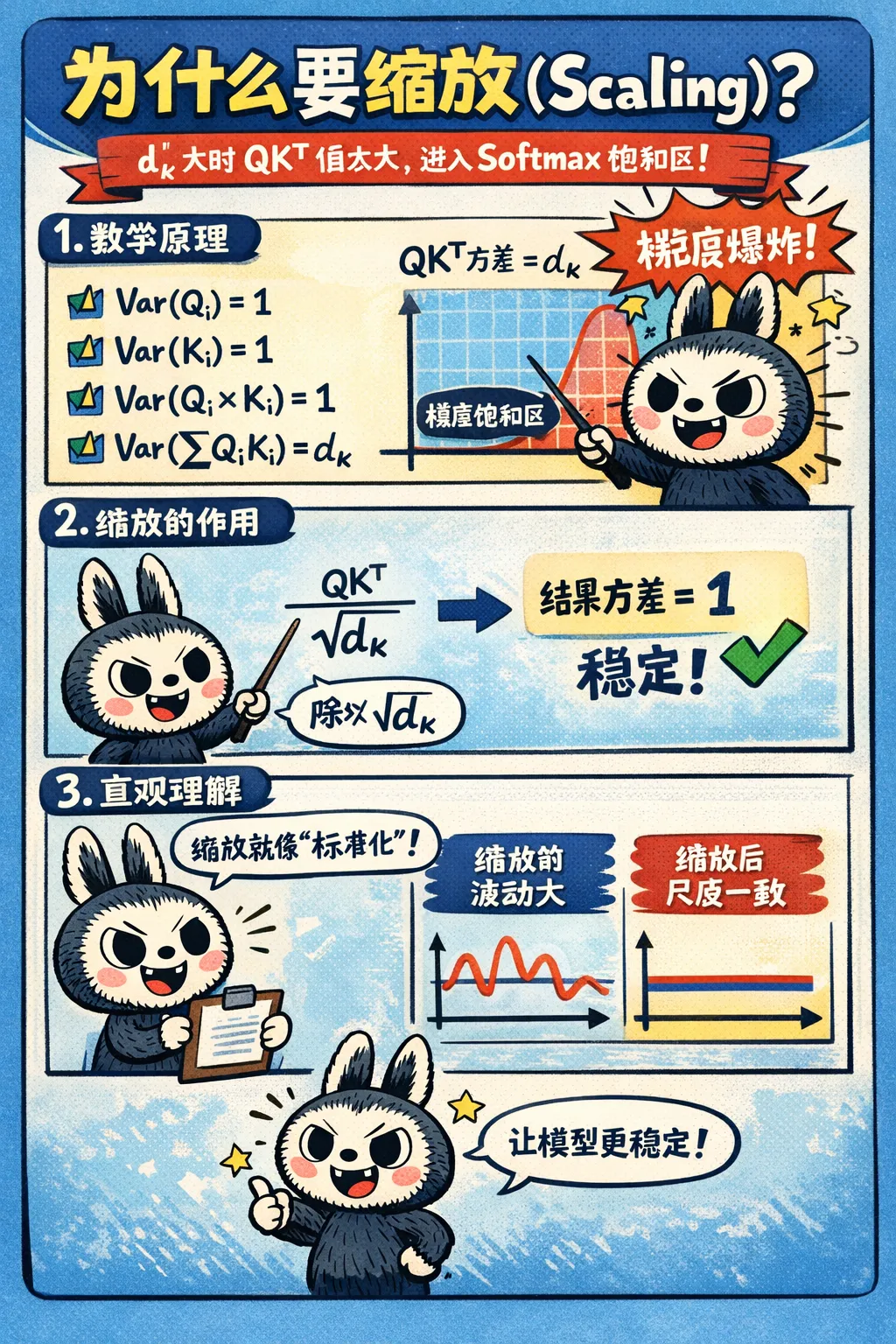
三、为什么要缩放(Scaling)
核心问题:当 dₖ 较大时,QKᵀ 的点积值会变得很大,导致 softmax 函数进入梯度饱和区。
3.1 数学原理
假设 Q 和 K 的各个分量是相互独立的随机变量,均值为0,方差为1。那么它们的点积 QKᵀ 的均值为0,方差为 dₖ。- Var(∑ QᵢKᵢ) = dₖ:dₖ个独立项求和的方差
3.2 缩放的作用
当我们将 QKᵀ 除以 √(dₖ) 后,结果的方差变为:Var(QKᵀ / √(dₖ)) = dₖ / dₖ = 1
这样,无论 dₖ 多大,点积结果的分布都保持稳定的方差,softmax 函数的输入不会过大或过小,梯度可以正常传播。3.3 直观理解
可以把缩放理解为“归一化”操作。就像我们在统计学中对数据进行标准化处理一样,缩放确保了注意力分数的尺度一致性,使模型训练更加稳定。四、为什么多头(Multi-Head)
核心思想:一次注意力计算只能拟合一种相关关系,多头注意力让模型同时从多个角度理解序列关系。4.1 单头的局限
在单头注意力中,所有信息都通过同一组 Q、K、V 投影矩阵处理,只能学习到一种固定的注意力模式。但语言中的关系是复杂多样的:4.2 多头的优势
- 多视角学习:每个注意力头使用不同的投影矩阵(Wₖᵢ, Wₖᵢ, Wᵥᵢ),可以学习到不同的注意力模式。例如,一个头可能关注语法结构,另一个头可能关注语义相似性。
- 增强表达能力:多个头的输出拼接后,再经过线性变换 Wᴼ,相当于对多种注意力模式进行综合,形成更丰富的表示。
- 并行计算:多个头的计算是相互独立的,可以并行执行,不会显著增加计算时间。
4.3 实际效果
在Transformer原论文https://arxiv.org/abs/1706.03762(详见后面几页)中,作者通过可视化展示了不同注意力头确实学习到了不同的模式:五、计算流程总结
5.1 缩放点积注意力计算步骤
- 缩放:scaled_scores = scores / √(dₖ)
- 归一化:attention_weights = softmax(scaled_scores)
- 加权求和:output = attention_weights × V
5.2 多头注意力计算步骤
- 线性投影:对每个头 i,计算 Qᵢ=QWₖᵢ, Kᵢ=KWₖᵢ, Vᵢ=VWᵥᵢ
- 并行计算:对每个头计算 headᵢ = Attention(Qᵢ, Kᵢ, Vᵢ)
- 拼接:multi_head = Concat(head₁, ..., headₕ)
- 线性变换:output = multi_head × Wᴼ
六、关键要点回顾
为什么要缩放?当 dₖ 较大时,点积结果方差会变大(Var = dₖ),导致 softmax 梯度消失。除以 √(dₖ) 可以将方差归一化为1,保证梯度稳定传播。为什么多头?单头只能学习一种注意力模式,多头通过不同的投影矩阵,让模型同时从多个角度理解序列关系,捕捉语法、语义、指代等不同层面的信息。