Kalman Filter
Background (Lecture1)
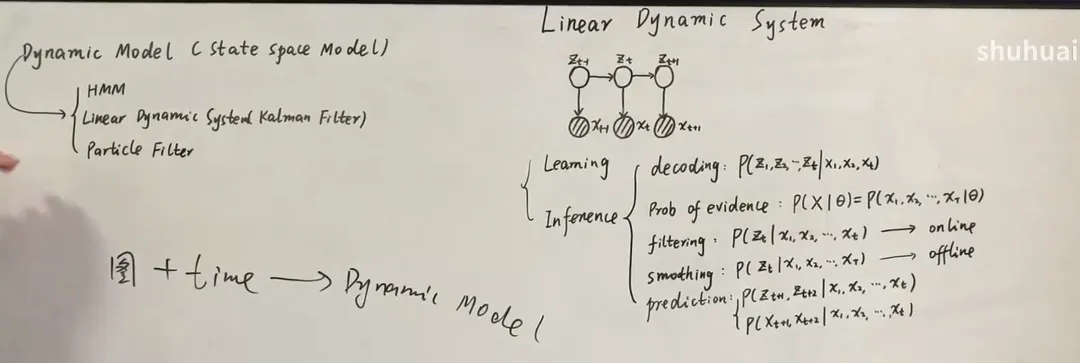
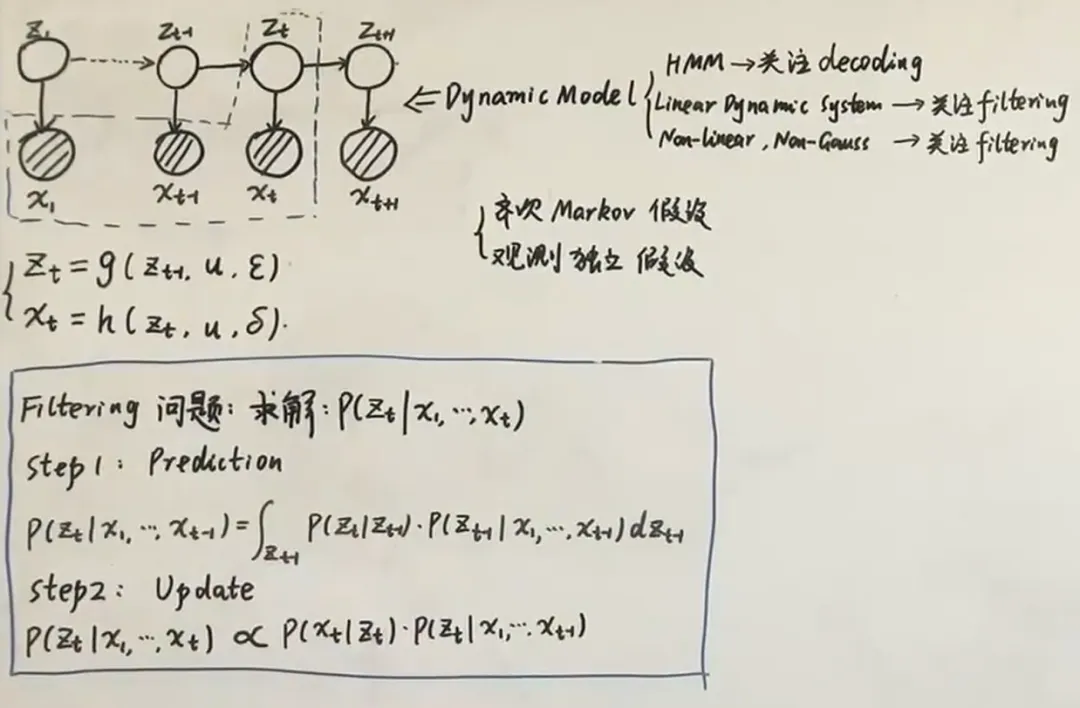
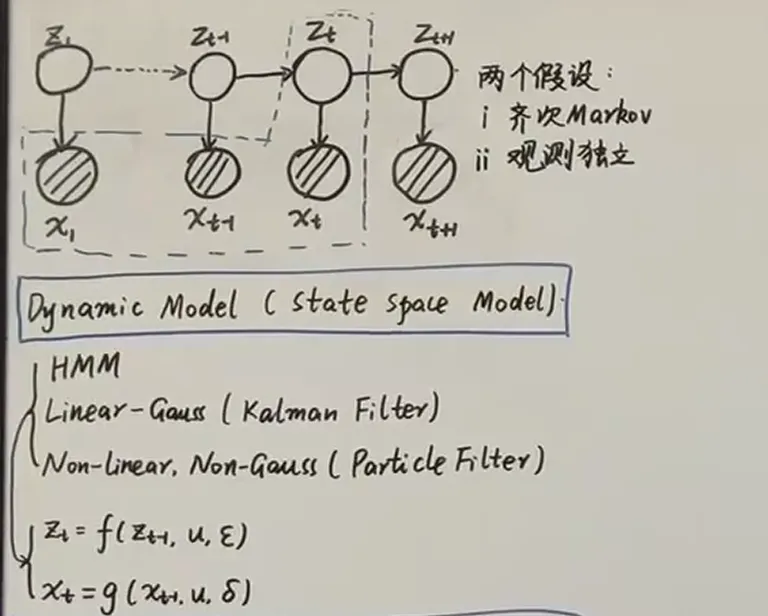
概率图模型+时间→ dynamic model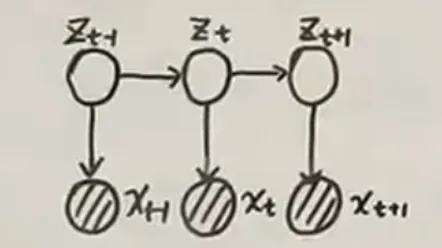 Dynamic model (state space model)
Dynamic model (state space model)
- state is discrete 隐状态离散,观测变量离散 or 连续没有要求 → hidden Markov Model (HMM)
- Linear dynamic system (Kalman Filter, linear Gaussian model): 隐变量和观测变量都是连续的,且都服从于高斯分布
- particle filter → non-linear , non-Gaussian
两大问题:
- learning: learning问题就是要把系统的参数求出来
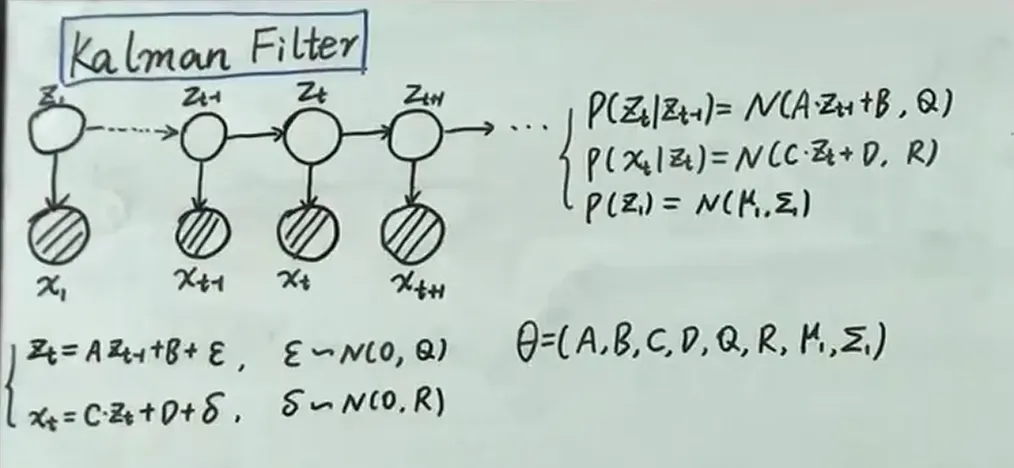
Linear dynamic system (Kalman filter)
Linear 体现在两个方面:
Gaussian Dist 体现在 , , 表示引入的噪声分布
initial state :
Above is a simple description of Kalman filter, the paramters are .
Filtering (Lecture 2)
- learning: learning问题就是要把系统的参数求出来
- Prob of evidence: → 前向/后向
- filtering: → online → marginal posterior
- smoothing: → offline 给定所有的数据,求 的后验分布
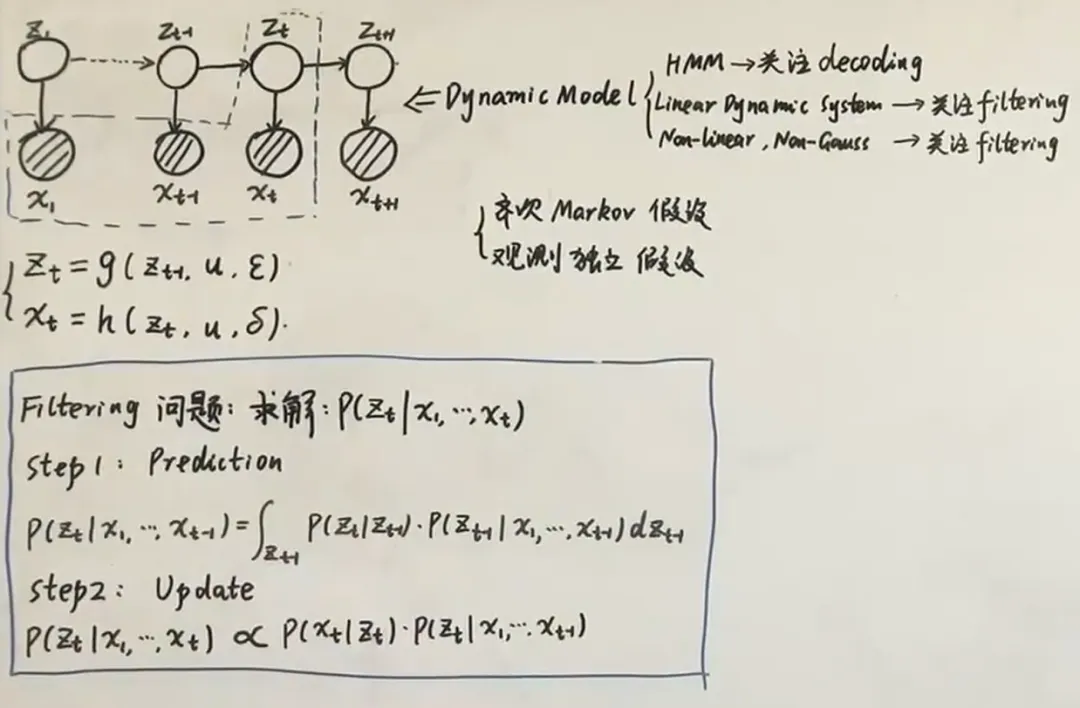
Goal :
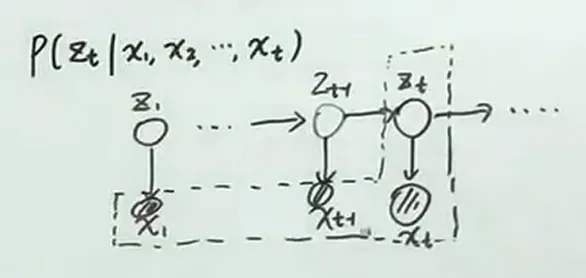 此处求的filter,可以联想至HMM中的forward algorithm
此处求的filter,可以联想至HMM中的forward algorithm
利用Bayes' Theorem,
由于为已知的观测变量,其联合分布概率为可以计算出来的常量,因此正比于 的联合分布
观测独立性假设 单独抽出prediction那一项继续推导
单独抽出prediction那一项继续推导 filter递推式就得到了
filter递推式就得到了
- → update(correction) (用的数据去修正时刻的prediction)
上述都是高斯分布,高斯分布的特点是一个多元高斯分布的边缘分布,条件概率分布均为高斯分布,两个高斯分布的联合概率分布仍然为高斯分布。
上述代入仍然有closed-form的高斯分布。
Filtering (lecture 3)



Particle Filter (Lecture 4)
Dynamic model均满足两个假设:
- 齐次 Markov 假设 : 给定 , 和无关,仅与 有关
相当于给 一个先验,用数据 去updata得到后验
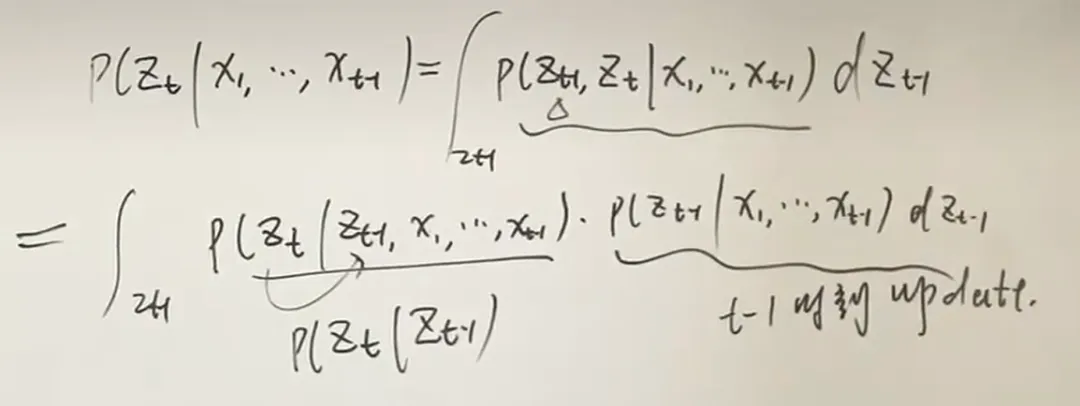
上述第二个等号利用了齐次Markov假设
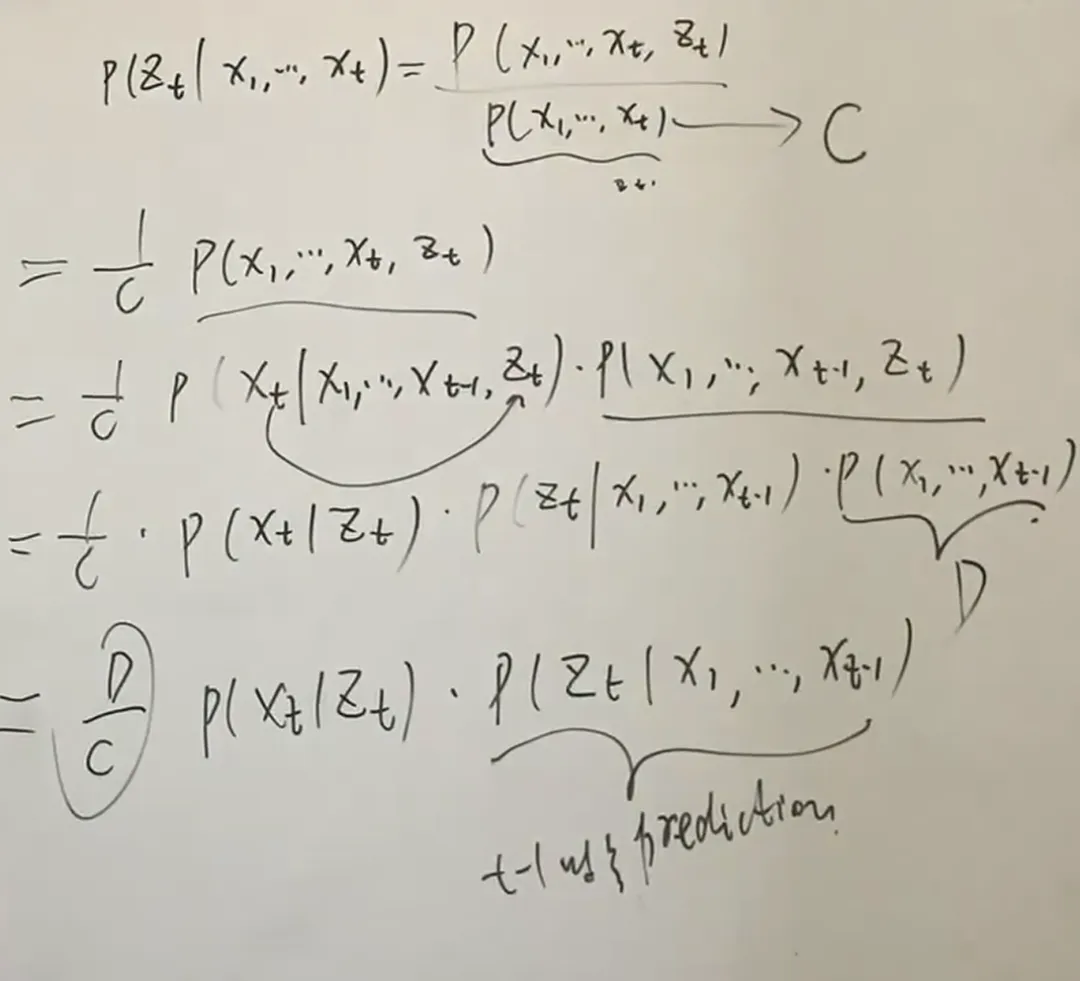
上述用到了观测独立假设以及prediction公式
Non-linear, Non-Gaussian
- 无解析解 → 采样 (Monte Carlo Method)
Monte Carlo Method
对分布进行采样
此处简写为
Importance Sampling
 引入符号
引入符号
Sequential Importance Sampling (SIS)
试图找到 → 找到两者之间的递推关系


则找到了与之间的递推式。
Record:
- Dynamic Model (State space model)
Sequential Importance Sampling Filter (SIS) → Basic Partical Filter
往往假设 只和 相关,i.e.
algorithm
问题: 权值退化, 越来越不平均,权重集中在几个粒子上,粒子的方差太大,利用这些例子去逼近分布不实际,源于高维空间的维度灾难
解决方法:
- 选择一个合适的更好的 proposal distribution
Resampling
重采样的想法就是优胜劣汰,权重高的例子多播种,小的就少播种
权重多的多复制,权重少的复制少甚至会被丢弃
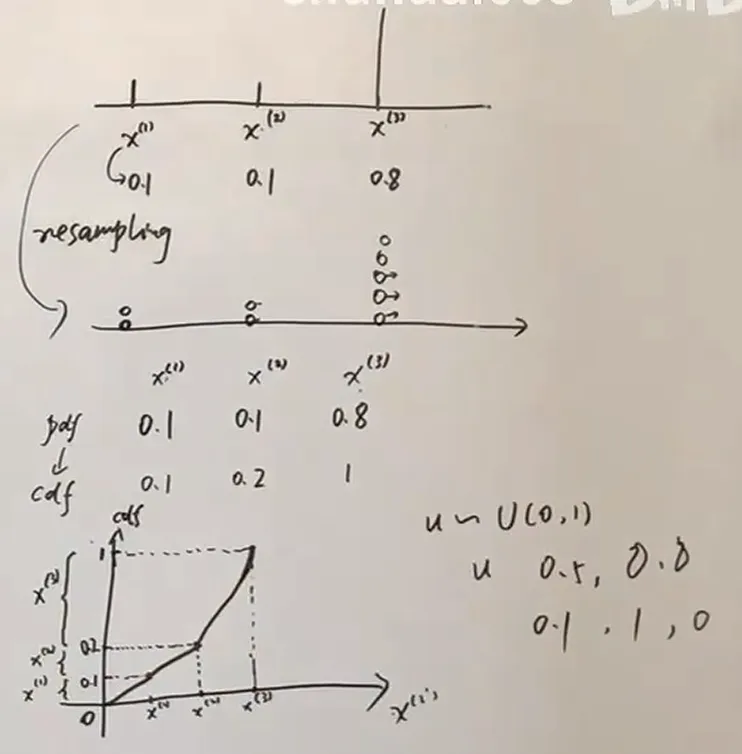
SIS + Resampling
algorithm
SIR Filter : Sampling-Importance-Resampling (SIS+Resampling+)
选择
generate and test
- test: 如果生成的粒子更能代表目标分布的话,则就会比较大
后续会针对笔记中涉及的Monte Carlo Method, Importance Sampling Methods等采样方法进行细致的讲解,上述笔记为记录B站《机器学习白板推导》课程所写。

