前几次学完AI能做什么、项目怎么做、岗位怎么被改变,这周终于进入最实际的问题:
手里一堆想法,到底该挑哪个下手?
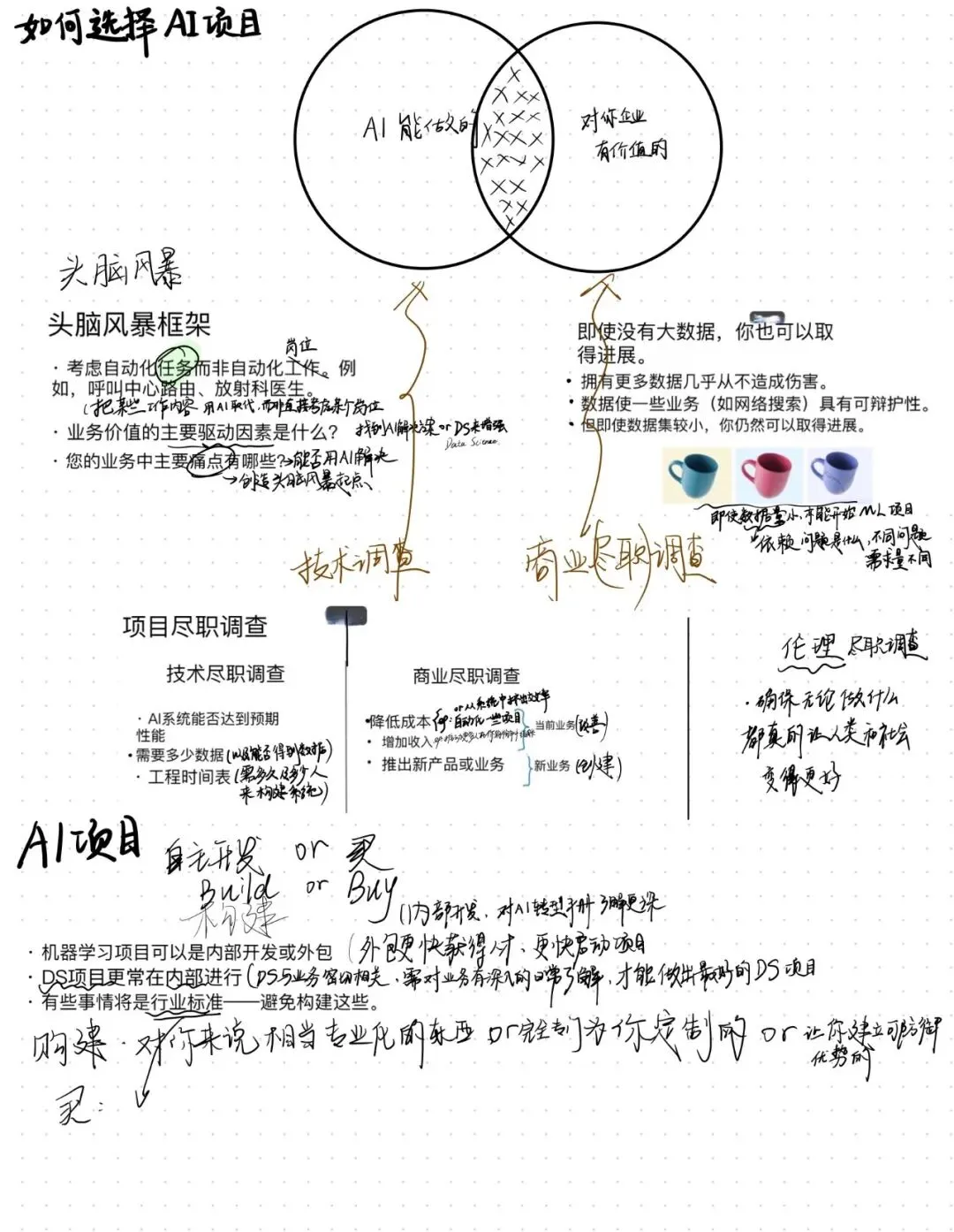
讲课的Andrew教授给了一个特别朴素的比喻——
AI能做的事是一个圈,对业务有价值的事是另一个圈。好项目,就是这两个圈的交集。
道理简单,做起来难。因为你得同时懂AI的边界和业务的痛点,而这两件事通常不在同一个人脑子里。
这次的内容,就是一套帮你选出好项目的框架。
教授反复强调:别指望一个人想出完美项目。
· AI专家知道左边那个圈(AI能做什么)的边界
· 业务专家(销售、市场、制造……)知道右边那个圈(什么对业务有价值)的重点
把这两拨人拉到一个房间里,让他们互相启发,才能找到交集。
这种团队叫跨职能团队。听起来高大上,其实就是——懂技术的别自己闷头想,懂业务的也别等着被投喂,大家一起聊。
教授分享了一个他在很多公司用过的框架,就三个问题:
1. 能不能把某个任务自动化,而不是取代整个岗位?
媒体整天说“AI要取代工作了”,但做项目时这么想容易把自己吓死,也容易想偏。
更好的思路是:盯着具体任务,别盯着整个岗位。
· 呼叫中心员工要做很多事:接电话、回邮件、处理退款……其中“邮件分类”这个任务,AI完全可以做,而且一做就比人快。
· 放射科医生要看X光片、培训年轻医生、给病人咨询……其中“看片”这个任务,AI可以当助理,帮医生先筛一遍。
所以别问“AI能不能取代这个人”,问“这个人做的哪件事,AI能替TA干”。
2. 驱动你业务价值的主要因素有哪些?AI能不能增强它们?
每个行业都有自己的核心驱动力:
· 电商:转化率、客单价
· 制造业:良品率、设备利用率
· SaaS:续费率、用户活跃度
找到这些关键指标,然后问:AI能不能帮我们把这项做得更好?
3. 你业务里最大的痛点是什么?有没有哪个能用AI缓解?
痛点往往是最好的切入点。
· 客服响应太慢?AI自动回复常见问题。
· 质检工人招不到?AI视觉检测顶上。
· 库存预测总不准?AI用历史数据做预测。
这三个问题轮番问,一圈下来,能筛掉一半不靠谱的想法。
你可能听过一种说法:AI必须有大鱼大肉(海量数据)才能喂出来。
教授说:别信。有大数据当然好,但没有大数据也能起步。
举个例子:你想做咖啡杯的自动质检,需要一堆有瑕疵的杯子图片。但如果你只有100个瑕疵杯子的照片,难道就不做了吗?可以啊,先拿这100张训练一个初版模型,跑起来,看看效果,再慢慢收集更多数据。
关键是先开始,不是等完美。
当然,有些问题确实需要大数据(比如语音识别),但也有很多问题,几百张图片就能让你看到希望。跟你的AI工程师聊,他们会告诉你大概需要多少。
找到几个看起来不错的项目后,别急着开干。教授建议做三轮“尽职调查”:
1. 技术尽职调查
· 这个性能指标(比如95%准确率)现实吗?
· 需要多少数据才能达到?我们能拿到吗?
· 大概需要多久、多少人?
2. 商业尽职调查
· 这个项目到底能省多少钱、多赚多少钱?
· 别凭感觉,拉个Excel算一算。比如95%准确率的质检系统,能帮我们少扔多少杯子?值多少钱?
3. 道德尽职调查
· 这个项目会不会有偏见?会不会让某些人群受损?
· 能赚钱不代表就该做。确保它让社会变得更好,而不是更糟。
这是个老问题,但在AI时代更复杂。
· 机器学习项目:可以自建,也可以外包。很多公司一开始外包,跑通后再组建内部团队。
· 数据科学项目:通常建议自己做,因为需要对业务理解极深,外包很难替代。
还有一条黄金法则:如果已经有成熟的行业标准解决方案,别自己从头造轮子。
教授讲了一个特别形象的比喻:不要跟火车赛跑。
想象一列火车在铁轨上跑,你非要冲到它前面去——你跑得再快,早晚会被追上撞飞。火车就是那些已经成熟的行业标准方案(比如开源框架、云服务)。与其自己费劲再造一遍,不如直接拿来用,把精力花在真正对你业务独特的地方。
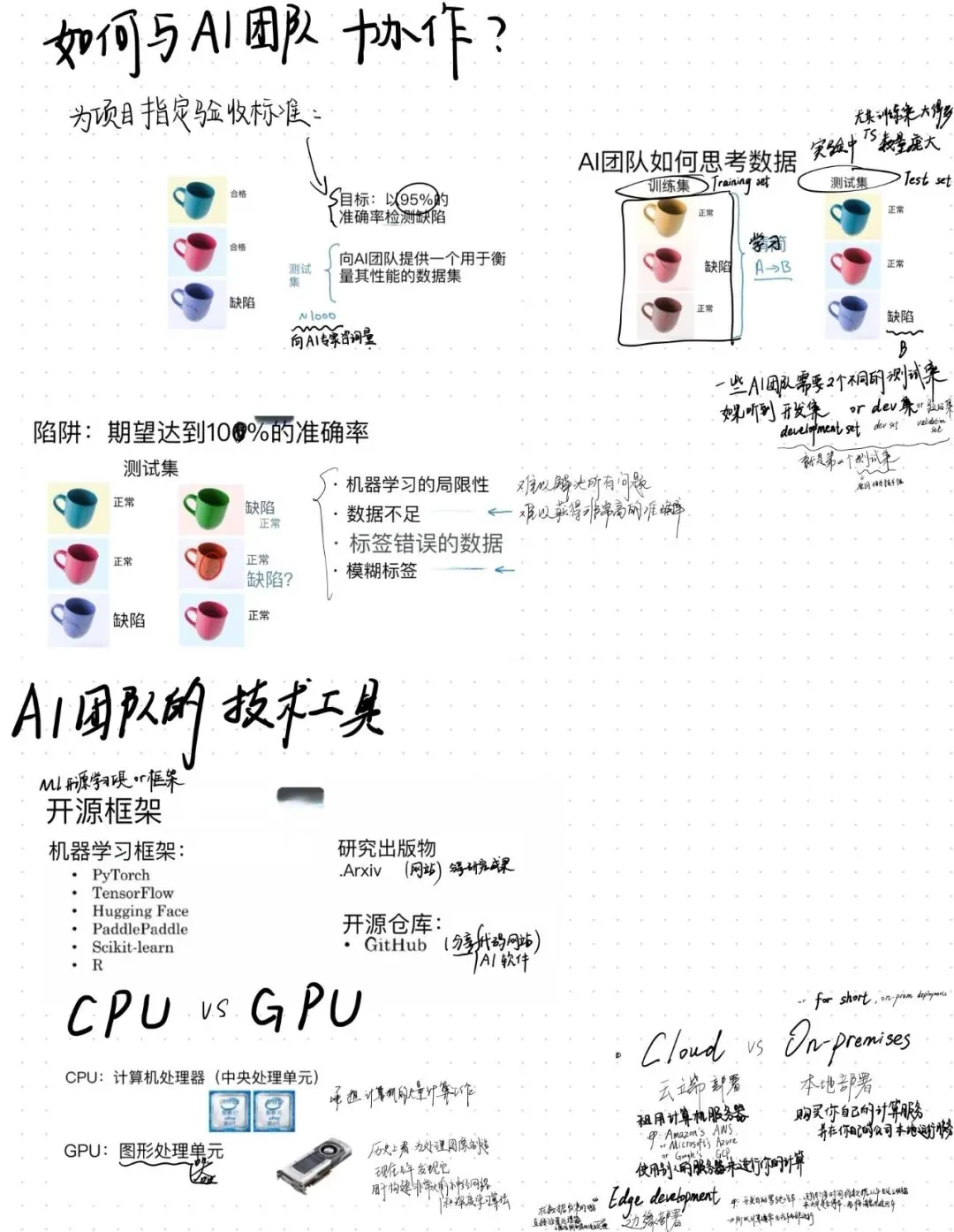
假设项目定了,你跟AI工程师说:“帮我做个质检系统,要准。”
工程师内心:准是多准?怎么算准?用什么数据测?
所以你需要给出验收标准,比如:
以至少95%的准确率检测咖啡杯缺陷。
然后,你需要提供测试集——一组已经标好“合格/不合格”的图片,用来验证模型到底有没有达到95%。
AI团队会把数据分成:
· 训练集:给模型学习用的
· 测试集:考模型用的(不能提前让模型看到)
· 有时还有一个开发集/验证集(别怕,工程师会解释)
这里有个重要提醒:别指望100%准确率。
为什么?
· 技术有局限
· 数据可能不足
· 数据可能标错(比如明明合格的杯子被标成不合格)
· 数据可能模棱两可(这个划痕算不算瑕疵?专家也吵架)
所以跟团队聊清楚:合理的准确率是多少?我们业务能接受多少?
很多AI系统,哪怕只有90%的准确率,已经能创造巨大价值。别被“完美”卡住。
附:技术工具小科普
如果你听到AI工程师聊这些,知道大概意思就好:
· 开源框架:TensorFlow、PyTorch、Keras……都是帮他们更快写代码的工具,像预制菜,不用从种菜开始。
· arXiv/GitHub:arXiv是论文预印本网站,GitHub是代码分享平台。很多AI成果第一时间公开在这。
· CPU/GPU:CPU是电脑的大脑,GPU本来是处理图像的,后来发现特别适合跑深度学习,成了AI标配。
· 云/本地/边缘:云是用别人的服务器,本地是用自己的服务器,边缘是把计算放在设备上(比如音箱里、汽车里),为了更快响应。
最后做一个总结
1. 好项目 = AI可行 ∩ 业务价值,需要跨职能团队一起找
2. 三个问题帮你头脑风暴:自动化什么任务?增强什么驱动力?解决什么痛点?
3. 小数据也能起步,别等完美数据
4. 项目启动前做三轮尽职调查:技术、商业、道德
5. 有现成的就别自己造,别跟火车赛跑
6. 给AI团队清晰验收标准 + 测试集,别指望100%准确率
如果你也是AI小白,欢迎一起慢慢学。🌱







 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
