人工智能前沿知识汇总!(附学习资料)
人工智能前沿知识汇总!(附学习资料)
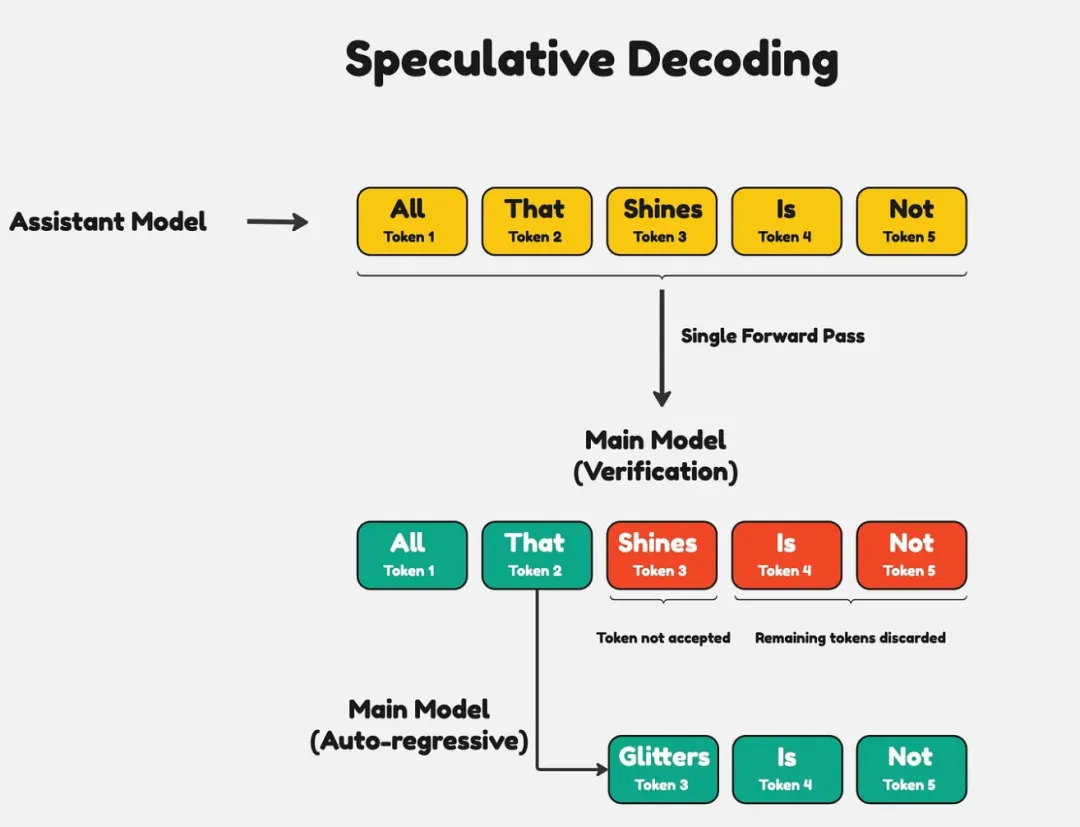
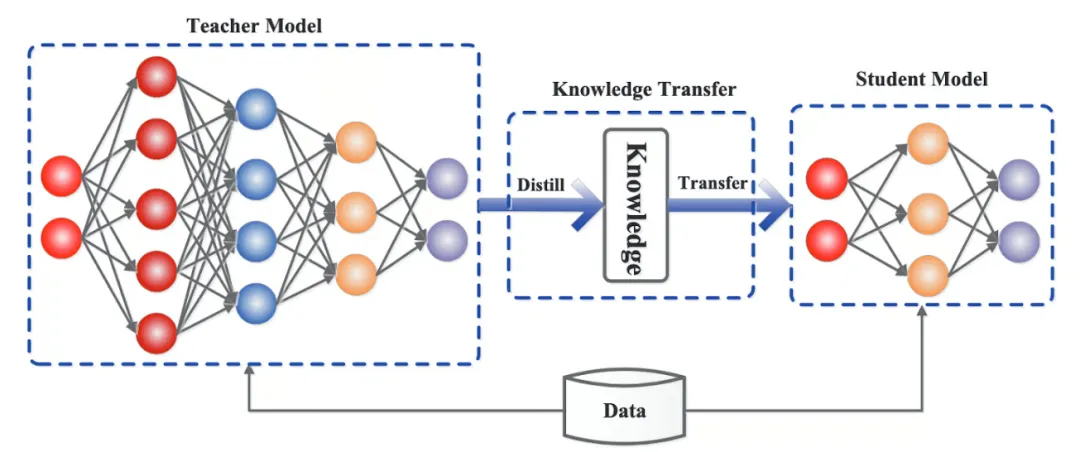
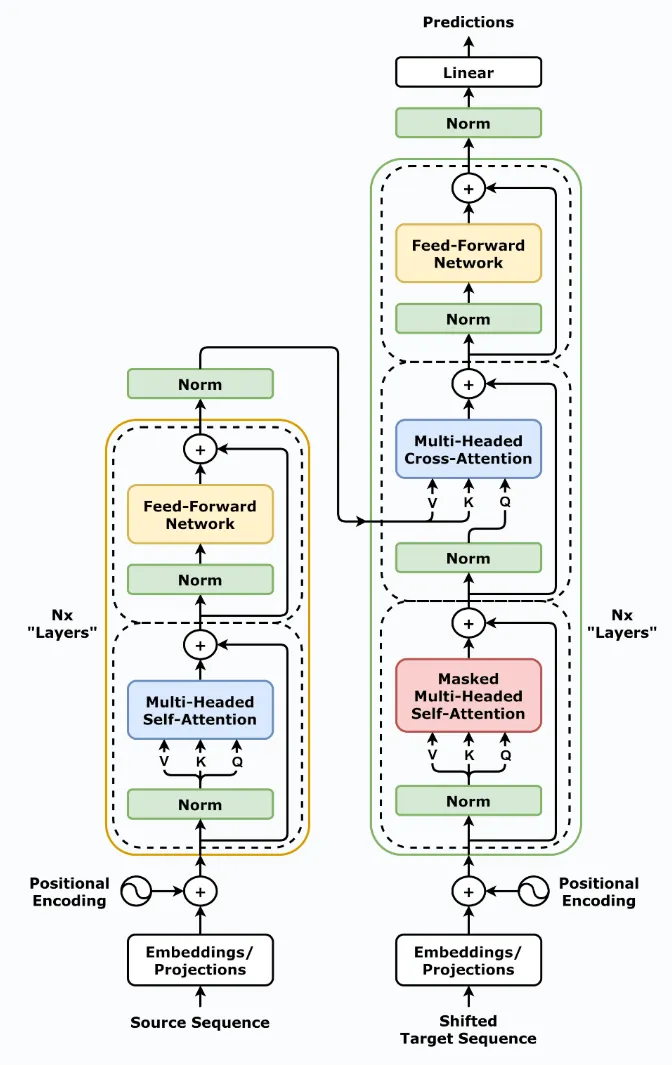
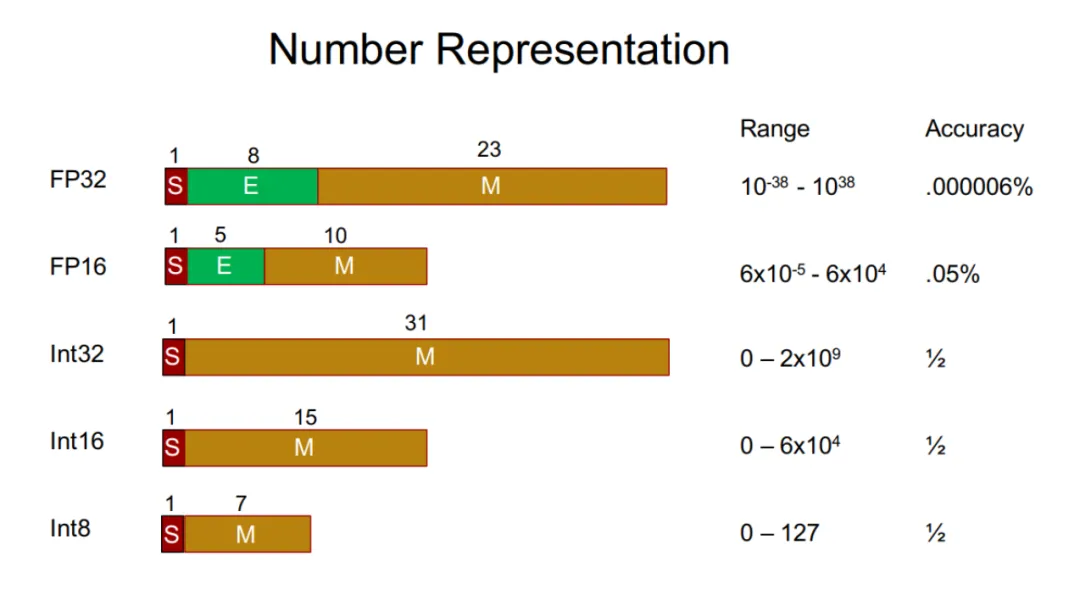
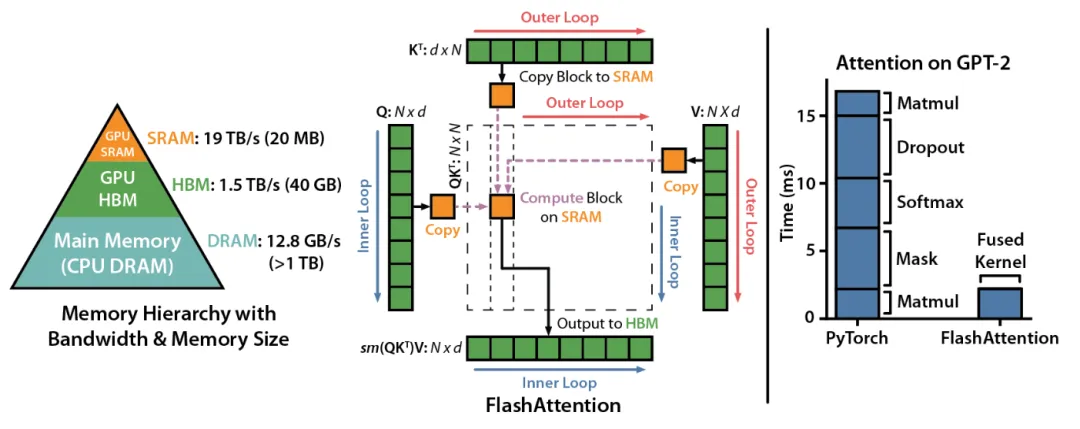
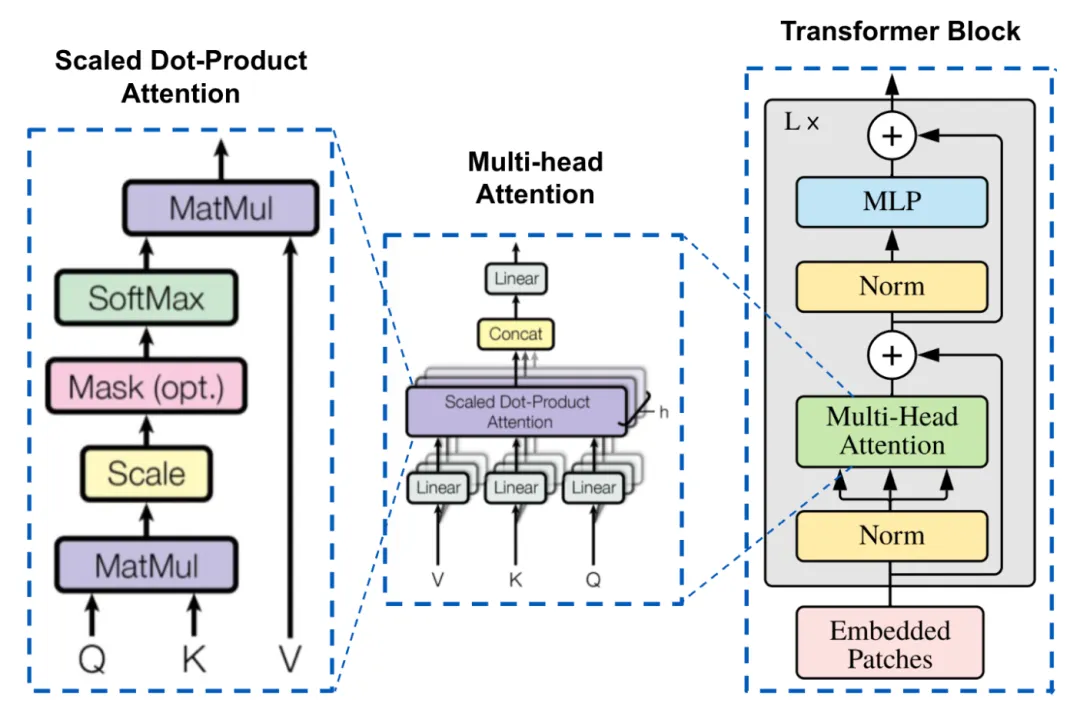
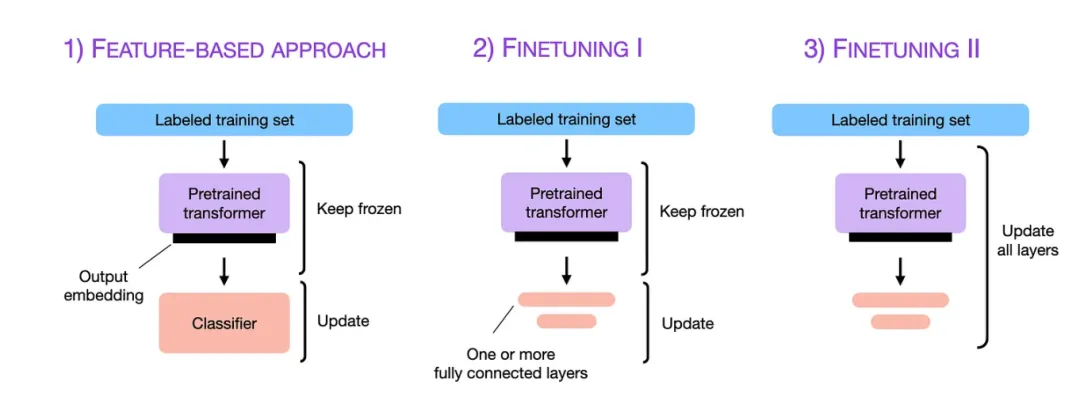
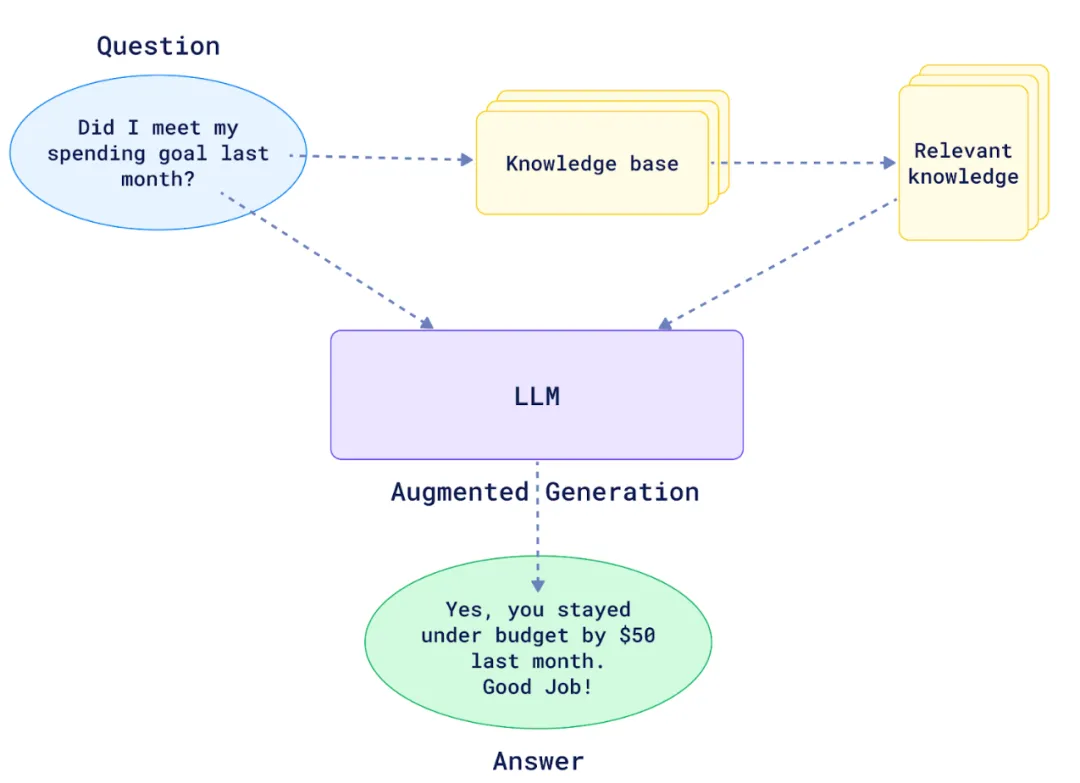
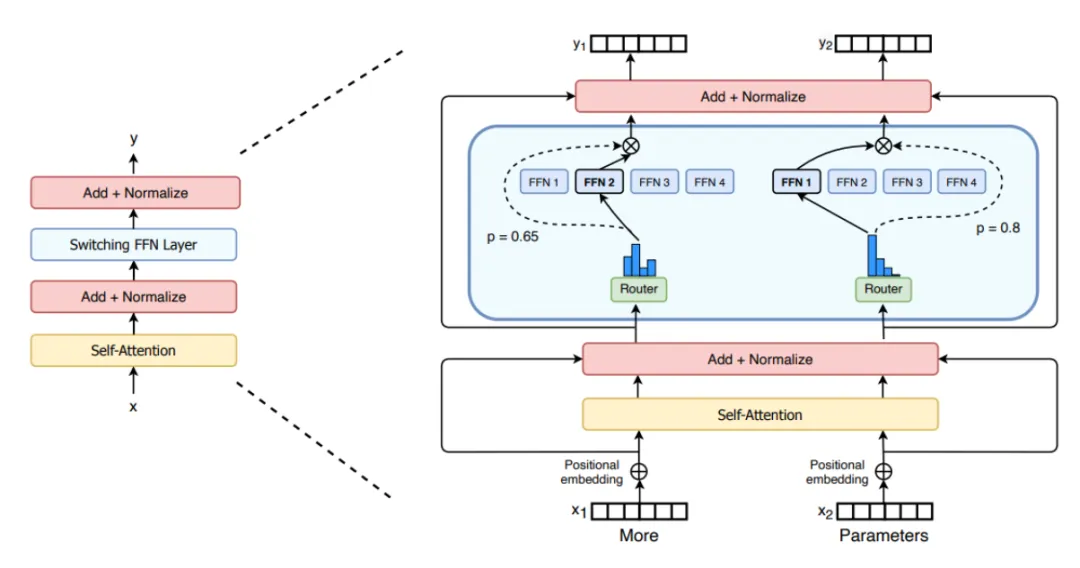
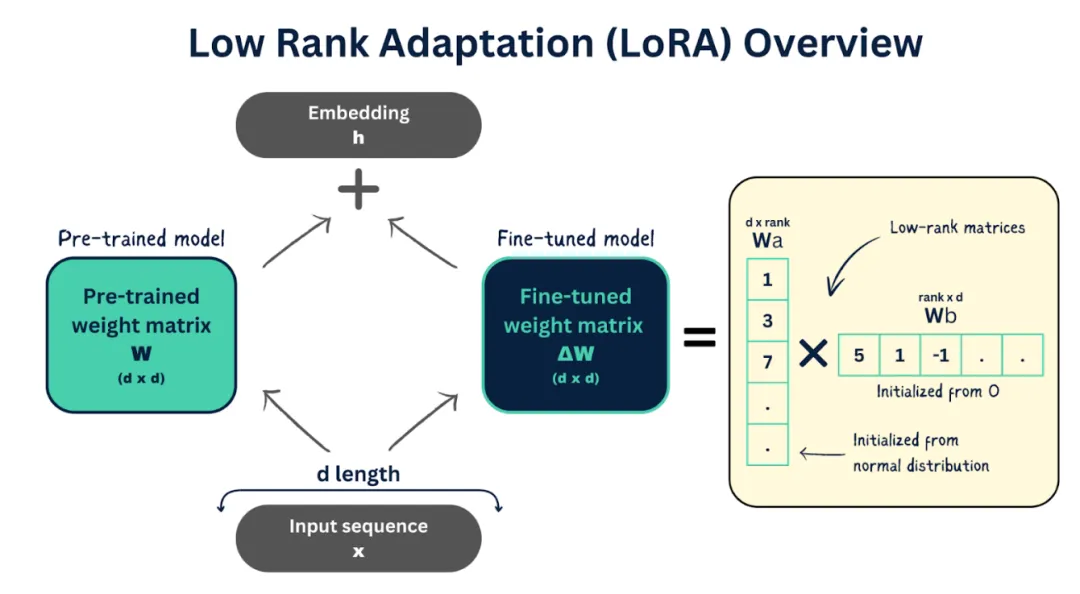
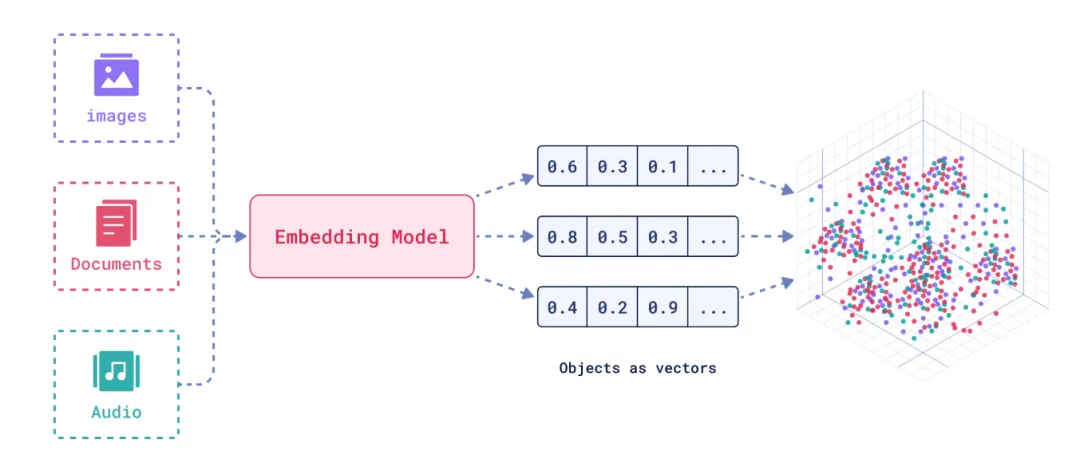
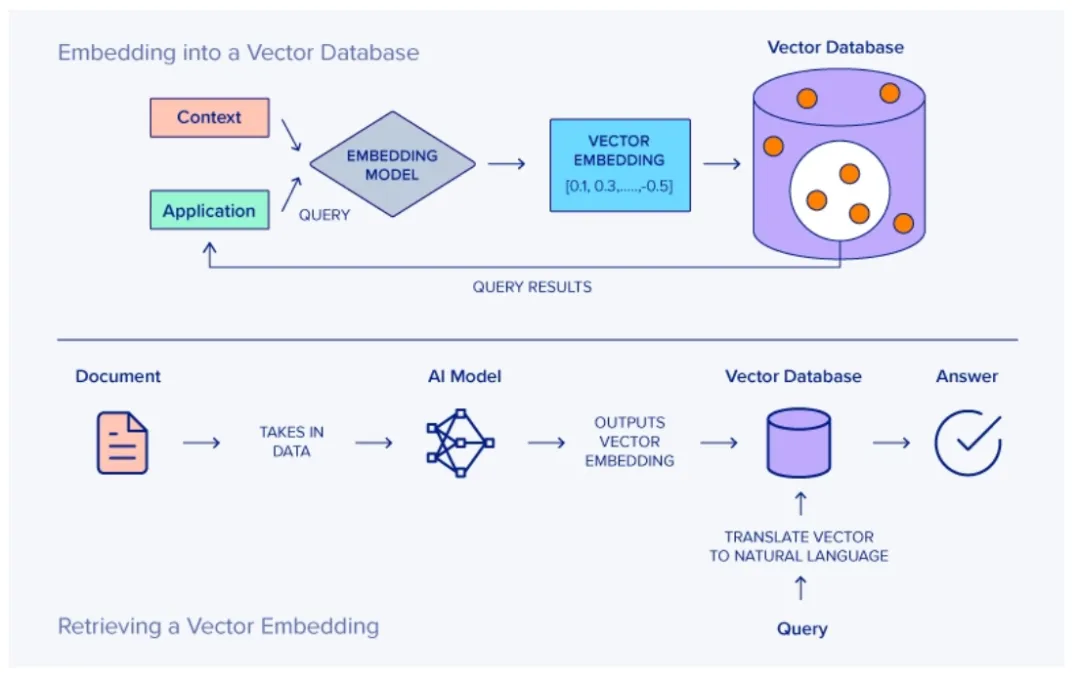
现在人工智能发展太快,如果想要跟上时代的步伐就得不断学习,持续学习,需要学习的内容太多很多前沿的知识点,比如LLM模型蒸馏,其实可以通过五分钟就完成大概内容的学习,不需要了解复杂的公式和繁杂的理论推导,只需要从整体上了解即可这一期主要是给大家推荐五分钟了解人工智能前沿知识点系列推测性解码是一种用于优化大语言模型推理性能的技术。它的核心思想是:在当前大模型生成当前 token 的同时,使用小的草稿模型对未来的 token 进行预测LLM 蒸馏 (Distillation) 是一种技术,用于将大型语言模型 (LLM) 的知识转移到较小的模型中。其主要目的是在保持模型性能的同时,减少模型的大小和计算资源需求。通过蒸馏技术,较小的模型可以在推理时更高效地运行,适用于资源受限的环境Transformer 是一种用于自然语言处理 (NLP) 的深度学习模型架构, 由 Vaswani 等人在 2017 年提出. 它主要用于处理序列到序列的任务, 如机器翻译, 文本生成等,Transformer 的核心创新和强大之处在于它使用的自注意力机制(self-attention mechanism), 这使得它们能够处理整个序列, 并比之前的架构 (RNN) 更有效地捕捉长距离依赖关系.量化 是一种通过降低模型参数的数值精度来压缩模型大小的技术. 在深度学习中, 模型参数通常以32位浮点数 (FP32) 存储, 通过量化可以将其转换为更低精度的表示形式, 从而减少模型的内存占用和计算开销Flash Attention 是一种优化的注意力机制, 旨在提高深度学习模型中注意力计算的效率. 它通优化访存机制来加速训练和推理过程。而 Flash Attention 则是采用分块计算技术,将大型注意力矩阵划分为多个块,在 SRAM 中逐块执行计算多头注意力(Multi-Head Attention)是 Transformer 架构中的一个核心组件,它通过并行运行多个注意力机制来增强模型的性能。在多头注意力机制中,"头"是指一个独立的注意力机制。每个头有自己的一组权重,用于计算输入的自注意力。通过使用多个头,模型可以从不同的角度和特征空间中提取信息LLM 微调 (Fine-tuning) 是一种通过特定领域数据对预训练语言模型进行二次训练的技术。目的是在保持模型通用语言理解能力的基础上,使其适应特定任务或领域。通过微调技术,基础模型可以显著提升在目标领域(如医疗、法律、金融等)的表现。RAG (Retrieval-Augmented Generation, 检索增强生成) 是一种结合检索与生成的混合式语言模型技术。其核心思想是通过外部知识库增强语言模型的生成能力,使模型在回答时能够动态检索相关信息,从而提高生成内容的准确性和事实性MoE (Mixture of Experts, 混合专家模型) 是一种通过组合多个专业子模型 (专家) 来提升模型性能的神经网络架构,它通过动态路由机制选择性地激活部分专家, 在保持模型容量的同时显著降低计算成本, 已成为大规模语言模型的重要技术方案.LoRA(Low-Rank Adaptation, 低秩自适应):由微软于 2021 年提出,是一种高效微调大型语言模型(LLM)的技术。它通过在冻结的预训练模型权重旁添加小型可训练的"低秩适应"层,显著降低了微调过程中的计算和内存需求,无需重新训练整个模型向量嵌入(Vector Embeddings)是将复杂数据(如文本、图像、音频等)转换为密集数值向量的过程和结果。这些向量通常是高维的数字数组,使机器能够"理解"数据间的语义关系。其核心思想是通过数学表示捕捉原始数据的语义信息,将抽象概念映射到多维空间,这样语义空间的相似性,就可以转化为向量空间中的接近性(数学问题)向量数据库(Vector Database)是一种专门设计用于存储、管理和搜索向量嵌入的数据库系统。其核心价值在于能够高效执行相似性搜索(similarity search),支持AI应用中常见的"寻找最相似内容"需求,成为现代人工智能基础设施的重要组成部分此外,还有AI幻觉,模态编码,表示空间,多模态模型,LLM困惑度,KVCache, 滑动窗口注意力,vibe coding是什么,大模型精度格式等内容学完上面内容,就可以对AI前沿内容有一个整体的认识,基本上几分钟掌握一个新的知识点,越学越上瘾,真的看的很快2. 发送口令“前沿知识”领取(人工回复可能有时差,都会发给大家的,不用着急
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。