偷懒的论文学习笔记(5)|DeepSeek开源OCR 2:视觉编码器大换血!首创“因果流”机制,让模型像人眼一样“逻辑看图”
DeepSeekOCR2告诉我们用 LLM 架构做视觉编码器是可行的。这为未来的统一全模态编码器(Unified Omni-modal Encoder)铺平了道路——也许未来,一个编码器就能同时处理图像、音频和文本,唯一的区别只在于“查询 Token”的不同。核心速览:
- • 痛点:传统多模态模型(VLM)看图是死板的“光栅扫描”(从左到右、从上到下),难以处理布局复杂的文档和图表。
- • 突破:发布 DeepSeek-OCR 2,引入全新的视觉编码器 DeepEncoder V2。它抛弃了 CLIP,改用 LLM 架构作为视觉编码器,实现了视觉 token 的动态重排序(Visual Causal Flow)。
- • 刷新纪录:在 OmniDocBench v1.5 上达到 91.09% 的准确率,阅读顺序编辑距离显著降低,代码权重全开源。
- • 深度洞察:这不仅是 OCR 的进步,更是向**原生多模态(Native Multimodality)**和真正的 2D 推理迈出的关键一步。
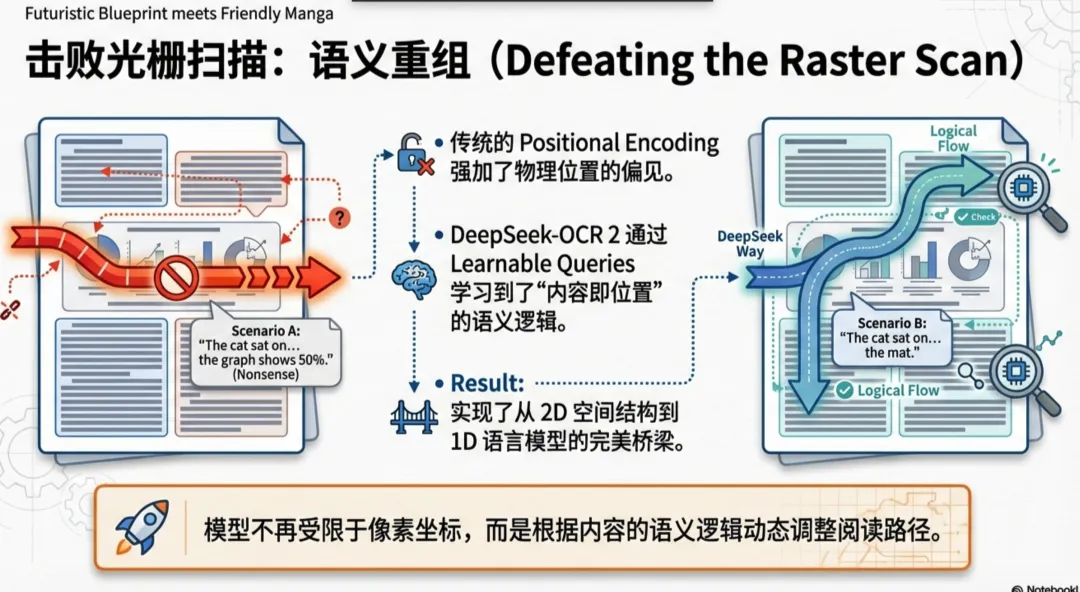
当我们在看一张复杂的报表、或者读一篇排版花哨的杂志时,我们的视线真的是从左上角一开始,逐行扫描到右下角吗?
答案是否定的。人类的视觉是因果驱动(Causally-driven) 的——我们会根据内容的逻辑,眼神在重点之间跳跃、关联。然而,现有的视觉语言模型(VLM)大多还在傻傻地进行“光栅扫描”,这也成为了它们理解复杂文档的最大绊脚石。
近日,DeepSeek-AI 团队发布了 DeepSeek-OCR 2,通过引入全新的 DeepEncoder V2,让模型第一次拥有了“重组视觉逻辑”的能力。
01 核心创新:DeepEncoder V2 与“因果流”
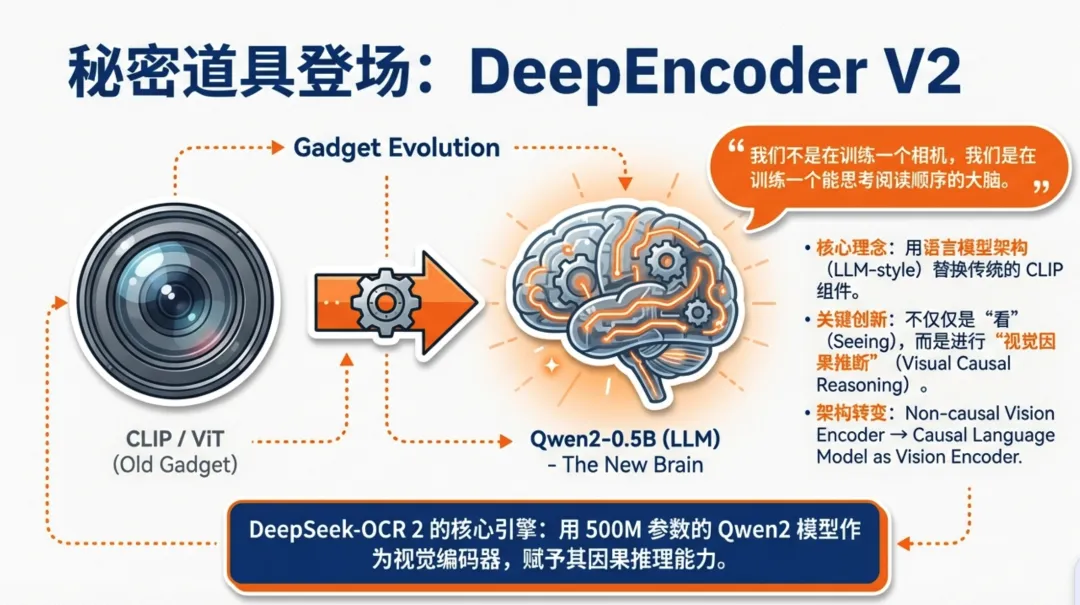
DeepSeek-OCR 2 最大的变革在于其编码器(Encoder)。
传统的 DeepSeek-OCR 或其他 VLM 通常使用 CLIP 来提取特征。而 DeepSeek-OCR 2 大胆地将 CLIP 替换为一个紧凑的 LLM 架构(基于 Qwen2-0.5B)。
这一改变带来了什么?
- • 拒绝死板扫描: 模型引入了因果流查询(Causal Flow Query)。这是一组可学习的 Token,它们不仅能看到所有的视觉信息,还能像 LLM 预测下一个词一样,根据语义逻辑对视觉 Token 进行重排序。
- • 混合注意力机制: 在 DeepEncoder V2 内部,视觉 Token 之间是双向可见的(保留全局视野),而查询 Token 则是因果可见的(模拟推理过程)。这种设计让模型既看清了全图,又理清了逻辑。
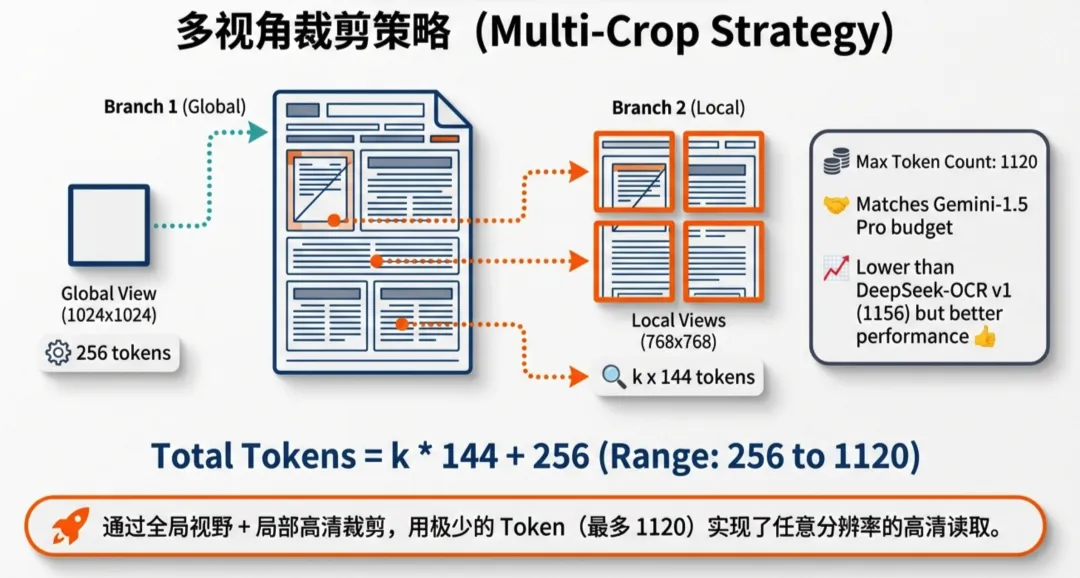
- • 极低成本: 尽管架构升级,模型依然保持了极高的压缩率。输入 LLM 的视觉 Token 数量仅为 256 到 1120 个,这与 Google Gemini-1.5 Pro 的视觉预算相当,兼顾了性能与效率。
02 架构细节:LLM 既是大脑,也是眼睛
DeepSeek-OCR 2 延续了“编码器-解码器”的整体框架,但内部大有乾坤:
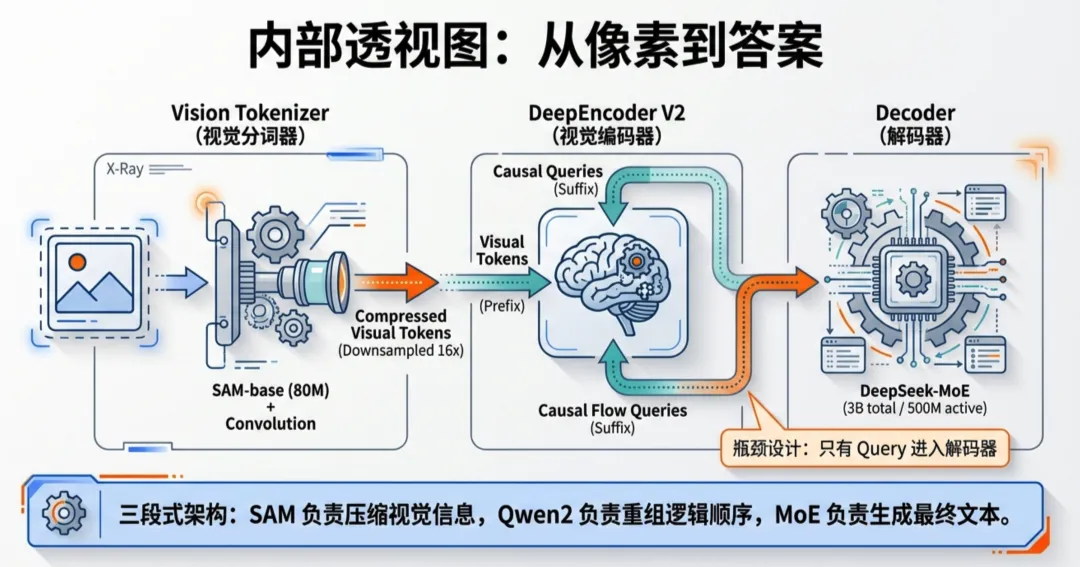
- 1. 视觉Tokenizer: 使用 80M 参数的 SAM-base 配合卷积层,将图像压缩 16 倍,保留细节。
- 2. LLM 式视觉编码器: 这是一个 0.5B 参数的语言模型架构。它通过“多视窗策略(Multi-crop)”处理图像,利用学到的 Query 将杂乱的像素信息整理成有序的“视觉叙事”。
- 3. MoE 解码器: 后端连接 DeepSeek-MoE(3B参数,500M激活),负责将整理好的视觉特征翻译成最终的文本。
03 战绩:读得更准,逻辑更顺
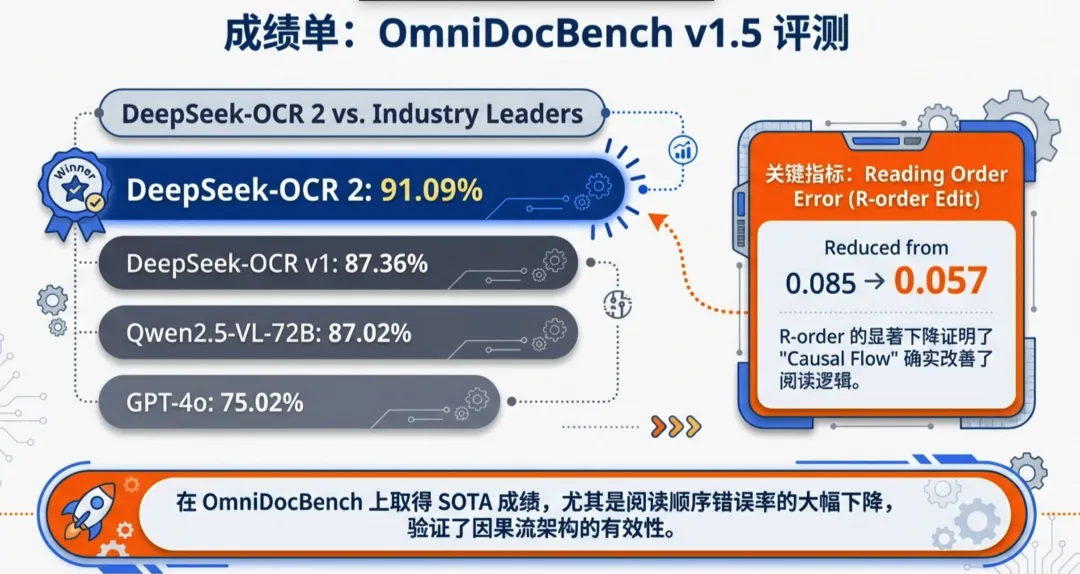
在权威榜单 OmniDocBench v1.5 上,DeepSeek-OCR 2 展现了统治力:
- • 综合得分: 达到 91.09%,相比上一代提升了 3.73%,大幅领先 Qwen2.5-VL-72B (87.02%) 和 GPT-4o (75.02%)。
- • 读懂逻辑: 最关键的指标是阅读顺序编辑距离(R-order Edit Distance),从 0.085 降至 0.057。这意味着模型不再是“乱读一通”,而是真正理解了文档的起承转合。
- • 实战抗打: 在线上业务的实测中,模型的复读率(Repetition Rate)显著下降,证明其能够更流畅地处理长难文档,不仅是“刷榜神器”,更是“生产力工具”。
04 未来展望:通往真正的 2D 推理
DeepSeek 团队在报告中指出,DeepSeek-OCR 2 的意义远不止于 OCR 任务本身。
它验证了一个全新的范式:用 LLM 架构做视觉编码器是可行的。这为未来的统一全模态编码器(Unified Omni-modal Encoder)铺平了道路——也许未来,一个编码器就能同时处理图像、音频和文本,唯一的区别只在于“查询 Token”的不同。
目前,DeepSeek-OCR 2 的代码和模型权重已在 GitHub 开源。
🔗 开源地址:http://github.com/deepseek-ai/DeepSeek-OCR-2
参考资料:DeepSeek-AI Technical Report "DeepSeek-OCR 2: Visual Causal Flow". arXiv:2601.20552.
NLPer|一个努力自我提升的“懒癌患者”聚焦前沿 AI 技术与云上 AI 应用落地的工程实践,涵盖机器学习、自然语言处理、计算机视觉、LLM 等方向。站在LLM的风口上,

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
