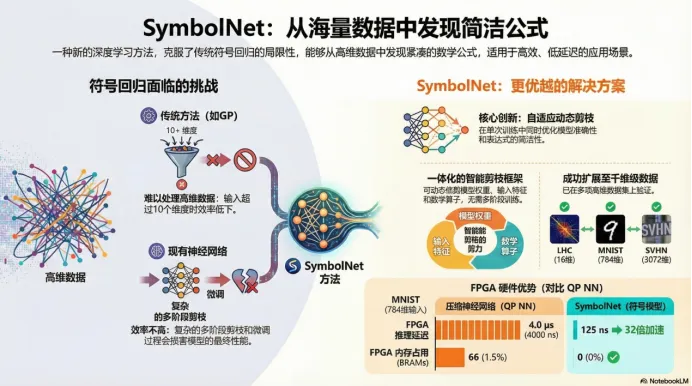
SymbolNet不是单纯追求“发现最像真理的公式”,而是把目标落到更工程化的方向——在资源受限的环境里(尤其是FPGA 这类低延迟硬件),把模型压缩到足够小、足够快,同时还保留一定可解释性。
一、问题从哪里来:低延迟场景需要“紧凑但强”的模型
在资源受限(延迟、带宽、功耗都很敏感)的系统中,我们往往需要更紧凑的模型。符号回归的潜力在于——如果最终模型是一个解析表达式,它天然更轻量、可解释,也更容易被映射成硬件友好的实现。
但现实是两条经典路线各有硬伤:GP(遗传编程)虽然可解释,但搜索慢、组合爆炸,高维/大数据上非常吃力;深度学习做 SR 虽然能用梯度优化加速,但常见套路是“训练→剪枝→微调”的多阶段流程,剪枝与精度之间经常互相拉扯,调参成本也高。
二、SymbolNet 的定位:用一个统一框架解决“剪枝 + 符号回归 + 高维”
SymbolNet 想做的是一个统一框架,让符号回归既能面对高维数据,又能在训练过程中自动变稀疏,并且稀疏程度不是“随缘”,而是能朝着设定目标收敛。
这其实非常关键:传统多阶段方法往往把“拟合误差”和“稀疏约束”分开处理,导致要么剪过头精度崩,要么不够稀疏表达式太长。SymbolNet 试图把两者绑到同一个训练过程里,让模型从一开始就朝“可部署、可读”的方向成长。
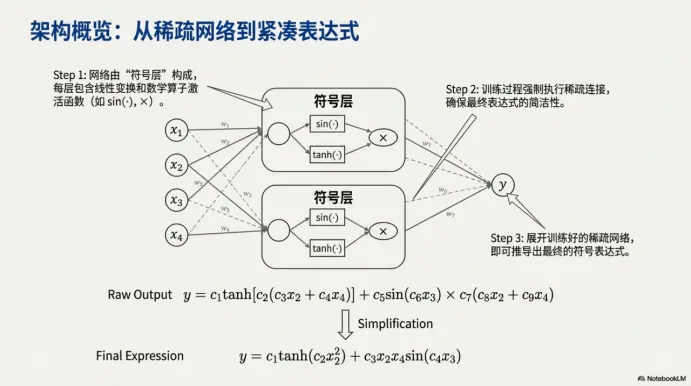
三、架构直觉:从稀疏网络到紧凑表达式的三步走
第一步,构建带有“符号层”的网络。所谓符号层,本质上是把激活函数变成一组算子(例如 sin、tanh、乘法等),让网络具备“可展开成表达式树”的潜质。
第二步,通过训练过程中的稀疏化,让网络连接变少,结构变得更像一棵简洁的表达式树。
第三步,把稀疏网络unroll 成显式表达式,并做化简,得到最终可读的形式。
这张图还特别展示了“Raw output → Simplification → Final expression”的变化,符号回归并不一定一步到位,化简/整理是把结果变得可用的重要环节。
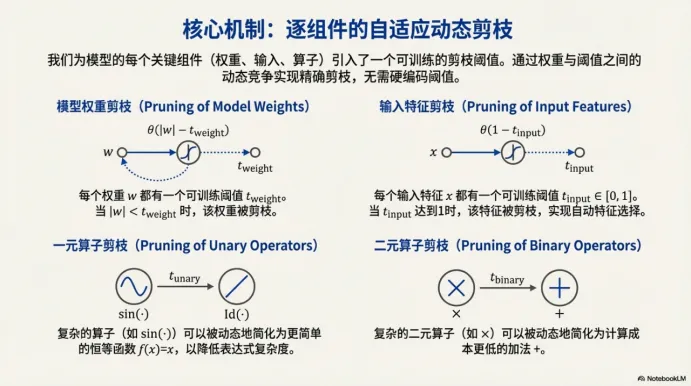
四、核心机制:逐组件的自适应动态剪枝(不只剪权重)
如果只用“剪权重”,你得到的是稀疏网络;但 SymbolNet 追求的是稀疏结构+ 简洁算子,最后变成表达式。因此它的剪枝对象更“结构化”,这一页把它分成四类组件:
l模型权重剪枝:决定哪些连接保留,哪些直接屏蔽;
l输入特征剪枝:相当于训练中自动特征选择,哪些输入根本不用看;
l一元算子剪枝:把复杂一元算子“降级”为恒等映射 Id,避免表达式出现过多算子嵌套导致的过拟合与不可读;
l二元算子剪枝:把复杂二元算子“降级”为加法,朝着更便宜、更硬件友好的运算形式收敛。
SymbolNet 的剪枝不是“删掉一切”,而是“把模型往更朴素、更硬件友好、更像公式的结构推”。
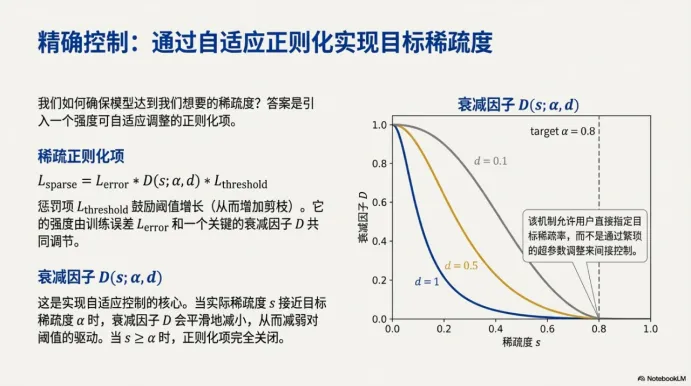
五、稀疏怎么“控住”:自适应正则把稀疏度当成可跟踪目标
如果我希望最终表达式足够短,我就需要更稀疏;但稀疏太强又会牺牲精度。传统做法通常靠固定正则系数(比如L1),然后反复调参。SymbolNet 的思路更像“带刹车的控制系统”:引入一个随稀疏度变化的衰减因子 (D(s;\alpha,d)),当当前稀疏度 (s) 逐渐接近目标 (\alpha) 时,稀疏驱动力会自动减弱。
图里的曲线非常直观:不同(d) 控制衰减速度,但共同点是——越接近目标稀疏度,越不应该继续强行剪枝,否则很容易把模型剪“瘫”。这一点对“想得到短公式”的任务尤其重要,因为短公式意味着结构必须极简,任何过剪都可能让表达能力突然断崖式下降。
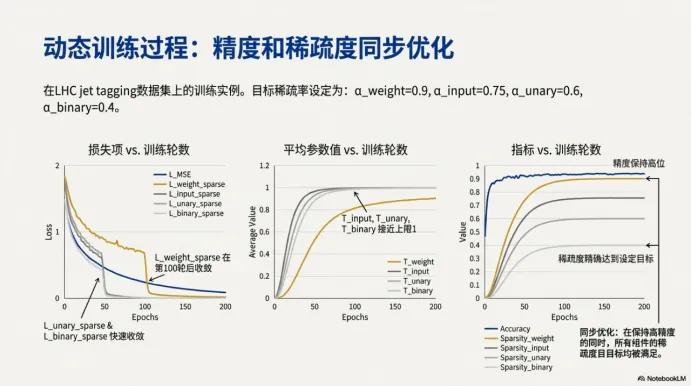
六、训练过程长什么样:精度和稀疏度同步演化,而不是分阶段修补
左图展示损失下降,说明模型在学;中间与右图展示精度上升的同时,不同组件(权重/输入/一元/二元)的稀疏度也在逐步变化,并最终接近设定目标。
这背后的含义是:模型不是先把精度学到极致再硬剪,而是在整个训练过程中持续做权衡——一边保证任务性能,一边把多余结构挤出去。这种同步演化的优势是,你不需要在训练后再人为决定“剪多少、剪哪里”,模型自己会在规则下走到一个相对平衡的位置。
七、验证场景:把 SR 推到真实世界的高维任务
从O(10) 级别到 O(1000) 级别的维度跨度,选择了三类典型任务:LHC Jet Tagging(较低维但工业/科研强相关)、MNIST(784 维)、SVHN(二分类,3072 维)。
我觉得这里的“跨度”比具体数据集名更重要,因为它要回答的是:符号回归到底能不能走出低维玩具问题?SymbolNet 的主张是:通过动态剪枝让结构变得可控,从而能在更高维的输入上跑起来,并且产出可用的紧凑表达式。
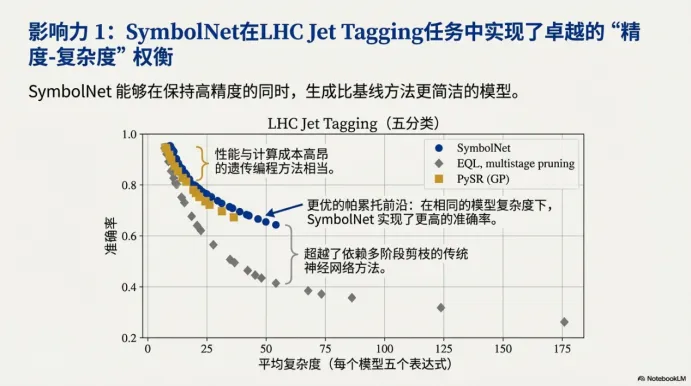
八、影响力 1:在 LHC 任务上做到了更好的“精度—复杂度”权衡
在实际操作中不能只盯着最高准确率,而要看在不同复杂度下模型能达到什么精度,也就是“精度—复杂度”权衡。图中的趋势表达了一件事:SymbolNet 的点更靠近理想区域——在相同复杂度附近,能取得更高精度;或者在相同精度附近,能把表达式压得更短。
这对工程落地很关键,因为复杂度基本就是部署成本的代理指标:表达式更短、算子更朴素,就意味着更低的延迟、更低的资源占用、更低的维护难度。
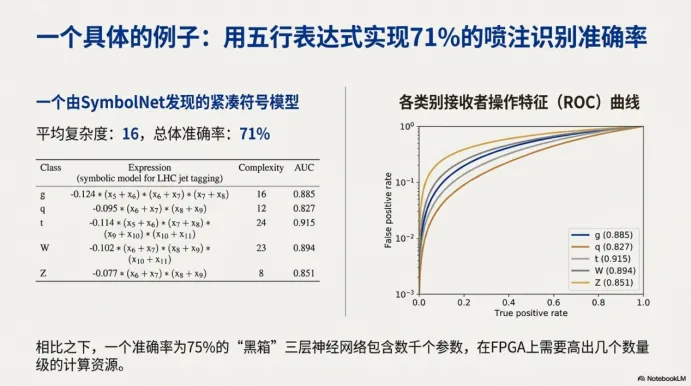
九、影响力 1 的“具象化”:几行表达式也能跑出可用性能
图中展示了一个具体发现的紧凑符号模型,并且配上ROC 曲线。
它传达的重点不只是“能拟合”,而是“能简化到足够短”。在很多硬件场景里,短表达式的价值是直接的:这意味着不需要加载大量参数,也不需要复杂的层级结构,硬件实现可以更稳定、更可预测。
将SymbolNet模型与更复杂的黑箱模型对比可以发现:黑箱可以得到更高一点的精度,但代价是大量参数与更重的计算资源。而SymbolNet 的路线更像“用最少的结构,换足够的效果”。
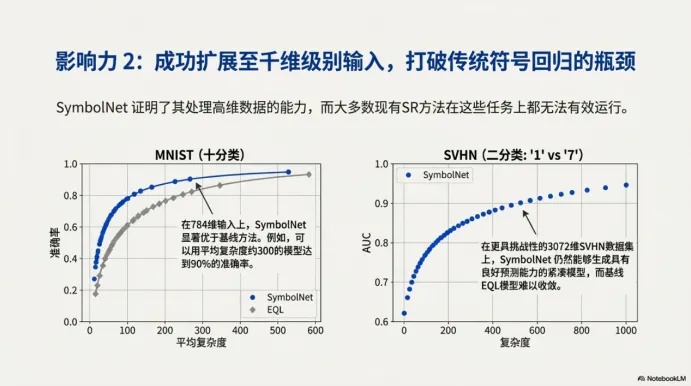
十、影响力 2:能扩展到千维级输入,打破传统 SR 的维度瓶颈
符号回归在高维下容易出现两个极端:要么表达式爆炸般复杂,要么为了变简单而性能大幅下滑。SymbolNet 的优势是:通过把稀疏度当成可控目标,训练会把结构压缩在一个更可用的范围里。
我个人读到这里的感受是:SymbolNet 不一定保证“最美的公式”,但它更像一个实用工具——当输入维度很高时,你仍然有机会获得一个可以运行、可以部署、还能解释一部分结构的表达式模型。
十一、一个“可复现感”很强的展示:MNIST 可解释表达式分类器
图像分类任务也能被写成一串串表达式。它说明这条路线在高维任务中确实能产出明确的符号形式。但与此同时也提醒我:表达式的可读性与规模控制仍然是挑战,尤其当表达式变长时,人类理解会变困难。因此,如何选择算子库、如何约束复杂度、如何做后处理化简,会直接决定结果“能不能被人读懂”。
十二、影响力 3:在 FPGA 上把延迟和资源降到“肉眼可见的量级差”
这一页是典型的工程对比:把量化剪枝后的神经网络(QP DNN/CNN)与 SymbolNet 的符号回归模型放在同一张表里比较 BRAM、DSP、延迟与精度。最醒目的结论是:SymbolNet 生成的符号模型在多个任务上能做到更低延迟,并且BRAM 占用接近 0 的趋势非常亮眼。
SymbolNet 的核心价值主张不是纯粹“学术上的可解释”,而是在回答“能不能把推理真正做到极致轻量”。当系统的硬门槛是纳秒级/微秒级延迟时,这种“表达式级模型”可能比“再怎么压缩的神经网络”更接近终局方案。
十三、总结:它在“性能—可解释—可部署”之间搭了一座桥
对研究者,它提供一种把高维现象“蒸馏”成符号规律的工具;对工程师,它提供一种面向低延迟硬件的模型压缩路线。
SymbolNet 的贡献是让 SR 更可控、更可落地——把剪枝对象扩展到结构层面,把稀疏度变成可追踪目标,最终把模型输出从“参数”转为“表达式”。