1 视觉问答(VQA)核心定义与任务本质
视觉问答(Visual Question Answering,简称VQA)是视觉-语言多模态领域的核心基础任务,也是连接计算机视觉与自然语言处理的关键桥梁。
1.1 标准输入输出
VQA的任务规则极为明确,无额外拓展与变形:
- • 输入:一张固定的图像(Image)+ 一条自然语言形式的问题(Question)
- • 输出:与图像内容完全匹配、准确简洁的自然语言答案(Answer)
1.2 任务核心目标
模型需要完成图像视觉信息理解、文本问题语义解析、跨模态信息对齐与推理三大核心动作,最终输出符合事实的答案,而非凭空生成内容。
1.3 基础示例

- • 问题:What color is the child's outfit?(孩子的衣服是什么颜色?)
这是VQA最基础的单步事实型问答,也是所有复杂VQA任务的底层原型。
2 VQA经典方法与模型框架演进
VQA的模型发展遵循多模态融合架构迭代的核心逻辑,按技术代际可分为三大阶段,核心模型与创新点均基于原文定义,无额外杜撰。
2.1 第一代模型:ViLBERT(2019)
ViLBERT是VQA领域里程碑式的奠基模型,首次将BERT语言模型与Transformer视觉模型结合,确立了双流多模态架构的基础。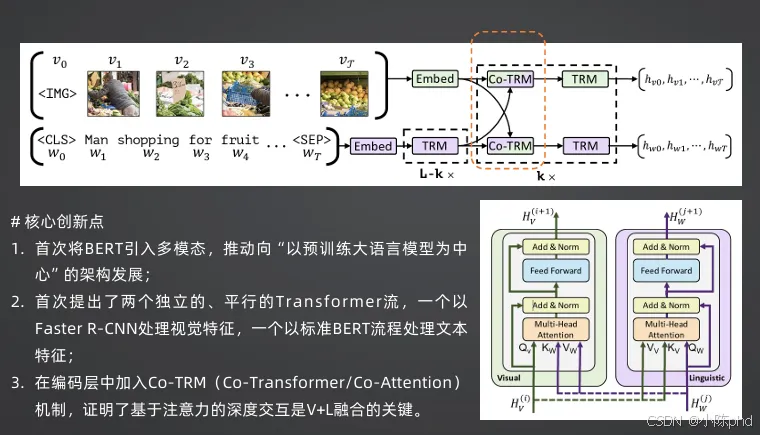
- • 采用双流(Two-Stream)并行架构:一条流处理视觉特征,一条流处理文本特征,两条流相互独立又相互交互。
- • 视觉端:通过Faster R-CNN提取图像区域特征,转化为视觉Token。
- • 文本端:通过标准BERT流程处理文本,转化为文本Token。
- • 引入Co-TRM(Co-Transformer/Co-Attention)协同注意力机制,实现视觉与文本特征的深度跨模态交互。
- • 首次将BERT引入多模态任务,推动VQA向预训练大语言模型为核心的方向发展。
- • 验证了注意力机制是视觉-语言融合的关键,为后续所有多模态模型奠定基础。
- • 架构短板:双流架构需从头学习所有跨模态对齐与融合逻辑,无预训练特征加持,学习成本高。
- • 效率短板:视觉输入约100个区域特征、文本输入约50个Token,总序列长度短但自注意力计算复杂度为O(L²),扩展能力差。
- • 视觉特征短板:完全依赖Faster R-CNN提取固定区域特征,视觉信息提取能力有限。

2.2 第二代模型:BLIP-2(2023)
BLIP-2是高效多模态融合的标杆模型,解决了ViLBERT的效率问题,首次提出双塔+轻量级桥接架构,成为后续开源多模态模型的主流范式。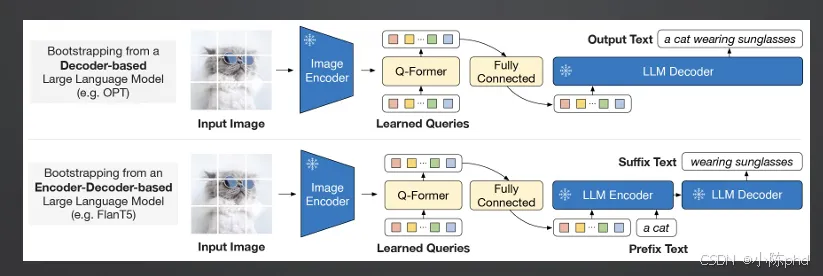
- • 采用双塔架构:独立的视觉编码器(ViT)与独立的语言大模型(LLM),大部分参数冻结,仅训练轻量级桥接模块。
- • 提出Q-Former信息提炼机制:用极少量Query Token从ViT中提取精炼视觉特征,解决视觉与语言大模型的连接效率问题。
- • 支持两种LLM适配模式:基于Decoder的OPT模型、基于Encoder-Decoder的FlanT5模型。
- • 大幅降低训练成本,仅需训练桥接模块即可实现高效跨模态融合。
- • 确立了冻结预训练大模型+轻量级桥接的工业级落地范式,几乎所有后续开源VQA模型均借鉴此思路。
2.3 第二代进阶模型:LLaVA-Next(2024)
LLaVA-Next是LLaVA家族的升级版本,基于LLaMA系列大语言模型开发,将BLIP-2的桥接机制进一步简化,达到开源模型顶尖水平。
- • 桥接模块:MLP(多层感知机)投影层,替代BLIP-2的Q-Former,架构更极简。
- • 语言端:LLaMA系列大语言模型,参数量更大、上下文窗口更长、推理能力更强。
- • 引入AnyRes任意分辨率技术,不再限制图像输入尺寸,适配更多场景。
- • 验证核心结论:当LLM基座足够强大时,极简MLP桥接的效果优于复杂的Q-Former,效率与精度双提升。
3 BLIP-2核心组件:Q-Former工作原理详解
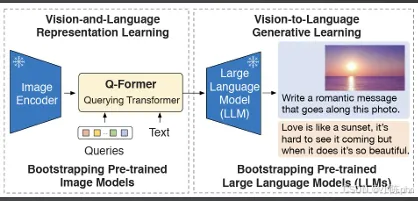
Q-Former是BLIP-2的核心,也是视觉特征向语言模型对齐的关键模块,其工作原理严格遵循原文定义,无额外拓展:
- • 输入1:Query Stream,可学习的查询向量,数量固定且极少(如32个Query Token),远小于图像特征数量。
- • 输入2:Image Stream,ViT处理后的图像Patch特征(如256个),是完整的视觉信息载体。
- • Query Stream通过多层交替的自注意力与交叉注意力学习:Query Token充当查询Q,ViT特征充当键K和值V。
- • 仅用32个Query Token完成对全部ViT视觉特征的信息提炼,实现视觉信息的高效压缩。
- • Q-Former输出的32个向量,通过线性投影转化为与LLM文本Token相同的维度。
- • 投影后的特征与文本Token拼接,直接输入LLM进行后续问答推理。
4 LLaVA-Next架构创新与技术特点
LLaVA-Next是当前开源VQA的主流实用模型

- • 放弃复杂的Q-Former,采用单层/多层MLP作为视觉-语言桥接,参数量更小、推理更快、训练更简单。
- • 基于LLaMA系列大模型,依托其成熟的Decoder-only技术、指令微调能力与GPU优化,推理稳定性更强。
- • 支持单图像多Patch、多图像、多帧视频、多视角3D数据的统一处理,从单纯VQA扩展到多模态通用感知。
- • 通过大规模指令微调,实现统一任务范式,可无缝切换问答、描述、定位、计数等多任务。
5 指令微调:统一VQA任务范式与能力提升
指令微调是VQA从单任务模型升级为通用多模态模型的核心技术,原文明确了其范式与能力提升逻辑:
5.1 传统VQA与指令微调VQA的范式对比
- • 局限:任务固定,仅能处理预设类型的问题,泛化能力差。
- • 输入:指令(根据提供的图片,请回答下面的问题)+ 具体问题(图中有多少只猫?)
- • 优势:将“回答问题”转化为通用指令遵循任务,模型可灵活适配不同任务需求。
5.2 指令微调带来的核心能力提升

- 1. 任务泛化能力:模型学会理解通用指令,无需重新训练即可适配新的问答场景。
- 2. 多任务学习能力:通过混合数据集训练,可在问答、描述、定位、推理等任务间自由切换。
- 3. 复杂推理能力:支持因果推理、关系推理、多步推理等高级视觉推理逻辑。
- 4. 抗偏差能力:可识别并纠正问题中的错误预设,输出符合事实的答案。
5.3 典型推理类型
- 1. 因果推理:根据图像与常识,解释事件发生的原因(如“为什么这个人会戴墨镜?”)。
- 2. 关系推理:描述物体间的相对位置与动作(如“空调和窗户的位置关系是什么?”)。
- 3. 多步推理:分步完成视觉感知与逻辑判断(如“先识别交通工具,再判断最快的交通工具颜色”)。
- 4. 抗偏差推理:判断问题中的错误描述并给出理由(如“图中汽车是黑色的吗?请说明理由”)。
6 VQA主流数据集与评估指标
VQA的数据集与评估指标均为行业通用标准,原文已明确核心类型,无新增虚构内容。
6.1 核心数据集
- • 基于MS COCO数据集,覆盖日常生活自然场景(街道、动物、食物、人物等)。
- • 问题聚焦基础视觉内容,是VQA领域最基础、最通用的评测数据集。
- • 基于Visual Genome数据集,问题为复杂推理型,侧重场景图理解与多跳逻辑推理。
6.2 核心评估指标
- • 允许一张图像的一个问题对应多个人工标注的合理答案。
- • 模型预测结果与所有人工答案的匹配度越高,得分越高,是VQA最核心的评测指标。
- • 将VQA任务转化为多项选择题,计算模型的分类准确率,适用于封闭答案型VQA任务。
- • 行业通用计算公式:,即所有问题的准确率平均值。
7 总结
视觉问答(VQA)作为多模态AI的核心基础任务,完成了从像素级视觉信息到语义级文本答案的转化,其模型演进清晰反映了多模态融合的技术趋势:
- 1. 从ViLBERT的双流协同注意力,到BLIP-2的双塔+Q-Former桥接,再到LLaVA-Next的极简MLP桥接,高效化、轻量化是VQA模型的核心发展方向。
- 2. 指令微调让VQA从单一问答任务,升级为通用多模态指令遵循任务,泛化能力与推理能力大幅提升。
- 3. 冻结预训练视觉/语言大模型、仅训练轻量级桥接模块,成为当前VQA模型工业落地与科研研究的主流范式。
- 4. VQA的核心价值始终围绕视觉与语言的精准对齐、事实性答案输出,是视觉推理、图文生成、具身智能等高级多模态任务的底层支撑。