摘要:前三天都是线性模型,今天换一种思路,线性不可分怎么办?递归分割一层层切下去。在 Iris 上从零实现了一棵 CART 决策树,训练、剪枝、可视化都走了一遍。决策树也是后面理解随机森林、GBDT 的底座。线性模型画一条线,决策树画一个框。线从数据中间穿过去,框可以层层嵌套,一个套一个。
前三天走完了线性模型家族:线性回归 → Ridge → Lasso → 逻辑回归。它们有一个共同点:用一条直线(或超平面)把数据分开。但现实中的很多决策不这么走。例如医生诊断不是量一个指标就下结论,而是阶梯式的:先看体温是否正常,再看白细胞,再看其他指标,逐层往下。
决策树模仿的就是这种逐层判断的思维方式。每一步只关心一个问题:选哪个特征、切在什么值上,能让分出来的两个子集不纯度最低。
一、什么是决策树?
决策树是一种基于树结构的分类模型。内部节点对应一个特征上的判断条件(特征 + 阈值),每条分支对应一个判断结果,每个叶节点对应一个分类结果。训练时从根节点开始,递归地将数据划分为不纯度更低的子集,直到满足停止条件为止。
以Iris数据集来说,要分出三种鸢尾花,先看花瓣长度,如果很短,一定是 setosa,直接分出去。剩下的再看花瓣宽度,窄的是 versicolor,还搞混的再进一步切。决策树做的就是这件事,每一步都在问:
选哪个特征、切在什么值上,能让分出来的两个子集不纯度最低?
二、Gini 不纯度:怎么衡量"纯不纯"
CART 用 Gini 不纯度来量化。公式很简单:每个类别的概率平方和取反加一。每次分裂的目标,就是选一个特征和切分点,让分出来的两个子集 Gini 加权和最小。实现上就是遍历所有特征、所有可能的切分点:
def _cart_split(self, X, y): best_gini = float('inf') for f in range(n_features): col = X[:, f] values = np.unique(col) candidates = (values[:-1] + values[1:]) / 2 # 中点作为候选 for thresh in candidates: mask = col <= thresh y_left, y_right = y[mask], y[~mask] gini = (len(y_left) * gini(y_left) + len(y_right) * gini(y_right)) / len(y) if gini < best_gini: best_gini = gini
递归地在左右子节点上重复,直到满足停止条件(深度到上限、节点样本太少、或不纯度已降为零)。
训练集的决策树结构。根节点用 petal length ≤ 2.45 一刀切下去,左边 40 个样本全是 setosa(Gini=0),直接收工。右边剩下 versicolor 和 virginica,继续用 petal length 和 petal width 逐层切。到深度 3 时每个叶子节点基本只含一种类了。每个节点旁标注了样本分布和 Gini 值,能清晰看到每次分裂后纯度如何提升。
Iris 数据集 150 条样本、4 个特征、3 个品种。选它是因为:
- 树很浅,深度 3 就到 100% 准确率,可视化不费力
- 能画边界,只用花瓣长宽两个特征就能在二维平面上画决策区域
设置 max_depth=3 训练:
训练集准确率:95.8%测试集准确率:100%
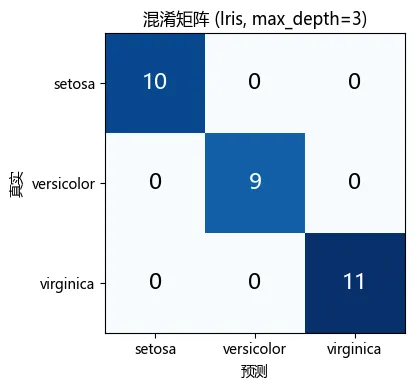
测试集 30 个样本全部分对。和 sklearn 的 DecisionTreeClassifier 对比,结果完全一致。混淆矩阵。测试集 30 个样本全部落在对角线上,setosa 10 个、versicolor 9 个、virginica 11 个,没有任何混淆。对 Iris 来说,深度 3 已经够用了。四、决策边界:树在二维空间里画什么
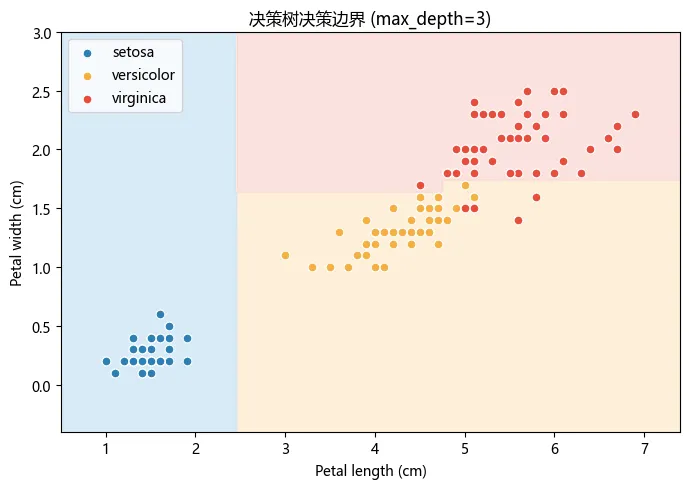
用 petal length 和 petal width 两个特征单独训练一棵树,画出决策区域: 二维决策边界。背景色块表示树的预测区域:左下方蓝色全是 setosa,中间绿色是 versicolor,右上方红色是 virginica。注意边界全是水平或垂直的,树每次只在一个特征上切一刀,所以切出来的区域永远是矩形。这和逻辑回归的斜线边界、SVM 的曲线边界都不一样。边界在 petal length = 4.75 处有一条明显的水平线,这是树的第二个关键分裂。4.75 以下继续按 petal width 细分,4.75 以上直接按另一条规则走。五、特征重要性:哪些特征真正管用
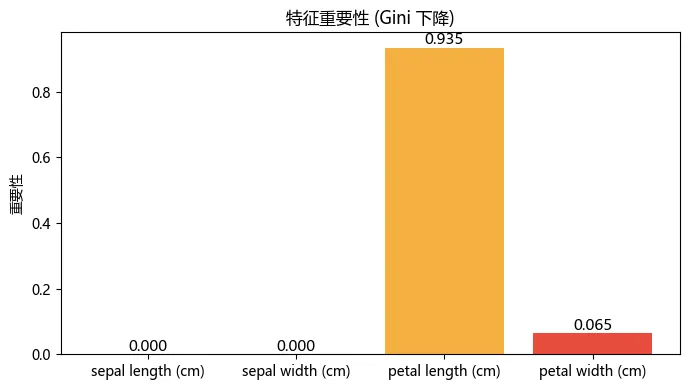
决策树有个副产品:特征重要性。每个特征在分裂时带来的 Gini 下降总量,按该节点样本数加权求和,最后归一化到 [0, 1],就是它对分类的贡献。用公式写就是:Iris 的结果很不均衡,也就是说,区分三种鸢尾花,看花瓣就够了。花萼长宽在这个任务里没有任何贡献,不是算法忽略它们,而是算法发现它们确实没必要。特征重要性。petal length(花瓣长度)占了 93.5%,petal width(花瓣宽度)占 6.5%,花萼长和宽完全不参与分裂,重要性为 0。六、超参数:树长多深合适
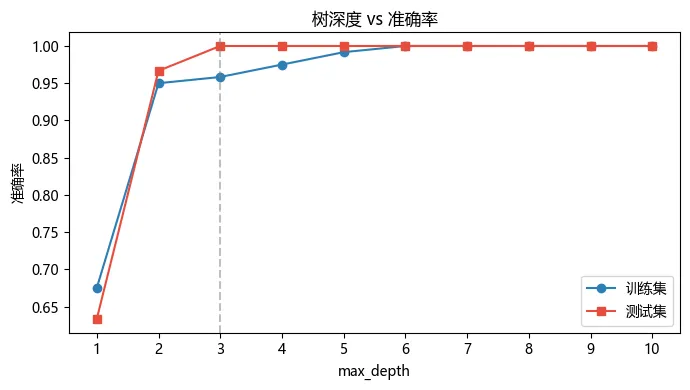
max_depth 从 1 到 10 的表现:
深度 1 只分一叉,严重欠拟合。深度 3 测试集就到顶了。再加深训练准确率还能涨(深度 6 到 100%),但测试集不动了,对 Iris 来说,深度 3 就是最佳位置。
深度 vs 准确率曲线。两条线在深度 1-2 之间急速上升,3 之后测试集稳住不动,训练集继续缓慢爬到 6 才到 100%。灰色虚线标出推荐值 3。
七、概率输出:树的信心程度
决策树还可以输出概率,每个叶子节点里各类样本的比例,就是落在该节点的样本被预测为某类的概率。比如一个叶节点有 36 个 versicolor 和 0 个其他,那么所有落到这个节点的样本,都有 100% 的把握说是 versicolor。另一个节点有 4 个 versicolor 和 4 个 virginica,那就只有 50% 的把握,树自己也知道这里不太确定。
八、和逻辑回归比一下
翻出 Day 3 的逻辑回归结果,放在一起看两种模型在 Iris 上的差异:
最本质的差异在决策边界的形状。逻辑回归画一条斜线把空间一分为二,决策树用水平线和垂直线一层层框出区域。这意味着:
- 如果类别边界接近一条直线(比如预测是否发烧,体温就是决定性指标),逻辑回归更高效
- 如果类别边界不规则、需要多次判断才能区分(比如 Iris 要同时看花瓣长和宽),决策树更灵活
准确率上决策树高 3 个百分点,但 Iris 对两者都太简单,这个差距说明不了什么。真正选哪个,取决于你的数据,线性可分的用逻辑回归,有复杂交互关系的用决策树。
小结
决策树是集成学习的基础,随机森林、GBDT 都建立在它之上。单独一棵树可能不太稳定(数据稍微一变,结构可能就不同),但作为组件非常强大:
- 可解释:每步决策能说清楚为什么
- 不挑数据:不用标准化,不用处理缺失值
- 不稳定:对数据变化敏感,方差高——所以才需要森林和 boosting
接下来会看到:随机森林用 Bagging 降低方差,GBDT 用 Boosting 降低偏差。底座都是今天这棵树。
代码仓库:模型实现见 models/decision_tree.py
完整实验见 notebooks/day4_decision_tree.ipynb