本系列前两篇文章:
使用 Claude Code 做开发时,有一个容易被忽视但至关重要的概念:context window,即上下文窗口。
它决定了 Claude 在当前会话中能"看到"多少信息,也直接影响着我们的开发体验。
Context window 里装的不只是对话历史。
它包含了文件内容、命令输出、CLAUDE.md 配置、auto memory 自动记忆、已加载的 skills,以及系统指令。
随着工作的推进,这个窗口会逐渐被填满。
虽然 Claude 会自动压缩,但会话早期给出的指令可能会在压缩过程中丢失。
这就是为什么 Claude Code 建议我们把持久化的规则写进 CLAUDE.md,而不是只在对话里口头交代。
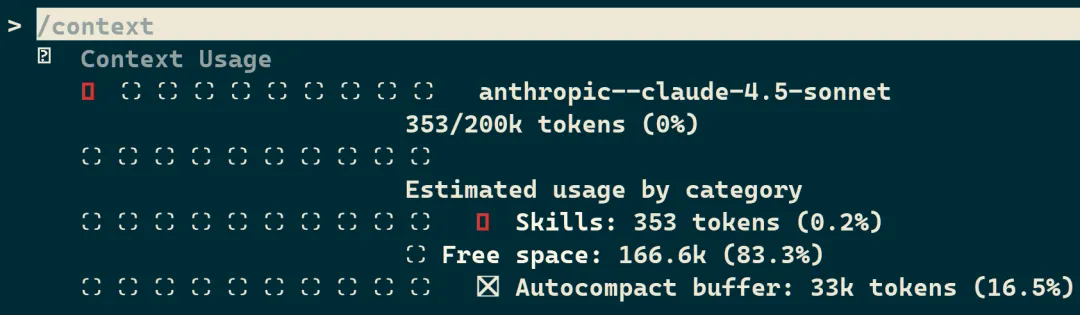
想知道当前到底是什么在占用空间?运行 /context 命令就能看到详细的分类统计。
当上下文窗口被填满时
Claude Code 在接近上下文窗口上限时会自动进行管理。
它的策略很清晰:先清理掉较旧的 tool outputs,如果还不够,就对会话历史进行摘要压缩。
这个过程中,我们的请求和关键代码片段会被保留下来,但会话早期那些详细的指令说明就可能被丢弃了。
这也是为什么反复强调要把持久化规则写进 CLAUDE.md 的原因,不能依赖对话历史来传达长期有效的约束。
如果想控制压缩过程中保留什么内容,可以在 CLAUDE.md 里添加一个 Compact Instructions 章节,或者运行 /compact 时指定焦点,比如 /compact focus on the API changes。
还有一种特殊情况:如果某个单一文件或 tool output 大到每次摘要后立刻又把上下文填满,Claude Code 会在尝试几次自动压缩后停止循环,直接显示错误提示,而不是陷入无限压缩的死循环。
MCP tool definitions 默认采用延迟加载机制,只有工具名称会占用上下文,具体的工具定义要等 Claude 真正使用某个工具时才会按需加载。
想查看各个 MCP server 的成本分布,可以运行 /mcp 命令。
用 Skills 和 Subagents 管理上下文
除了自动压缩,Claude Code 还提供了其他维度的上下文控制能力。
Skills 采用按需加载的方式。
会话启动时 Claude 能看到 skill 的描述信息,但完整内容只有在实际使用时才会加载进来。
对于手动调用的 skills,可以设置 disable-model-invocation: true,这样连描述信息都不会在启动时占用上下文。
Subagents 则拥有完全独立的上下文窗口,和主会话完全隔离。
它们的工作过程不会让主会话的上下文膨胀。
任务完成后,subagent 只会返回一个摘要。这种隔离机制正是 subagents 能够帮助长会话保持高效的关键所在。
上下文窗口的生命周期
我们可以通过一个典型的开发会话来理解上下文是如何演进的。
会话启动时:在我们输入任何内容之前,CLAUDE.md、auto memory、MCP tool names 和 skill descriptions 就已经加载到上下文里了。
如果配置了 output style 或者使用了 --append-system-prompt 参数,这些内容也会被添加到 system prompt 中。
Claude 工作时:每读取一个文件就会增加上下文占用,path-scoped rules(路径作用域规则)会在匹配的文件被读取时自动加载,PostToolUse hook 会在每次编辑操作后触发。
后续提示词:如果我们启动一个 subagent 去做研究工作,那些大文件的读取操作会发生在 subagent 自己的独立上下文窗口里,不会污染主会话。最后只有摘要和少量元数据会返回到主会话。
会话结束时:运行 /compact 会把对话历史替换成结构化的摘要。大部分启动时加载的内容会自动重新载入,具体每种机制的处理方式各有不同。
会话压缩后什么会被保留
当一个长会话被压缩时,Claude Code 对会话历史进行摘要以适应上下文窗口的限制。
我们给出的指令会产生什么效果,取决于它们是通过什么方式加载的:
| |
|---|
| System prompt 和 output style | |
| |
| |
| |
| |
| 重新注入,但每个 skill 上限 5,000 tokens,总计上限 25,000 tokens;最旧的会被丢弃 |
| |
Path-scoped rules 和嵌套的 CLAUDE.md 文件在触发文件被读取时加载到消息历史中,所以压缩操作会把它们连同其他内容一起摘要掉。
它们会在下次 Claude 读取匹配文件时重新加载。
如果某条规则必须在压缩后仍然保留,需要去掉 paths: frontmatter 或者把它移到项目根目录的 CLAUDE.md 里。
Skill bodies 在压缩后会重新注入,但大的 skills 会被截断以适应单个 skill 的容量上限,而且当总预算超标时,最早调用的 skills 会被丢弃。
截断操作保留文件开头部分,所以要把最重要的指令放在 SKILL.md 的顶部。
检查实际的会话状态
上面给出的数字只是代表性的估算。
想查看任意时刻的实际上下文使用情况,运行 /context 可以得到按类别划分的实时明细,还会给出优化建议。
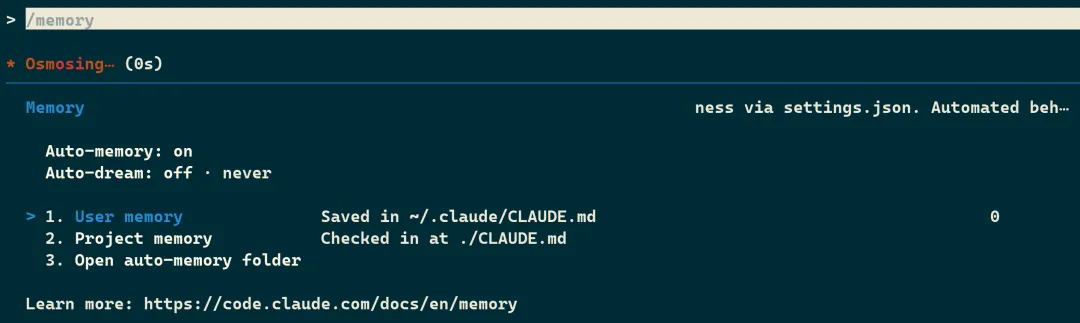
运行 /memory 可以查看启动时加载了哪些 CLAUDE.md 和 auto memory 文件。
写在最后
理解 Claude Code 的 context window 机制,说白了就是理解如何让 Claude 在长会话中始终记得我们真正在意的东西。
System prompt 和项目根目录的 CLAUDE.md 具有最高的持久性,它们是压缩风暴中的定海神针。
Auto memory 紧随其后,保证了 Claude 对项目上下文的长期记忆。
Path-scoped rules 和嵌套 CLAUDE.md 适合做局部配置,它们的「按需加载 + 压缩后丢失」特性正好符合局部规则的生命周期。
Skills 的分层加载和 subagents 的上下文隔离,则是从架构层面解决长会话中的上下文膨胀问题。
前者避免了不必要的内容在启动时就占坑,后者把复杂任务的上下文成本完全转移到独立的工作空间里。
从长期看,在 Claude Code 里做开发,把握好什么该写在哪里、什么时候会被保留、什么时候会被压缩,比单纯记住某个命令或快捷键更重要。
这些机制的设计目标很明确:让我们能在一个会话里持续工作几个小时甚至更久,而不用担心早期的关键指令会在不知不觉中被遗忘。