学习笔记:临床回顾性研究实用指南(九)混杂因素的控制方法
- 2026-05-01 15:52:28
如果一个系统能够通过执行某个过程改进它的性能,这就是学习。 ----赫尔伯特•西蒙 Herbert A. Simon |
统计学习用于对数据的预测与分析,特别是对未知新数据的预测与分析。 ----统计学习方法(第二版)李航 |
目录
1 : 1 无放回的卡钳贪婪匹配:one-to-one without replacement greedy matching with a caliper
最优匹配 optimal matching
均方误 mean squared error
最邻近匹配 nearest-neighbor matching
1:M匹配 one-to-many matching
标准化差异 standardized difference, SD
符号秩检验 sign rank test
因果推断 causal inference
时依性混杂time-dependent
边缘结构模型 marginal structural model, MSM
条件处理效应 conditional treatment effect
边际处理效应 marginal treatment effect
平均处理效应 average effect of treatment
个体 individual
总体 population
个体处理效应 individual treatment effect, ITE
平均处理效应 average treatment effect, ATE
接受处理人群的处理效应 average treatment effect among the treated, ATT
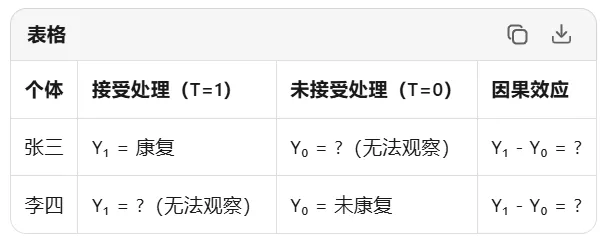
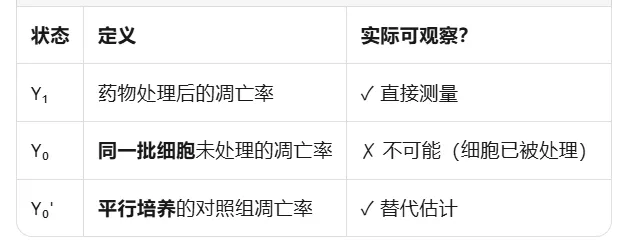
反事实框架 counterfactual framework
n. 层化,成层,阶层的形成 social stratification社会分层,社会阶层化Those individual decisions to drop out collectively amount to society-wide stratification. 那些个人决定退学总体上等于社会范围的阶层分化。 And they can avoid stratification by requiring people to clear their spaces each night. 他们可以要求同事每晚清理自己用过的空间,避免工位上堆放了层层叠叠的东西。 |
propensity 英 /prə'pensɪtɪ/美 /prə'pɛnsəti/ n. 倾向,习性 propensity to consume 消费倾向 |
关键内容摘要
定义:在给定一组观测到的预处理协变量的条件下,某个个体接受特定治疗(或暴露)的条件概率 取值范围[0,1]
核心价值:将多维混杂变量压缩为一维得分,简化混杂校正过程,使观察性研究结果更接近随机对照试验(RCT)的可靠性。
|
倾向性研究匹配
基本思想:将处理组和对照组倾向性评分相近或相同的研究对象配对
步骤:
1.估计倾向性评分值:Logistic 回归、Probit 回归、机器学习法(支持
向量机、回归树、随机森林和神经网络);
2.进行匹配:为1 : 1 无放回的卡钳贪婪匹配、最优匹配、无放回的匹配、最邻近匹配、1:M的匹配;
3.评估协变量组间均衡性:即评估处理组与对照组基线协变量的相似程度,一定程度上反映了匹配的质量;目的为比较样本间可比性。
一般用SD来评价,对于连续性变量和分类变量,其计算公式不同。
4.结局效应估计:协变量已经均衡,可以直接比较处理组和对照组对象的结局指标来估计处理效应。
5.敏感性分析:从以下角度进行考虑

注意事项:
1.倾向性评分匹配适用情形:本质是因果推断,有两个前提假设:①所有混杂因素均被观测到,②研究对象均有可能接受所有的处理;不能控制时依性混杂;
2.估计倾向性评分模型自变量的选择:
至少符合以下四个标准:
a.选入的因素一定是发生在接受处理因素之后的变量;
b.可以选入只与结局因素有关的变量;
c.可以选入既和结局因素有关又和处理因素有关的变量;
d.不可以选入只与处理因素有关的变量。
3.倾向性评分匹配vs多变量回归分析
倾向性评分逆概率加权
框架基础:边缘结构模型
基本思想:首先构造逆概率权重,然后通过该权重对原始样本进行加权,构建一个虚拟人群
概念:个体处理效应、平均处理效应、接受处理人群的处理效应
平均处理效应
处理组对象的权重为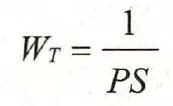
对照组对象的权重为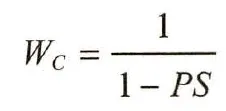
其中, PS为该对象的倾向性评分值。
接受处理人群的处理效应
处理对象的权重为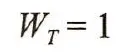
对照组对象的权重为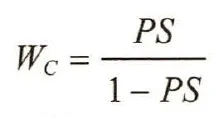
其中, PS为该对象的倾向性评分值。
一个对象出现在该组的概率越小,其在虚拟人群中的权重就越大,因此该方法被称作“逆概率”加权。
注意事项:对极端权重很敏感,可以进行极端权重截尾。
   |
【这则学习笔记更新的比较慢
一则 从未接触过的概念学起来就是比较吃力,大概看了两三遍才能觉得自己大概看懂是怎么回事儿,才将其记录下来。学习新东西,一是梳理框架,二是反复琢磨,如是而已;
二是 近期事情繁多,学习时间有限;学习是重要的,锻炼身体、维系亲情、保持心情愉快也是很重要的。一切顺其自然,只要内心还在惦着学习就好
另外,学不进去的时候看了看《女士品茶》,真的很有趣,即便是《女士品茶》这种偏科普类书籍,有些地方也是要反复看几遍才能看懂的。费希尔Fisher的天才形象已经在我心中牢牢树立了,只是,即便是这样的天才,也有不能逾越的学术障碍,似乎对于安慰自己也蛮有一些帮助。统计学和统计学的历史,都可以帮助人们缓解焦虑,如此甚好~总归有一天,要写写《女士品茶》的读后感,写写统计学如何并以何种程度帮我对抗焦虑。】
以上内容援引自《临床回顾性研究实用指南》,系自行学习总结,如有版权问题请联系删除。

