序号 | 术语 | 解释 |
1 | NLP | 自然语言处理,人工智能领域的重要分支,旨在使计算机能够理解、处理和生成人类语言。 |
2 | LLM | 大语言模型,基于预训练语言模型发展而来,通过扩大模型参数和数据规模实现的突破性成果。 |
3 | PLM | 预训练语言模型,通过在海量无监督文本上进行自监督预训练,实现强大的自然语言理解能力。 |
4 | Transformer | 完全由注意力机制构成的神经网络架构,是LLM的鼻祖及核心架构,由Encoder和Decoder两部分组成。 |
5 | 注意力机制 | 通过计算Query与Key的相关性为Value加权求和,拟合序列中每个词同其他词的相关关系。 |
6 | 自注意力 | 注意力机制的变种,计算本身序列中每个元素对其他元素的注意力分布。 |
7 | 多头注意力 | 同时对语料进行多次注意力计算,每次拟合不同关系,将多次结果拼接作为最终输出。 |
8 | 掩码自注意力 | 使用注意力掩码的自注意力机制,使模型只能使用历史信息进行预测。 |
9 | Encoder | Transformer的组成部分,用于将输入的自然语言序列编码成能够表征语义的向量或矩阵。 |
10 | Decoder | Transformer的组成部分,用于将编码结果解码成目标序列。 |
11 | Seq2Seq | 序列到序列模型,输入一个自然语言序列,输出另一个可能不等长的自然语言序列。 |
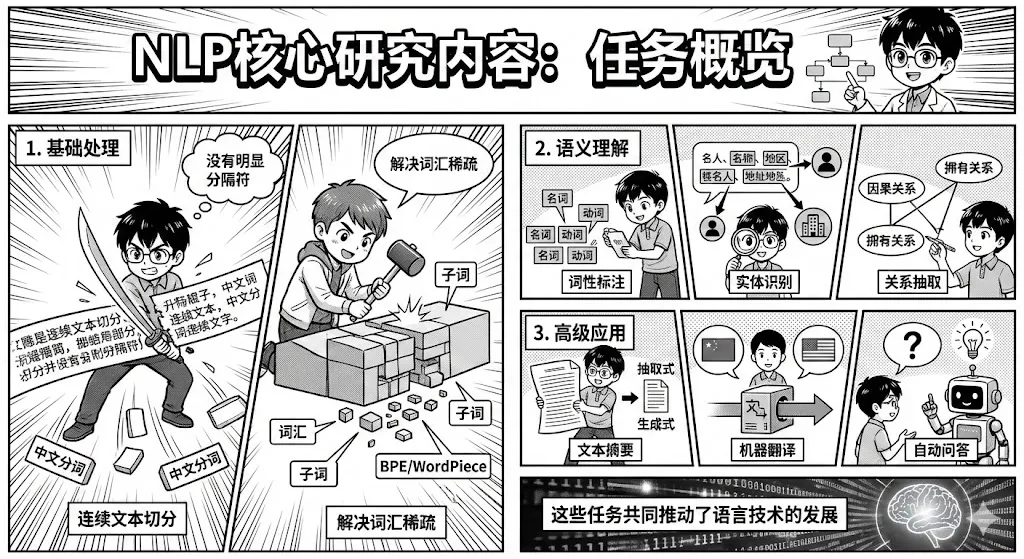
12 | 中文分词 | NLP基础任务,将连续的中文文本切分成有意义的词汇序列。 |
13 | 子词切分 | 将词汇进一步分解为更小单位的文本预处理技术,常见方法有BPE、WordPiece等。 |
14 | 词性标注 | 为文本中的每个单词分配词性标签(如名词、动词、形容词)的基础任务。 |
15 | 文本分类 | 将给定文本自动分配到一个或多个预定义类别的核心任务。 |
16 | 实体识别 | 自动识别文本中具有特定意义的实体并分类为预定义类别的关键任务。 |
17 | 关系抽取 | 从文本中识别实体之间语义关系的关键任务,对构建知识图谱具有重要意义。 |
18 | 文本摘要 | 生成简洁准确摘要来概括原文主要内容的任务,分为抽取式和生成式两大类。 |
19 | 机器翻译 | 使用计算机程序将一种自然语言自动翻译成另一种自然语言的核心任务。 |
20 | 自动问答 | 使计算机理解自然语言问题并根据数据源自动提供准确答案的高级任务。 |
21 | 词向量 | 将文本中的语言单位转换为计算机可理解的向量表示。 |
22 | N-gram模型 | 基于统计的语言模型,核心思想是一个词的出现概率仅依赖于它前面的N-1个词。 |
23 | Word2Vec | 2013年提出的词嵌入技术,通过神经网络学习词与词之间的上下文关系生成词的密集向量表示。 |
24 | ELMo | 实现一词多义、静态词向量到动态词向量跨越的模型,首次将预训练思想引入词向量生成。 |
25 | BERT | Google于2018年发布的预训练语言模型,采用Encoder-Only架构。 |