01前言
人类拥有技能的轨迹是通过理论+实践修得的。
理论获取路线大体也分两步:一、事物概念;二、事物联系。
实践就是通过动手来验证理论并内化的过程。
我们学习神经网络的历程也是这样。
02理论
2.1 神经元(Neuron)
计算单元:它接收若干输入 x1, x2, …,每个输入乘以一个权重 wi,相加后加上偏置 b,再经过一个非线性函数(激活函数)f 输出值:

权重:决定输入的重要性。
偏置:允许输出整体平移。
激活函数:制造非线性(否则无论堆多少层,都是线性变换)。
总结和比喻: 让我们把神经元的工作流程串起来,用一个完整的比喻来理解: 一个神经元就像一个“小型决策委员会”: 1收集信息(输入):委员会成员(输入数据)进来开会。 1评估重要性(权重):每个成员发言的重要性(权重)不一样。大老板的话(重要特征)权重大。 1考虑公司基调(偏置):公司本身就有一种做事倾向(偏置),比如“天生激进”或“天生保守”。 1汇总分数(计算总和):秘书把所有人的发言(输入*权重)和公司基调(偏置)加在一起,得到一个总分数 z = (x*w) + b。 1老大拍板(激活函数):最后,委员会主席(激活函数)根据这个总分数,做出最终的、规范化的决策。 1他可能说:“分数超过5?好,我们干!”(类似ReLU) 1也可能说:“我来算算,嗯,根据这个分数,我们有80%的成功率。”(类似Sigmoid) 所以,没有激活函数,神经网络就只是一堆数学计算,无法做出复杂的、非线性的决策。激活函数是赋予神经网络“灵魂”,让它能够学习和模拟世界上几乎所有复杂现象的关键部件。 |
2.2 层(Layer)与网络结构(Architecture)
多个神经元并排形成一层(Layer)。
输入层 -> 隐藏层(可以有多个) -> 输出层 构成一个网络。
常见小型网络:
1全连接网络(MLP / feedforward network)
1卷积网络(CNN)
1循环网络(RNN/LSTM)
2.3 激活函数(Activation)
Sigmoid:输出 (0,1),常用于二分类输出。
Tanh:输出 (−1,1)。
ReLU(常用):ReLU(x)=max(0,x),计算简单、训练稳定。
Softmax:把向量转换为概率分布(分类多类常用)。
2.4 损失函数(Loss)
衡量预测与真实标签的差距。
常见:
1均方误差(MSE):适用回归场景
1二元交叉熵(binary cross-entropy):适用二分类场景
1多类交叉熵(categorical cross-entropy):适用多分类场景
2.5 训练=优化(Optimization)
我们有参数(所有权重和偏置),希望最小化损失函数。
常用方法是梯度下降(Gradient Descent)或其变种(SGD、Adam 等)。
关键步骤:计算损失对每个参数的导数(梯度),并沿负梯度方向更新参数。
2.6 反向传播(Backpropagation)
通过链式法则把输出损失对每层参数的导数计算出来,从输出层往回传播。
这是神经网络高效计算梯度的算法。
2.7 训练流程概览
初始化参数(随机) → 前向传播计算预测 → 计算损失 → 反向传播计算梯度 → 更新参数(一次或多次迭代) → 重复直到收敛/满足条件。
2.8 常见问题与技巧
学习率太大:训练不稳定;太小:收敛慢。
过拟合:训练集上很好,测试集差。解决:更多数据、正则化(L2、dropout)、早停。
批量训练(mini-batch):在大数据上效率和稳定性好。
初始化权重要合理(避免梯度消失/爆炸)。
03实践
3.1 从0到1手搓一个小神经网络
下面用最简单的网络把概念、前向、反向、更新都自己纯手搓一遍,帮大家彻底搞懂它是如何运作的。
这是一个用纯 numpy 实现的简单神经网络(MLP),它的结构如下:
1输入层 2 个神经元
1隐藏层 4 个神经元(tanh 激活)
1输出层 1 个神经元(sigmoid 激活)
该神经网络用来学习 XOR(异或)这个二分类问题。
训练方法是批量梯度下降(每次用整个训练集计算梯度并更新参数)。
损失函数是二元交叉熵(binary cross-entropy)。
完整代码如下:
Python # nn_xor_numpy.py # 纯 numpy 实现:一个隐藏层的 MLP,解决 XOR(二分类) import numpy as np # --- 数据:XOR --- # shape = (行数, 列数) # ndim = 维度个数 = 2(二维矩阵) # size = 总元素个数 = 4 × 2 = 8 # XOR 是非线性可分的,线性模型学不出来,需要隐藏层。 X = np.array([ [0,0], [0,1], [1,0], [1,1] ], dtype=float) y = np.array([[0],[1],[1],[0]], dtype=float)# 二分类标签 # --- 超参数 --- np.random.seed(42) input_dim = 2 hidden_dim = 4# 隐藏单元数(增加会更容易学) output_dim = 1 lr = 0.5# 学习率 epochs = 10000 # --- 初始化权重(小随机数)--- W1 = np.random.randn(input_dim, hidden_dim) * 0.5 b1 = np.zeros((1, hidden_dim)) W2 = np.random.randn(hidden_dim, output_dim) * 0.5 b2 = np.zeros((1, output_dim)) # --- 激活函数及导数 --- def sigmoid(x): return 1 / (1 + np.exp(-x)) def sigmoid_deriv(s): return s * (1 - s)# s 已经是 sigmoid(x) # --- 训练循环(批量梯度下降)--- for epoch in range(epochs): # 前向传播 z1 = X.dot(W1) + b1# (4, hidden_dim) a1 = np.tanh(z1)# 隐藏层激活,tanh 比 sigmoid 好点 z2 = a1.dot(W2) + b2# (4,1) a2 = sigmoid(z2)# 输出概率 # 损失(平均二元交叉熵) eps = 1e-12 loss = -np.mean(y * np.log(a2 + eps) + (1-y) * np.log(1 - a2 + eps)) # 反向传播(链式法则) dout = (a2 - y) / (y.shape[0])# dLoss/dz2(for BCE with sigmoid output) dW2 = a1.T.dot(dout) db2 = np.sum(dout, axis=0, keepdims=True) da1 = dout.dot(W2.T)# (4, hidden_dim) dz1 = da1 * (1 - np.tanh(z1)**2)# tanh 导数 = 1 - tanh^2 dW1 = X.T.dot(dz1) db1 = np.sum(dz1, axis=0, keepdims=True) # 更新参数 W2 -= lr * dW2 b2 -= lr * db2 W1 -= lr * dW1 b1 -= lr * db1 # 打印损失 if epoch % 1000 == 0: preds = (a2 > 0.5).astype(int) acc = np.mean(preds == y) print(f"epoch {epoch:5d} loss={loss:.6f} acc={acc:.3f}") # 训练后结果 print("\n训练后预测:") for xi, yi, pi in zip(X, y, a2): print(f"输入 {xi} -> 预测概率 {pi[0]:.4f}, 标签 {int(yi[0])}") |
P.S:训练模型,本质就是训练参数和偏置,这里的w就是模型参数,b就是偏置。这里的 a2 就是模型推理结果。 |
程序运行结果截图为:
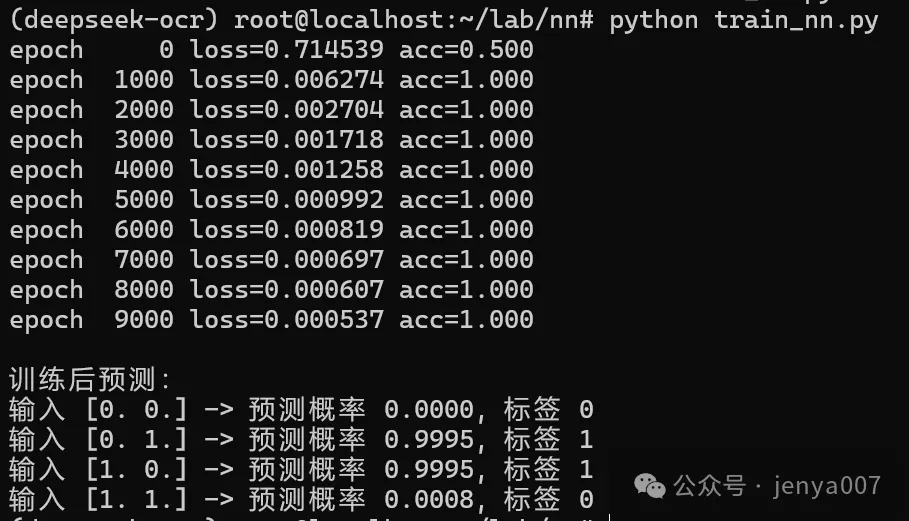
3.2 使用 PyTorch 在 MNIST 上训练一个小模型
这个例子的目的是让大家体验真实世界训练流程,包括:数据集加载、模型定义、训练循环、保存模型、评估。学习使用自动求导(Autograd)与优化器(例如 Adam)。
Python # train_mnist_pytorch.py # PyTorch 主库,用来做张量(Tensor)计算、GPU 加速等 import torch # nn:神经网络模块,用于构建网络层(如卷积、全连接)。optim:优化器模块(如 Adam、SGD) from torch import nn, optim # datasets:常用数据集的集合,这里用 MNIST。transformers:对图片做预处理(如转为 Tensor、归一化) from torchvision import datasets, transforms # DataLoader:负责把 dataset 按 batch 分批加载 from torch.utils.data import DataLoader # --- 配置 --- batch_size = 128# 一次训练喂 128 张图片,而不是一张一张训练,速度更快。 epochs = 5# 整个训练集要重复学习 5 次。 lr = 1e-3# 学习率,模型更新的步子大小。 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') print("Using device:", device) # --- 数据准备(MNIST)--- # Compose(): 先把 ToTensor 和 Normalize 这两个行为打包成流水线 # ToTensor():把 0~255 像素的图片变为 0~1 的 Tensor(浮点数)。让模型输入更小,梯度更稳,训练更快 # Normalize(mean, std):把 0~1 像素值 → 以 0.13 为中心,以 0.31 为波动;让数据分布更稳定,训练更快 # MNIST 的均值是 0.1307、标准差 0.3081(预先算好的)。 transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 加载训练集和测试集,train=True:加载训练集。train=False:加载测试集。 train_ds = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_ds= datasets.MNIST(root='./data', train=False, download=True, transform=transform) # 使用 DataLoader 打包。shuffle=True:打乱数据,避免模型死记顺序。test_loader不用 shuffle(测试顺序不重要) train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True) test_loader= DataLoader(test_ds,batch_size=batch_size, shuffle=False) # --- 模型(简单的全连接网络)--- # MNIST 图像大小是 28×28# Flatten():把 28×28 变成一维向量 784。 # nn.Linear(a, b):全连接层,相当于矩阵乘法。 # nn.ReLU():激活函数,让模型有非线性能力。 # 结构图如下:784 → 256 → ReLU → 128 → ReLU → 10 # 输出 10 类,对应数字 0~9。 class SimpleMLP(nn.Module): # 构建模型:简单的全连接网络 def __init__(self): super().__init__() self.flatten = nn.Flatten() self.net = nn.Sequential( nn.Linear(28*28, 256), nn.ReLU(), nn.Linear(256, 128), nn.ReLU(), nn.Linear(128, 10) ) # 前向传播。 # forward() 就是模型如何计算结果。PyTorch 会自动调用它。 def forward(self, x): x = self.flatten(x) return self.net(x) # 实例化模型。把模型加载到 GPU 或 CPU。 model = SimpleMLP().to(device) # 损失函数 + 优化器 criterion = nn.CrossEntropyLoss() # 分类任务常用损失函数(会做 softmax)。 optimizer = optim.Adam(model.parameters(), lr=lr) # 常用优化器,自动调整学习率,让训练更稳。 # --- 训练函数 --- def train_one_epoch(): model.train()# 启用训练模式(如 dropout) total_loss = 0.0 # 从 DataLoader 中取出一个 batch:imgs: 128 张图片;labels: 对应的数字(0~9) for imgs, labels in train_loader: imgs, labels = imgs.to(device), labels.to(device) # 清空梯度,否则梯度会累积。 optimizer.zero_grad() # 前向传播 + 损失 logits = model(imgs)# logits 是模型的输出(还未 softmax)。 loss = criterion(logits, labels)# loss 表示预测和真实标签的差距。 # 反向传播 + 更新参数 loss.backward() optimizer.step() # loss.item() 把损失变成普通数字。 total_loss += loss.item() * imgs.size(0) return total_loss / len(train_loader.dataset)# 最后返回平均损失。 # --- 评估 --- def evaluate(): model.eval()# 关闭 dropout/batchnorm 的训练模式。 correct = 0 total = 0 with torch.no_grad():# 不计算梯度(节省显存) for imgs, labels in test_loader: imgs, labels = imgs.to(device), labels.to(device) logits = model(imgs) preds = logits.argmax(dim=1) # 计算预测结果。argmax 找最大值位置 = 预测的数字 correct += (preds == labels).sum().item() total += labels.size(0) # 返回准确率(accuracy) return correct / total # --- 训练主循环 --- # 训练 5 个 epoch。 # 每个 epoch: #跑一次训练函数 #跑一次评估函数 #打印损失和准确率 for epoch in range(1, epochs+1): train_loss = train_one_epoch() test_acc = evaluate() print(f"Epoch {epoch}/{epochs}Train loss: {train_loss:.4f}Test acc: {test_acc:.4f}") # 保存模型 torch.save(model.state_dict(), "mnist_mlp.pth")# state_dict() 存模型参数(权重) print("模型已保存为 mnist_mlp.pth") |
模型最终运行结果如下图:


