Python学习笔记——Pandas 简明指南:核心概念与财务人必备操作
- 2026-04-09 18:42:49
Pandas 是一个开源的 Python 数据分析库,专门为处理表格数据(如 Excel 表格、数据库表)而设计。名称来源于“Panel Data”(面板数据),现已成数据分析领域的事实标准。其核心设计理念包括:
数据表思维:所有操作围绕“表格”展开,财务人员极易理解
向量化计算:避免循环,整列数据同时计算,速度极快
自动对齐:智能处理索引匹配,减少手动对齐错误
为什么财务人需要 Pandas?其原因包括:
突破 Excel 限制:处理百万行以上数据不卡顿
流程可追溯:代码即操作记录,审计追踪方便
自动化能力强:月度报表、重复分析可脚本化
无缝衔接:与数据库、网络数据源、可视化工具集成
下面,我们就一起来学习Pandas的基本操作。

01
—
Pandas的安装
pip install pandas
安装完毕后,在使用它们之前,我们需将其先行导入,其导入语句如下:
import pandas as pd为引用模块时书写方便,我们一般使用as为模块取个别名,上例中pd即为pandas模块的简写。
每个程序模块仅需导入一次,不需要重复导入。
02
—
核心数据结构
一、Series(系列)
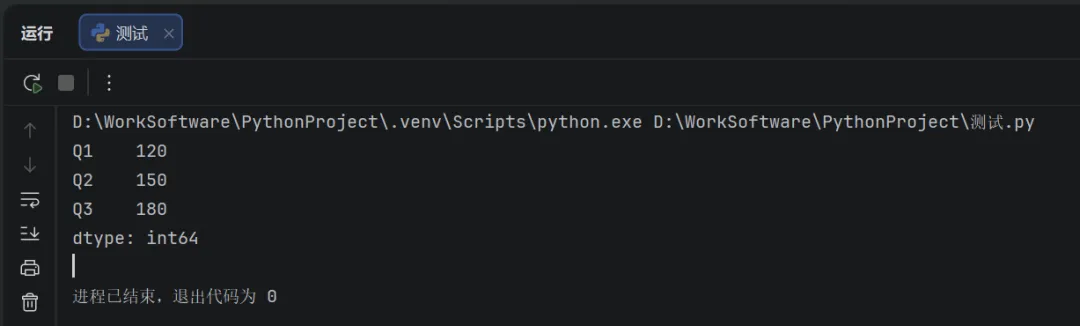
Series是一种类似一维数组的对象,即由一组数据与一组与之相关的数据标签(索引)组成。可使用pd.Series()方法创建:
import pandas as pd#创建Seriesrevenue=pd.Series([120,150,180],index=['Q1','Q2','Q3'])#打印结果print(revenue)
运行结果如下:
二、DataFrame(数据框)
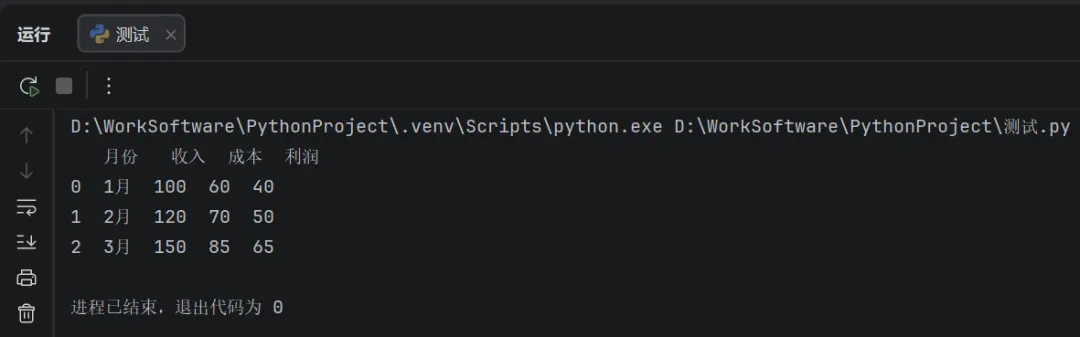
DataFrame是由一组数据与一对索引(行索引与列索引)组成的表格型数据结构。其数据形式与Excel的数据存储形式相近。其可通过pd.DataFrame()方式创建。
import pandas as pd#创建DataFrame(类似Excel整个工作表)financial_data=pd.DataFrame({'月份': ['1月', '2月', '3月'],'收入': [100, 120, 150],'成本': [60, 70, 85],'利润': [40, 50, 65]})#打印运行结果print(financial_data)
运行结果如下:
03
—
财务人日常操作语句
一、数据读取
1、EXCEL文件数据读取
以Excel文件为例,我们可以使用pd.read_excel()方法进行读取:
import pandas as pd# 读取文件df=pd.read_excel(r'D:\WorkSoftware\PythonProject\CWsoft\合同数据汇总.xlsx',sheet_name='合同数据')#打印结果print(df.head())
r为转义符,可根据需要确定是否添加; 'D:\WorkSoftware\PythonProject\CWsoft\合同数据汇总.xlsx'为文件路径; sheet_name='合同数据'为指定工作表; print(df.head())为打印结果,使用df.head()方法默认打印前五条数据。
2、CSV、TXT文件数据读取
CSV、TXT读取方法包括:
# 从 CSV 读取df = pd.read_csv('交易记录.csv', encoding='utf-8')# 从txt文件读取df = pd.read_table(r'c:\Users\Desktop\test.txt',sep=' ')
3、SQL server数据读取:
在开始前,请确保完成以下两步:
安装 ODBC 驱动:
从微软官网下载并安装 “ODBC Driver for SQL Server”。请选择与您SQL Server版本兼容的驱动程序(如 ODBC Driver 17 或 18)。
安装 Python 库:
在命令行中执行以下命令来安装必要的库:
pip install pyodbc pandas连接数据库并读取数据到 pandas DataFrame具体代码如下:
import pyodbcimport pandas as pd# 第1步:构建连接字符串(关键!)# 请根据您的实际情况修改以下参数:server = '你的服务器地址或名称' # 例如:'localhost', '192.168.1.100', 'DESKTOP-ABC123\\SQLEXPRESS'database = '你的数据库名称' # 例如:'AdventureWorks'username = '你的用户名' # 如果用SQL Server身份验证password = '你的密码' # 如果用SQL Server身份验证# 方式一:使用 SQL Server 身份验证(用户名/密码)connection_string = f'DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={server};DATABASE={database};UID={username};PWD={password}'# 方式二:使用 Windows 身份验证(信任连接,推荐在本机开发时使用)# connection_string = f'DRIVER={{ODBC Driver 17 for SQL Server}};SERVER={server};DATABASE={database};Trusted_Connection=yes;'# 第2步:建立连接并读取数据try:# 创建数据库连接conn = pyodbc.connect(connection_string)# 编写你的 SQL 查询语句sql_query = """SELECT TOP 10 *FROM 你的表名"""# 使用 pandas 的 read_sql 函数直接读取数据到 DataFramedf = pd.read_sql(sql_query, conn)# 显示数据print("成功导入数据!")print(df.head())except pyodbc.Error as e:print(f"连接或查询数据库时出错: {e}")finally:# 确保关闭连接if 'conn' in locals():conn.close()print("数据库连接已关闭。")
我的数据测试结果如下:
代码成功连接到了SQL Server数据库并导入了数据。但是pandas给出了一个警告,建议使用SQLAlchemy连接而不是直接的pyodbc连接对象。可根据实际情况按照警告的提示进行改进。
二、数据的保存
我们可以使用to_excel()、to_csv()等方法对数据进行保存。
# 保存到 Exceldf.to_excel('分析结果.xlsx', index=False) # index=False 不保存索引列# 保存到 CSVdf.to_csv('导出数据.csv', encoding='utf-8-sig')
三、数据查看和字段更名
# 查看[合同信息]工作表的字段和数据htxx= pd.read_excel(file_path, sheet_name='合同信息',usecols=['合同编号', '项目名称', '合同甲方','原始合同金额', '合同收到时间','合同大类','合同类型','子类','甲方性质','开发类型','区域'])#字段更名htxx=htxx.rename(columns={'原始合同金额':'原始金额','合同收到时间':'生效日期'})
# 查看前5行(类似 Excel 滚动查看)df.head()# 查看后5行df.tail()# 查看数据形状(行数,列数)df.shape # 返回 (1000, 15) 表示1000行15列# 查看列信息df.columns # 所有列名df.info() # 数据类型、非空值数量# 查看统计摘要(数值列)df.describe() # 计数、均值、标准差、分位数等
四、数据筛选与选择
# 选择单列(返回 Series)df['收入']# 选择多列df[['月份', '收入', '利润']]# 按行选择(类似 Excel 筛选)# 条件筛选:收入大于100的记录df[df['收入'] > 100]# 多条件筛选(且 &,或 |)df[(df['收入'] > 100) & (df['利润'] > 50)]# 按位置选择行df.iloc[0:5] # 选择前5行df.iloc[10] # 选择第10行(从0开始)
五、数据计算与新增列
# 计算利润率(新增列)df['利润率'] = df['利润'] / df['收入'] * 100# 计算同比(假设有“上年收入”列)df['收入同比增长'] = (df['收入'] - df['上年收入']) / df['上年收入'] * 100# 累计计算df['累计收入'] = df['收入'].cumsum() # 类似 Excel 下拉累加# 移动平均(3期移动平均)df['收入_MA3'] = df['收入'].rolling(window=3).mean()
六、数据清洗与处理
# 处理缺失值(财务数据常见问题)df.fillna(0) # 用0填充空值df.dropna() # 删除含空值的行# 删除重复值df.drop_duplicates()# 数据类型转换df['金额'] = df['金额'].astype('float') # 转为浮点数# 重命名列(比 Excel 重命名高效)df.rename(columns={'old_name': 'new_name'}, inplace=True)# 替换值df['科目'].replace({'A类': '资产类', 'B类': '负债类'}, inplace=True)数据排序与分组
七、数据排序与分组
# 排序(类似 Excel 排序功能)df.sort_values('利润', ascending=False) # 利润降序排列# 分组汇总(类似 Excel 数据透视表)# 按部门统计收入总和department_summary = df.groupby('部门')['收入'].sum()# 多维度分组统计summary = df.groupby(['年份', '部门']).agg({'收入': 'sum','利润': 'mean', # 平均值'成本': ['min', 'max'] # 最小值和最大值})
八、数据合并与连接
# 读取多个表格df1 = pd.read_excel('表1.xlsx')df2 = pd.read_excel('表2.xlsx')# 上下合并(类似 Excel 复制粘贴行)combined = pd.concat([df1, df2], ignore_index=True)# 左右合并(类似 VLOOKUP)merged = pd.merge(df1, df2, on='科目代码', how='left')# how参数:'left'(左连接), 'right'(右连接), 'inner'(内连接), 'outer'(全连接)
九、时间序列处理(财务分析核心)
# 将字符串转为日期类型df['日期'] = pd.to_datetime(df['日期文本'])# 按日期筛选df[df['日期'] >= '2025-01-01']# 设置日期为索引df.set_index('日期', inplace=True)# 按月重采样(月度汇总)monthly_revenue = df['收入'].resample('M').sum()# 按季度统计quarterly_summary = df['利润'].resample('Q').mean()
04
—
结语
请从实际问题开始,从工作中每一个具体痛点(如合并报表)开始,对照Excel 操作学习,思考“Excel 中怎么做 → Pandas 代码怎么写”,善用AI工具,掌握 20% 常用功能,即可满足 80% 工作所需。
财务工作的未来,属于那些既能理解业务,又能用代码优化流程的人。而Pandas 正是连接这两端的桥梁。从今天开始,尝试用 pd.read_excel()代替手动打开,你会发现一个全新的高效世界。

