《C++实战笔记》学习笔记4
- 2026-05-20 19:47:41
《C++实战笔记-罗剑锋》学习笔记4

18 | 性能分析:找出程序的瓶颈 运行阶段能做什么 系统级工具 小结 19 | 设计模式(上):C++与设计模式有啥关系? 单一职责 开闭原则 里氏替换原则 接口隔离原则 依赖反转原则 小结 20 | 设计模式(下):C++是怎么应用设计模式的? 创建型模式 结构型模式 行为模式 小结 结束语
18 | 性能分析:找出程序的瓶颈
运行阶段能做什么
在编码阶段,你会运用之前学习的各种范式和技巧,写出优雅、高效的代码,然后把它交给编译器。经过预处理和编译这两个阶段,源码转换成了二进制的可执行程序,就能够在 CPU 上“跑”起来。
在运行阶段,C++ 静态程序变成了动态进程,是一个实时、复杂的状态机,由 CPU 全程掌控。但因为 CPU 的速度实在太快,程序的状态又实在太多,所以前几个阶段的思路、方法在这个时候都用不上。
所以,在运行阶段能做、应该做的事情主要有三件:
调试(Debug) 测试(Test) 性能分析(Performance Profiling)
常用的工具是 GDB,它的关键是让高速的 CPU 慢下来,把它降速到和人类大脑一样的程度,于是,我们就可以跟得上 CPU 的节奏,理清楚程序的动态流程。
性能分析
Code Review 是一种静态的程序分析方法,在编码阶段通过观察源码来优化程序、找出隐藏的Bug。
而性能分析是一种动态的程序分析方法,在运行阶段采集程序的各种信息,再整合、研究,找出软件运行的“瓶颈”,为进一步优化性能提供依据,指明方向。
性能分析的关键就是“测量”,用数据说话。
性能分析的范围非常广,可以从 CPU 利用率、内存占用率、网络吞吐量、系统延迟等许多维度来评估。
系统级工具
Linux 系统自己就内置了很多用于性能分析的工具,比如 top、sar、vmstat、netstat,等等。
四个“高性价比”的工具:top、pstack、strace 和 perf。
top
“top”,它通常是性能分析的“起点”。无论你开发的是什么样的应用程序,敲个 top 命令,就能够简单直观地看到 CPU、内 存等几个最关键的性能指标。
一个是按“M”,看内存占用(RES/MEM),另一个是按“P”,看 CPU占用,这两个都会从大到小自动排序,方便你找出最耗费资源的进程。
也可以按组合键“xb”,然后用SHIFT + “<>”手动选择排序的列,这样查看起来更自由。
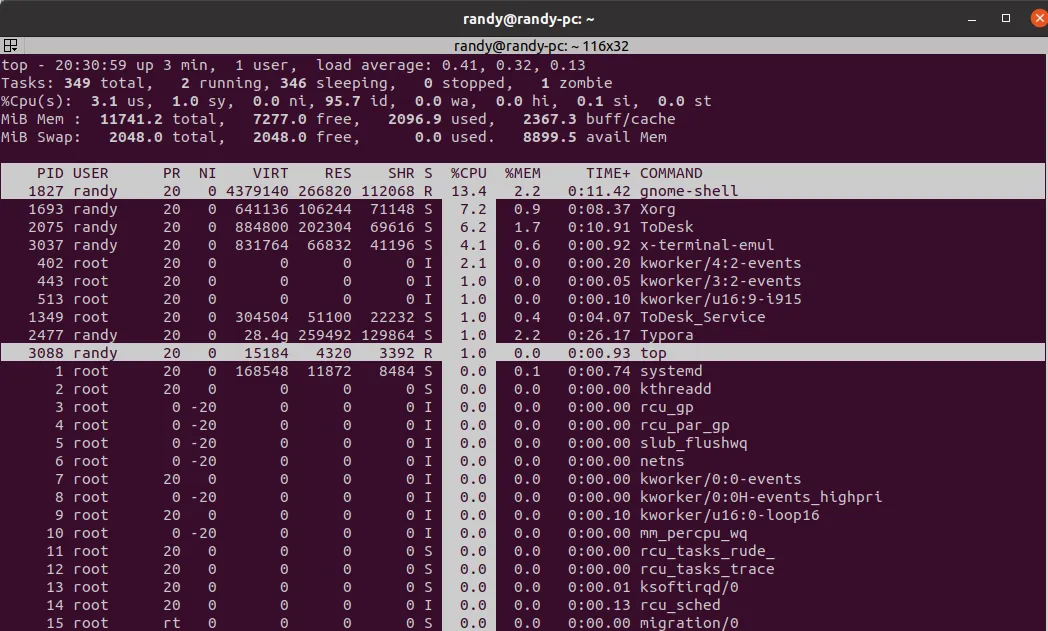
从 top 的输出结果里,可以看到进程运行的概况,知道 CPU、内存的使用率。如果你发现某个指标超出了预期,就说明可能存在问题。比如说,这里面的一个进程 CPU 使用率太高,就要深入进程内部,看看到底是哪些操作消耗了 CPU。
pstack & strace
pstack 可以打印出进程的调用栈信息,有点像是给正在运行的进程拍了个快照,能看到某个时刻的进程里调用的函数和关系,对进程的运行有个初步的印象。
pstack 显示的只是进程的一个“静态截面”,信息量还是有点少,而 strace 可以显示出进程的正在运行的系统调用,实时查看进程与系统内核交换了哪些信息。
把 pstack 和 strace 结合起来,大概就可以知道,进程在用户空间和内核空间都干了些什么。当进程的 CPU 利用率过高或者过低的时候,我们有很大概率能直接发现瓶颈所在。
perf
perf 可以说是 pstack 和 strace 的“高级版”,它按照固定的频率去“采样”,相当于连续执行多次的 pstack,然后再统计函数的调用次数,算出百分比。只要采样的频率足够大,把这些“瞬时截面”组合在一起,就可以得到进程运行时的可信数据,比较全面地描述出 CPU 使用情况。
常用的 perf 命令是“perf top -K -p xxx”,按 CPU 使用率排序,只看用户空间的调用,这样很容易就能找出最耗费 CPU 的函数。
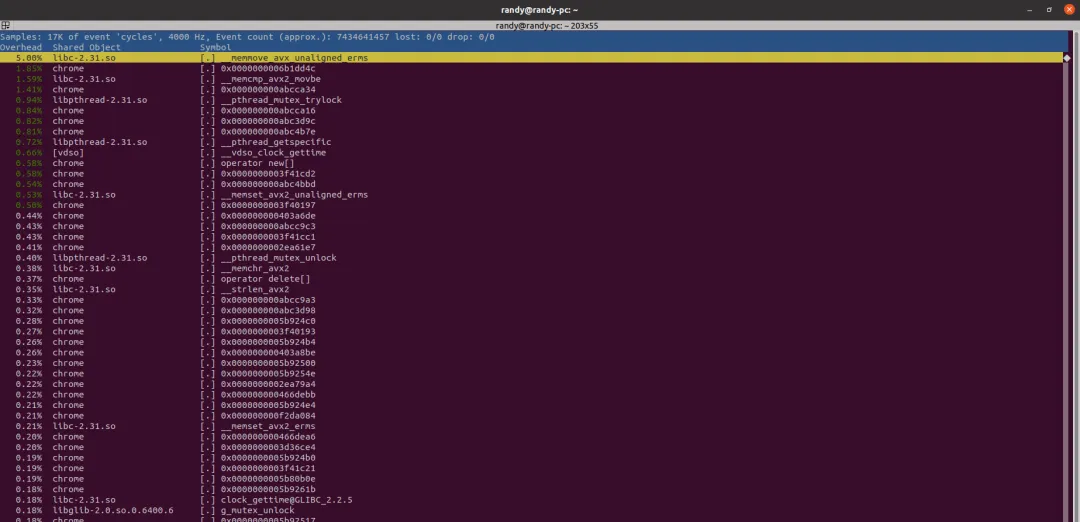
总之,使用 perf 通常可以快速定位系统的瓶颈,帮助你找准性能优化的方向。
源码级工具
top、pstack、strace 和 perf 属于“非侵入”式的分析工具,不需要修改源码,就可以在软件的外部观察、收集数据。它们虽然方便易用,但毕竟是“隔岸观火”,还是不能非常细致地分析软件,效果不是太理想。
所以,还需要有“侵入”式的分析工具,在源码里“埋点”,直接写特别的性能分析代码。这样针对性更强,能够有目的地对系统的某个模块做精细化分析,拿到更准确、更详细的数据。其实,这种做法你并不陌生,比如计时器、计数器、关键节点打印日志,等等,只是通常并没有上升到性能分析的高度,手法比较“原始”。
推荐一个专业的源码级性能分析工具:GooglePerformance Tools,一般简称为 gperftools。它是一个 C++ 工具集,里面包含了几个专门的性能分析工具(还有一个高效的内存分配器 tcmalloc),分析效果直观、友好、易理解,被广泛地应用于很多系统,经过了充分的实际验证。
apt-get install google-perftoolsapt-get install libgoogle-perftools-devgperftools 的性能分析工具有 CPUProfiler 和 HeapProfiler 两种,用来分析 CPU 和内存。不过,如果总是使用智能指 针、标准容器,不使用 new/delete,就完全可以不用关心HeapProfiler。
CPUProfiler 的原理和 perf 差不多,也是按频率采样,默认是每秒100 次(100Hz),也就是每 10 毫秒采样一次程序的函数调用情况。它的用法也比较简单,只需要在源码里添加三个函数:
ProfilerStart(),开始性能分析,把数据存入指定的文件里;ProfilerRegisterThread(),允许对线程做性能分析;ProfilerStop(),停止性能分析。
所以,只要把想做性能分析的代码“夹”在这三个函数之间就行,运行起来后,gperftools 就会自动产生分析数据。
为了写起来方便,我用 shared_ptr 实现一个自动管理功能。这里利用了 void* 和空指针,可以在智能指针析构的时候执行任意代码(简单的 RAII 惯用法):
#include<iostream>#include<string>#include<memory>#include<cassert>#include<regex>// gperftools 性能分析头文件(需提前安装 gperftools 库)#include<gperftools/profiler.h>// 2. 声明常用命名空间(简化代码书写)usingnamespacestd;// 3. 补充缺失的 make_regex 函数(封装正则对象创建)// 适配 C++11 及以上的 regex 库auto make_regex = [](conststring &pattern){return regex(pattern); // 构造 std::regex 对象并返回};// 4. 补充缺失的 make_match 函数(封装匹配结果对象)auto make_match = [](){return smatch(); // 构造 std::smatch 对象(用于 string 匹配)};intmain(){ // 程序入口函数(必须补充)auto make_cpu_profiler = // lambda表达式启动性能分析 [](conststring &filename) // 传入性能分析的数据文件名 { ProfilerStart(filename.c_str()); // 启动性能分析 ProfilerRegisterThread(); // 对线程做性能分析returnstd::shared_ptr<void>( // 返回智能指针nullptr, // 空指针,只用来占位 [](void *) { // 删除函数执行停止动作 ProfilerStop(); // 停止性能分析 }); };auto cp = make_cpu_profiler("case1.perf"); // 启动性能分析auto str = "neir:automata"s; // C++14 字符串字面量(需开启 -std=c++14 编译选项)for (int i = 0; i < 1000; i++) { // 循环一千次auto reg = make_regex(R"(^(\w+)\:(\w+)$)"); // 正则表达式对象 应移到循环外auto what = make_match(); assert(regex_match(str, what, reg)); // 正则匹配 }cout << "程序执行完成!正则匹配全部通过断言验证" << endl;return0;}编译:g++ -std=c++14 -o regex_perf t_regex_perf.cpp -lprofiler -lpthread
作者特意在 for 循环里定义了正则对象。编译运行后会得到一个“case1.perf”的文件,里面就是 gperftools 的分析数据,但它是二进制的,不能直接查看,如果想要获得可读的信息,还需要另外一个工具脚本 pprof。
git clone git@github.com:gperftools/gperftools.gitpprof --text ./a.out case1.perf > case1.txtFile: regex_perfType: cpuShowing nodes accounting for 160ms, 100% of 160ms total flat flat% sum% cum cum% 20ms 12.50% 12.50% 20ms 12.50% __nss_database_lookup 10ms 6.25% 18.75% 10ms 6.25% [libstdc++.so.6.0.28] 10ms 6.25% 25.00% 20ms 12.50% __cxxabiv1::__vmi_class_type_info::__do_dyncast 10ms 6.25% 31.25% 10ms 6.25% __gnu_cxx::__ops::__iter_equals_val 10ms 6.25% 37.50% 10ms 6.25% __gnu_cxx::new_allocator::allocate 10ms 6.25% 43.75% 10ms 6.25% std::_Vector_base::~_Vector_base 10ms 6.25% 50.00% 30ms 18.75% std::__copy_move_a2 10ms 6.25% 56.25% 30ms 18.75% std::__cxx11::regex_traits::transform 10ms 6.25% 62.50% 10ms 6.25% std::__find_if 10ms 6.25% 68.75% 10ms 6.25% std::__niter_base 10ms 6.25% 75.00% 10ms 6.25% std::__niter_wrap 10ms 6.25% 81.25% 10ms 6.25% std::bitset::reference::operator= 10ms 6.25% 87.50% 10ms 6.25% std::ctype::tolower 10ms 6.25% 93.75% 40ms 25.00% std::uninitialized_copy 10ms 6.25% 100% 60ms 37.50% std::vector::vector 0 0% 100% 20ms 12.50% __dynamic_cast 0 0% 100% 160ms 100% __libc_start_main 0 0% 100% 160ms 100% _start 0 0% 100% 160ms 100% main 0 0% 100% 10ms 6.25% std::_Construct 0 0% 100% 10ms 6.25% std::_Function_base::_Base_manager::_M_clone 0 0% 100% 10ms 6.25% std::_Function_base::_Base_manager::_M_manager 0 0% 100% 10ms 6.25% std::_Vector_base::_M_allocate 0 0% 100% 160ms 100% std::__cxx11::basic_regex::basic_regex 0 0% 100% 10ms 6.25% std::__cxx11::collate::do_transform 0 0% 100% 10ms 6.25% std::__cxx11::collate::transform 0 0% 100% 10ms 6.25% std::__cxx11::regex_traits::isctype 0 0% 100% 110ms 68.75% std::__cxx11::regex_traits::transform_primary 0 0% 100% 10ms 6.25% std::__detail::_BracketMatcher::_BracketMatcher 0 0% 100% 140ms 87.50% std::__detail::_BracketMatcher::_M_apply 0 0% 100% 140ms 87.50% std::__detail::_BracketMatcher::_M_apply() const::{lambda()#1}::operator() 0 0% 100% 150ms 93.75% std::__detail::_BracketMatcher::_M_make_cache 0 0% 100% 150ms 93.75% std::__detail::_BracketMatcher::_M_ready 0 0% 100% 160ms 100% std::__detail::_Compiler::_Compiler 0 0% 100% 150ms 93.75% std::__detail::_Compiler::_M_alternative 0 0% 100% 150ms 93.75% std::__detail::_Compiler::_M_atom 0 0% 100% 150ms 93.75% std::__detail::_Compiler::_M_disjunction 0 0% 100% 150ms 93.75% std::__detail::_Compiler::_M_insert_character_class_matcher 0 0% 100% 150ms 93.75% std::__detail::_Compiler::_M_term 0 0% 100% 10ms 6.25% std::__detail::_NFA::_M_insert_accept 0 0% 100% 10ms 6.25% std::__detail::_NFA::_M_insert_state 0 0% 100% 10ms 6.25% std::__detail::_State::_State 0 0% 100% 160ms 100% std::__detail::__compile_nfa 0 0% 100% 40ms 25.00% std::__uninitialized_copy::__uninit_copy 0 0% 100% 40ms 25.00% std::__uninitialized_copy_a 0 0% 100% 10ms 6.25% std::__uninitialized_move_if_noexcept_a 0 0% 100% 10ms 6.25% std::allocator_traits::allocate 0 0% 100% 30ms 18.75% std::copy 0 0% 100% 20ms 12.50% std::find 0 0% 100% 10ms 6.25% std::function::function 0 0% 100% 30ms 18.75% std::use_facet 0 0% 100% 40ms 25.00% std::vector::_M_range_initialize 0 0% 100% 10ms 6.25% std::vector::_M_realloc_insert 0 0% 100% 10ms 6.25% std::vector::emplace_back 0 0% 100% 10ms 6.25% std::vector::push_back 0 0% 100% 10ms 6.25% std::vector::~vector 0 0% 100% 160ms 100% {lambda(std::__cxx11::basic_string const&)#1}::operator()pprof 的文本分析报告和 perf 的很像,也是列出了函数的采样次数和百分比,但因为是源码级的采样,会看到大量的内部函数细节,虽然很详细,但很难找出重点。
好在 pprof 也能输出图形化的分析报告,支持有向图和火焰图,需要你提前安装 Graphviz 和 FlameGraph:
apt-get install graphvizgit clonegit@github.com:brendangregg/FlameGraph.gitpprof --svg ./regex_perf case1.perf > case1.svg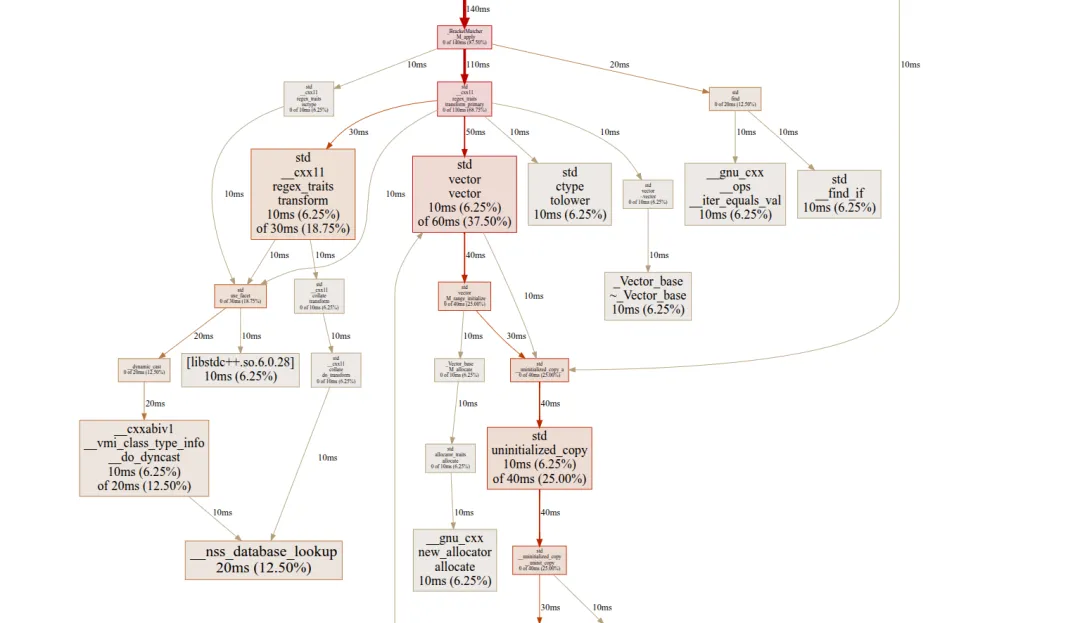
就可以使用“ --svg ”“ --collapsed ”等选项,生成更直观易懂的图形报告了
pprof --svg ./a.out case1.perf > case1.svgpprof --collapsed ./a.out case1.perf > case1.cbtflamegraph.pl case1.cbt > flame.svgflamegraph.pl --invert --color aqua case1.cbt > icicle.svg
这张火焰图实际上是“倒置”的冰柱图,显示的是自顶向下查看函数的调用栈。
由于 C++ 有名字空间、类、模板等特性,函数的名字都很长,看起来有点费劲,不过这样也比纯文本要直观一些,可以很容易地看出,正则表达式占用了绝大部分的 CPU 时间。再仔细观察的话,就会发现,_Compiler() 这个函数是真正的“罪魁祸首”。
现在就可以优化代码了,把创建正则对象的语句提到循环外面:
auto reg = make_regex(R"(^(\w+)\:(\w+)$)"); // 正则表达式对象 应移到循环外 auto what = make_match();for (int i = 0; i < 1000; i++) { // 循环一千次 assert(regex_match(str, what, reg)); // 正则匹配 }可以去看gperftools的官方文档了解更多的用法,比如使用环境变量和信号来控制启停性能分析,或者链接 tcmalloc 库,优化 C++ 的内存分配速度。
小结
perf和gperftools的性能分析基于“采样”,所以数据只具有统计意义,每次的分析结果不可能完全相同,只要数据大体上一致,就没有问题。
GCC/Clang内置了Google开发的Sanitizer工具,编译时使用“fsanitize:=address”就可以检查可能存在的内存泄漏。如果仅仅在CMakeLists.txt中增加这个编译选项,则只有程序结束的时候才会显示内存泄漏情况。
option(ENABLE_ASAN "Enable AddressSanitizer" ON)if(ENABLE_ASAN) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address -fno-omit-frame-pointer -g -O0 -ldw") set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -fsanitize=address") set(CMAKE_SHARED_LINKER_FLAGS "${CMAKE_SHARED_LINKER_FLAGS} -fsanitize=address")endif()火焰图由Brendan Gregg发明,把函数堆栈折叠为“可视化”的集合,从全局视角查看整个程序的调用栈执行情况。因为它像是一簇簇燃烧的火苗,所以被称为“火焰图”。
基于动态追踪技术和火焰图,OpenResty公司开发出了全新的性能分析工具“OpenResty XRay”,看网站介绍,功能非常强大,感兴趣的话,可以去申请试用。
19 | 设计模式(上):C++与设计模式有啥关系?
应该去关注它的参与者、设计意图、面对的问题、应用的场合、后续的效果等代码之外的部分,它们通常比实现代码更重要。
因为代码是“死”的,只能限定由某几种语言实现,而模式发现问题、分析问题、解决问题的思路是“活”的,适用性更广泛,这种思考“What、Where、When、Why、How”并逐步得出结论的过程,才是设计模式专家经验的真正价值。
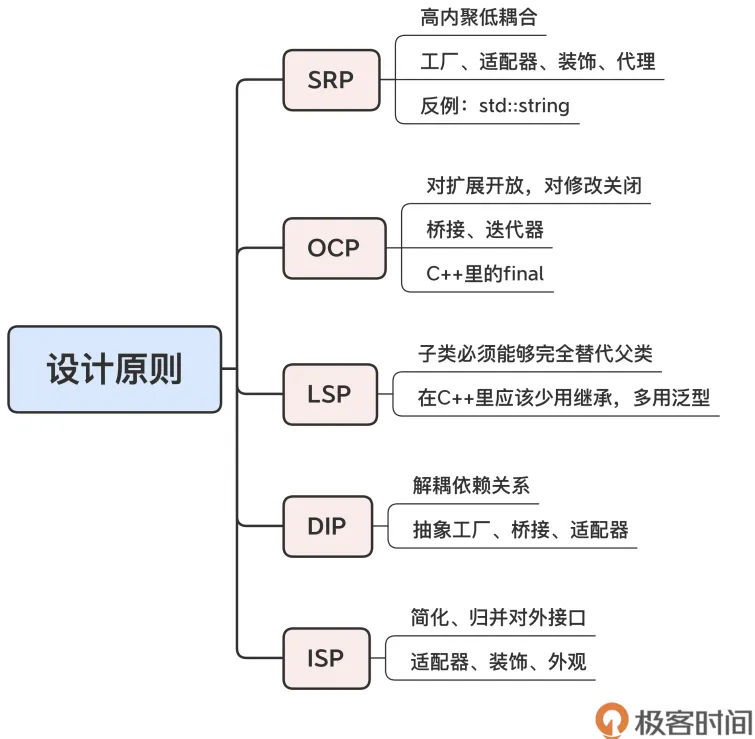
“设计原则”最常用有 5 个原则,也就是常说的“SOLID”。
SRP,单一职责(Single ResponsibilityPrinciple);
OCP,开闭(Open Closed Principle);
LSP,里氏替换(Liskov Substitution Principle);
ISP,接口隔离(Interface-Segregation Principle);
DIP,依赖反转,有的时候也叫依赖倒置(Dependency Inversion Principle)。
单一职责
单一职责原则,简单来说就是“不要做多余的事”,更常见的说法就是“高内聚低耦合”。在设计类的时候,要尽量缩小“粒度”,功能
明确单一,不要设计出“大而全”的类。
使用单一职责原则,经常会得到很多“短小精悍”的对象,这时候,就需要应用设计模式来组合、复用它们了,比如,使用工厂来分类创建对象、使用适配器、装饰、代理来组合对象、使用外观来封装批量的对象。
单一职责原则的一个反例是 C++ 标准库里的字符串类 string,它集成了字符串和字符容器的双重身份,接口复杂,让人无所适从(所以,我们应该只把它当作字符串,而把字符容器的工作交给vector<char>)。
开闭原则
开闭原则,也许是最“模糊”的设计原则了,通常的表述是“对扩展开放,对修改关闭”。
可以反过来理解这个原则,在设计类的时候问一下自己,这个类封装得是否足够好,是否可以不改变源码就能够增加新功能。如果答案是否定的(要改源码),那就说明违反了开闭原则。
应用开闭原则的关键是做好封装,隐藏内部的具体实现细节,然后开放足够的接口,这样外部的客户代码就可以只通过接口去扩展功能,而不必侵入类的内部。可以在一些结构型模式和行为模式里找到开闭原则的“影子”:比如桥接模式让接口保持稳定,而另一边的实现任意变化;又比如迭代器模式让集合保持稳定,改变访问集合的方式只需要变动迭代器。
C++ 语言里的 final 关键字也是实践开闭原则的“利器”,把它用在类和成员函数上,就可以有效地防止子类的修改。
里氏替换原则
里氏替换原则,意思是子类必须能够完全替代父类。
这个原则就是说子类不能改变、违反父类定义的行为。像在第 5 讲里说的正方形、鸟类的例子,它们就是违反了里氏替换原则。
接口隔离原则
接口隔离原则,它和单一职责原则有点像,但侧重点是对外的接口而不是内部的功能,目标是尽量简化、归并给外界调用的接口,避免写出大而不当的“面条类”。
大多数结构型模式都可以用来实现接口隔离,比如,使用适配器来转换接口,使用装饰模式来增加接口,使用外观来简化复杂系统的接口。
依赖反转原则
依赖反转原则,个人觉得是一个比较难懂的原则,上层要避免依赖下层的实现细节,下层要反过来依赖上层的抽象定义,说白了,大概就是“解耦”吧。
模板方法模式可以算是比较明显的依赖反转的例子,父类定义主要的操作步骤,子类必须遵照这些步骤去实现具体的功能。如果单从“解耦”的角度来理解的话,存在上下级调用关系的设计模式都可以算成是依赖反转,比如抽象工厂、桥接、适配器。
还有两个比较有用:DRY(Don’t Repeate Yourself)和 KISS(Keep It Simple Stupid)。
它们的含义都是要让代码尽量保持简单、简洁,避免重复的代码,这在 C++ 里可以有很多方式去实现,比如用宏代替字面值,用 lambda表达式就地定义函数,多使用容器、算法和第三方库。
小结
面向对象是主流编程范式,使用设计模式可以比较容易地得到良好的面向对象设计;
经典的设计模式有 23 个,分成三大类:创建型模式、结构型模式和行为模式;
应该从多角度、多方面去研究设计模式,多关注代码之外的部分,学习解决问题的思路;
设计原则是设计模式之上更高层面的指导思想,适用性强,但可操作性弱,需要多在实践中体会;
最常用的五个设计原则是“SOLID”,此外,还有“DRY”和“KISS”。
设计模式虽然很好,但它绝不是包治百病的“灵丹妙药”。如果不论什么项目都套上设计模式,就很容易导致过度设计,反而会增加复杂度,僵化系统。
对于C++ 程序员来说,更是要清楚地认识到这一点,因为在C++ 里,不仅有面向对象编程,还有泛型编程和函数式编程等其他式,所以领会它的思想,在恰当的时候改用模板 / 泛型 /lambda 来替换“纯”面向对象,才是使用设计模式的最佳做法。
20 | 设计模式(下):C++是怎么应用设计模式的?
创建型模式
创建型模式,它隐藏了类的实例化过程和细节,让对象的创建独立于系统的其他部分。
创建型模式不多,一共有 5 个,最有用的是单件和工厂。
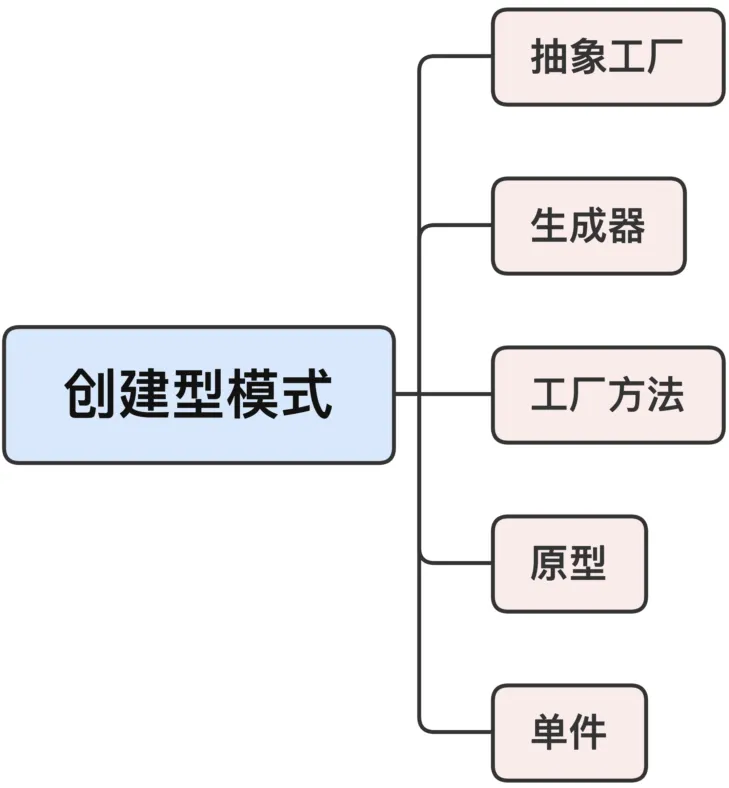
单件
单件很简单,要点在于控制对象的创建数量,只能有一个实例。
关于单件模式,一个“老生常谈”的话题是“双重检查锁定”,它可以用来避免在多线程环境里多次初始化单件,写起来特别繁琐。
使用 call_once,可以很轻松地解决这个问题,但如果你想要更省事的话,其实在 C++ 里还有一种方法(C++ 11 之后),就是直接使用函数内部的 static 静态变量。C++ 语言会保证静态变量的初始化是线程安全的,绝对不会有线程冲突。
auto& instance()// 生产单件对象的函数{static T obj; // 静态变量return obj; // 返回对象的引用}工厂模式
指的是抽象工厂、工厂方法这两个模式,因为它们就像是现实世界里的工厂一样,专门用来生产对象。
抽象工厂是一个类,而工厂方法是一个函数,在纯面向对象范式里,两者的区别很大。而 C++ 支持泛型编程,不需要特意派生出子类,只要接口相同就行,所以,这两个模式在 C++ 里用起来也就更自由一些,界限比较模糊。
可以用 DRY(Don’t Repeate Yourself)原则来理解,也就是说尽量避免重复的代码,简单地认为它就是“对 new 的封装”。
想象一下,如果程序里到处都是“硬编码”的 new,一旦设计发生变动,比如说把“new 苹果”改成“new 梨子”,你就需要把代码里所有出现 new 的地方都改一遍,不仅麻烦,而且很容易遗漏,甚至是出错。如果把 new 用工厂封装起来,就形成了一个“中间层”,隔离了客户代码和创建对象,两边只能通过工厂交互,彼此不知情,也就实现了解耦,由之前的强联系转变成了弱联系。所以,你就可以在工厂模式里拥有对象的“生杀大权”,随意控制生产的方式、生产的时机、生产的内容。
make_unique()、make_shared() 这两个函数,就是工厂模式的具体应用,它们封装了创建的细节,看不见 new,直接返回智能指针对象,而且接口更简洁,内部有更多的优化。
作者这个观点挺新颖的,用了这么久才恍然大悟:
工厂模式的核心本质是「封装对象的创建过程,让调用方无需关心创建细节」,而 make_unique()/make_shared() 完美契合这一点:不仅封装了「裸 new」的创建细节,还统一了创建接口,简化调用,无论创建什么类型的对象,接口都是统一的 make_xxx<类型>(参数),无需关注不同类型的创建差异。
// 不用工厂函数(裸new,需手动管理)std::unique_ptr<int> p1(newint(10)); // 用make_unique(工厂函数,封装new)auto p2 = std::make_unique<int>(10); // 调用方完全看不到new,创建细节被封装// 创建int对象auto p1 = std::make_unique<int>(10);// 创建自定义类对象auto p2 = std::make_shared<MyClass>(100, "test");// 接口一致,调用方只需传类型和构造参数make_shared():单次内存分配(同时分配对象内存和控制块内存,而裸 new+shared_ptr 是两次分配),效率更高;异常安全:避免「裸 new 后智能指针构造前」的内存泄漏(比如 func(std::shared_ptr<int>(new int(10)), may_throw())可能泄漏,而func(std::make_shared<int>(10), may_throw())不会)。
还有用函数抛出异常、创建正则对象、创建 Lua 虚拟机,其实也都是应用了工厂模式。
使用工厂模式的关键,就是要理解它面对的问题和解决问题的思路,比如说创建专属的对象、创建成套的对象,重点是“如何创建对象、创建出什么样的对象”,用函数或者类会比单纯用 new 更灵活。
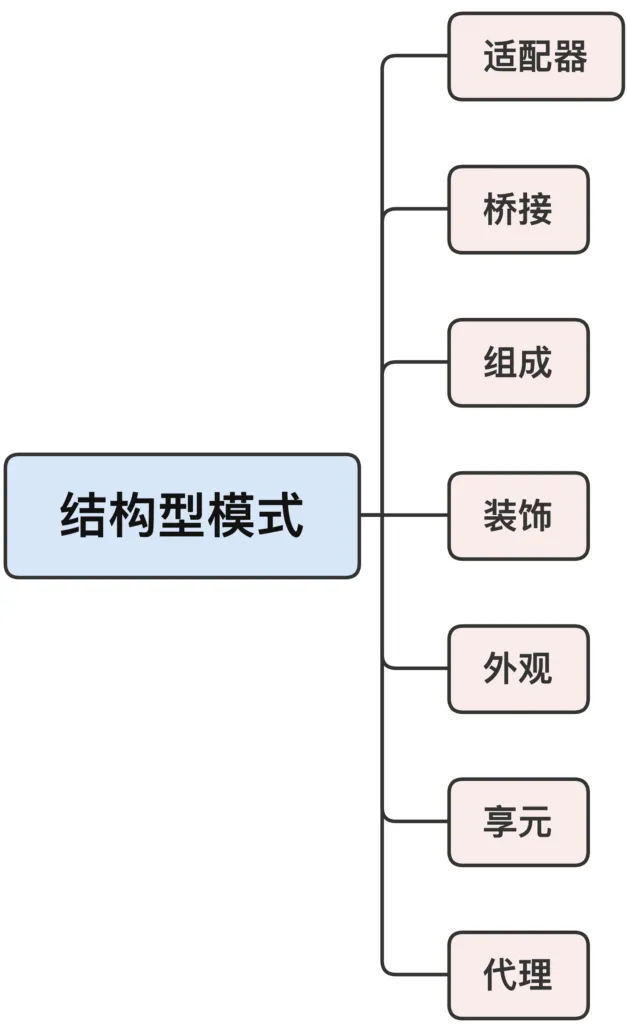
结构型模式
结构型模式,它关注的是对象的静态联系,以灵活、可拆卸、可装配的方式组合出新的对象。
结构型模式的重要特点:虽然它会有多个参与者,但最后必定得到且使用的是“一个”对象,而不是“多个”对象。
结构型模式一共有 7 个,其中,在 C++ 里比较有用、常用的是适配器、外观和代理。
适配器模式
适配器模式的目的是接口转换,不需要修改源码,就能够把一个对象转换成可以在本系统中使用的形式。
打个比方,就像是拿到了一个英式电源插头,无法插到国标插座上,但你不必拿工具去拆开插头改造,只要买个转换头就行。适配器模式在 C++ 里多出现在有第三方库或者外部接口的时候,通常这些接口不会恰好符合我们自己的系统,功能很好,但不能直接用,想改源码很难,甚至是不可能的。所以,就需要用适配器模式给“适配”一下,让外部工具能够“match”我们的系统,而两边都不需要变动,“皆大欢喜”。
容器 array 就是一个适配器,包装了 C++的原生数组,转换成了容器的形式,让“裸内存数据”也可以接入标准库的泛型体系。
array<int, 5> arr = {0,1,2,3,4};auto b = begin(arr);auto e = end(arr);for_each(b, e, [](int x){...});外观模式
外观模式封装了一组对象,目的是简化这组对象的通信关系,提供一个高层次的易用接口,让外部用户更容易使用,降低系统的复杂度。
外观模式的特点是内部会操作很多对象,然后对外表现成一个对象。使用它的话,你就可以不用“事必躬亲”了,只要发一个指令,后面的杂事就都由它代劳了,就像是一个“大管家”。
外观模式并不绝对控制、屏蔽内部包装的那些对象。如果你觉得外观不好用,完全可以越过它,自己“深入基层”,去实现外观没有提供的功能。
前面提到的函数 async() 就是外观模式的一个例子,它封装了线程的创建、调度等细节,用起来很简单,但也不排斥你直接使用thread、mutex 等底层线程工具。
auto f = std::async([](){...});f.wait();代理模式
它和适配器有点像,都是包装一个对象,但关键在于它们的目的、意图有差异:不是为了适配插入系统,而是要“控制”对象,不允许外部直接与内部对象通信,所以叫作“代理”。
代理模式的应用非常广泛,如果你想限制、屏蔽、隐藏、增强或者优化一个类,就可以使用代理。这样,客户代码看到的只是代理对象,不知道原始对象(被代理的对象)是什么样,只能用代理对象给出的接口,这样就实现了控制的目的。
代理在 C++ 里的一个典型应用就是智能指针,它接管了原始指针,限制了某些危险操作,并且添加了自动生命周期管理,虽然少了些自由,但获得了更多的安全。
行为模式
它描述了对象之间动态的消息传递,也就是对象的“行为”、工作的方式。
行为模式比较多,有 11 个,这是因为,面向对象的设计更注重运行时的组合,比静态的组合更能增加系统的灵活性和可扩展性。
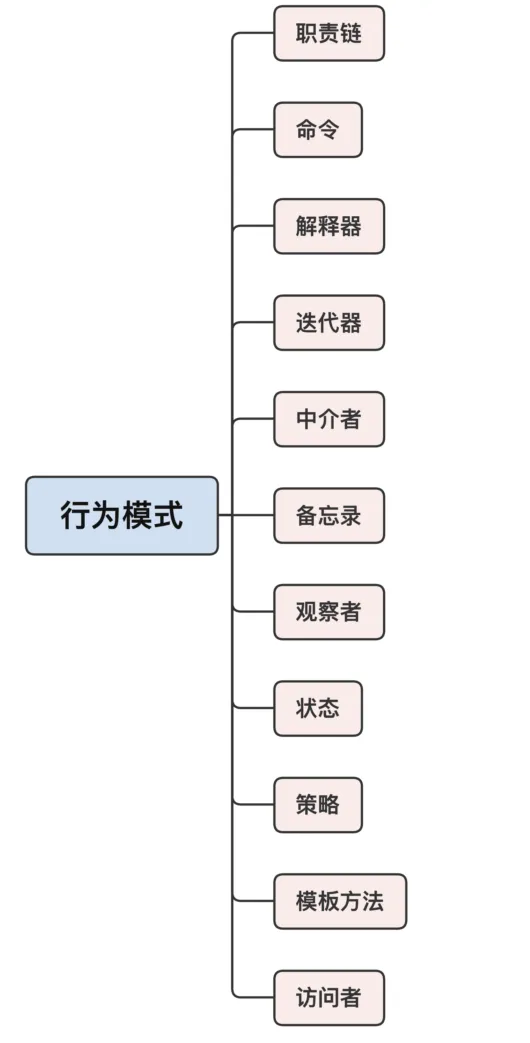
因为行为模式都是在运行时才建立联系,所以通常都很复杂,不太好理解对象之间的关系和通信机制。
比较难用,或者说是要尽量避免使用的模式有解释器和中介者,它们的结构比较难懂,会增加系统的复杂度。而比较容易理解、容易使用的有职责链、命令和策略。
职责链和命令这两个模式经常联合起来使用。职责链把多个对象串成一个“链条”,让链条里的每个对象都有机会去处理请求。而请求通常使用的是命令模式,把相关的数据打包成一个对象,解耦请求的发送方和接收方。
其实,你仔细想一下就会发现,C++ 的异常处理机制就是“职责链 + 命令”的一个实际应用。在异常处理的过程中,异常类 exception 就是一个命令对象,throw抛出异常就是发起了一个请求处理流程。而一系列的 try-catch 块就构成了处理异常的职责链,异常会自下而上地走过函数调用栈——也就是职责链,直到在链条中找到一个能够处理的 catch 块。
策略模式的要点是“策略”这两个字,它封装了不同的算法,可以在运行的时候灵活地互相替换,从而在外部“非侵入”地改变系统的行为内核。
策略模式有点像装饰模式和状态模式,你可不要弄混了。跟它们相比,策略模式的的特点是不会改变类的外部表现和内部状态,只是动态替换一个很小的算法功能模块。
前面讲过的容器和算法用到的比较函数、散列函数,还有 for_each 算法里的 lambda 表达式,它们都可以算是策略模式的具体应用。另外,策略模式也非常适合应用在有 if-else/switch-case 这样“分支决策”的代码里,可以把每个分支逻辑都封装成类或者 lambda 表达式,再把它们存进容器,让容器来帮你查找最合适的处理策略。
小结
创建型模式里常用的有单件和工厂,封装了对象的创建过程,隔离了对象的生产和使用; 结构型模式里常用的有适配器、外观和代理,通过对象组合,得到一个新对象,目的是适配、简化或者控制,隔离了客户代码与原对象的接口; 行为模式里常用的有职责链、命令和策略,只有在运行时才会建立联系,封装、隔离了程序里动态变化的那部分。
JSON/MessagePack等的序列化和反序列化可以不严格地看成是备忘录模式(在对象外保存对象的状态)。观察者模式是一个应用很广的行为模式,更常见的别名是信号机制、发布-订阅机制,但它比较复杂,自己实现的难度比较高,所以大多内置在语言或者应用框架里。
结束语
三句编程格言:
任何人都能写出机器能看懂的代码,但只有优秀的程序员才能写出人能看懂的代码。
有两种写程序的方式:一种是把代码写得非常复杂,以至于“看不出明显的错误”;另一种是把代码写得非常简单,以至于“明显看不出错误”。
“把正确的代码改快速”,要比“把快速的代码改正确”,容易得太多。
作者对这三句格言的理解:
写代码,是为了给人看,而不是给机器(编译器、CPU)看,也就是 human readable;
代码简单、易理解最重要,长而复杂的函数、类是不受欢迎的,要经常做 Code Clean;
功能实现优先,性能优化次之,在没有学会走之前,不要想着跑,也就是 Do the right thing。
4本值得一读再读的经典好书
《设计模式:可复用面向对象软件的基础》
软件开发类图书浩如烟海,但如果让我只推荐一本,那就只能是《设计模式:可复用面向对象软件的基础》。它是在我心目中永远排在第一位的技术书籍。
书里系统地总结了专家的经验,开创性地提出了“设计模式”的概念,只要遵循“模式”,就能够得到良好的设计。
其中阐述的 23 个设计模式已经被无数的软件系统所验证,并且成为了软件界的标准用语,比如单件、工厂、代理、职责链、观察者、适配器,等等。
无论你使用什么语言,无论你使用哪种范式,无论你开发何种形式的软件,都免不了会用到这些模式。而且有些模式,甚至就直接成为了编程语言的一部分(例如 C++ 的 iterator、Java 的 Observer)。
《C++ 标准程序库》
讲 C++ 语言的书有很多,但讲 C++ 标准库的却是屈指可数。因为标准库的庞大和复杂程度远远超过了语言本身,能把它“啃”下来就已经很不容易了,要把它用通俗易懂的形式讲出来,更是难上加难。
而这本书却“举重若轻”,不仅完整全面地介绍了标准库,而且还由浅入深、条理清楚,对库中每个组件的优缺点都分析得丝丝入扣,让人心悦诚服。内容的安排组织也详略得当,千余页的大部头作品读起来却毫不费力,不得不叹服作者的至深功力。
经过了这本书的“洗礼”,才真正地“脱胎换骨”,透彻地理解了 C++,开启了泛型编程、函数式编程的新世界大门。
《C++ 语言的设计与演化》
它并非直接描述语言特性,而是以“回忆录”的形式介绍了 C++ 语言的发展历史和设计理念,同时坦诚地反思了一些由于历史局限而导致的缺点和失误,视角非常独特。
这两个特别之处让它从众多语言类书籍中脱颖而出,能够解答很多学习 C++ 过程中的困惑。比如,为什么 C++ 会变成这个样子,为什么要引进 class、template 关键字,为什么会设计出那些奇怪的语法……知道了前因后果,你就可以更深刻地理解 C++。
阅读这本书时,你还能“读史以明志”,学习先驱者的经验教训,了解他们做决策时的思考方式,领会语言设计背后的“哲思”,这些技术之外的“软知识”也能够帮助你更好地使用 C++。
《C++ Primer》
虽然这本书确实自视为“入门教材”,全书的编排也是循序渐进,例子浅显易懂,但内容非常得全面、精准,基本囊括了 C++11 的所有新特性和标准库组件,C++ 老手完全可以把它当成是语言参考手册。
而且,它还有一个独到之处,就是把语言和库融合在一起讲解,而不是像其他书那样割裂开。这对于 C++ 初学者可算得上是“福音”,可以一开始就接触到标准库,学习现代 C++ 编程方式,减少了很多入门的成本。
它的不足之处是,没有涉及标准库里的线程部分,不过考虑到这本书的名字“Primer”,而多线程编程确实比较高级,不讲也是情有可原的。
它们的定位各有特色:
面向对象(《设计模式:可复用面向对象软件的基础》)
泛型编程(《C++ 标准程序库》)
历史读本(《C++ 语言的设计与演化》)
教科全书(C++ Primer)

