《C++实战笔记》学习笔记1
- 2026-05-22 09:33:36
《C++实战笔记-罗剑锋》学习笔记1

前言 01 | 重新认识C++:生命周期和编程范式 C++ 语言的编程范式 02 | 编码阶段能做什么:秀出好的code style 四条规则: 普遍认可的原则 用好注释 “必杀技” 03 | 预处理阶段能做什么:宏定义和条件编译 04 | 编译阶段能做什么:属性和静态断言 编译阶段编程 05 | 面向对象编程:怎样才能写出一个“好”的类? 设计思想 实现原则 编码准则 使用技巧
前言
看了一些C++方面的书,想看下有没有什么实战经验,毕竟书上的知识和运用到实战,还是有点差距的,而且实战经验更加好用。所以跳了罗老师的实战笔记学习下,记录下学习过程。
罗老师说的很实际:
市面上有不少教授现代 C++ 的书,也都是专家、大师之作,权威性毋庸置疑。但 C++ 实在是太庞大了,相应的书都很厚,慢慢去“啃”、去“消化”实在是吃力。而且,这些毕竟是纸面上的知识,离实际的开发还有一定的距离
有的地方读的时候还是很有共鸣的,比如三句编程格言:
任何人都能写出机器能看懂的代码,但只有优秀的程序员才能写出人能看懂的代码。
有两种写程序的方式:一种是把代码写得非常复杂,以至于“看不出明显的错误”;另一种是把代码写得非常简单,以至于“明显看不出错误”。
“把正确的代码改快速”,要比“把快速的代码改正确”,容易得太多。
这3句的意思也非常明显,罗老师也做了解释:
写代码,是为了给人看,而不是给机器(编译器、CPU)看,也就是 human readable; 代码简单、易理解最重要,长而复杂的函数、类是不受欢迎的,要经常做 Code Clean; 功能实现优先,性能优化次之,在没有学会走之前,不要想着跑,也就是 Do the right thing。
开发有时候,真的是能跑通是第一位的,优化可以放到后面,而且能跑通也是不容易的,把代码写简单,明显看不出错误总比复杂代码看不出明显错误要安全稳健得多;
比如项目上有个多相机同时拍照的问题,一开始就设计为多线程多相机拍照,但是总是失败,最后发现是1张照片占用较大宽带传输,多相机就会造成网络包丢失,造成某些相机拍照失败,但是现场网口和交换机带宽又不够,改为多个相机单线程顺序拍照就解决了这个问题。所以,一般来说多线程肯定是效率比较高的,但是在上面这种情况下,往往看起来比较笨的方法,往往很稳健。
总共分为5个模块:
“概论”模块,从程序的生命周期和编程范式这两个独特的角度来审视它,看清楚 C++ 复杂的本质,透彻理解 C++ 程序的运行机制和面向对象编程思想。 在“语言特性”模块,精选出了 C++ 中的自动类型推导、智能指针、Lambda 表达式等几个重要特性,掌握惯用法,消灭代码里的隐患,用这些特性写出清晰、易读、安全的代码。 “标准库”模块,介绍其中最核心的四个部分:字符串、容器、算法和并发,用好这个最基本的库,学会泛型编程,提高程序的运行效率。 “技能进阶”模块里,介绍 C++ 标准之外的一些第三方工具,实现序列化、网络通信和性能分析等功能,解决实际开发中遇到的常见问题。 “总结”模块,结合 C++ 讲讲设计模式,并给出一个完整可用的 C++ 服务端程序例子,把前面的所有知识点都串联起来,看看在项目中 C++ 是具体怎么思考、设计、落地的。
01 | 重新认识C++:生命周期和编程范式
一个 C++ 程序从“诞生”到“消亡”,要经历这么几个阶段:编码(Coding)、预处理(Pre-processing)、编译(Compiling)和运行(Running)。
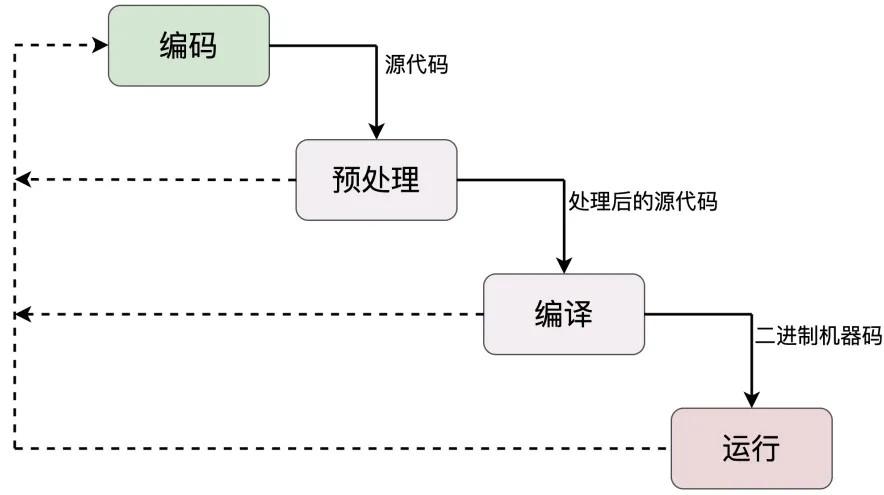
应该在“编码”“预处理”“编译”这前面三个阶段多下功夫,消灭 Bug,优化代码,尽量不要让 Bug在“运行”阶段才暴露出来,也就是所谓的“把问题扼杀在萌芽期”。
程序的代码可能会运行在不同的阶段,分别由预处理器、编译器和 CPU 执行;
C++ 语言的编程范式
“编程范式”是一种“方法论”,就是指导你编写代码的一些思路、规则、习惯、定式和常用语。
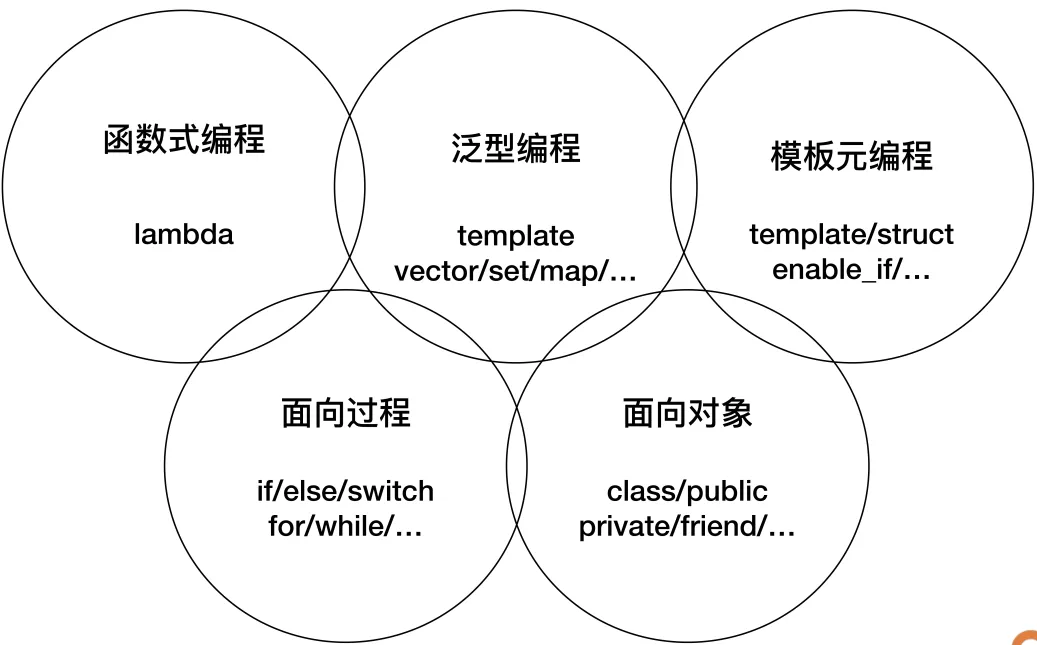
面向过程是 C++ 里最基本的一种编程范式。它的核心思想是“命令”,通常就是顺序执行的语句、子程序(函数),把任务分解成若干个步骤去执行,最终达成目标。
面向对象是 C++ 里另一个基本的编程范式。它的核心思想是“抽象”和“封装”,倡导的是把任务分解成一些高内聚低耦合的对象,这些对象互相通信协作来完成任务。它强调对象之间的关系和接口,而不是完成任务的具体步骤。
在 C++ 里,面向对象范式包括
class、public、private、virtual、this等类相关的关键字,还有构造函数、析构函数、友元函数等概念。泛型编程是自 STL(标准模板库)纳入到 C++ 标准以后才逐渐流行起来的新范式,核心思想是“一切皆为类型”,或者说是“参数化类型”“类型擦除”,使用模板而不是继承的方式来复用代码,所以运行效率更高,代码也更简洁。 在 C++ 里,泛型的基础就是 template 关键字,然后是庞大而复杂的标准库,里面有各种泛型容器和算法,比如 vector、map、sort,等等。
模板元编程:核心思想是“类型运算”,操作的数据是编译时可见的“类型”,代码只能由编译器执行,而不能被运行时的 CPU 执行。 模板元编程更多的是以库的方式来使用,比如
type_traits、enable_if等。函数式:数学意义上、无副作用的函数,核心思想是“一切皆可调用”,通过一系列连续或者嵌套的函数调用实现对数据的处理。 函数式早在 C++98 时就有少量的尝试(bind1st/bind2nd 等函数对象),但直到 C++11 引入了 Lambda 表达式,它才真正获得了可与 其他范式并驾齐驱的地位。
02 | 编码阶段能做什么:秀出好的code style
四条规则:
变量、函数名和名字空间用 snake_case,全局变量加“g_”前缀;自定义类名用 CamelCase,成员函数用snake_case,成员变量加“m_”前缀;宏和常量应当全大写,单词之间用下划线连接; 尽量不要用下划线作为变量的前缀或者后缀(比如 _local、name_),很难识别。
普遍认可的原则
变量 / 函数的名字长度与它的作用域成正比,也就是说,局部变量 / 函数名可以短一点,而全局变量 / 函数名应该长一点。
用好注释
一般来说,注释可以用来阐述目的、用途、工作原理、注意事项等代码本身无法“自说明”的那些东西。
注释必须要正确、清晰、有效,尽量言简意赅、点到为止,不要画蛇添足,更不能写出含糊、错误的注释。
除了给代码、函数、类写注释,我还建议最好在文件的开头写上本文件的注释,里面有文件的版权声明、更新历史、功能描述,等等。
// Copyright (c) 2026 by Randy// file : xxx.cpp// since : 2020-xx-xx// desc : ...//注释还有一个很有用的功能就是 todo,作为功能的占位符,提醒将来的代码维护者(也许就是你)
“必杀技”
善用 code review,和你周围的同事互相审查代码,可以迅速改善自己的 code style。
网上有很多工具可以检查C++代码风格,一个比较常见的是cpplint.。它是一个Python脚本,可以用命令“sudo pip install cpplint”安装。
03 | 预处理阶段能做什么:宏定义和条件编译
预处理编程
“# 开头、顶格写”
预处理编程由预处理器执行,使用 #include、#define、#if 等指令来实现文件包含、文本替换、条件编译,把编码阶段产生的源码改变为另外一种形式。适当使用的话,可以简化代码、优化性能。
C++ 语言有近百个关键字,预处理指令只有十来个,常用的也就是 #include、#define、#if,所以很容易掌握。
首先,预处理指令都以符号“#”开头,它走的是预处理器,不受 C++ 语法规则的约束。
一般来说,预处理指令不应该受 C++ 代码缩进层次的影响,不管是在函数、类里,还是在 if、for 等语句里,永远是顶格写。
另外,单独的一个“#”也是一个预处理指令,叫“空指令”,可以当作特别的预处理空行。而“#”与后面的指令之间也可以有空格,从而实现缩进,方便排版。
预处理程序也有它的特殊性,暂时没有办法调试,不过可以让 GCC使用“-E”选项,略过后面的编译链接,只输出预处理后的源码,比如:
g++ test03.cpp -E -o a.cxx #输出预处理后的源码包含文件(#include)
只要你愿意,使用“#include”可以把源码、普通文本,甚至是图片、音频、视频都引进来。
“#include”其实是非常“弱”的,不做什么检查,就是“死脑筋”把数据合并进源文件。
在写头文件的时候,为了防止代码被重复包含,通常要加上“Include Guard”,也就是用“#ifndef/#define/#endif”来保护整个头文件
#ifndef _XXX_H_INCLUDED_#define _XXX_H_INCLUDED_...// 头文件内容#endif// _XXX_H_INCLUDED_宏定义(#define/#undef)
“#define”,它用来定义一个源码级别的“文本替换”。
“#define”可谓“无所不能”,在预处理阶段可以无视 C++ 语法限制,替换任何文字,定义常量 / 变量,实现函数功能,为类型起别名(typedef),减少重复代码……
使用宏的时候一定要谨慎,时刻记着以简化代码、清晰易懂为目标,不要“滥用”,避免导致源码混乱不堪,降低可读性。
技巧
因为宏的展开、替换发生在预处理阶段,不涉及函数调用、参数传递、指针寻址,没有任何运行期的效率损失,所以对于一些调用频繁的小代码片段来说,用宏来封装的效果比 inline 关键字要更好,因为它真的是源码级别的无条件内联。
#define ngx_tolower(c) ((c >= 'A' && c <= 'Z') ? (c | 0x20) : c)#define ngx_toupper(c) ((c >= 'a' && c <= 'z') ? (c & ~0x20) : c)#define ngx_memzero(buf, n) (void)memset(buf, 0, n)宏是没有作用域概念的,永远是全局生效。
对于一些用来简化代码、起临时作用的宏,最好是用完后尽快用“#undef”取消定义,避免冲突的风险。
#define CUBE(a) (a) * (a) * (a) # // 定义一个简单的求立方的宏 cout << CUBE(10) << endl; // 使用宏简化代码cout << CUBE(15) << endl; // 使用宏简化代码#undef CUBE // 使用完毕后立即取消定义宏定义前先检查,如果之前有定义就先 undef,然后再重新定义
#ifdef AUTH_PWD // 检查是否已经有宏定义# undef AUTH_PWD // 取消宏定义#endif// 宏定义检查结束#define AUTH_PWD "xxx"// 重新宏定义适当使用宏来定义代码中的常量,消除“魔术数字”“魔术字符串”(magic number)。
用好“文本替换”的功能,可以有很多好用的功能:
#define BEGIN_NAMESPACE(x) namespace x {#define END_NAMESPACE(x) }BEGIN_NAMESPACE(my_own)...// functions and classesEND_NAMESPACE(my_own)
条件编译(#if/#else/#endif)
利用“#define”定义出的各种宏,我们还可以在预处理阶段实现分支处理,通过判断宏的数值来产生不同的源码,改变源文件的形态,这就是“条件编译”。
条件编译有两个要点,一个是条件指令“#if”,另一个是后面的“判断依据”,也就是定义好的各种宏,而“判断依据”是条件编译里最关键的部分。
通常编译环境都会有一些预定义宏,比如 CPU 支持的特殊指令集、操作系统 / 编译器 / 程序库的版本、语言特性等,使用它们就可以早于运行阶段,提前在预处理阶段做出各种优化,产生出最适合当前系统的源码。
除了“__cplusplus”,C++ 里还有很多其他预定义的宏,像源文件信息的“FILE”“ LINE”“ DATE”,以及一些语言特性测试宏,比如“__cpp_decltype” “__cpp_decltype_auto”“__cpp_lib_make_unique”等。
条件编译还有一个特殊的用法,那就是,使用“#if 1”“#if 0”来显式启用或者禁用大段代码,要比“/* … */”的注释方式安全得多,也清楚得多。
#if 0 // 0即禁用下面的代码,1则是启用... // 任意的代码#endif// 预处理结束#if 1 // 1启用代码,用来强调下面代码的必要性... // 任意的代码#endif// 预处理结束“条件编译”其实就是预处理编程里的分支语句,可以改变源码的形态,针对系统生成最合适的代码。
04 | 编译阶段能做什么:属性和静态断言
“编译阶段”的目标是生成计算机可识别的机器码(machine instruction code)。
编译阶段编程
编译是预处理之后的阶段,它的输入是(经过预处理的)C++ 源码,输出是二进制可执行文件(也可能是汇编文件、动态库或者静态库)。
05 | 面向对象编程:怎样才能写出一个“好”的类?
设计思想
面向对象编程,本质上是一种设计思想、方法,与语言细节无关,要点是抽象(Abstraction)和封装(Encapsulation)。“继承”“多态”是衍生出的特性,不完全符合现实世界。
面向对象编程的基本出发点是“对现实世界的模拟”,把问题中的实体抽象出来,封装为程序里的类和对象,这样就在计算机里为现实问题建立了一个“虚拟模型”。
然后以这个模型为基础不断演化,继续抽象对象之间的关系和通信,再用更多的对象去描述、模拟……直到最后,就形成了一个由许多互相联系的对象构成的系统。
要想从理论高度上学好面向对象编程,必须要掌握的知识是“设计模式”,然后还有“开闭原则”“里氏替换原则”等基本原则。
实现原则
在设计类的时候尽量少用继承和虚函数。
特别的,如果完全没有继承关系,就可以让对象不必承受“父辈的重担”(父类成员、虚表等额外开销),轻装前行,更小更快。没有隐含的重用代码也会降低耦合度,让类更独立,更容易理解。
把“继承”切割出去之后,可以避免去记忆、实施那一大堆难懂的相关规则,比如
public/protected/private继承方式的区别、多重继承、纯虚接口类、虚析构函数,还可以绕过动态转型、对象切片、函数重载等很多危险的陷阱,减少冗余代码,提高代码的健壮性。
非要用继承不可,一定要控制继承的层次,用 UML画个类体系的示意图来辅助检查。
如果继承深度超过三层,就说明有点“过度设计”了,需要考虑用组合关系替代继承关系,或者改用模板和泛型。
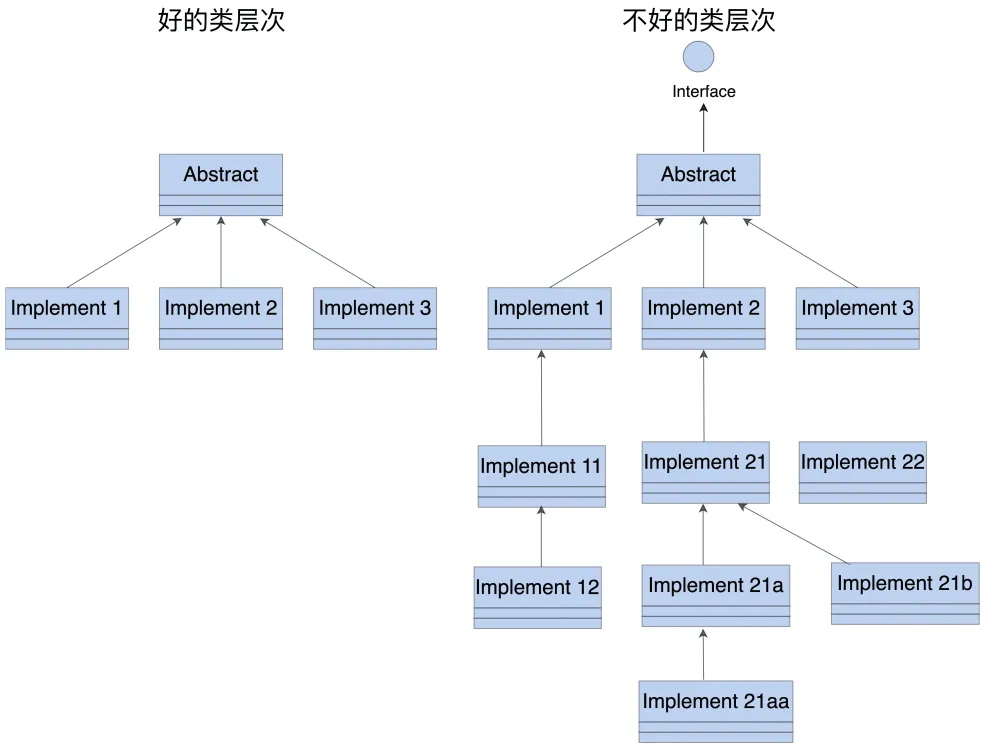
很多人有一种不好的习惯,就是喜欢在类内部定义一些嵌套类,美其名曰“高内聚”。但恰恰相反,这些内部类反而与上级类形成了强耦合关系,也是另一种形式的“万能类”。
编码准则
final
C++11 新增了一个特殊的标识符“final”(注意,它不是关键字),把它用于类定义,就可以显式地禁用继承,防止其他人有意或者无意地产生派生类。无论是对人还是对编译器,效果都非常好,一定要积极使用。
public继承
在必须使用继承的场合,建议只使用 public 继承,避免使用virtual、protected,因为它们会让父类与子类的关系变得难以捉摸,带来很多麻烦。当到达继承体系底层时,也要及时使用“final”,终止继承关系。
6大基本函数
C++11 因为引入了右值(Rvalue)和转移(Move),又多出了两大函数:转移构造函数和转移赋值函数。所以,在现代 C++ 里,一个类总是会有六大基本函数:三个构造(构造函数、拷贝构造函数、转移构造函数)、两个赋值(拷贝赋值函数、转移赋值函数)、一个析构。
= default
一般情况下,C++ 编译器会自动为我们生成这些函数的默认实现,对于比较重要的构造函数和析构函数,应该用“= default”的形式,明确地告诉编译器(和代码阅读者):“应该实现这个函数,但我不想自己写。”
= delete
“= delete”的形式。它表示明确地禁用某个函数形式,而且不限于构造 / 析构,可以用于任何函数(成员函数、自由函数)。
比如说,如果你想要禁止对象拷贝,就可以用这种语法显式地把拷贝构造和拷贝赋值“delete”掉,让外界无法调用。
classDemoClassfinal {public:DemoClass(const DemoClass&) = delete; // 禁止拷贝构造DemoClass& operator=(const DemoClass&) = delete; // 禁止拷贝赋值};explicit 显式构造
因为 C++ 有隐式构造和隐式转型的规则,如果你的类里有单参数的构造函数,或者是转型操作符函数,为了防止意外的类型转换,保证安全,就要使用“explicit”将这些函数标记为“显式”。
classDemoClassfinal{public:explicitDemoClass(const string_type& str)// 显式单参构造函数{ ... }explicitoperatorbool()// 显式转型为bool{ ... }};使用技巧
1. 委托构造 (delegating constructor)
如果你的类有多个不同形式的构造函数,为了初始化成员肯定会有大量的重复代码。为了避免重复,常见的做法是把公共的部分提取出来,放到一个 init() 函数里,然后构造函数再去调用。这种方法虽然可行,但效率和可读性较差,毕竟 init() 不是真正的构造函数。
在 C++11 里,你就可以使用“委托构造”的新特性,一个构造函数直接调用另一个构造函数,把构造工作“委托”出去,既简单又高效。
classDemoDelegatingfinal {private:int a; // 成员变量public: DemoDelegating(int x) : a(x) // 基本的构造函数 {} DemoDelegating() : // 无参数的构造函数 DemoDelegating(0) // 给出默认值,委托给第一个构造函数 {} DemoDelegating(conststring &s) : // 字符串参数构造函数 DemoDelegating(stoi(s)) // 转换成整数,再委托给第一个构造函数 {}};2.成员变量初始化(In-class member initializer)
如果你的类有很多成员变量,那么在写构造函数的时候就比较麻烦,必须写出一长串的名字来逐个初始化,不仅不美观,更危险的是,容易“手抖”,遗漏成员,造成未初始化的隐患。
在 C++11 里,你可以在类里声明变量的同时给它赋值,实现初始化,这样不但简单清晰,也消除了隐患。
3.类型别名(Type Alias)
C++11 扩展了关键字 using 的用法,增加了 typedef 的能力,可以定义类型别名。它的格式与 typedef 正好相反,别名在左边,原名在右边,是标准的赋值形式,所以易写易读。
usinguint_t = unsignedint; // using别名typedefunsignedintuint_t; // 等价的typedef可以在类里面用 using 给外部类型,比如标准库里的string、vector,还有其他的第三方库和自定义类型(这些名字通常都很长,特别是带上名字空间、模板参数)起别名,不仅简化了名字,同时还能增强可读性。
classDemoClassfinal {public:using this_type = DemoClass; // 给自己也起个别名using kafka_conf_type = KafkaConfig; // 外部类起别名public:using string_type = std::string; // 字符串类型别名using uint32_type = uint32_t; // 整数类型别名using set_type = std::set<int>; // 集合类型别名using vector_type = std::vector<std::string>; // 容器类型别名private: string_type m_name = "tom"; // 使用类型别名声明变量 uint32_type m_age = 23; // 使用类型别名声明变量 set_type m_books; // 使用类型别名声明变量private: kafka_conf_type m_conf; // 使用类型别名声明变量};在C++里,不要再使用“typedef struct{…} xxx;”的方式来定义结构体,这是传统的C做法,在C++里不仅没有必要,而且会造成困惑。
类的编写
传统的类编写方式是“*h+*.cpp”,声明与实现分离,但我更推荐在一个“*.hpp”里实现类的全部功能,这样更“现代”。很多开源的现代C++项目都全面采用了“hpp”的方式,比如著名的Boost。.

