一、RAG 概念
1. 什么是 RAG
RAG 是一种混合 AI 架构,其核心思想是:让大模型在回答问题前,先从外部知识库中检索出与问题最相关的信息片段,再将这些信息与问题一起输入大模型,引导其基于真实、最新的知识生成准确答案。
简单来说,RAG 就像给大模型配备了一个"实时可更新的图书馆" 和"智能检索员",让模型不再只依赖训练时学到的静态知识,而是能随时查阅最新、最专业的资料。
2. RAG 解决的核心问题
知识时效性差:大模型的训练数据有明确的截止日期,无法回答训练后发生的事件
幻觉问题严重:大模型会编造不存在的事实和数据,尤其在专业领域
数据隐私风险:将企业私有数据用于模型微调存在数据泄露风险
专业能力不足:通用大模型在垂直领域(如医疗、法律、金融)的知识深度不够
更新成本高昂:通过重新训练或微调更新模型知识耗时耗力且成本极高
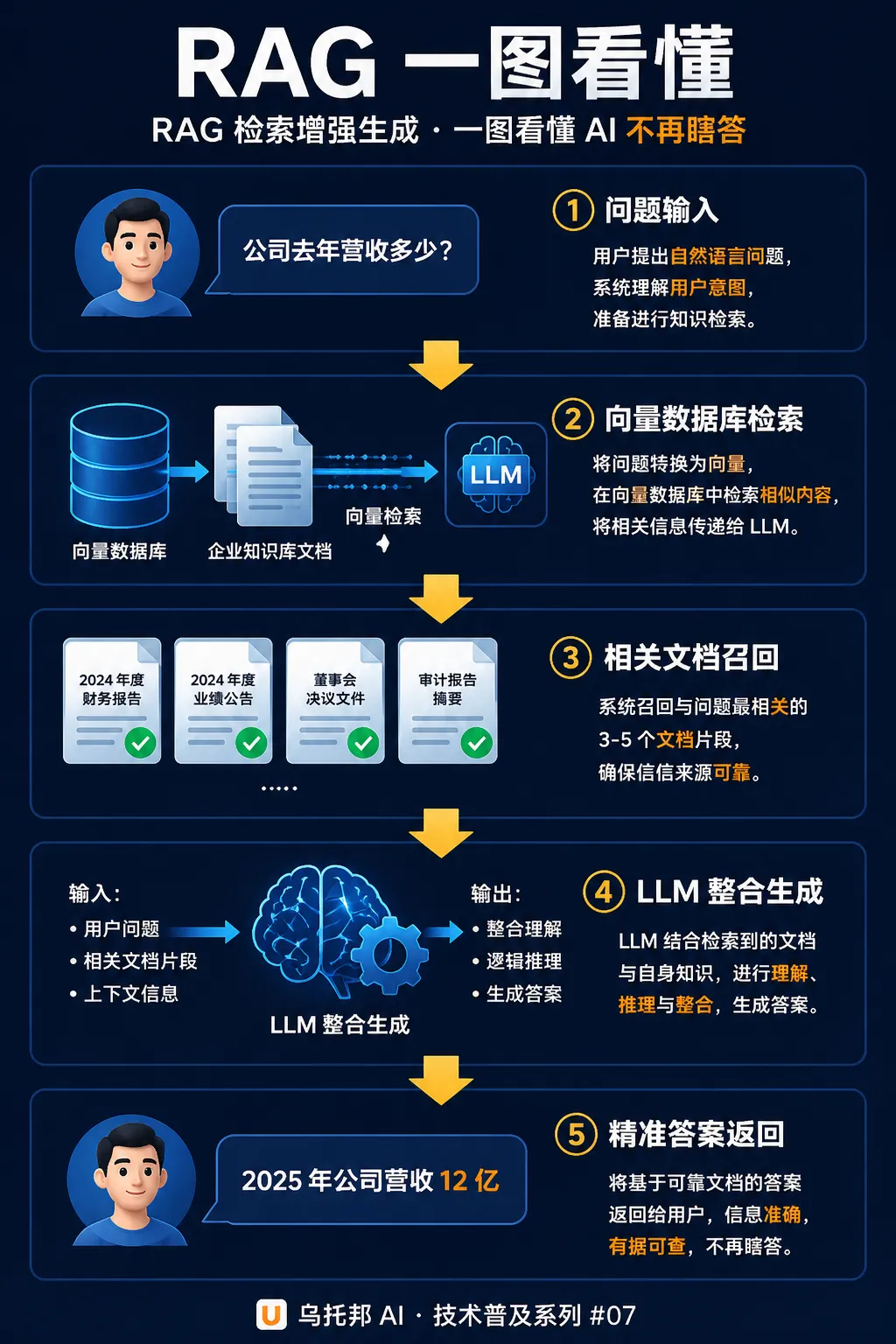
3. 原生 RAG 基本工作流程
最基础的 RAG 系统包含离线数据处理和在线问答两个阶段,整个流程可以用下图清晰展示:
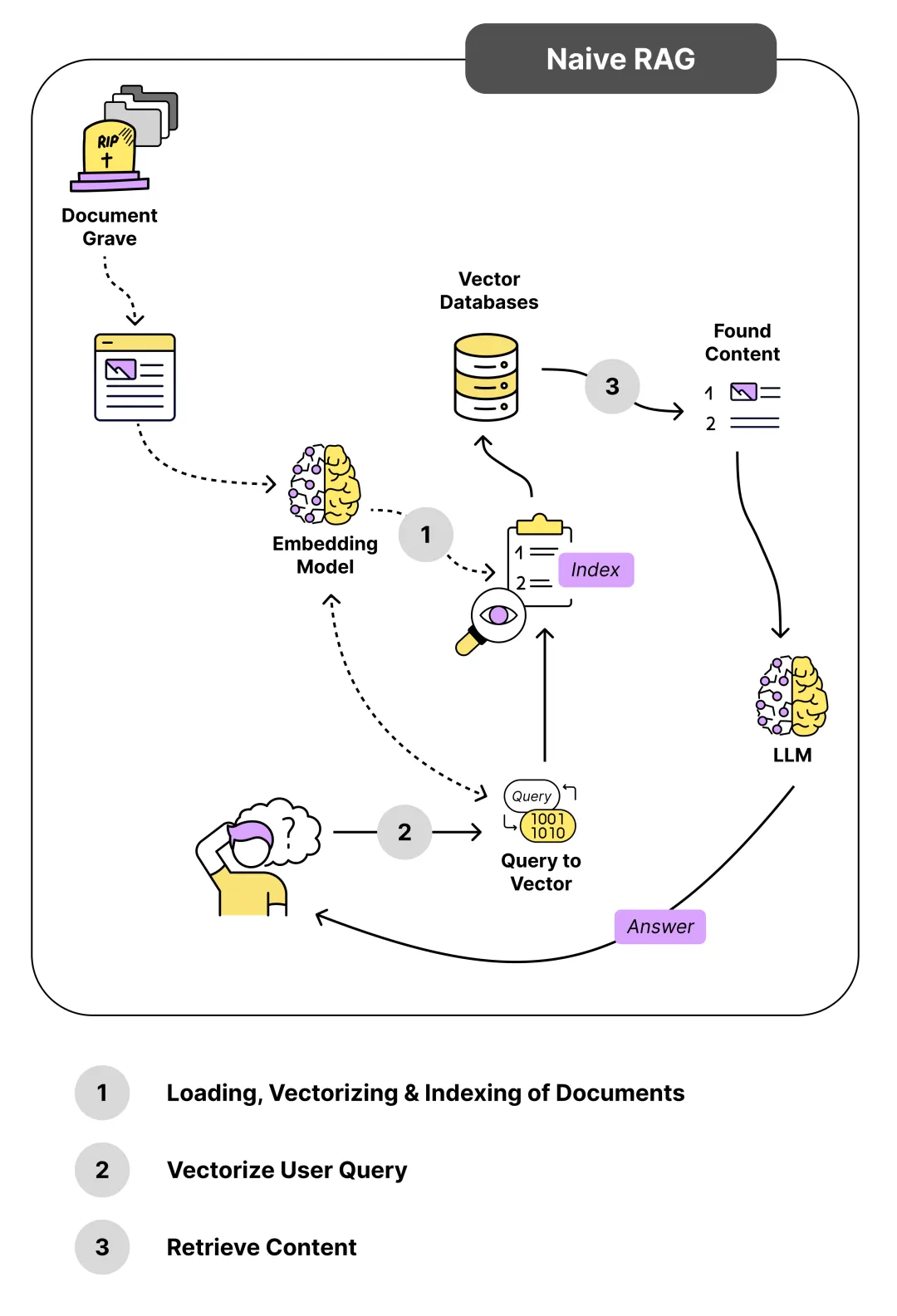
离线阶段(数据准备):
文档加载:读取各种格式的文档(PDF、Word、网页、数据库等)
文档分割:将长文档切分成适合向量检索的小块(Chunk)
向量嵌入:使用嵌入模型(Embedding)将文本块转换为向量表示
向量存储:将向量和原始文本存入向量数据库(Vector Database)
在线阶段(问答过程):
问题嵌入:将用户的问题转换为向量表示
相似度检索:在向量数据库中检索与问题向量最相似的Top-K个文本块
上下文构建:将检索到的文本块与用户问题拼接成提示词(Prompt)
大模型生成:将提示词输入大模型,生成基于检索信息的答案
二、RAG 技术更新换代
RAG 技术自 2020 年被 Meta 首次提出以来,经历了快速的迭代和演进,目前已发展到第四代。每一代都在解决上一代的核心痛点,在检索准确性、上下文利用效率、系统灵活性等方面实现了质的飞跃。
第一阶段:原生 RAG(Naive RAG)- 2020 年 - 2023 年初
提出背景:2020 年7月,Meta AI 在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中首次正式提出 RAG 架构。当时大模型的幻觉问题和知识更新问题日益突出,而微调方法成本高昂且效果有限。
核心架构:采用 "检索 - 生成" 的简单两阶段架构,没有任何额外的优化模块。
关键特点:
优势:
架构简单,易于实现和部署
能显著提升大模型回答的准确性和时效性
无需对大模型进行任何微调
局限性:
检索质量不稳定:固定长度切分可能破坏语义完整性,单一相似度检索容易返回不相关信息
上下文冗余:检索到的多个文本块可能存在大量重复信息,浪费上下文窗口
缺乏推理能力:无法处理需要多步推理的复杂问题
召回率低:难以检索到与问题语义相关但字面差异较大的信息
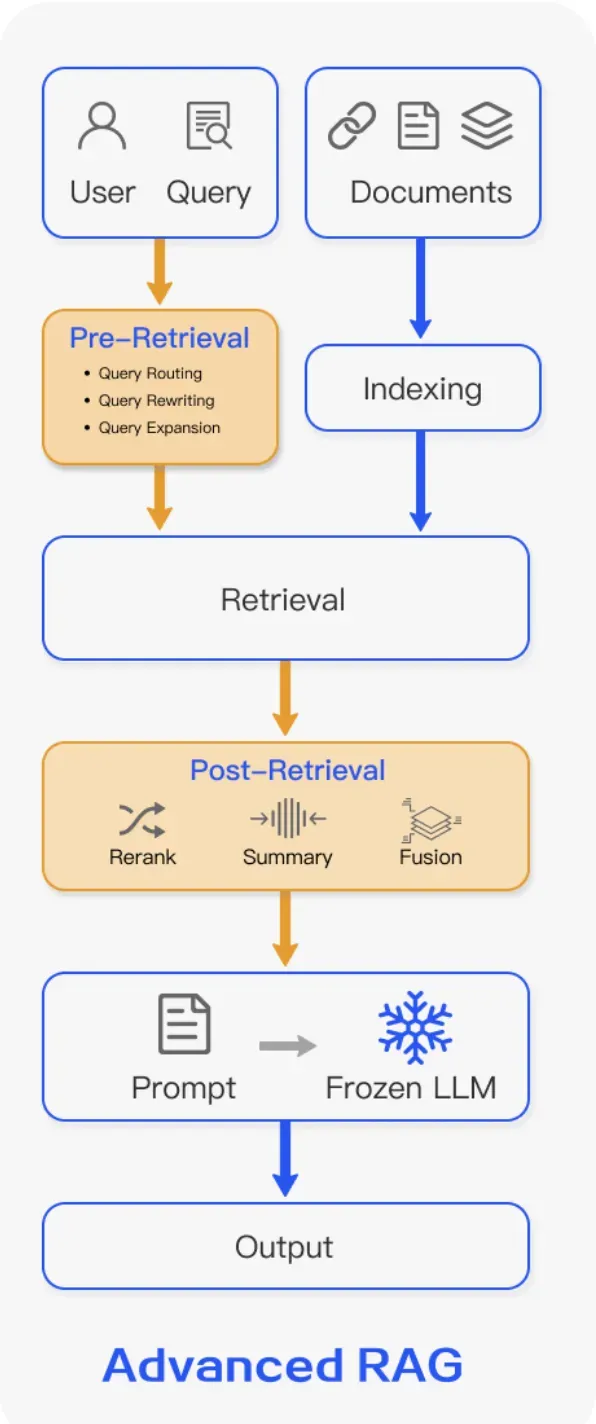
第二阶段:高级 RAG(Advanced RAG)- 2023 年上半年
提出背景:原生 RAG 在实际应用中暴露出大量问题,尤其是检索准确性不足导致的 "检索到了但回答错了" 的现象。开发者开始在原生 RAG 的基础上增加各种优化模块,形成了高级 RAG 架构。
核心架构:在 "检索 - 生成" 的基础上,增加了预处理优化、检索优化和后处理优化三个关键环节。
关键技术突破:
1. 预处理优化
2. 检索优化
查询重写(Query Rewriting):将用户的模糊问题转换为更适合检索的标准查询
多查询检索(Multi-Query Retrieval):生成多个不同角度的查询,分别检索后合并结果
混合检索(Hybrid Retrieval):结合向量相似度检索和关键词检索(如 BM25)的优势
重排序(Reranking):使用专门的重排序模型(如 Cohere Rerank、BGE-Reranker)对初步检索结果进行二次排序,提升相关性
3. 后处理优化
优势:
检索准确性和召回率大幅提升
上下文利用效率更高,减少了冗余信息
答案的可信度和可解释性增强
能处理更复杂的文档和问题
局限性:
架构仍然相对固定,难以根据不同场景进行灵活调整
所有查询都执行相同的检索和生成流程,资源浪费严重
无法处理需要跨多个文档、多步推理的复杂问题
缺乏自我评估和纠错能力
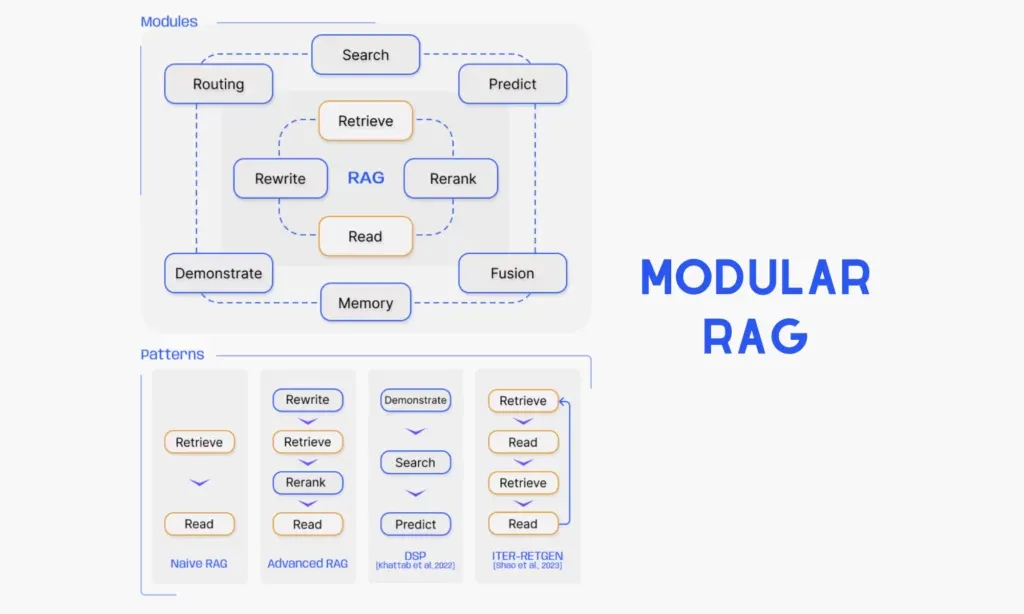
第三阶段:模块化 RAG(Modular RAG)- 2023 年下半年至今
提出背景:高级 RAG 虽然提升了性能,但架构仍然不够灵活,不同模块之间耦合度高,难以替换和扩展。同时,随着 RAG 应用场景的不断丰富,需要针对不同任务定制化构建 RAG 系统。
核心思想:将 RAG 系统拆解为一系列独立、可替换、可组合的模块,开发者可以根据具体需求选择和组合不同的模块,构建最适合的 RAG 架构。
核心模块划分:
数据处理模块:文档加载、分割、清洗、嵌入
检索模块:向量检索、关键词检索、图检索、SQL 检索
路由模块:根据问题类型选择合适的检索策略或工具
推理模块:处理需要多步推理的复杂问题
生成模块:基于检索到的信息生成答案
评估模块:评估检索质量和生成答案的准确性
记忆模块:存储对话历史和用户偏好
关键技术突破:
路由机制:引入大模型作为路由器,根据问题的复杂度和类型动态选择处理流程。例如,简单问题直接回答,复杂问题触发检索,需要计算的问题调用计算器
多源检索融合:支持同时从多个不同类型的数据源(向量数据库、关系型数据库、知识图谱、API)检索信息
图 RAG(Graph RAG):将文档转换为知识图谱,利用图结构进行检索和推理,能更好地捕捉实体之间的关系
小模型增强:使用专门的小模型完成特定任务(如查询重写、重排序、分类),降低成本并提升效率
流水线编排:支持将多个模块组合成复杂的处理流水线
优势:
架构高度灵活,可定制性强
支持复杂的多步推理和多工具调用
能整合多种不同类型的数据源
性能和成本之间可以更好地平衡
易于扩展和维护
局限性:
系统复杂度大幅提升,开发和调试难度增加
模块之间的交互和协调需要精心设计
仍然需要人工设计和优化处理流程
缺乏自适应能力,无法根据运行时反馈自动调整策略
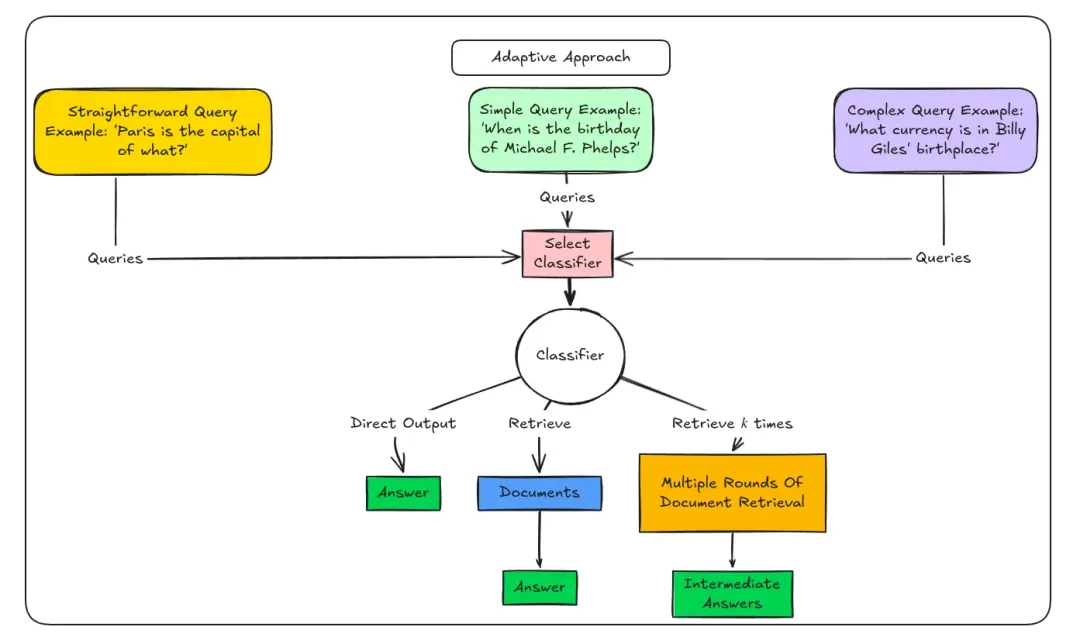
第四阶段:自适应 RAG(Adaptive RAG)- 2024 年至今(发展中)
提出背景:模块化 RAG 虽然灵活,但仍然需要人工预先定义所有可能的处理流程和模块组合。随着大模型能力的不断提升,人们开始探索让 RAG 系统能够自主感知问题、自主选择策略、自主优化性能,这就是自适应 RAG。
核心思想:赋予 RAG 系统自我感知、自我决策和自我优化的能力,让它能够根据问题的特点、知识库的状态和运行时的反馈,动态调整自己的行为,以最优的方式完成任务。
关键技术方向:
1. 自适应检索
动态决定是否需要检索、检索多少次、检索多少个结果
根据检索结果的质量自动调整检索策略
当检索结果不足时,自动扩展查询或切换数据源
2. 自适应生成
根据检索到的信息质量动态调整生成策略
当信息不足时,主动向用户追问更多信息
自动检测和纠正生成过程中的错误和幻觉
3. 自我评估与优化
内置评估模块,实时评估检索质量和生成答案的准确性
根据评估结果自动调整模块参数和处理流程
从用户反馈中学习,持续优化系统性能
4. 长期记忆与学习
存储历史问答对和处理经验
从历史交互中学习用户偏好和常见问题
自动更新和优化知识库
优势:
能够处理更加复杂和不确定的问题
系统性能会随着使用不断提升
大幅减少人工干预和调优的工作量
能更好地适应不同的用户和场景
局限性:
技术尚不成熟,处于研究和探索阶段
对大模型的推理能力和可靠性要求极高
系统复杂度达到了新的高度
可解释性和可控性有所下降
三、RAG 技术核心组件详解
一个完整的 RAG 系统主要由以下四个核心组件组成,它们协同工作,共同完成从知识存储到答案生成的全过程:
1. 嵌入模型(Embedding Model)
嵌入模型是 RAG 系统的 "眼睛",它将文本转换为向量表示,向量之间的距离反映了文本之间的语义相似度。
2. 向量数据库(Vector Database)
向量数据库是专门用于存储和检索向量数据的数据库,是 RAG 系统的 "大脑"。
3. 重排序模型(Reranker)
重排序模型是提升检索准确性的关键组件,它对初步检索结果进行更精细的语义排序。
4. 大语言模型(LLM)
大语言模型是 RAG 系统的 "嘴",负责基于检索到的信息生成最终答案。
四、RAG 技术未来发展趋势
与 Agent 深度融合:RAG 将成为智能体的核心知识获取组件,智能体将利用 RAG 获取外部知识,完成更加复杂的任务
多模态 RAG:支持文本、图像、音频、视频等多种模态的检索和生成
端侧 RAG:将 RAG 系统部署在边缘设备上,实现离线运行,保护数据隐私
知识图谱增强 RAG:利用知识图谱的结构化信息,提升 RAG 的推理能力和准确性
实时 RAG:支持实时数据流的检索和处理,能够回答最新发生的事件
低代码 / 无代码 RAG 平台:降低 RAG 系统的开发门槛,让更多企业能够快速构建自己的 RAG 应用
五、结语
RAG 技术在短短几年内经历了从原生到自适应的快速演进,已经从一个简单的 "检索 + 生成" 架构发展成为一个复杂、灵活、智能的知识增强系统。它不仅解决了大模型的固有缺陷,还为企业级 AI 应用的落地提供了一条安全、高效、低成本的路径。
随着技术的不断发展,RAG 将与智能体、多模态、知识图谱等技术深度融合,成为未来 AI 系统不可或缺的核心组件。