有人会说,不放心环节可以等视为风险,太过于离谱。
昨天LL总留言,祸患常积于忽微如何建模?
觉得比较有意思,于是开夜车学习了一些皮毛,属于现学现卖。
祸患常积于忽微。这个“忽微”在风险分析中怎么建模?
“祸患常积于忽微”出自欧阳修的《伶官传序》,意思是灾祸往往由极细微的隐患日积月累而成。在风险分析中,“忽微”就是那些初始能量极小、容易被忽略,但随时间或系统耦合会非线性放大的风险因子。
如果要想对其进行建模,核心是刻画三个特征:
隐蔽性 → 累积性 → 临界突变。
一、可落地的建模思路
1. 随机退化建模:
把“忽微”看作性能的微小衰减——
很多工程灾难源于材料疲劳、腐蚀、绝缘老化等渐变过程。每一次微小的损耗就是“忽微”。
模型:维纳过程 或 伽马过程
表达式: X(t) = μt+σW(t)
其中 μ为退化速率(几乎不可见),σ为微小波动。
μt 是线性漂移项,若 μ > 0,整体有上升趋势;若 μ < 0,整体有下降趋势。
σ更为精准的说法:扩散系数 / 波动率;
代表随机波动的强度。σ 越大,过程的不确定性(方差)越大。
在很小的时间区间 Δt 内,随机部分的方差约为 σ²Δt。
W(t)(标准维纳过程 / 标准布朗运动)
W(t) 满足:
W(0) = 0;
增量独立:对任意 0 ≤ s < t,W(t) - W(s) 服从正态分布 N(0, t - s);样本路径连续。
σW(t) 则将标准布朗运动按波动率 σ 进行缩放。
因此,X(t) 在 t 时刻的分布为:
X(t) ~ N(μt, σ²t)
即均值为 μt,方差为 σ²t 的正态分布。
“积于忽微”的体现:退化轨迹平稳,直到首次跨越失效阈值 L。
风险度量:计算首达时间的分布 P(T ≤t) ,得出即便每次损伤极小,累积到阈值的概率也会随时间急剧上升。
每一次微小的衰减,都在给倒计时上发条——
很多从事设备管理的同行倾向于把“忽微”看作为性能的微小的衰减。材料疲劳、绝缘老化、管路腐蚀,每一次的损耗小的连精密仪器都未必能够准确地进行捕捉,但是经过几年的累积,问题就到来了。
有一个从事管道完整性评估的团队曾向我展示过他们的模型,其底层正是一个维纳过程。
在日常巡检中所看到的数据,仿佛是在正常的范围内进行着随机的游走,而实际上它们一直在缓慢地逼近那一条失效阈值 L。
风险并不是藏于某一个数据点之中,而是藏于首达时间的分布里。他们曾经计算过一条壁厚每年只减薄 0.1 毫米的管线,其在前十五年的泄漏概率几乎可以被忽略,但是从第十八年往后,曲线便一下子陡峭了上去。
这其实与锂电储能系统的衰减逻辑是完全地一模一样的。很多工商业储能柜在第一年与第二年的时候,循环效率看起来是挺健康的,然而,一旦电芯内阻增大到了某一个拐点,温升和容量的跳水便会突然地加速。
没有人能够指着某一天的数据说道“今天出问题了”,但是退化模型却能够提前地告诉你:你正活在那条概率曲线的陡坡之前。
2. 近失事件模型:
量化“差点出事”背后的积累效应。
海因里希安全法则指出,每一起重大事故背后有29次小事故和300个隐患。“忽微”就是那些未遂事件、微小偏差。
模型:泊松-伽马复合分布 或 自激点过程(霍克斯过程)
逻辑:忽微事件的发生率本身会因未纠正的隐患而升高。
霍克斯过程 λ(t) = μ + α∑ e^{-β(t-ti)}
能刻画每次小疏漏都会提高后续风险的概率,形成“积微成祸”的正反馈。
落地:用近失报告的数据估计 α(激励强度),即统计险些成为问题的次数,或者说是一般问题的个数,实际上工程研制过程中,经常性出问题的系统或单机,这一定会出现严重或重大质量问题。
若 α 显著大于0,说明小问题正在自我累积,哪怕单个事件概率极低,连锁爆发风险也呈超线性增长。
① λ(t)—— 当前时刻 t 的事件发生率(或风险强度)
这是公式的“结果”。它表示在时间 t 瞬间,发生新事件(比如新的隐患、小疏漏或事故)的概率密度。它不是一个固定值,而是会随着历史事件的发生而动态变化。
② μ—— 基线发生率
它代表了背景风险。即如果没有之前发生的任何事件影响,系统自身固有的、基础的风险发生率。这是风险的“底数”。
③ α—— 激励强度(触发系数)
这是整个公式中最关键、最需要关注的参数。
可以把它称作“激励强度”。
它代表每一个历史事件会对未来风险产生多大的“提升作用”。
落地应用:如果估计出来的 α显著大于0,就说明小问题正在自我累积。单个小疏漏看似概率很低,但每次发生都会给后续的风险“添柴加火”(正反馈),最终导致风险呈超线性增长,形成“积微成祸”的连锁反应。
④ ti —— 每个历史事件的发生时刻
这里 i 代表1, 2, 3... 第 i 个历史事件发生的具体时间点。
⑤ t —— 当前的观测时刻
⑥ ∑ —— 对全部历史事件的求和
它表示要把过去发生的每一个小事件的影响都累加在一起。
⑦ β— 衰减率(与记忆力相关)
它决定了历史事件的影响随时间退去的速度。
它出现在指数项 e^{-β(t-ti)} 中。如果 β很大,说明旧事件的影响很快就消失了,系统“忘”得快;如果 β 较小,说明隐患的影响会持续很久,久久不能消散。
⑧ e^{-β(t-ti)} —— 衰减核(记忆核)
这是一个指数衰减函数。
它表示:越久远的事件,对当下风险的影响越小。如果 t-ti (当前时间减去历史事件发生时间)很大,也就是那个事发生了很久,那么它的影响会指数级下降,趋向于0。
用这个模型去分析“近失报告”(Near-miss report)时,核心看的就是 α。如果 α很大,就说明现在每忽略一个小问题,都在为未来的巨大灾难埋下伏笔,风险正在以超乎预想的速度膨胀。
小问题本身会“生”出更多问题——
如果说退化模型所讲述的是物理层面的“积微”,那么在组织和管理的层面则存在着另一套逻辑——小的事件本身就在提高着未来出现大事件的概率。
海因里希的那个 1:29:300 的法则已经被说到烂了,但是真正能够将这件事情进行量化的人却并不多。
某一个机队在一段时间里,机务日志中经常出现“润滑油消耗率略高于正常值”的记录,每一次单独地看都不够停飞的标准,机务组也就按照常规进行补充了事。
在三个月之后,那个机队真的发生了一次空中单发失效的严重事故征候。
当他们将半年内的接近失误报告丢进模型之中运行之后,他们发现 α 显著地大于零,并且衰减率 β 很低,这说明了这些微小异常的影响根本不会随着几天几夜的排故工作而消退,反而如同滚雪球一般越积越多。
这便是典型的正反馈:每忽略一个忽微,并不是在原地踏步,而是在抬高着整个系统的风险地基。即便单次的概率低到了不像话的程度,连锁爆发的概率也会呈现出超线性的增长。
从事工程的人经常给出这样的说法,即‘某个单机老是出小毛病,迟早要来一次大的’,这一句话背后的数学,正是霍克斯过程之中的 α 系数。
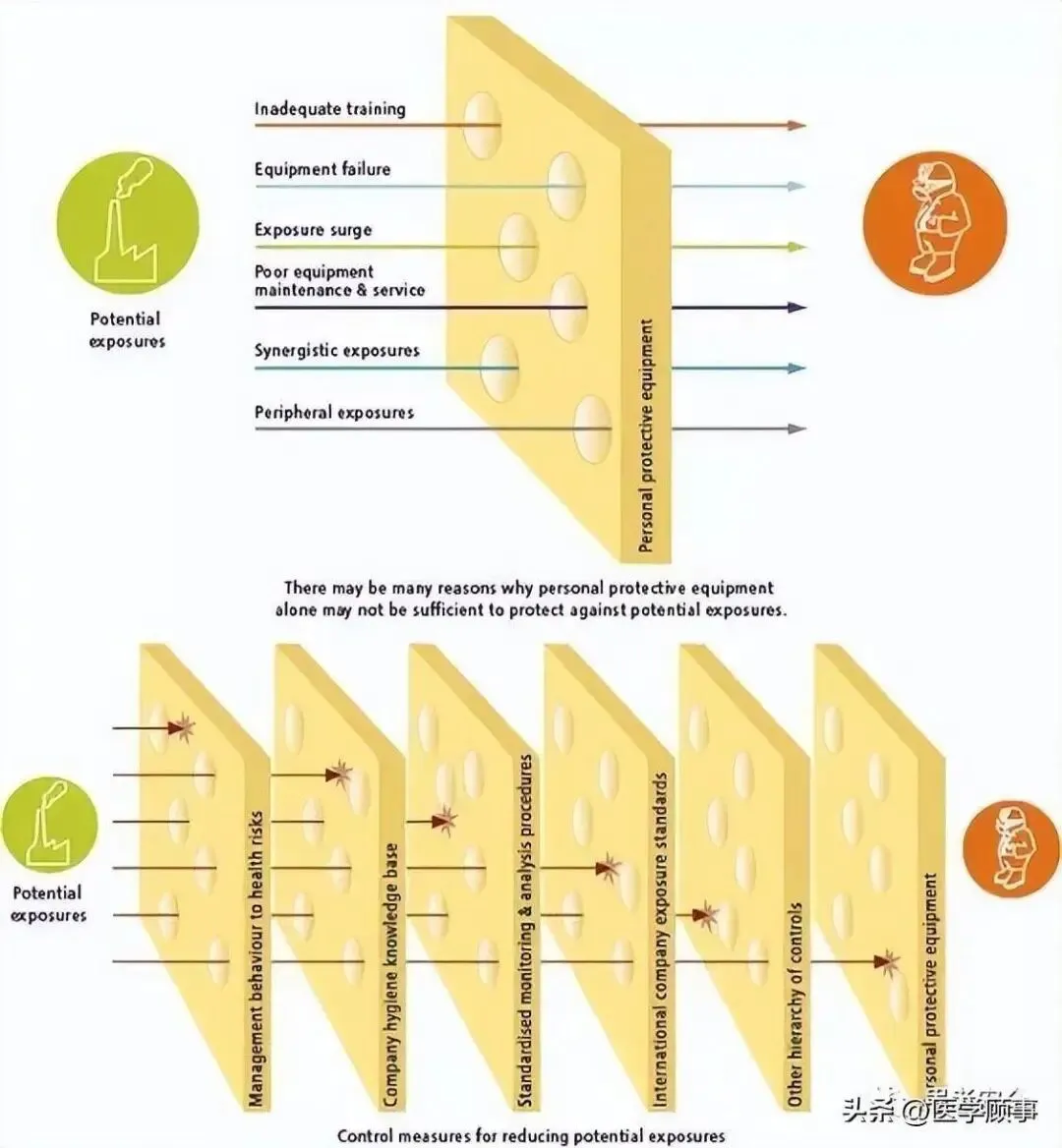
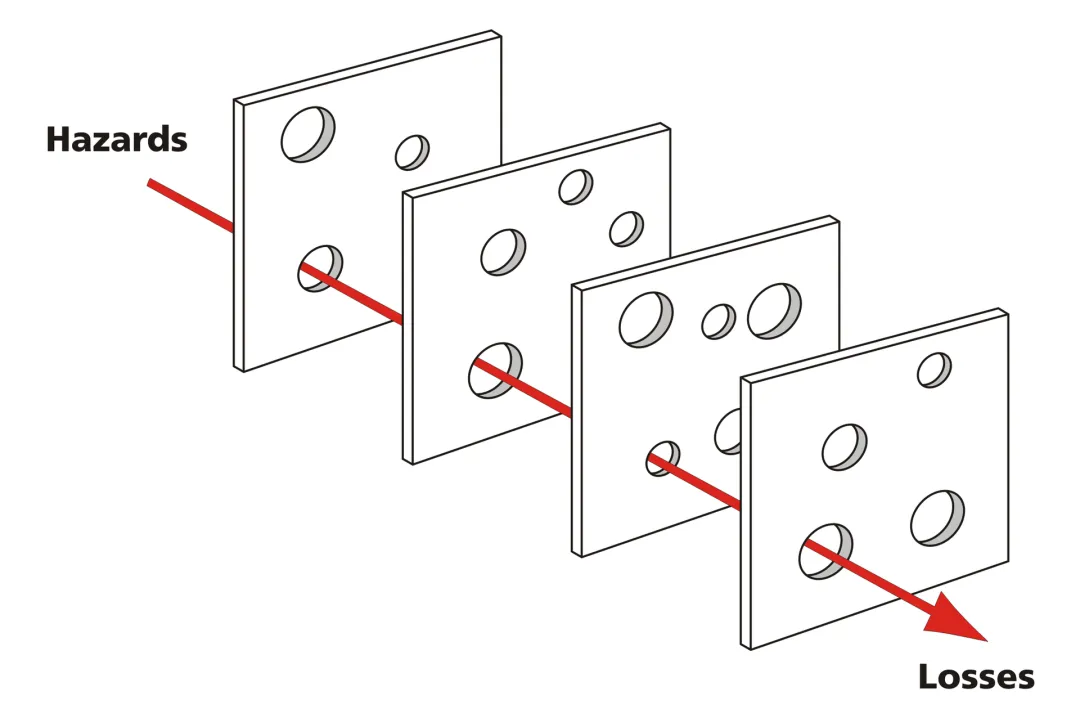
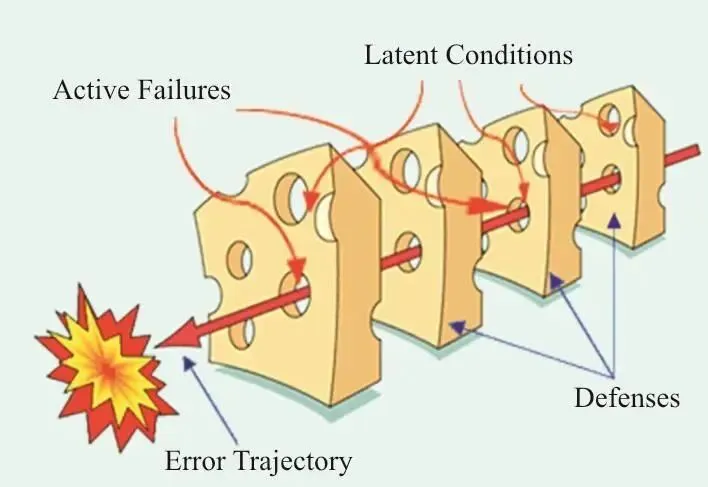
3. 瑞士奶酪模型 + 动态贝叶斯网络
多层微小缺陷的“对齐”。
Reason的瑞士奶酪模型指出,事故是各层防御上原本极小的“孔洞”瞬间对齐的结果。每个孔洞就是一个“忽微”。
建模方式:构造动态贝叶斯网络,每层防御节点有“正常/微小失效”状态。微小失效的概率随时间缓慢增大,且层级间有条件依赖。
核心算法:
计算所有孔洞对齐的概率——
P(事故) = P(孔洞_1 ∩…孔洞_k)
随着维护疏漏(忽微积累),单层失效概率从0.001升至0.05,对齐概率便从10^{-9}升至10^{-4},形成爆发性增长。
优势:可动态更新,每发现一次“忽微”(如巡检发现螺丝松动),就更新其后验概率,提前预警对齐风险。
这对应小概率事件必定会发生或经常性发生…
所有小孔同时对齐的那一瞬间——
但是,有一些事故,并不是某个单一指标累积突破了阈值,而是多层防御之上那些原本毫不起眼的小漏洞,在某一个瞬间突然地对齐了。Reason 的瑞士奶酪模型,但凡从事风险管理的人都是知道的,然而,真正能够动态地计算“孔洞对齐概率”的团队却并不多。
一种比较务实的做法是搭建一个动态贝叶斯网络。在每一层防御的节点上,只设定两个状态:正常,或者微小失效。微小失效的概率被设定为随着时间而缓慢地增大,并且层级之间存在着条件的依赖。单个孔洞出现的概率也许仅仅是从 0.001 上升到 0.05,维护人员可能会感觉到这仍处在可接受的范围之内,但是,当你要同时计算那个概率时,其爆发性强得吓人。
我本人就曾经经历过这一种类的事情。早年我经手过一个元器件等级的失效分析,单个批次的问题率标称只有 10PPM,这看起来是极其良好的了,对吧?
但是,那一次恰好有几个“十万分之一”等级的微小缺陷同时地出现在一条关键的回路上,系统便直接被击穿。当时并没有动态贝叶斯网络这种东西,在事后进行复盘时才意识到,这套系统早已经被无数细微的缺陷悄悄地掏空了,它只是在等待着最后的一个随机的工况而已。
4. 级联失效的网络模型
微小扰动在耦合系统中的雪崩。
金融系统性风险、电网崩溃、供应链断裂中,一个微小节点的初始异常(忽微)会通过关联传播被逐级放大。
模型:相依网络渗流模型 或 阈值模型
机制:定义每个节点有“微小扰动”的耐受度。
当某节点因忽微失效,其负载转移给邻居。邻居原本只承受自身的小缺陷,现在叠加后超过阈值,引发级联反应。
建模“忽微”:将系统初始状态设为所有节点都带有微小的随机减额(如0.5%能力衰减),通常无碍,但通过仿真可知,只需再加一个随机冲击,就能找出引发全局崩溃的临界点。
价值:揭示看似冗余充足、实则已被无数小缺陷掏空的“临界系统”。
级联失效,更多的在于绝大多数可靠性模型的串联属性……
5. 弱信号检测与变点分析
在“积微”阶段就拉响警报。
“忽微”在数据上表现为指标缓慢漂移,常规阈值警报会漏掉。建模目标是识别统计上的微小偏移累积(漂移,征兆)。
〔1〕方法:
CUSUM(累积和控制图) 或 指数加权移动平均(EWMA)
CUSUM逻辑: St= max(0, S(t-1) + (xt - μ0) - k)
其中 k 是允许的微小松弛量
xt —— 第 t 个观测值
μ0—— 目标均值或过程受控均值
k —— 参考值(或容忍度、松弛因子)
k一个设计参数,用来定义“多大的偏差才值得被关注”。只有正向偏差 x_t - μ0超过 k 时,多余的偏差才会被累积;小于 k 的随机波动会被自动滤除。
选择依据:通常 k = δ/2,
其中 δ是我们希望尽快检测到的最小有实际意义的偏移量。比如我们想对“均值上升 1.0 单位”敏感,可设 k = 0.5。
St 与 S(t-1)—— 上侧累积和统计量
St 是到时刻 t 为止,所有超出容许范围的微小正偏差的累积和。它是一个“记忆值”,只要持续有微小的超额偏差,它就会越积越大。
S_0 通常设为 0。
公式中的 max(0, . ) 保证 St 永远不会变负,一旦没有正向超额偏差,累积和就被重置为 0,不会对过去负的偏差“记仇”。
这就让统计量只对持续的正向漂移敏感。
这个统计量专门对持续的小偏差进行积分式累积,一旦突破控制线即报警——完美呼应“积于忽微”。
应用:医疗设备轻微漏电流、金融交易微小异常频率,CUSUM能比传统阈值早数个周期捕捉到恶化趋势。
〔2〕公式的运作逻辑(结合“忽微”)
将 S(t-1) + (xt -μ0) - k 分解来看:
① 计算当前偏差:xt - μ0
如果过程正常,这个值应在 0 附近上下波动;如果出现微小恶化,它会变成一个虽小但持续存在的正数。
② 减去容忍度 k:(xt -μ0) - k
如果今天的偏离还不够大(即 xt - μ0 ≤k),则括号内为负数或零,加上之前的 S(t-1) 后可能会变小,但 max(0, .) 会把它截断为 0。
这意味着:孤立的、微小的波动完全被忽略,不积累风险。
③ 累积“超额”偏差:
只有当 xt -μ0 > k 时,超额部分 (xt - μ0) - k 才会被加到上一期的累积和 S(t-1) 上。
这正是“积于忽微”的模型化:每次偏离都“很小”,比如仅仅超过容忍线 0.1 个单位,一次并不起眼。但如果过程均值已经悄悄偏移,这种微小的超额就会日复一日地累加,使 St 稳步增长。
④ 触发警报:
当累积和 St 达到预设的控制界限 h(决策区间),系统就判定“微小的偏移已经积累到不可忽视的程度”,发出报警。
h通常基于可接受的平均运行长度(ARL)来设定。
这个与测试数据包络分析其实在内在层面是一致的……
6. 系统动力学
正反馈下的“微小失误 → 形势恶化”闭环。
“忽微”还常体现在人因与组织失误中:一个小疏忽增加了工作负荷,导致更多小疏忽,最终系统崩溃。
模型:系统动力学流图
关键回路:微小偏差 → 需要额外检查 → 时间压力上升 → 更可能跳过微小步骤 → 更多偏差累积。
仿真:设定初始“微小忽视规程”的发生概率仅1%,但通过“疲劳-走捷径”反馈环,仿真数月后,规程遵守率可能从99%滑坡到60%,重大事故风险陡增。
干预点:模型能揭示在哪个节点打破“积微”循环最高效(如增加自动提醒装置)。
二、建模“忽微”的三条核心原则
1. 必须引入时间/次数累积维度——单次忽微毫无威胁,风险是它累积计数的函数。
2. 关注阈值与非线性——通常用幂律或指数函数连接微小因子与灾难,而非线性外推。
3. 数据源要下沉到“领先指标”——近失报告、微缺陷记录、性能漂移日志、员工安全观察卡,没有这些,“忽微”永远是黑箱。
若把上述方法集成,一个典型的智能风险系统会:
用CUSUM监控传感器数据的微漂移 → 检测到累积异常时,更新贝叶斯网络各孔洞状态 → 触发退化模型重新预测剩余寿命 → 结合网络模型评估级联影响,最终给出“虽未见明显故障,但忽微已积累至临界,建议立即停机检修”的决策。
这正是古人智慧的数理化再现:能够建模那些“什么都没发生,但一切都在积累”的寂静时刻,才算真正抓住了“积于忽微”的祸患逻辑。
PS:
可以解释任何不放心环节皆可视为风险……