0. AI服务器的进化
早期,AI服务器主要靠GPU单方面升级来提升性能。但这条路快走到头了,因为把晶体管做小(制程微缩)越来越难,成本也越来越高。比如,4纳米工艺从2022年到2025年几乎停滞,直到今年才升级到3纳米。
大家发现,GPU很多时候都在“等数据”,算力再强,数据传不过来也白搭。于是,设计思路发生了根本性转变:从“GPU单一升级”转向“互联系统协同”。
什么意思呢?在2023年,一台AI服务器里,CPU的价值占到90%以上。但到了今天,GPU的价值占比降到了60%,而存储、PCB电路板、光模块这些负责“传输数据”的部件,价值量翻了3倍!
这就好比,一个城市的交通系统,以前只想着把法拉利(GPU)造得越来越快,现在发现路太窄(数据通道),法拉利也跑不起来。于是,大家开始一起修路、建高架、扩宽车道(提升存储、PCB、光模块)。
1. 从物理定义讲起:涛定律 = “电路的时间常数”
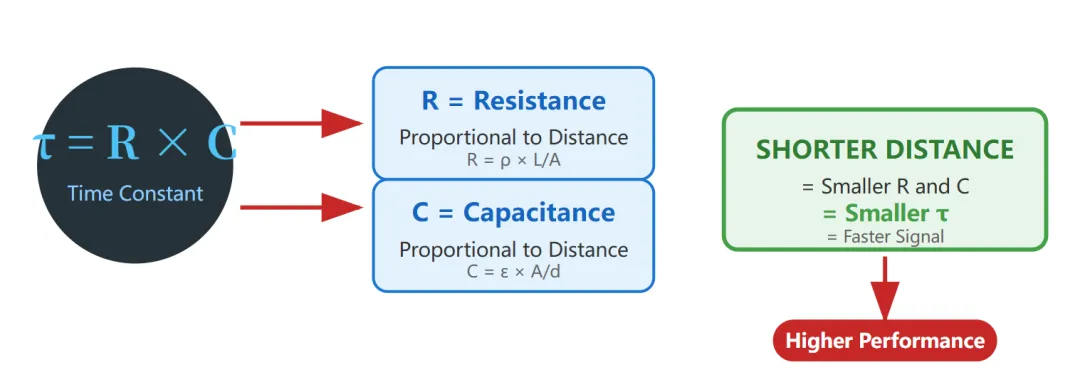
涛定律,符号写作 τ(读作“涛”),在物理学和电路理论中,它就是一个时间常数。它的计算公式是 τ = R × C(电阻乘以电容)。
这个时间常数决定了什么?决定了信号在这条电路上传播的速度。
那么问题来了:怎么把 τ 变小?
从公式看,要么减小 R(电阻),要么减小 C(电容)。但在芯片设计已经高度优化的情况下,最有效的办法是——缩短信号传输的物理距离。
因为距离越短,导线电阻 R 和寄生电容 C 自然就越小。所以,涛定律的本质用一句话就能说清:
要想芯片快,先让距离短。
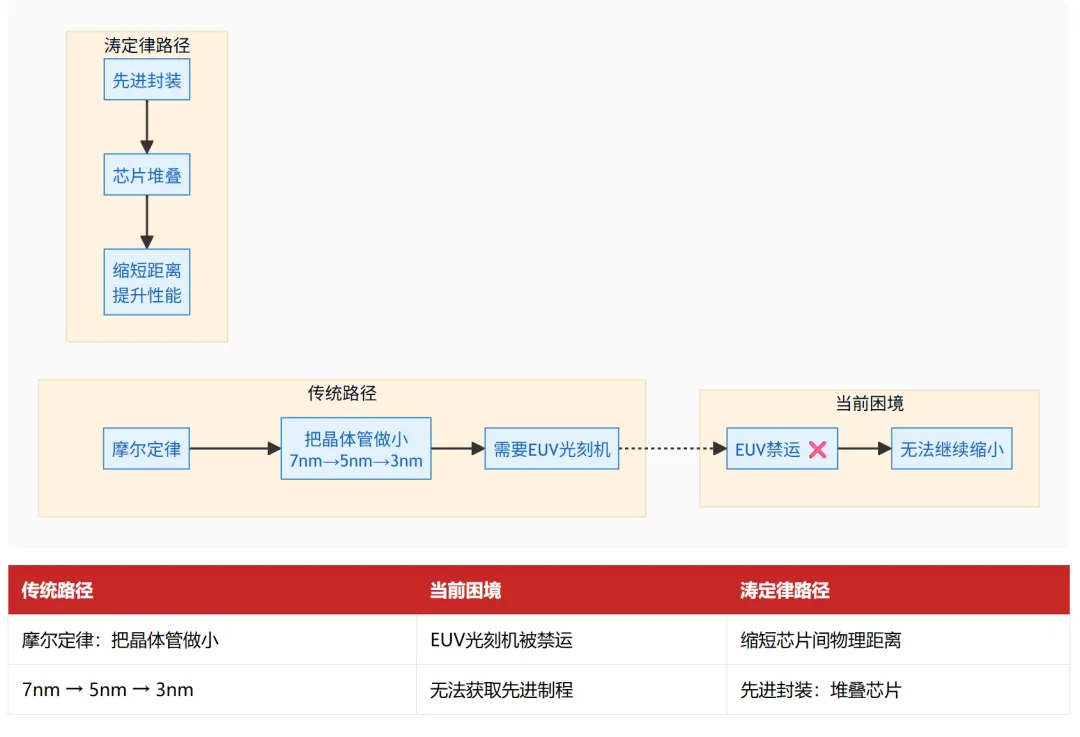
2. 产业现实:没有EUV光刻机,怎么继续提升性能?
过去几十年,我们靠“摩尔定律”吃饭:不断把晶体管做小,在同样面积里塞进更多管子。这条路靠的是先进制程,比如从7nm到5nm到3nm,需要最贵的EUV光刻机。
但在国内,EUV设备是被禁运的。我们没办法单纯靠“把线刻细”来提升性能了。那怎么办?
涛定律提供了另一条腿走路:既然单个晶体管缩小难,那我们就让多个芯片之间的配合更高效。
具体做法就是:不再把芯片平铺在电路板上,而是把它们上下堆叠起来,缩短彼此的“距离”。
这个“堆叠”的技术,就是先进封装。
3. 先进封装为什么是涛定律的核心工具?
我们可以用一个城市交通的比喻来理解:
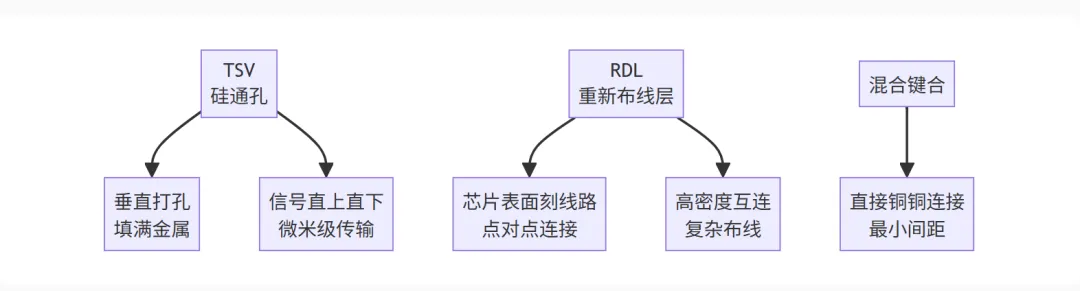
这个“专属电梯”就是TSV(硅通孔)——在硅片上垂直打孔,填满金属,让信号直上直下。
这个“直通走廊”就是RDL(重新布线层)——在芯片表面刻出极细的线路,实现复杂的点对点连接。
通过这种方式,芯片间的通信距离可以从几毫米甚至几厘米,缩短到微米级别。距离缩短了,τ自然就小了,信号传输速度和能效就上去了。
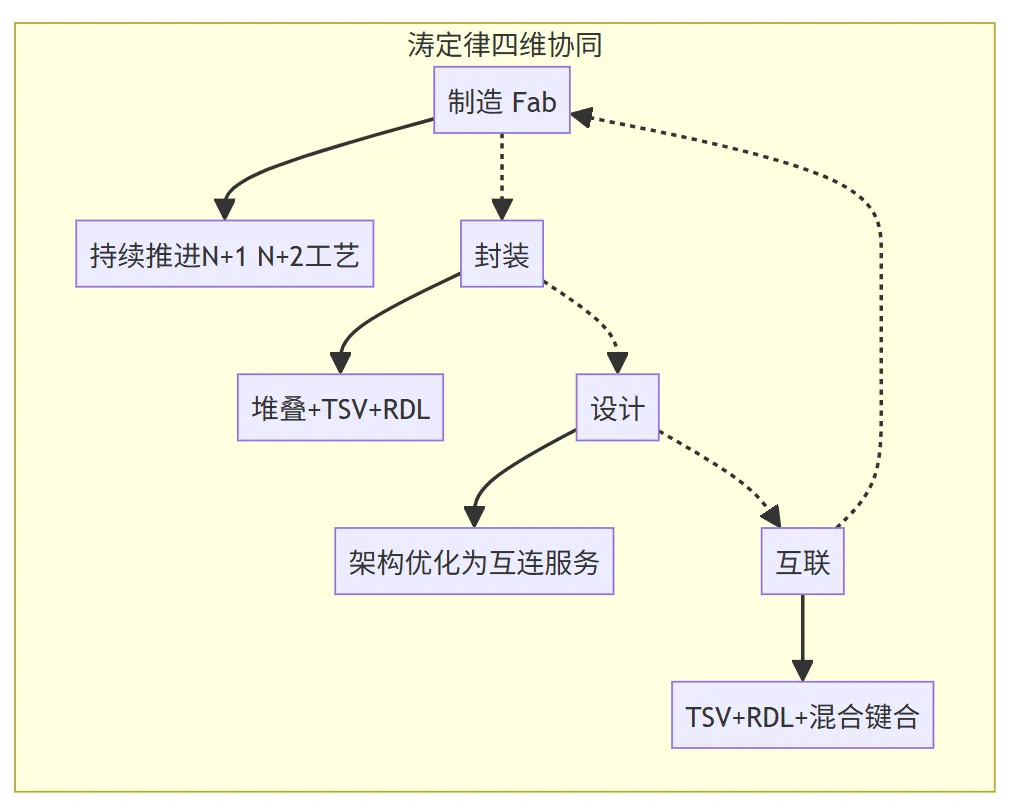
4. 涛定律不只是封装,而是一个“系统级”的思路
很重要的一点:涛定律并不是说只用先进封装就能解决所有问题。它强调的是“制造 + 封装 + 设计 + 互联”的系统协同。
制造(Fab):依然要推进我们的N+1、N+2、N+3工艺,这是基础。
封装:用堆叠和互连技术,弥补制程的不足。
设计:芯片架构要专门为堆叠和互连做优化,比如留出专门的“PHY区”用于高密度通信。
互联:包括TSV、RDL、混合键合等具体工艺的配合。
所以,涛定律的本质不是什么单一技术,而是一套在受限条件下,通过系统集成来持续提升芯片性能的工程方法论。
5. 华为的实践:已经量产381款芯片,证明这条路径可行
很多人会怀疑:这听起来像“弯道超车”,真的能落地吗?
华为已经给出了答案。根据会议信息,华为基于涛定律的思路,已经实现了381款芯片的量产,覆盖通信、计算、传感器等各个领域。
这些芯片已经在华为的手机、服务器等终端上大规模出货。这不是实验室里的概念,而是经过市场验证的成熟技术。
6. 争议与澄清:涛定律不是要替代摩尔定律
市场上也有一些担忧,比如:
它是否能像摩尔定律那样,保持几十年可预测、可重复的演进规律?这还需要时间和产业共识。但目前至少在华为体系内,它已经被当作一条工程规律在用了。
这是一个误解。实际上,先进封装需要的硅中介层(Interposer)本身就是在FAB厂用65nm/55nm工艺做的。而且,要把芯片性能推到1.4nm的等效水平,依然离不开FAB厂先进制程的进步。两者是协同关系,不是替代关系。
中国占全球半导体1/3的市场需求,这个体量足以拉动产业链上下游一起投入。只要需求在,设备商、材料商、封测厂都会跟着走。
7. 总结:涛定律的本质,一句话 + 三个关键词
一句话:
通过缩短芯片间的物理距离,来弥补先进制程的不足,让系统性能持续提升。
三个关键词: