摘要:上一篇文章拆解了 bthread_sem_t 的实现——butex 的值直接就是信号量的计数值,用 CAS 消费、fetch_add 生产。本文继续拆解 bthread 同步原语中组合最复杂的类型:读写锁 bthread_rwlock_t。它用两个信号量(reader_sema + writer_sema)和一个互斥锁(write_queue_mutex)组合实现,核心是 reader_count 的编码技巧——正值表示活跃读者数量,负值(减去 2^30)表示有写者等待。读锁只需一次 fetch_add(1) 就能在无写者时立即获取;写锁通过减去 2^30 "冻结"读者计数,阻止新读者进入(写者优先策略)。整个设计参考了 Go 语言的 RWMutex。在上一篇文章中,我们拆解了 bthread_sem_t——协程友好的信号量。我们看到 butex 的值直接就是计数值,用 CAS 消费、fetch_add 生产、butex_wake_n 唤醒。
现在我们拆解 bthread 同步原语中组合最复杂的类型:读写锁。
读写锁的规则:多个读者可以同时读取,但写者必须独占(读写互斥、写写互斥)。这在"读多写少"的场景中比互斥锁高效得多——互斥锁连读操作都要串行化。
但读写锁的实现也最复杂:需要区分读者和写者,需要处理"读者饿死写者"或"写者饿死读者"的公平性问题。bthread 的读写锁是如何解决这些问题的?让我们从数据结构开始。
一、bthread_rwlock_t:两个信号量 + 一个互斥锁
typedef struct bthread_rwlock_t { bthread_sem_t reader_sema; // 读者等待写者完成 bthread_sem_t writer_sema; // 写者等待读者完成 int reader_count; // 活跃读者计数(编码值) int reader_wait; // 写者等待期间还需退出的读者数 bool wlock_flag; // 写锁持有标志 bthread_mutex_t write_queue_mutex; // 写者队列互斥锁 bthread_contention_site_t writer_csite;// 写者竞争统计} bthread_rwlock_t;
reader_sema (bthread_sem_t) → 读者在此等待写者完成writer_sema (bthread_sem_t) → 写者在此等待读者完成write_queue_mutex (bthread_mutex_t) → 写者之间串行化
读者之间的并发通过 reader_count 的原子操作实现——不需要锁。写者之间通过 write_queue_mutex 串行化。读写之间的协调通过 reader_count 的编码和两个信号量完成。
二、reader_count 的编码技巧
reader_count 是理解读写锁的关键。它用一个 int 同时编码两个信息:
RWLockMaxReaders = 1 << 30(2^30 = 1073741824)。写者获取锁时执行 fetch_add(-2^30),使 reader_count 变为负数。
为什么是 2^30 而不是 2^31?因为 int 是有符号 32 位整数,范围 [-2^31, 2^31-1]。减去 2^30 后,低 30 位仍然是实际读者数量,符号位确保值为负。实际读者数不可能达到 2^30(十亿级),所以不会溢出。
无写者,3 个读者: reader_count = 3有写者等待,3 个读者:reader_count = 3 - 2^30 = -1073741821无写者,0 个读者: reader_count = 0有写者等待,0 个读者:reader_count = -2^30 = -1073741824
这种编码的好处:一次原子操作就能同时传达"读者数量"和"是否有写者"两个信息。读者加锁时 fetch_add(1) 后检查结果——如果 >= 0,快速路径获取成功;如果 < 0,知道有写者在等。
三、初始化与销毁
3.1 bthread_rwlock_init
intbthread_rwlock_init(bthread_rwlock_t* __restrict rwlock, const bthread_rwlockattr_t* __restrict) { // 初始化两个信号量(初值 0),禁用各自的竞争采样(读写锁自行管理) bthread_sem_init(&rwlock->reader_sema, 0); bthread_sem_disable_csite(&rwlock->reader_sema); bthread_sem_init(&rwlock->writer_sema, 0); bthread_sem_disable_csite(&rwlock->writer_sema); // 初始化计数器 rwlock->reader_count = 0; rwlock->reader_wait = 0; rwlock->wlock_flag = false; // 初始化写者队列互斥锁(禁用竞争采样) bthread_mutexattr_t attr; bthread_mutexattr_init(&attr); bthread_mutexattr_disable_csite(&attr); bthread_mutex_init(&rwlock->write_queue_mutex, &attr); bthread_mutexattr_destroy(&attr); return 0;}
三个要点:
- 信号量初值为 0——读者和写者都在信号量上等待"被唤醒",初始时没有信号
- 禁用内部原语的竞争采样——读写锁自行管理竞争分析,避免内部原语的采样干扰
- reader_count 和 reader_wait 初始化为 0——初始时没有活跃读者
3.2 bthread_rwlock_destroy
intbthread_rwlock_destroy(bthread_rwlock_t* rwlock){ bthread_sem_destroy(&rwlock->reader_sema); bthread_sem_destroy(&rwlock->writer_sema); bthread_mutex_destroy(&rwlock->write_queue_mutex); return 0;}
按初始化的逆序销毁三个内部原语,各自归还 butex 到 ObjectPool。
四、加读锁
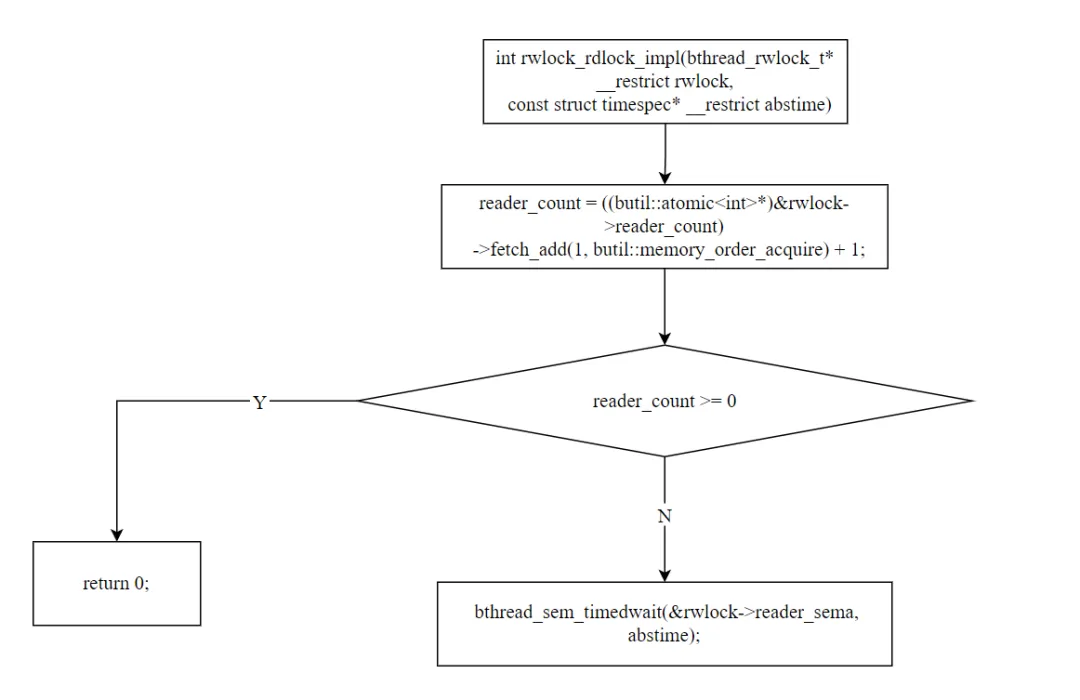
4.1 rdlock:阻塞获取
staticintrwlock_rdlock_impl(bthread_rwlock_t* rwlock, const struct timespec* abstime) { // 第一步:原子递增读者计数 int reader_count = ((butil::atomic<int>*)&rwlock->reader_count) ->fetch_add(1, butil::memory_order_acquire) + 1; // 第二步:快速路径——无写者等待 if (reader_count >= 0) { return 0; // 直接获取读锁成功 } // 第三步:慢速路径——有写者等待,在 reader_sema 上阻塞 return bthread_sem_timedwait(&rwlock->reader_sema, abstime);}
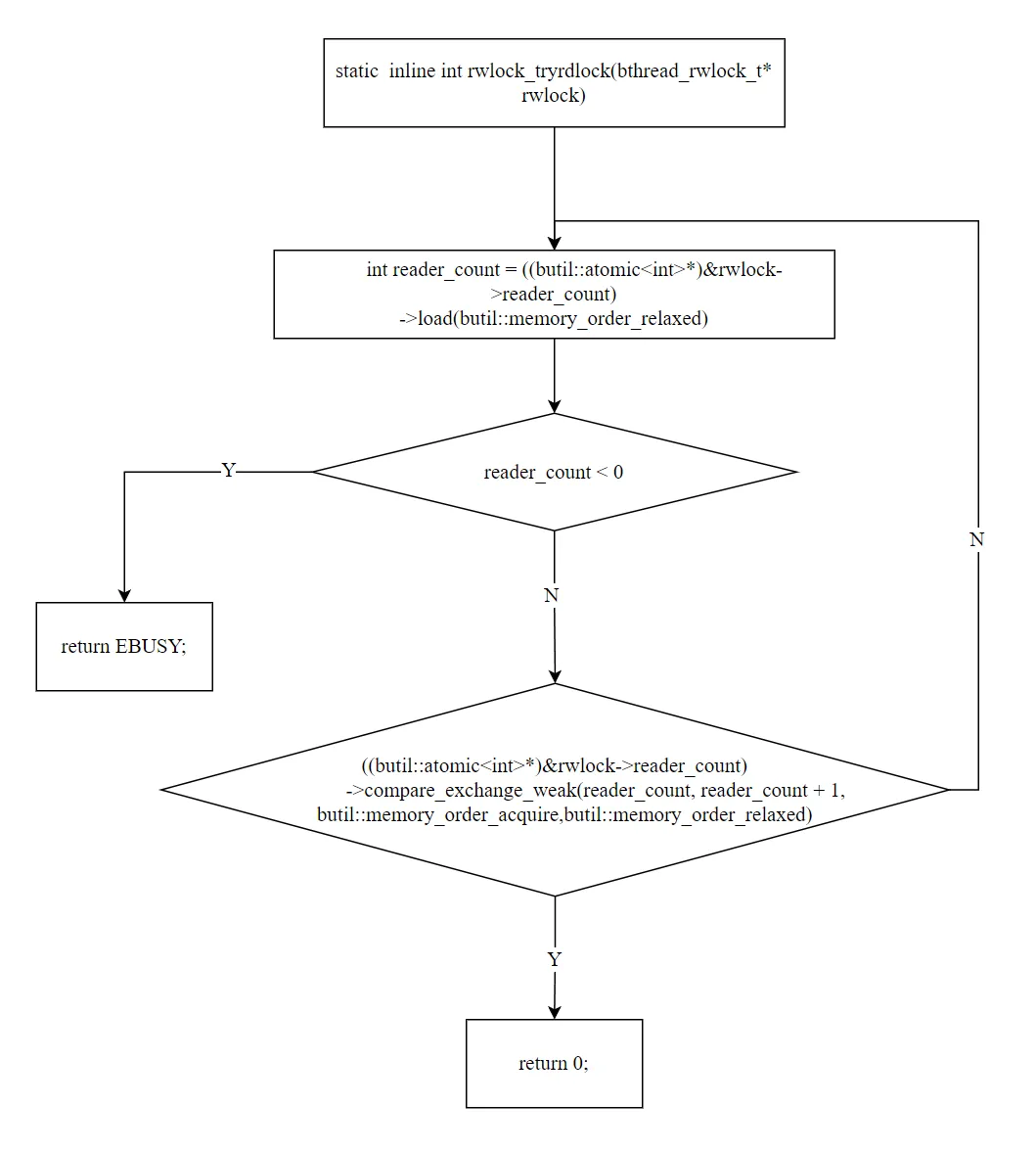
快速路径:fetch_add(1) 后结果 >= 0 → 无写者等待,直接获取读锁。这是最常见的路径——大多数情况下没有写者。慢速路径:fetch_add(1) 后结果 < 0 → 有写者等待,在 reader_sema 上阻塞等待。为什么先加 1 再判断?这是一种"乐观获取"策略。先假设没有写者,直接增加读者计数。如果发现有写者,也不需要撤销——读者计数已经加了 1,reader_wait 会在写者的等待逻辑中正确计算。大多数情况下读锁不会遇到写者竞争,所以 fetch_add 非常高效。4.2 tryrdlock:非阻塞获取
staticinlineintrwlock_tryrdlock(bthread_rwlock_t* rwlock){ while (true) { int reader_count = ((butil::atomic<int>*)&rwlock->reader_count) ->load(butil::memory_order_relaxed); if (reader_count < 0) { return EBUSY; // 有写者,获取失败 } if (((butil::atomic<int>*)&rwlock->reader_count) ->compare_exchange_weak(reader_count, reader_count + 1, ...)) { return 0; // CAS 成功 } // CAS 失败,重试 }}
与 rdlock 的区别:使用 CAS 而非 fetch_add,遇到写者时直接返回 EBUSY 而非阻塞。
五、释放读锁
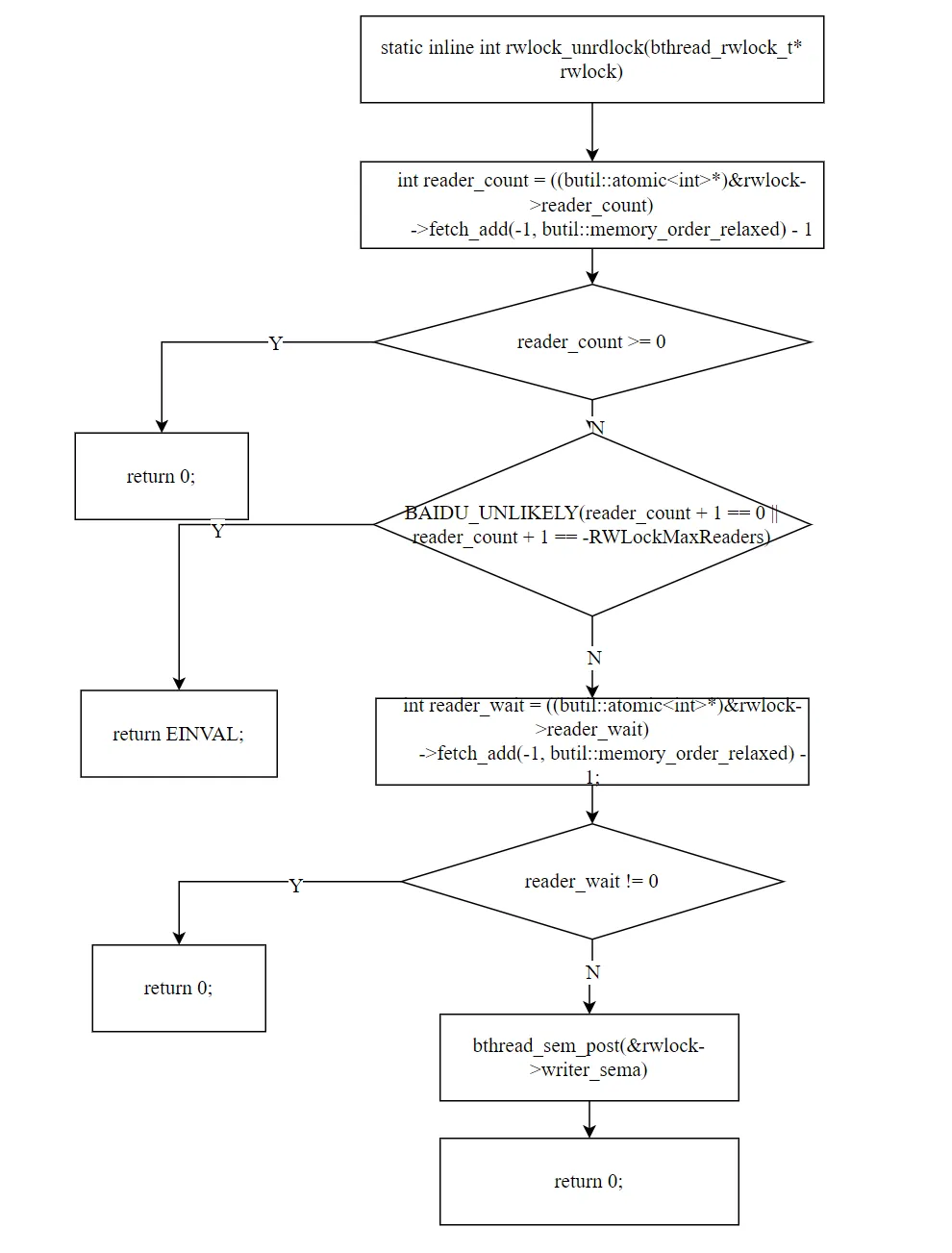
staticinlineintrwlock_unrdlock(bthread_rwlock_t* rwlock){ // 第一步:原子递减读者计数 int reader_count = ((butil::atomic<int>*)&rwlock->reader_count) ->fetch_add(-1, butil::memory_order_relaxed) - 1; // 第二步:快速路径——无写者等待 if (reader_count >= 0) { return 0; // 直接返回 } // 安全检查:双重解锁检测 if (reader_count + 1 == 0 || reader_count + 1 == -RWLockMaxReaders) { CHECK(false) << "rwlock_unrdlock of unlocked rwlock"; return EINVAL; } // 第三步:有写者等待,递减 reader_wait int reader_wait = ((butil::atomic<int>*)&rwlock->reader_wait) ->fetch_add(-1, butil::memory_order_relaxed) - 1; if (reader_wait != 0) { return 0; // 还有其他读者未退出 } // 第四步:最后一个读者唤醒写者 bthread_sem_post(&rwlock->writer_sema); return 0;}
释放读锁分两步:
快速路径:fetch_add(-1) 后结果 >= 0 → 无写者等待,直接返回。
慢速路径:fetch_add(-1) 后结果 < 0 → 有写者等待。递减 reader_wait。如果 reader_wait 降为 0,说明当前是最后一个读者,负责唤醒写者(通过 writer_sema)。
关键细节:只有最后一个读者才唤醒写者。这避免了多个读者同时 post writer_sema 导致信号量计数不正确。
六、加写锁
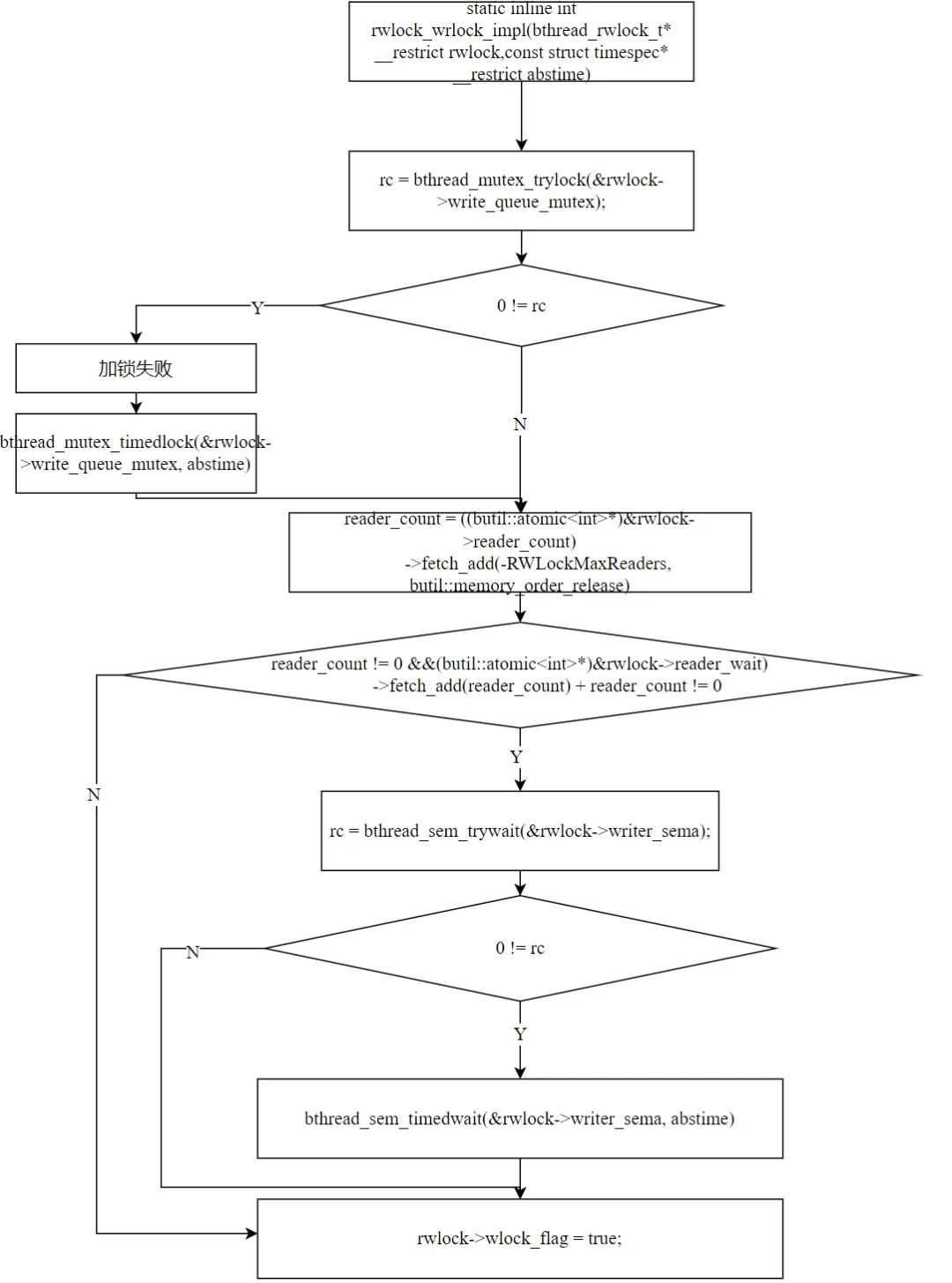
staticinlineintrwlock_wrlock_impl(bthread_rwlock_t* rwlock, const struct timespec* abstime) { // 第一步:获取 write_queue_mutex(与其他写者竞争) int rc = bthread_mutex_trylock(&rwlock->write_queue_mutex); if (0 != rc) { rc = bthread_mutex_timedlock(&rwlock->write_queue_mutex, abstime); if (0 != rc) return rc; } // 第二步:宣布有写者等待(reader_count -= RWLockMaxReaders) int reader_count = ((butil::atomic<int>*)&rwlock->reader_count) ->fetch_add(-RWLockMaxReaders, butil::memory_order_release); // 第三步:等待活跃读者全部退出 if (reader_count != 0 && ((butil::atomic<int>*)&rwlock->reader_wait) ->fetch_add(reader_count) + reader_count != 0) { // trywait 检查是否最后一个读者已经 post rc = bthread_sem_trywait(&rwlock->writer_sema); if (0 != rc) { rc = bthread_sem_timedwait(&rwlock->writer_sema, abstime); if (0 != rc) { bthread_mutex_unlock(&rwlock->write_queue_mutex); return rc; } } } rwlock->wlock_flag = true; // 标记写锁已持有 return 0;}
加写锁分三步:
6.1 第一步:写者之间串行化
bthread_mutex_trylock(&rwlock->write_queue_mutex);
多个写者通过 write_queue_mutex 串行化。只有一个写者能持有这把锁——其他写者必须等待。这是写写互斥的保证。
6.2 第二步:宣布有写者等待
fetch_add(-RWLockMaxReaders)
将 reader_count 减去 2^30,使其变为负数。这有两个效果:
- 后续的读者会检测到负值,进入慢速路径在
reader_sema 上阻塞——这就是写者优先策略 - 返回值是减之前的旧值,即当前活跃的读者数量
6.3 第三步:等待读者退出
fetch_add(reader_count) + reader_count
将活跃读者数量累加到 reader_wait。如果 reader_wait 不为 0,说明还有读者未退出,写者在 writer_sema 上等待。
这里有一个优化:先 trywait 检查最后一个读者是否已经 post 了 writer_sema。如果是,直接消费信号量,不需要阻塞。
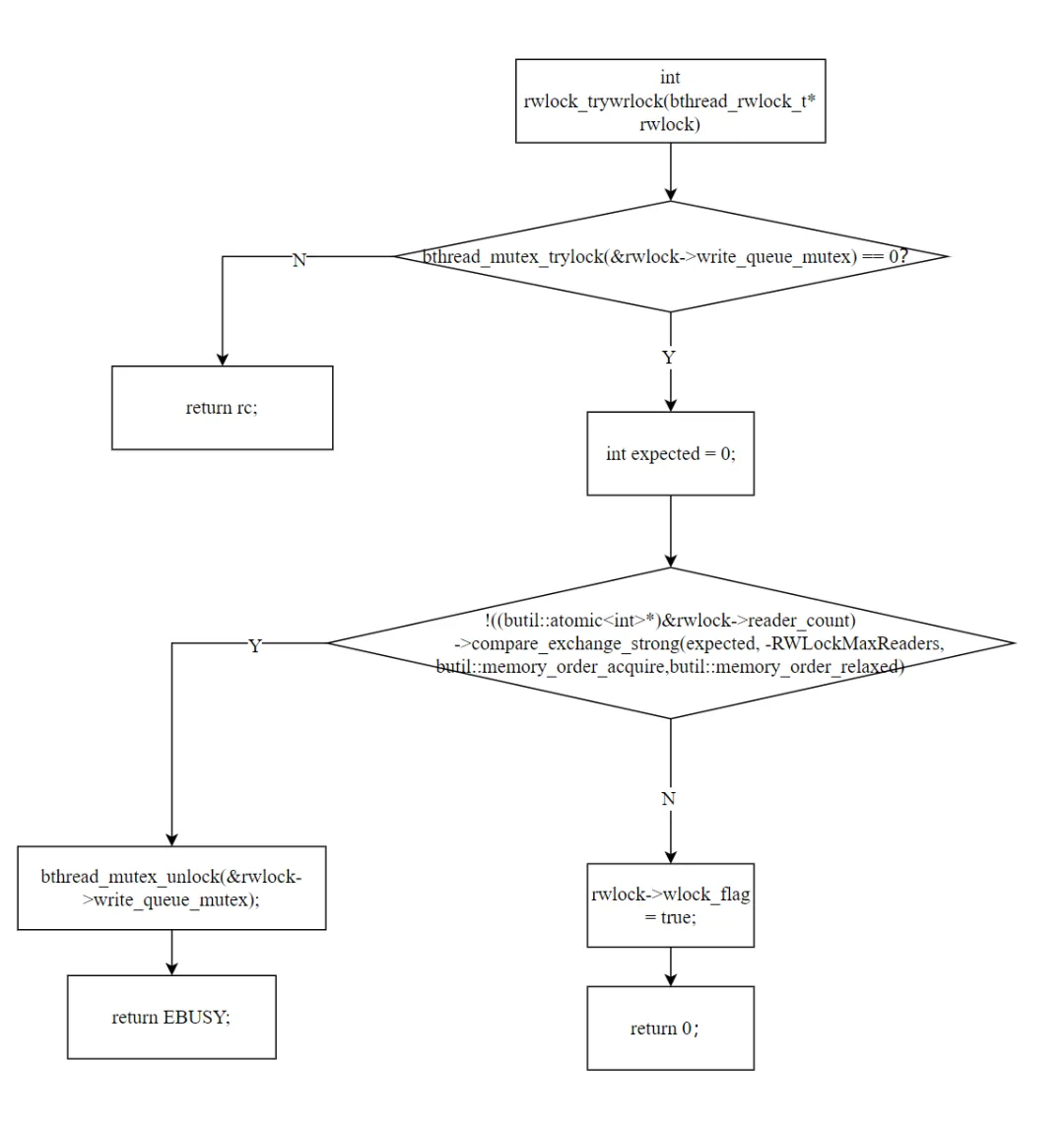
6.4 trywrlock:非阻塞获取
staticinlineintrwlock_trywrlock(bthread_rwlock_t* rwlock){ int rc = bthread_mutex_trylock(&rwlock->write_queue_mutex); if (0 != rc) return rc; int expected = 0; if (!CAS(reader_count, 0 → -RWLockMaxReaders)) { bthread_mutex_unlock(&rwlock->write_queue_mutex); return EBUSY; } rwlock->wlock_flag = true; return 0;}
两个条件缺一不可:
write_queue_mutexreader_count == 0
只有两个条件同时满足,才能 CAS 成功获取写锁。
七、释放写锁
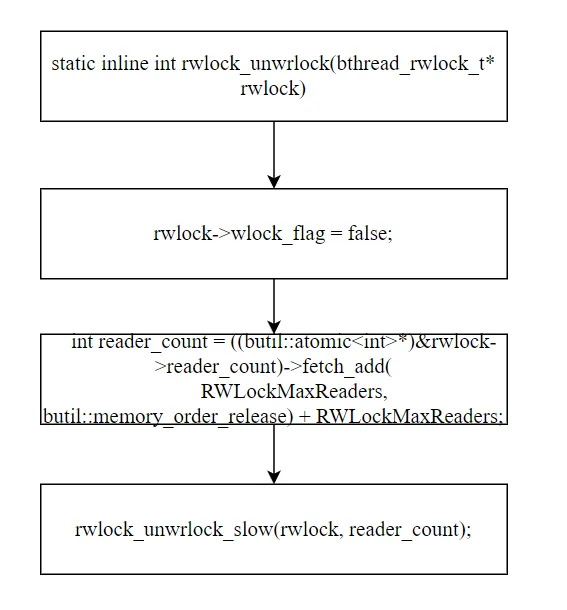
staticinlineintrwlock_unwrlock(bthread_rwlock_t* rwlock){ rwlock->wlock_flag = false; // 恢复 reader_count int reader_count = ((butil::atomic<int>*)&rwlock->reader_count) ->fetch_add(RWLockMaxReaders, butil::memory_order_release) + RWLockMaxReaders; // 慢路径:唤醒被阻塞的读者 + 释放写者互斥锁 rwlock_unwrlock_slow(rwlock, reader_count); return 0;}staticinlinevoidrwlock_unwrlock_slow(bthread_rwlock_t* rwlock, int reader_count){ bthread_sem_post_n(&rwlock->reader_sema, reader_count); // 批量唤醒读者 bthread_mutex_unlock(&rwlock->write_queue_mutex); // 允许下一个写者进入}
- 清除写锁标志:
wlock_flag = false - 恢复 reader_count:
fetch_add(RWLockMaxReaders) 加回 2^30。加回后的值就是写者持有期间累积的等待读者数量(他们在 reader_sema 上阻塞) - 唤醒等待者:
sem_post_n 批量唤醒 reader_count 个等待的读者,然后释放 write_queue_mutex 让下一个写者进入
注意释放顺序:先唤醒读者,再释放写者互斥锁。这确保被唤醒的读者在下一个写者获取锁之前有机会运行。
八、unlock:自动判断读锁/写锁
staticinlineintrwlock_unlock(bthread_rwlock_t* rwlock){ if (rwlock->wlock_flag) { return rwlock_unwrlock(rwlock); // 释放写锁 } else { return rwlock_unrdlock(rwlock); // 释放读锁 }}
九、写者优先策略
读写锁有一个经典的公平性问题:如果读者不断到来,写者可能永远等不到——这就是"读者饿死写者"。bthread 读写锁通过 write_queue_mutex 实现了写者优先策略:
时间线: t1: 读者A 获取读锁(reader_count = 1) t2: 写者X 获取 write_queue_mutex → reader_count -= 2^30 → 等待读者退出 t3: 读者B 尝试获取读锁 → reader_count < 0 → 在 reader_sema 上阻塞 t4: 读者A 释放读锁 → 最后一个读者 → 唤醒写者X t5: 写者X 获取写锁 t6: 写者X 释放写锁 → 唤醒读者B + 释放 write_queue_mutex
关键:在 t3 时刻,读者 B 检测到 reader_count < 0,被阻塞而不是直接获取读锁。这就是写者优先——一旦有写者开始等待,新的读者不能"插队"。
而 write_queue_mutex 在整个写锁持有期间都被持有(从加锁到释放),确保了:
- 写者等待期间,新读者被挡在
reader_sema 上(写者优先)
十、完整的状态转换图
把所有操作串联起来:
初始状态:reader_count = 0,无锁rdlock(): fetch_add(1) → reader_count >= 0? → 成功(共享读) reader_count < 0? → 阻塞在 reader_semawrlock(): 获取 write_queue_mutex → fetch_add(-2^30)(宣布有写者) → 等待活跃读者退出(reader_wait 降为 0) → 设置 wlock_flag = trueunrdlock(): fetch_add(-1) → reader_count >= 0? → 直接返回 reader_count < 0? → reader_wait-- → reader_wait == 0? → post(writer_sema) 唤醒写者unwrlock(): wlock_flag = false fetch_add(+2^30)(恢复读者计数) → sem_post_n(reader_sema)(唤醒等待的读者) → unlock(write_queue_mutex)(允许下一个写者)
关键观察:读写锁的所有状态转换都通过 reader_count 的原子操作完成。 读者用 fetch_add(±1),写者用 fetch_add(±2^30)。两种操作的"步长"不同,不会互相干扰——读者加 1 后检查正负,写者减 2^30 后读者看到负值。
十一、C++ 封装层
11.1 RWLock
class RWLock {public: RWLock() { bthread_rwlock_init(&_rwlock, NULL); } ~RWLock() { bthread_rwlock_destroy(&_rwlock); } voidrdlock() { bthread_rwlock_rdlock(&_rwlock); } voidwrlock() { bthread_rwlock_wrlock(&_rwlock); } booltry_rdlock() { return 0 == bthread_rwlock_tryrdlock(&_rwlock); } booltry_wrlock() { return 0 == bthread_rwlock_trywrlock(&_rwlock); } booltimed_rdlock(const timespec* abstime) { ... } booltimed_wrlock(const timespec* abstime) { ... } voidunlock() { bthread_rwlock_unlock(&_rwlock); } native_handler_type native_handler() { return &_rwlock; }private: bthread_rwlock_t _rwlock{};};
RAII 封装,构造时初始化,析构时销毁。
11.2 RAII 守卫
RWLockRdGuard(读锁守卫):
RWLockRdGuard guard(rwlock); // 构造时加读锁// ... 临界区 ...// 析构时自动释放
RWLockWrGuard guard(rwlock); // 构造时加写锁// ... 临界区 ...// 析构时自动释放
11.3 lock_guard 特化
// 通过 read 参数选择读锁/写锁std::lock_guard<bthread_rwlock_t> rd_lk(rwlock, true); // 读锁std::lock_guard<bthread_rwlock_t> wr_lk(rwlock, false); // 写锁
为 bthread_rwlock_t 和 bthread::RWLock 都提供了 std::lock_guard 特化。Debug 模式下会在加锁失败时记录 FATAL 日志并将指针置空,防止析构时 double unlock。
十二、与 Go RWMutex 的关系
源码注释明确说明:bthread_rwlock_t 是 Go 语言 RWMutex 的 bthread 实现。
A `bthread_rwlock_t' is a reader/writer mutual exclusion lock, which is a bthread implementation of golang RWMutex.For details, see https://github.com/golang/go/blob/master/src/sync/rwmutex.go
核心算法完全一致:
| | |
|---|
| int32 | int |
| int32 | int |
| sync.Mutex | bthread_sem_t |
| | bthread_sem_t |
| sync.Mutex | bthread_mutex_t |
| | |
区别在于阻塞原语:Go 使用 goroutine 的 semaphore,bthread 使用 butex。
十三、总结
bthread_rwlock_t 的设计可以归纳为一句话:用 reader_count 的编码技巧在读者和写者之间传递状态,用信号量和互斥锁组合实现等待和唤醒。
四个关键设计:
1. reader_count 的双重编码。 一个 int 同时编码活跃读者数量和是否有写者等待。正值(≥ 0)表示读者数量,负值(减去 2^30)表示有写者。读者和写者的原子操作步长不同(±1 vs ±2^30),互不干扰。
2. 写者优先策略。 写者通过 write_queue_mutex 串行化,并在获取锁时将 reader_count 减为负值。后续的读者检测到负值后被阻塞在 reader_sema 上,不能"插队"领先于写者。
3. 组合式设计。 读写锁不是从零实现,而是组合了两个信号量和一个互斥锁。读者在 reader_sema 上等待写者完成,写者在 writer_sema 上等待读者完成,写者之间通过 write_queue_mutex 串行化。
4. 读者的乐观获取。 加读锁时先 fetch_add(1) 再判断是否有写者——大多数情况下没有写者,一次原子操作就能获取锁。即使有写者,读者计数已经加了 1,reader_wait 的计算仍然正确。
本文基于 Apache brpc 源码(src/bthread/rwlock.h、src/bthread/rwlock.cpp、src/bthread/types.h)撰写。