摘要:逻辑回归虽然叫回归,做的其实是分类。它在线性回归外面叠加了一层 Sigmoid 函数,把输出从实数映射成 0~1 之间的概率。在 Titanic 数据集上跑到了 81% 的准确率,也说清楚什么时候用逻辑回归、以及与线性回归的关系。前面两篇讲的都是回归,预测一个连续数值,比如房价。这次换个任务:做分类。回归回答"多少",分类回答"是不是"。某个乘客是否幸存?邮件是垃圾还是正常?图片里是猫还是狗?分类问题比回归更常见。
逻辑回归就是解决二分类最基础的模型。
一、从线性回归到逻辑回归
输出的实数范围,正无穷到负无穷都有可能。但分类要的是 0 或 1,至少也得是个概率。怎么把一个实数映射成 [0, 1] 这个区间?答案就是 Sigmoid 函数:
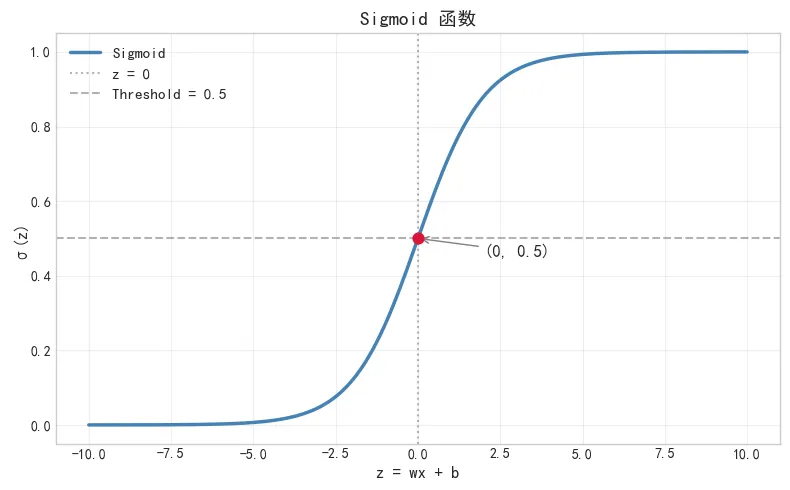
不管 z 多大或多小,Sigmoid 都把它映射到 0~1 之间。流程就变成了:先算线性部分 z = wx + b,再经过 Sigmoid,输出就是概率。多了一层函数,可以这么理解:先用线性回归算一个分数,再用 Sigmoid 把分数映射为概率。 概率大于 0.5 就预测为 1(幸存),否则为 0(遇难)。 Sigmoid 函数曲线,把实数映射到 0~1 之间,在 z=0 附近输出 0.5。灰色虚线标记了阈值 0.5 的位置。 从曲线形状可以看出,z 在 -5 以下时输出接近 0,+5 以上时输出接近 1,中间段是平滑过渡。这意味着线性部分的分数越正,幸存概率越接近 1;越负,则越接近 0。线性回归用均方误差(MSE),逻辑回归用二元交叉熵(Binary Cross-Entropy):Loss = -[y·log(ŷ) + (1-y)·log(1-ŷ)]
为什么不用 MSE?Sigmoid 把输出映射到 0~1 后,MSE 的梯度在两端会变得非常小。参数还没收敛到理想值,梯度却几乎为零,导致收敛缓慢。交叉熵在预测错误时梯度大、预测正确时梯度小,收敛速度更快。
换个角度看,交叉熵衡量的是"预测分布"与"真实分布"之间的距离,预测偏差越大,损失越大。
# 线性回归的梯度(MSE 损失)dw = (1/n) * X.T · (ŷ - y)# 逻辑回归的梯度(交叉熵损失)dw = (1/n) * X.T · (ŷ - y)
区别在于:线性回归的 ŷ 就是 wx + b 本身,而逻辑回归的 ŷ = σ(wx + b)。差别就是多了一步 Sigmoid。# 线性回归y_pred = np.dot(X, self.w) + self.b# 逻辑回归logits = np.dot(X, self.w) + self.by_pred = self._sigmoid(logits)
二、实验:Titanic 幸存者预测
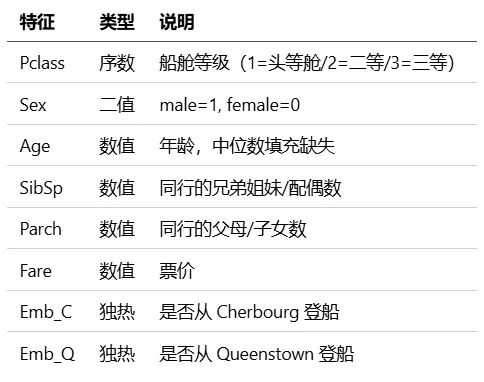
Titanic 数据集在分类入门里被广泛使用,已经是事实标准了。每条数据记录一个乘客的信息(船舱等级、性别、年龄、票价等),目标是预测他是否幸存。选取8个特征做预测,其中Embarked 是登船港口,有 C(Cherbourg)、Q(Queenstown)、S(Southampton)三个值。做独热编码后,用两个 0/1 变量表示:C=(1,0)、Q=(0,1)、S=(0,0)。S 作为基准,当两个变量都为 0 时模型就知道了。三个类别只需要两个哑变量,加第三个会导致特征间完全共线(虚拟变量陷阱),影响模型求解。891 条数据,80/20 拆分。训练集 712 条,测试集 179 条。幸存比例约 38%(训练集 37.6%,测试集 41.3%)。测试集准确率81.01%。对于只用 8 个简单特征的手写逻辑回归来说,表现不错。
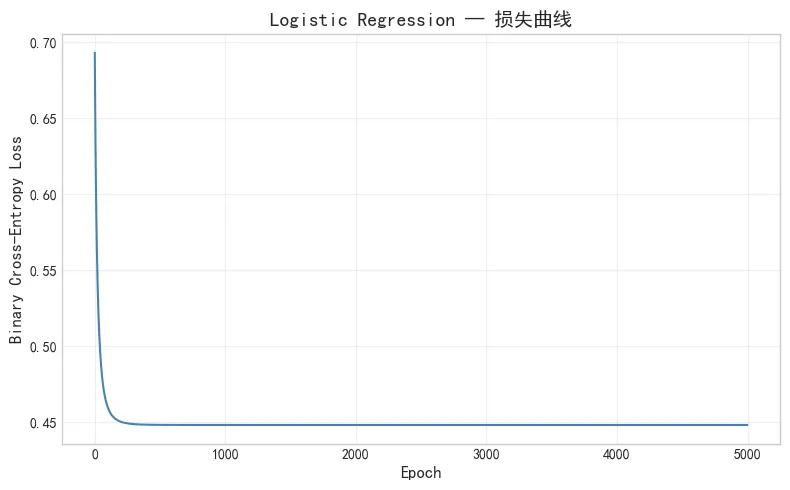
Train Loss: 0.4482, Train Acc: 0.8006Test Loss: 0.4156, Test Acc: 0.8101
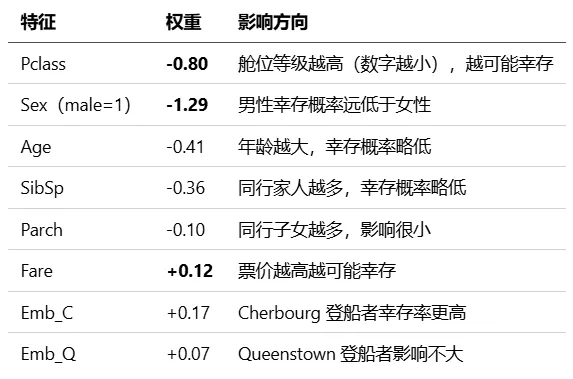
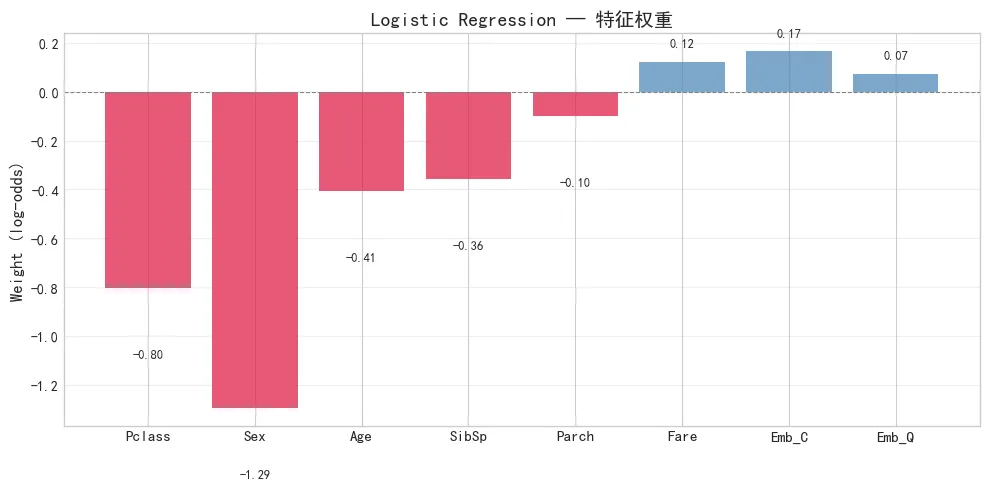
损失曲线,前 500 轮快速下降,后面平缓收敛。5,000 轮时基本稳定。 前 500 轮损失从 0.69 降到 0.48 左右,下降最快;后面 4,500 轮只降了 0.03。训练集和测试集损失很接近(0.448 vs 0.416),说明没有过拟合。权重是 log-odds(对数几率)的系数。正权重增加幸存概率,负权重降低。几个有意思的发现:
- Sex 的权重绝对值最大(-1.29),说明性别是影响生死的首要因素。Titanic 的"妇女儿童优先"政策确实有效,女性幸存率远高于男性。
- Pclass 权重次之(-0.80),头等舱的幸存率明显高于三等舱。三等舱乘客在船的下层,离救生艇最远。
- Fare 权重为正但很小(+0.12),票价跟舱位等级相关,信息被 Pclass 覆盖了大部分。
特征权重条形图。Sex 和 Pclass 的负权重最大,Fare 和 Emb_C 为小的正权重。 红色柱子代表负权重(降低幸存概率),蓝色代表正权重。Sex(male=1) 的权重 -1.29 意味着在其他条件相同时,男性幸存概率远低于女性。Pclass 的 -0.80 说明三等舱乘客明显更危险。Age 的 -0.41 表明年龄每增加一个标准差,幸存概率也会有所下降。- 精度(Precision):0.7857,预测幸存的人中,78.6% 真的幸存
- 召回(Recall):0.7432,实际幸存的人中,74.3% 被正确找出来
- F1-score:0.7639
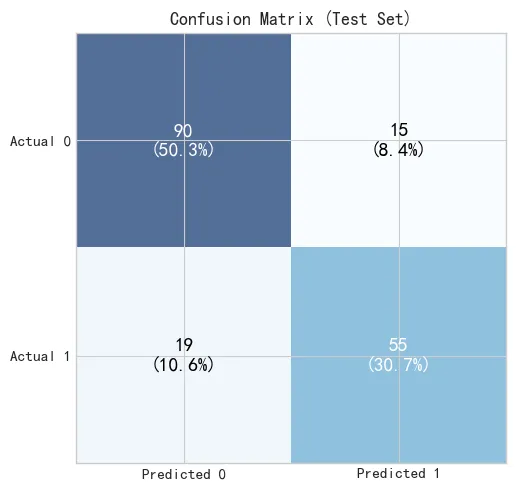
混淆矩阵热力图。左上角(真实 0 预测 0)和右下角(真实 1 预测 1)是预测正确的格子,颜色最深。 左下角(真实 1 预测 0)有 19 个漏报,是误判的大头。模型对"幸存"的判断偏保守,错误主要来自把实际幸存者预测为遇难。右下角的 55是正确预测的幸存者。
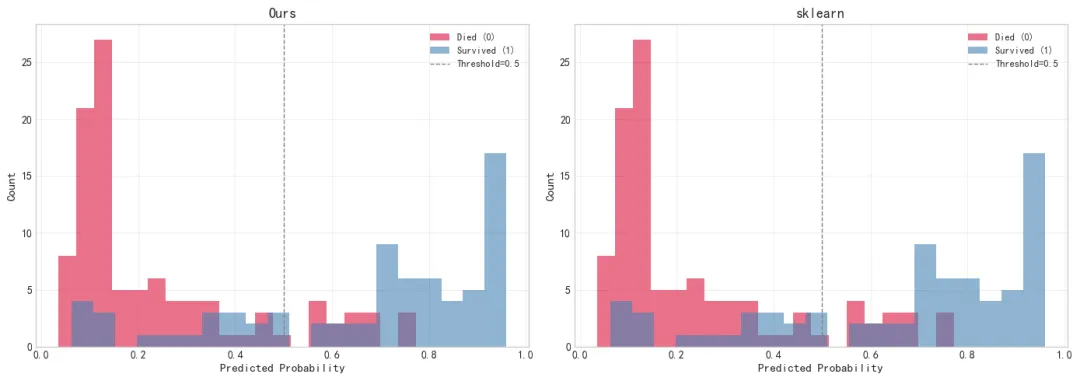
看测试集的预测概率分布:
预测概率分布直方图,遇难者(橙色)和幸存者(蓝色)的概率分布有明显区分。 橙色柱子集中在 0.2-0.4 区间,蓝色集中在 0.6-0.9 区间,说明模型对大部分样本的判断是比较确定的。中间 0.4-0.6 的重叠区域是模型信心不足的样本,这部分数量不多,不影响整体效果。
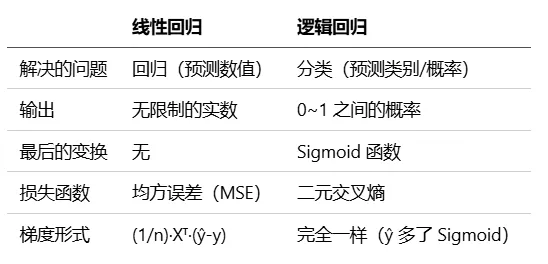
三、与线性回归对比
核心区别:逻辑回归 = 线性回归 + Sigmoid + 交叉熵损失。
四、怎么选择
- 二分类用逻辑回归是不错的选择。
- 多分类的话可以了解 Softmax 回归。 本质就是把 Sigmoid 换成 Softmax,输出每个类别的概率。
- 数据接近线性可分,逻辑回归效果很好。 特征和目标之间的关系不算太复杂时,逻辑回归已经够用。
- 数据高度非线性,考虑树模型或 SVM。 逻辑回归的决策边界是线性的,特征交互复杂时表达能力有限。
- 需要概率校准,逻辑回归。 有些模型(比如 SVM)输出的分数不是真正的概率,需要额外校准。逻辑回归输出的本身就是概率。
五、代码和实现
代码:models/logistic_regression.py
notebook:notebooks/day3_logistic_regression.ipynb
下一篇进决策树(CART)。思路跟线性模型完全不同——不再用直线和超平面,而是基于"如果-那么"的树形规则做判断。节点分裂用 Gini 系数还是信息增益?剪枝怎么防止过拟合?下篇详细讨论。
代码和数据集在https://github.com/HuangWuwutelling/ml-learning,实验都可以复现。