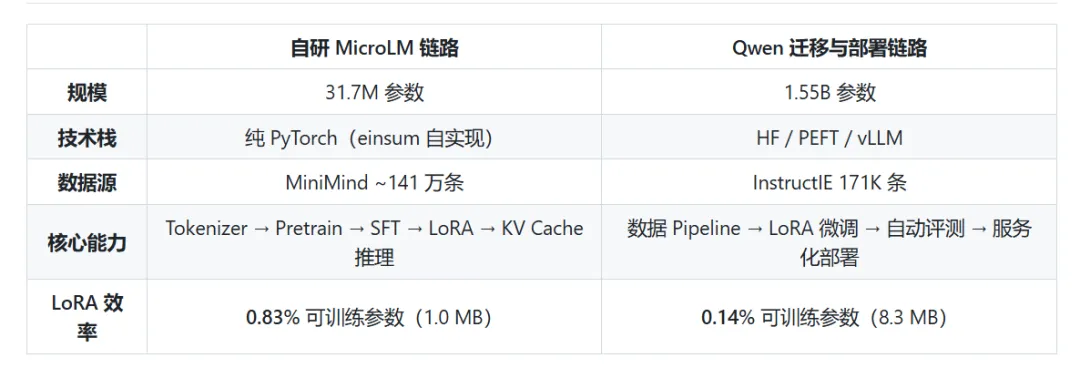
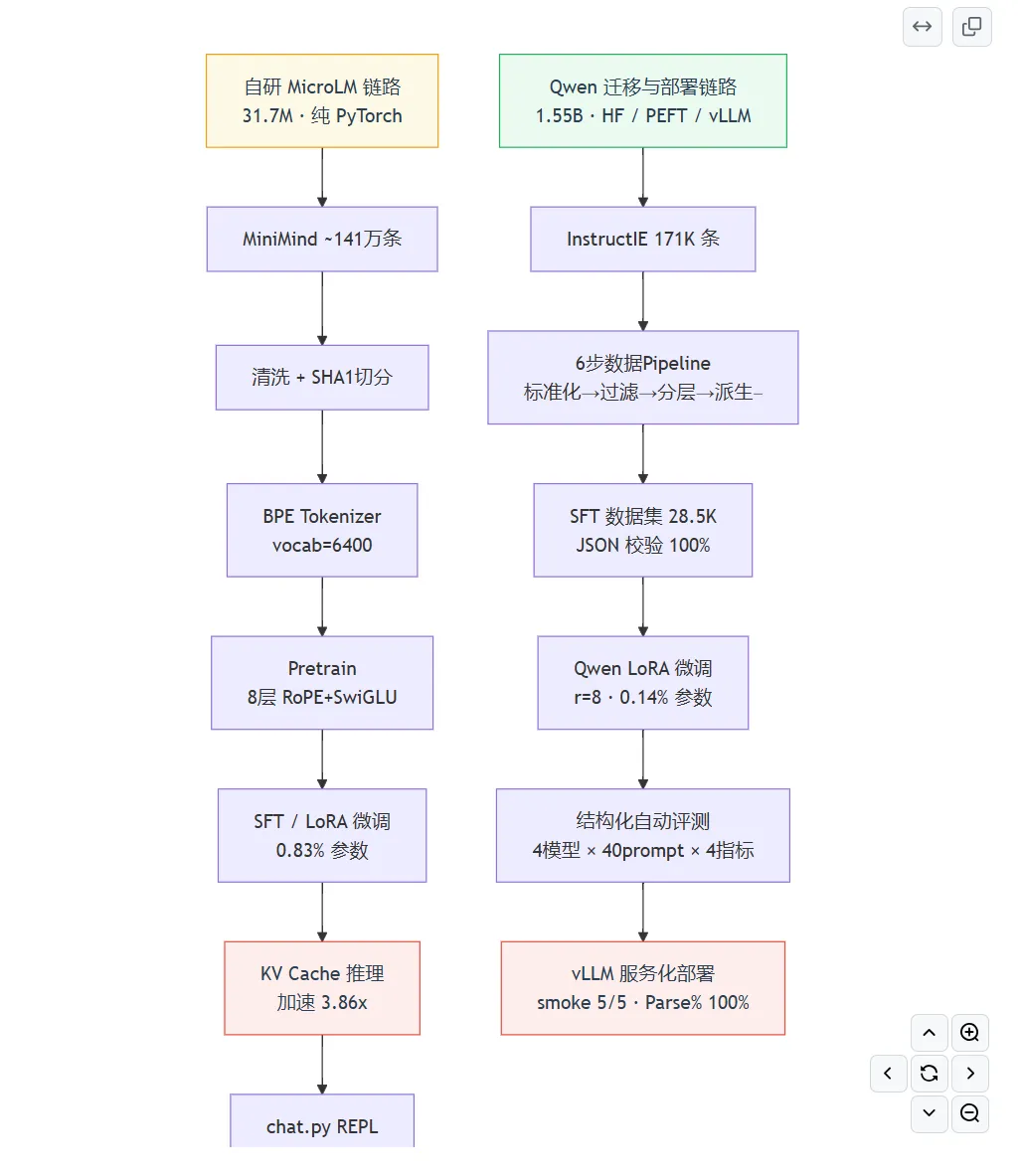
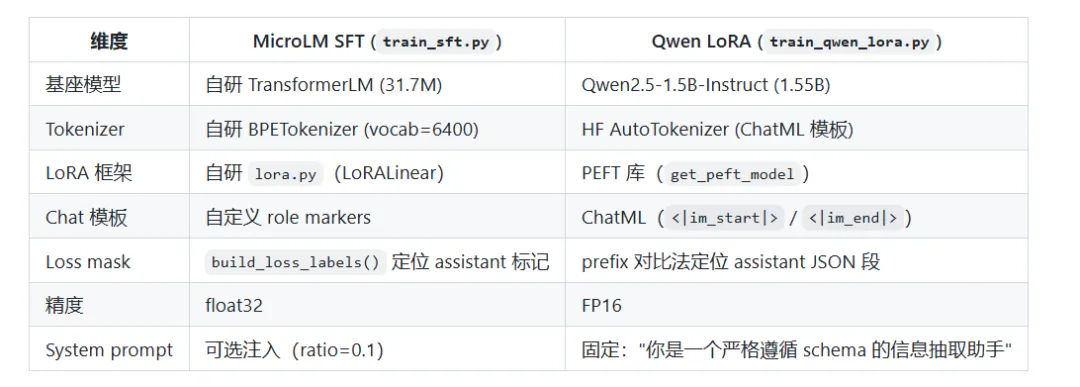
对于正在学习大模型的同学,可能对于高效参数微调,模型预训练和后训练等概念并不陌生,但是没有手搓过相应的代码,往往对这些概念的理解不够深刻学习大模型无非就是要学会从零开始搭建一个能训练,能微调,能推理的完整LLM链路,覆盖tokenizer训练,语料处理,预训练,SFT, Lora,推理优化,评测与部署等环节这一期主要是给大家推荐一个适合新手小白的大模型项目主要介绍这个项目的完整内容和技术路线,既可以学习手搓一个微型的LLM,也可以采用Qwen大模型来实战,重要是理解整个pipeline这一部分主要内容包括预训练数据处理与tokenizer, TransformerLM模型设计,预训练的流程,SFT数据协议与训练机制,Lora接入与高效参数微调,模型能力边界探索等,一定要自己去把每个环节都写一遍代码,这样子理解会非常深刻这一部分主要介绍如何调优大模型,包括prompt的设计,KV Cache优化,Benchmark设计,交互式对话系统设计等,这一部分还是有些难度的,一定要理解每个操作背后的原理这一部分把自研链路积累的方法论迁移到开源生态(Qwen2.5-1.5B-Instruct),同时把任务聚焦到结构化输出。它的定位不是"再做一次训练",而是"同一套方法论在工业工具栈上的验证 + 能力聚焦带来的可量化收益"。突出"迁移"和"聚焦",不是简单复制第二章这一部分需要建立一套可复现的统一评测流程——同一组 prompt、同一套采样参数、同一个随机种子,让不同模型之间的差异可比以上内容覆盖了大模型的各个环节,并且均有相应中文文档说明,不用担心看不懂代码,这个项目大概需要2周左右的时间,后面也可以写到简历上作为项目使用资料获取:
1. 关注本公众号
2. 发送口令“大模型项目”领取(人工回复可能有时差,都会发给大家的,不用着急)