花了3个多小时,完整的看完了罗福莉的访谈视频,很有收获。尤其是大半的时间,访谈内容都与Agent相关,让我对Agent的看法有了很大变化。
刚好赶上DeepSeek的V4发布,将看了访谈后的心得与DeepSeek进一步进行了交流,更新了人、Agent、大模型相互之间的关系,以后需要考虑使用Agent了。
主要的心得如下:
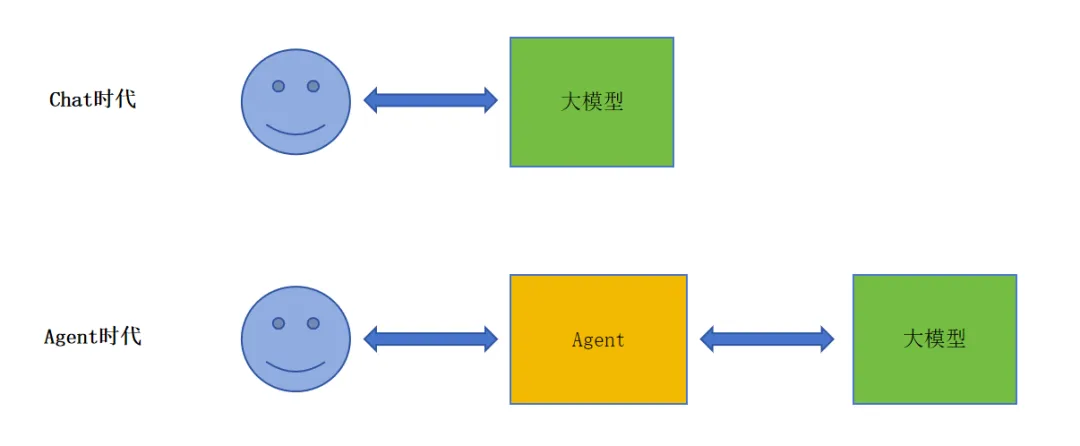
1,大模型从chat阶段演进到agent阶段。
如上图所示,以后,除了人与大模型之间的问答式交互,可能更为复杂的一些任务,都需要借助Agent来实现人与大模型之间的多轮复杂任务交互,尤其是需要多层记忆,借助数据库的场景,就必须依赖Agent了。
大体的分工如下:
lAgent层:负责任务拆解、工具调用、记忆管理、错误恢复。它把人类的高层意图转化为模型可执行的“步骤序列”。
l大模型层:只负责“下一步该做什么”的推理。它看到的是Agent塞给它的、已经是结构化的上下文(可能很长)。
l人类层:只与Agent对话。Agent可以是一个聊天窗口、一个语音助手、或者嵌入式插件。
关键信息点:
(1)Agent既能定义Agent与人之间的交互层,也能定义Agent与模型的沟通,成为人与大模型之间很好的中间层;
(2)Openclaw考虑到端到端的很多细节,context编排很精细,可以更好发挥模型优势;
(3)由于大模型训练时的语料限制,在Agent中可以增加人工定义的skill,对大模型的信息来源是很好的补充;
(4)Agent多模型的联合应用,根据需求选择不同的模型;
(5)Agent在评估环节的自我迭代,采用更好的模型的输出结果,沉淀下来,可以帮助次好模型达到更高水平;
(6)Agent的记忆体系,分层,数据库实现,是重要的工程实现环节;
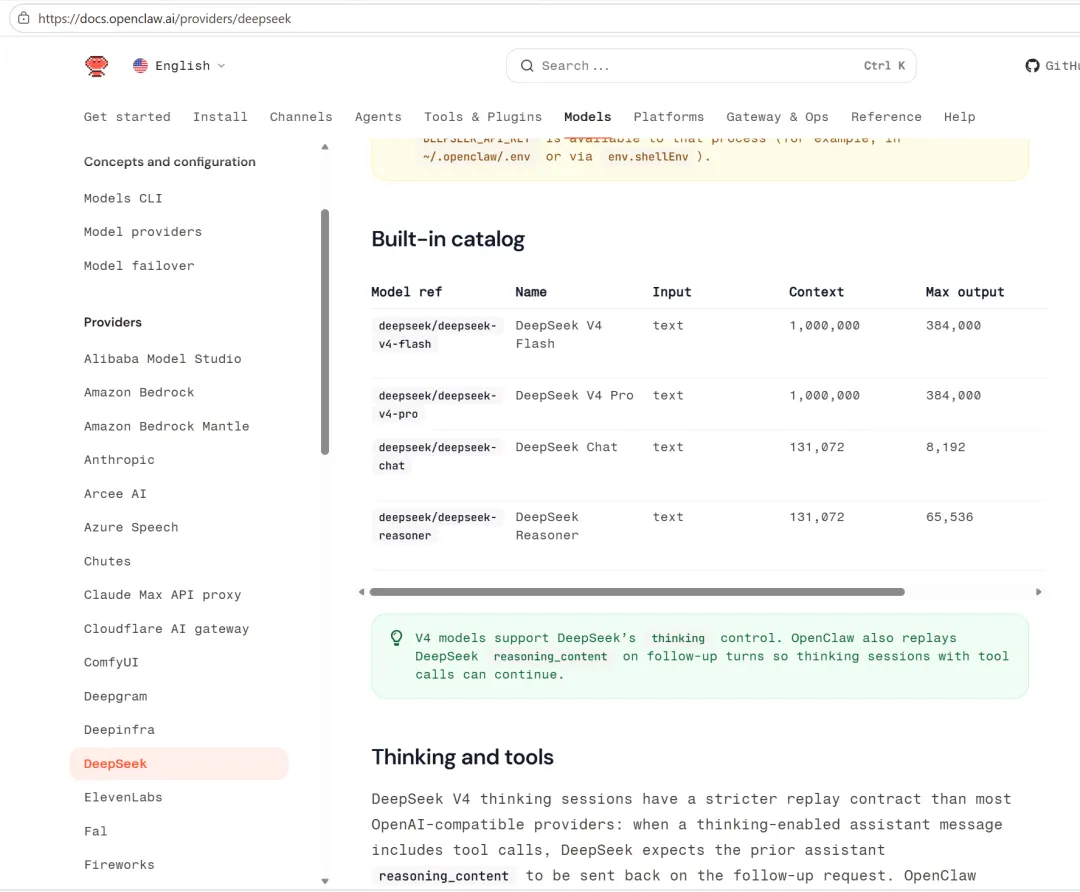
DeepSeek V4的核心技术包含了面向Agent能力的全栈优化,现在在Openclaw上也可以直接选择DeepSeek V4的模型了,Openclaw上的模型选择,国内的大模型已经很多了,阿里的千问、DeepSeek,GLM、Minimax、Moonshot的Kimi、百度的Qianfan、腾讯的Hy3、小米的Mimo,足见大模型厂商对Agent的重视程度。
下图是Openclaw网站的截图:
2、长上下文主要依靠Agent产生
长上下文是现在模型训练的一个重点,agent才能提供出更完整的上下文,也就是以后跟模型交互,agent的效率更高更好,人的手工输入比较难发挥模型效率。
人类与大模型的直接对话很少需要百万级上下文。
在日常聊天、单轮问答、甚至多数写作任务中,对话历史能超过几万token的场景极其罕见。真正需要100万token的场景,确实主要面向:
l一次性输入一个中型代码仓库。
l分析整本学术著作。
l处理超长会议记录、多轮技术排查日志等。
所以,对于普通聊天用户,长上下文更像一个“炫技”指标,而非刚需。
Agent在运行时,上下文爆炸几乎是必然的。原因如下:
思考链(Chain of Thought)累积
每一步「思考→行动→观察」都会追加数百token。完成一个复杂任务(例如“重构整个模块+运行测试+修复错误”)可能需要几十步,上下文轻松达到几万到几十万token。
工具返回的大块数据
例如:
grep一个代码库:返回100个匹配行(几千token)。
读取一个配置文件:几百到几千行。
执行一个数据库查询:返回表格数据(数万token)。
历史回溯与错误重试
Agent可能需要回顾早期的错误步骤,或者维护一个完整的“工作记忆”。如果不压缩,这部分历史会无限增长。
多任务切换
一个高级Agent可能在同时处理两个子任务(例如并行读取两份文档),上下文会包含两者的全部中间状态。
随着长上下文成本降低(像DeepSeek V4那样),Agent的“记忆”会从短期+外部向量库逐渐转向纯长上下文。这意味着:
lAgent不再需要切片、摘要、检索增强(RAG)这些复杂技术,直接把所有历史塞进上下文即可。
lAgent的代码会大幅简化,稳定性提高。
l模型之间的竞争将主要围绕每百万token的成本和长上下文中的信息召回准确率。
3、模型与Agent之间的界限如何界定
关键分界线:大模型负责“决定做什么”,Agent负责“如何做”以及“做完了怎么办”。
具体的差异如下(DeepSeekV4的输出):
4、模型与Agent之间如何配合
比如一个复杂的问题,需要先经过大模型分析后拆解为N个步骤,然后agent再把这N个步骤调用其他工具或者与大模型进行下一轮的沟通,但是如果agent的能力与大模型之前的预测不匹配怎么办呢?或者大模型在这N个步骤中难以保持前后一致性怎么处理?
问题一:如何约束模型的错误?
解决方案:三层防御机制
1.工具注册与模型提示(事前预防):Agent在调用模型时,会通过系统提示词告诉模型当前可用的工具列表(包括名称、参数、返回值格式)。模型在规划时,只能从该列表中选择工具。
2. 输出解析与校验(事中拦截):Agent收到模型的输出后,先用一个轻量解析器检查,如果校验失败,Agent 不会直接崩溃,而是构造一个错误反馈,重新发给模型,模型看到这个反馈后,可以修正自己的计划。
3. 降级与人工介入(兜底)
如果模型连续2-3次都给出无效调用,Agent可以:
l切换到“安全模式”:跳过该步骤,继续下一步。
l或向用户汇报:“我无法完成该步骤”
l或主动回滚到上一步,重新规划。
结论:不匹配是常态,但工程上通过反馈循环和约束提示可以将发生率降到很低。
问题二:大模型在多步骤中难以保持前后一致性
这是最棘手的问题。模型在每个时间点只看到当前上下文,可能忘记早期说过的话,或者前后矛盾。
解决方案:外部状态管理+ 思维链强制约束
1. 外部状态存储(Agent的职责)
Agent不应该依赖模型“记住”所有事实。正确的做法:
Agent维护一个工作记忆存储(如Python dict、Redis)。
当模型输出关键信息(如“用户ID是555”)时,Agent解析并存入memory['user_id'] = 555。
后续调用模型时,Agent将这个记忆以硬约束的形式注入提示词:
“已知:用户ID = 555。在调用任何API时,必须使用这个ID。”
这样,模型就不再需要自己回忆,而是直接从提示词中读取。
2. 思维链要求“显式引用”
在提示词中强制要求模型每一步都引用之前的结论:
text
步骤3:根据步骤1得到的用户ID(555),查询该用户的订单。
如果模型输出没有引用,Agent可以拒绝接受,要求重试。
3. 检查点与回滚
Agent将模型的每一个“决策点”记录为检查点。
如果后续发现模型自相矛盾(例如ID变了),Agent可以:
回滚到早期检查点。
清除矛盾的历史。
再次询问模型:“你之前说ID是555,现在说666,哪个正确?”
这相当于在Agent层面实现了人类对话中的“澄清”机制。
4. 显式计划执行与动态修订
模型首先生成一个大计划:[步骤1, 步骤2, 步骤3]。
Agent先不执行,而是将整个计划发回模型,要求一致性校验:
“检查以下计划中是否有矛盾或遗漏。”
计划确认后,Agent再逐步执行。每执行完一步,如果发现实际情况与计划预期不符(例如数据库返回空),Agent会触发重新规划,而不是强行执行后续步骤。
问题三:如何约束Agent的错误?
Agent同样需要被约束,而且这些约束往往比模型约束更关键。因为Agent是“发起方”和“执行方”,它的错误会直接放大模型的错误。
优秀的Agent系统还需要硬性的运行时约束和完善的治理机制。
1. 状态一致性约束:Agent不能“失忆”
Agent在多步执行中,必须知道“当前在哪一步、已经做了什么、还要做什么”。
2. 资源边界约束:Agent不能“失控”
这是最容易被忽略的约束。没有边界的Agent可能:
死循环:反复执行同一个失败步骤,永远不停止
无限消费:疯狂调用API/数据库,账单爆炸
资源耗尽:占用过多内存/CPU,影响其他服务
约束手段(硬性限额)
3. 行为安全约束:Agent不能“作恶”
模型可能是无意的,但Agent是实际执行者。如果Agent没有安全约束:
模型说“删除临时文件” → Agent执行 rm -rf /(灾难)
模型说“发送报告给团队” → Agent发送给所有人(隐私泄露)
模型说“执行这个SQL” → Agent执行 DROP TABLE users(数据丢失)
约束手段(多层防御)
4. 可观测性约束:Agent不能“黑箱”
当系统出错时,如果Agent没有留下痕迹,你无法知道是模型的规划错了,还是Agent的执行错了,还是工具返回了错误数据。
约束手段(强制日志规范)
所以一个Agent在架构层面的设计上需要考虑各种约束手段。